 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSay More with Less: Variable-Frame-Rate Speech Tokenization via Adaptive Clustering and Implicit Duration Coding
Sep 04, 2025Existing speech tokenizers typically assign a fixed number of tokens per second, regardless of the varying information density or temporal fluctuations in the speech signal. This uniform token allocation mismatches the intrinsic structure of speech, where information is distributed unevenly over time. To address this, we propose VARSTok, a VAriable-frame-Rate Speech Tokenizer that adapts token allocation based on local feature similarity. VARSTok introduces two key innovations: (1) a temporal-aware density peak clustering algorithm that adaptively segments speech into variable-length units, and (2) a novel implicit duration coding scheme that embeds both content and temporal span into a single token index, eliminating the need for auxiliary duration predictors. Extensive experiments show that VARSTok significantly outperforms strong fixed-rate baselines. Notably, it achieves superior reconstruction naturalness while using up to 23% fewer tokens than a 40 Hz fixed-frame-rate baseline. VARSTok further yields lower word error rates and improved naturalness in zero-shot text-to-speech synthesis. To the best of our knowledge, this is the first work to demonstrate that a fully dynamic, variable-frame-rate acoustic speech tokenizer can be seamlessly integrated into downstream speech language models. Speech samples are available at https://zhengrachel.github.io/VARSTok.
Solving the Min-Max Multiple Traveling Salesmen Problem via Learning-Based Path Generation and Optimal Splitting
Aug 23, 2025This study addresses the Min-Max Multiple Traveling Salesmen Problem ($m^3$-TSP), which aims to coordinate tours for multiple salesmen such that the length of the longest tour is minimized. Due to its NP-hard nature, exact solvers become impractical under the assumption that $P \ne NP$. As a result, learning-based approaches have gained traction for their ability to rapidly generate high-quality approximate solutions. Among these, two-stage methods combine learning-based components with classical solvers, simplifying the learning objective. However, this decoupling often disrupts consistent optimization, potentially degrading solution quality. To address this issue, we propose a novel two-stage framework named \textbf{Generate-and-Split} (GaS), which integrates reinforcement learning (RL) with an optimal splitting algorithm in a joint training process. The splitting algorithm offers near-linear scalability with respect to the number of cities and guarantees optimal splitting in Euclidean space for any given path. To facilitate the joint optimization of the RL component with the algorithm, we adopt an LSTM-enhanced model architecture to address partial observability. Extensive experiments show that the proposed GaS framework significantly outperforms existing learning-based approaches in both solution quality and transferability.
Time Is a Feature: Exploiting Temporal Dynamics in Diffusion Language Models
Aug 12, 2025Diffusion large language models (dLLMs) generate text through iterative denoising, yet current decoding strategies discard rich intermediate predictions in favor of the final output. Our work here reveals a critical phenomenon, temporal oscillation, where correct answers often emerge in the middle process, but are overwritten in later denoising steps. To address this issue, we introduce two complementary methods that exploit temporal consistency: 1) Temporal Self-Consistency Voting, a training-free, test-time decoding strategy that aggregates predictions across denoising steps to select the most consistent output; and 2) a post-training method termed Temporal Consistency Reinforcement, which uses Temporal Semantic Entropy (TSE), a measure of semantic stability across intermediate predictions, as a reward signal to encourage stable generations. Empirical results across multiple benchmarks demonstrate the effectiveness of our approach. Using the negative TSE reward alone, we observe a remarkable average improvement of 24.7% on the Countdown dataset over an existing dLLM. Combined with the accuracy reward, we achieve absolute gains of 2.0% on GSM8K, 4.3% on MATH500, 6.6% on SVAMP, and 25.3% on Countdown, respectively. Our findings underscore the untapped potential of temporal dynamics in dLLMs and offer two simple yet effective tools to harness them.
SpeakerLM: End-to-End Versatile Speaker Diarization and Recognition with Multimodal Large Language Models
Aug 08, 2025The Speaker Diarization and Recognition (SDR) task aims to predict "who spoke when and what" within an audio clip, which is a crucial task in various real-world multi-speaker scenarios such as meeting transcription and dialogue systems. Existing SDR systems typically adopt a cascaded framework, combining multiple modules such as speaker diarization (SD) and automatic speech recognition (ASR). The cascaded systems suffer from several limitations, such as error propagation, difficulty in handling overlapping speech, and lack of joint optimization for exploring the synergy between SD and ASR tasks. To address these limitations, we introduce SpeakerLM, a unified multimodal large language model for SDR that jointly performs SD and ASR in an end-to-end manner. Moreover, to facilitate diverse real-world scenarios, we incorporate a flexible speaker registration mechanism into SpeakerLM, enabling SDR under different speaker registration settings. SpeakerLM is progressively developed with a multi-stage training strategy on large-scale real data. Extensive experiments show that SpeakerLM demonstrates strong data scaling capability and generalizability, outperforming state-of-the-art cascaded baselines on both in-domain and out-of-domain public SDR benchmarks. Furthermore, experimental results show that the proposed speaker registration mechanism effectively ensures robust SDR performance of SpeakerLM across diverse speaker registration conditions and varying numbers of registered speakers.
Token Communication in the Era of Large Models: An Information Bottleneck-Based Approach
Jul 02, 2025This letter proposes UniToCom, a unified token communication paradigm that treats tokens as the fundamental units for both processing and wireless transmission. Specifically, to enable efficient token representations, we propose a generative information bottleneck (GenIB) principle, which facilitates the learning of tokens that preserve essential information while supporting reliable generation across multiple modalities. By doing this, GenIB-based tokenization is conducive to improving the communication efficiency and reducing computational complexity. Additionally, we develop $\sigma$-GenIB to address the challenges of variance collapse in autoregressive modeling, maintaining representational diversity and stability. Moreover, we employ a causal Transformer-based multimodal large language model (MLLM) at the receiver to unify the processing of both discrete and continuous tokens under the next-token prediction paradigm. Simulation results validate the effectiveness and superiority of the proposed UniToCom compared to baselines under dynamic channel conditions. By integrating token processing with MLLMs, UniToCom enables scalable and generalizable communication in favor of multimodal understanding and generation, providing a potential solution for next-generation intelligent communications.
ThinkSound: Chain-of-Thought Reasoning in Multimodal Large Language Models for Audio Generation and Editing
Jun 26, 2025



While end-to-end video-to-audio generation has greatly improved, producing high-fidelity audio that authentically captures the nuances of visual content remains challenging. Like professionals in the creative industries, such generation requires sophisticated reasoning about items such as visual dynamics, acoustic environments, and temporal relationships. We present \textbf{ThinkSound}, a novel framework that leverages Chain-of-Thought (CoT) reasoning to enable stepwise, interactive audio generation and editing for videos. Our approach decomposes the process into three complementary stages: foundational foley generation that creates semantically coherent soundscapes, interactive object-centric refinement through precise user interactions, and targeted editing guided by natural language instructions. At each stage, a multimodal large language model generates contextually aligned CoT reasoning that guides a unified audio foundation model. Furthermore, we introduce \textbf{AudioCoT}, a comprehensive dataset with structured reasoning annotations that establishes connections between visual content, textual descriptions, and sound synthesis. Experiments demonstrate that ThinkSound achieves state-of-the-art performance in video-to-audio generation across both audio metrics and CoT metrics and excels in out-of-distribution Movie Gen Audio benchmark. The demo page is available at https://ThinkSound-Demo.github.io.
OmniDRCA: Parallel Speech-Text Foundation Model via Dual-Resolution Speech Representations and Contrastive Alignment
Jun 11, 2025Recent studies on end-to-end speech generation with large language models (LLMs) have attracted significant community attention, with multiple works extending text-based LLMs to generate discrete speech tokens. Existing approaches primarily fall into two categories: (1) Methods that generate discrete speech tokens independently without incorporating them into the LLM's autoregressive process, resulting in text generation being unaware of concurrent speech synthesis. (2) Models that generate interleaved or parallel speech-text tokens through joint autoregressive modeling, enabling mutual modality awareness during generation. This paper presents OmniDRCA, a parallel speech-text foundation model based on joint autoregressive modeling, featuring dual-resolution speech representations and contrastive cross-modal alignment. Our approach processes speech and text representations in parallel while enhancing audio comprehension through contrastive alignment. Experimental results on Spoken Question Answering benchmarks demonstrate that OmniDRCA establishes new state-of-the-art (SOTA) performance among parallel joint speech-text modeling based foundation models, and achieves competitive performance compared to interleaved models. Additionally, we explore the potential of extending the framework to full-duplex conversational scenarios.
Speech Token Prediction via Compressed-to-fine Language Modeling for Speech Generation
May 30, 2025Neural audio codecs, used as speech tokenizers, have demonstrated remarkable potential in the field of speech generation. However, to ensure high-fidelity audio reconstruction, neural audio codecs typically encode audio into long sequences of speech tokens, posing a significant challenge for downstream language models in long-context modeling. We observe that speech token sequences exhibit short-range dependency: due to the monotonic alignment between text and speech in text-to-speech (TTS) tasks, the prediction of the current token primarily relies on its local context, while long-range tokens contribute less to the current token prediction and often contain redundant information. Inspired by this observation, we propose a \textbf{compressed-to-fine language modeling} approach to address the challenge of long sequence speech tokens within neural codec language models: (1) \textbf{Fine-grained Initial and Short-range Information}: Our approach retains the prompt and local tokens during prediction to ensure text alignment and the integrity of paralinguistic information; (2) \textbf{Compressed Long-range Context}: Our approach compresses long-range token spans into compact representations to reduce redundant information while preserving essential semantics. Extensive experiments on various neural audio codecs and downstream language models validate the effectiveness and generalizability of the proposed approach, highlighting the importance of token compression in improving speech generation within neural codec language models. The demo of audio samples will be available at https://anonymous.4open.science/r/SpeechTokenPredictionViaCompressedToFinedLM.
Towards Minimizing Feature Drift in Model Merging: Layer-wise Task Vector Fusion for Adaptive Knowledge Integration
May 29, 2025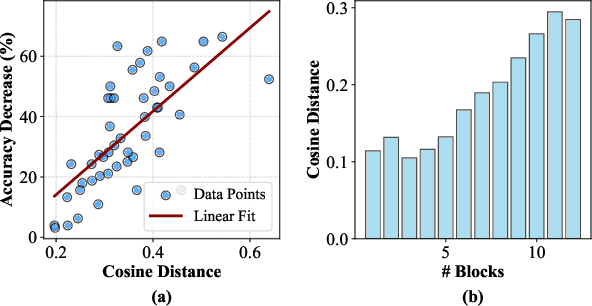
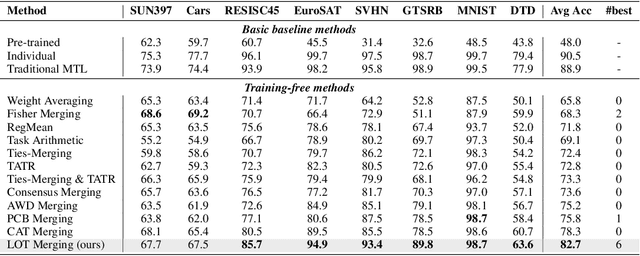
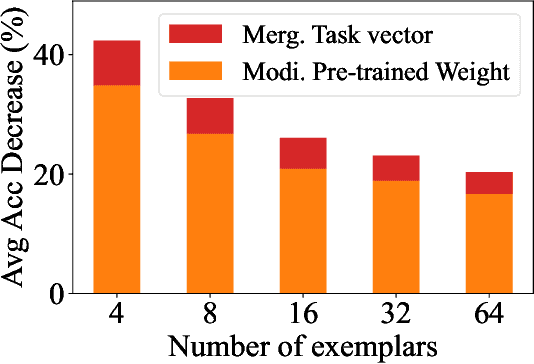
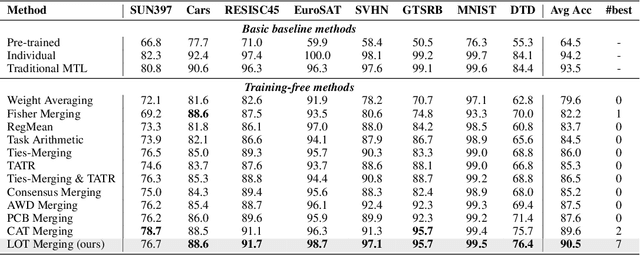
Multi-task model merging aims to consolidate knowledge from multiple fine-tuned task-specific experts into a unified model while minimizing performance degradation. Existing methods primarily approach this by minimizing differences between task-specific experts and the unified model, either from a parameter-level or a task-loss perspective. However, parameter-level methods exhibit a significant performance gap compared to the upper bound, while task-loss approaches entail costly secondary training procedures. In contrast, we observe that performance degradation closely correlates with feature drift, i.e., differences in feature representations of the same sample caused by model merging. Motivated by this observation, we propose Layer-wise Optimal Task Vector Merging (LOT Merging), a technique that explicitly minimizes feature drift between task-specific experts and the unified model in a layer-by-layer manner. LOT Merging can be formulated as a convex quadratic optimization problem, enabling us to analytically derive closed-form solutions for the parameters of linear and normalization layers. Consequently, LOT Merging achieves efficient model consolidation through basic matrix operations. Extensive experiments across vision and vision-language benchmarks demonstrate that LOT Merging significantly outperforms baseline methods, achieving improvements of up to 4.4% (ViT-B/32) over state-of-the-art approaches.
Omni-R1: Reinforcement Learning for Omnimodal Reasoning via Two-System Collaboration
May 26, 2025Long-horizon video-audio reasoning and fine-grained pixel understanding impose conflicting requirements on omnimodal models: dense temporal coverage demands many low-resolution frames, whereas precise grounding calls for high-resolution inputs. We tackle this trade-off with a two-system architecture: a Global Reasoning System selects informative keyframes and rewrites the task at low spatial cost, while a Detail Understanding System performs pixel-level grounding on the selected high-resolution snippets. Because ``optimal'' keyframe selection and reformulation are ambiguous and hard to supervise, we formulate them as a reinforcement learning (RL) problem and present Omni-R1, an end-to-end RL framework built on Group Relative Policy Optimization. Omni-R1 trains the Global Reasoning System through hierarchical rewards obtained via online collaboration with the Detail Understanding System, requiring only one epoch of RL on small task splits. Experiments on two challenging benchmarks, namely Referring Audio-Visual Segmentation (RefAVS) and Reasoning Video Object Segmentation (REVOS), show that Omni-R1 not only surpasses strong supervised baselines but also outperforms specialized state-of-the-art models, while substantially improving out-of-domain generalization and mitigating multimodal hallucination. Our results demonstrate the first successful application of RL to large-scale omnimodal reasoning and highlight a scalable path toward universally foundation models.