 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Symbolic World Models via Test-time Scaling of Large Language Models
Feb 07, 2025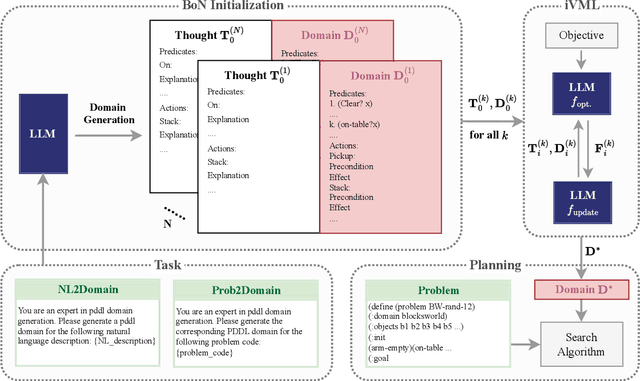

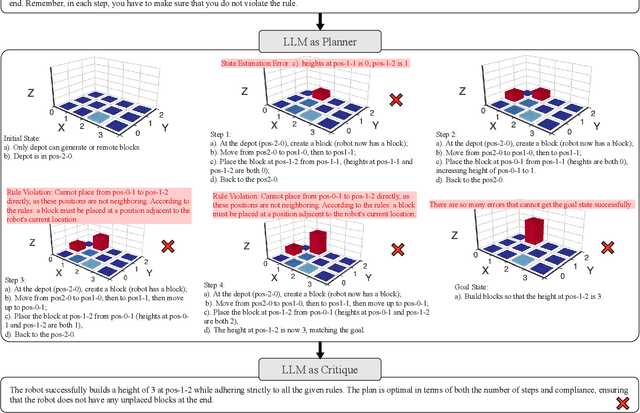
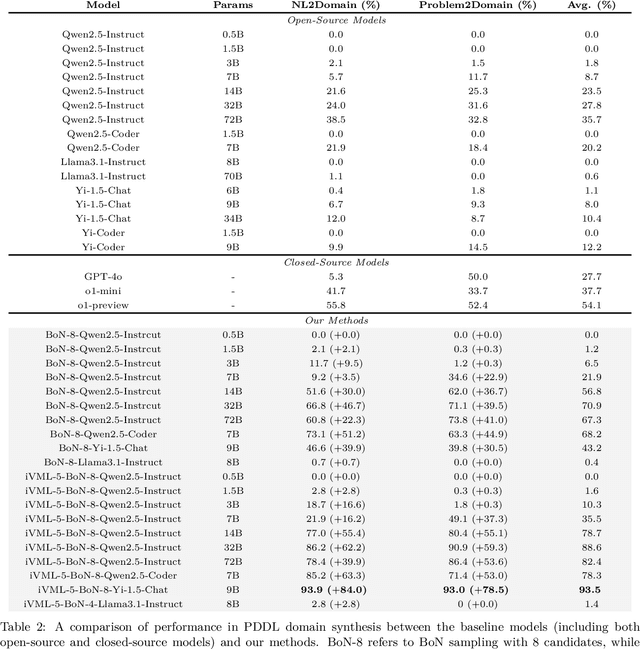
Solving complex planning problems requires Large Language Models (LLMs) to explicitly model the state transition to avoid rule violations, comply with constraints, and ensure optimality-a task hindered by the inherent ambiguity of natural language. To overcome such ambiguity, Planning Domain Definition Language (PDDL) is leveraged as a planning abstraction that enables precise and formal state descriptions. With PDDL, we can generate a symbolic world model where classic searching algorithms, such as A*, can be seamlessly applied to find optimal plans. However, directly generating PDDL domains with current LLMs remains an open challenge due to the lack of PDDL training data. To address this challenge, we propose to scale up the test-time computation of LLMs to enhance their PDDL reasoning capabilities, thereby enabling the generation of high-quality PDDL domains. Specifically, we introduce a simple yet effective algorithm, which first employs a Best-of-N sampling approach to improve the quality of the initial solution and then refines the solution in a fine-grained manner with verbalized machine learning. Our method outperforms o1-mini by a considerable margin in the generation of PDDL domain, achieving over 50% success rate on two tasks (i.e., generating PDDL domains from natural language description or PDDL problems). This is done without requiring additional training. By taking advantage of PDDL as state abstraction, our method is able to outperform current state-of-the-art methods on almost all competition-level planning tasks.
SepLLM: Accelerate Large Language Models by Compressing One Segment into One Separator
Dec 16, 2024



Large Language Models (LLMs) have exhibited exceptional performance across a spectrum of natural language processing tasks. However, their substantial sizes pose considerable challenges, particularly in computational demands and inference speed, due to their quadratic complexity. In this work, we have identified a key pattern: certain seemingly meaningless special tokens (i.e., separators) contribute disproportionately to attention scores compared to semantically meaningful tokens. This observation suggests that information of the segments between these separator tokens can be effectively condensed into the separator tokens themselves without significant information loss. Guided by this insight, we introduce SepLLM, a plug-and-play framework that accelerates inference by compressing these segments and eliminating redundant tokens. Additionally, we implement efficient kernels for training acceleration. Experimental results across training-free, training-from-scratch, and post-training settings demonstrate SepLLM's effectiveness. Notably, using the Llama-3-8B backbone, SepLLM achieves over 50% reduction in KV cache on the GSM8K-CoT benchmark while maintaining comparable performance. Furthermore, in streaming settings, SepLLM effectively processes sequences of up to 4 million tokens or more while maintaining consistent language modeling capabilities.
Efficient Diversity-Preserving Diffusion Alignment via Gradient-Informed GFlowNets
Dec 10, 2024While one commonly trains large diffusion models by collecting datasets on target downstream tasks, it is often desired to align and finetune pretrained diffusion models on some reward functions that are either designed by experts or learned from small-scale datasets. Existing methods for finetuning diffusion models typically suffer from lack of diversity in generated samples, lack of prior preservation, and/or slow convergence in finetuning. Inspired by recent successes in generative flow networks (GFlowNets), a class of probabilistic models that sample with the unnormalized density of a reward function, we propose a novel GFlowNet method dubbed Nabla-GFlowNet (abbreviated as $\nabla$-GFlowNet), the first GFlowNet method that leverages the rich signal in reward gradients, together with an objective called $\nabla$-DB plus its variant residual $\nabla$-DB designed for prior-preserving diffusion alignment. We show that our proposed method achieves fast yet diversity- and prior-preserving alignment of Stable Diffusion, a large-scale text-conditioned image diffusion model, on different realistic reward functions.
VERA: Explainable Video Anomaly Detection via Verbalized Learning of Vision-Language Models
Dec 02, 2024



The rapid advancement of vision-language models (VLMs) has established a new paradigm in video anomaly detection (VAD): leveraging VLMs to simultaneously detect anomalies and provide comprehendible explanations for the decisions. Existing work in this direction often assumes the complex reasoning required for VAD exceeds the capabilities of pretrained VLMs. Consequently, these approaches either incorporate specialized reasoning modules during inference or rely on instruction tuning datasets through additional training to adapt VLMs for VAD. However, such strategies often incur substantial computational costs or data annotation overhead. To address these challenges in explainable VAD, we introduce a verbalized learning framework named VERA that enables VLMs to perform VAD without model parameter modifications. Specifically, VERA automatically decomposes the complex reasoning required for VAD into reflections on simpler, more focused guiding questions capturing distinct abnormal patterns. It treats these reflective questions as learnable parameters and optimizes them through data-driven verbal interactions between learner and optimizer VLMs, using coarsely labeled training data. During inference, VERA embeds the learned questions into model prompts to guide VLMs in generating segment-level anomaly scores, which are then refined into frame-level scores via the fusion of scene and temporal contexts. Experimental results on challenging benchmarks demonstrate that the learned questions of VERA are highly adaptable, significantly improving both detection performance and explainability of VLMs for VAD.
Manifold-Constrained Nucleus-Level Denoising Diffusion Model for Structure-Based Drug Design
Sep 16, 2024Artificial intelligence models have shown great potential in structure-based drug design, generating ligands with high binding affinities. However, existing models have often overlooked a crucial physical constraint: atoms must maintain a minimum pairwise distance to avoid separation violation, a phenomenon governed by the balance of attractive and repulsive forces. To mitigate such separation violations, we propose NucleusDiff. It models the interactions between atomic nuclei and their surrounding electron clouds by enforcing the distance constraint between the nuclei and manifolds. We quantitatively evaluate NucleusDiff using the CrossDocked2020 dataset and a COVID-19 therapeutic target, demonstrating that NucleusDiff reduces violation rate by up to 100.00% and enhances binding affinity by up to 22.16%, surpassing state-of-the-art models for structure-based drug design. We also provide qualitative analysis through manifold sampling, visually confirming the effectiveness of NucleusDiff in reducing separation violations and improving binding affinities.
Can Large Language Models Understand Symbolic Graphics Programs?
Aug 15, 2024



Assessing the capabilities of large language models (LLMs) is often challenging, in part, because it is hard to find tasks to which they have not been exposed during training. We take one step to address this challenge by turning to a new task: focusing on symbolic graphics programs, which are a popular representation for graphics content that procedurally generates visual data. LLMs have shown exciting promise towards program synthesis, but do they understand symbolic graphics programs? Unlike conventional programs, symbolic graphics programs can be translated to graphics content. Here, we characterize an LLM's understanding of symbolic programs in terms of their ability to answer questions related to the graphics content. This task is challenging as the questions are difficult to answer from the symbolic programs alone -- yet, they would be easy to answer from the corresponding graphics content as we verify through a human experiment. To understand symbolic programs, LLMs may need to possess the ability to imagine how the corresponding graphics content would look without directly accessing the rendered visual content. We use this task to evaluate LLMs by creating a large benchmark for the semantic understanding of symbolic graphics programs. This benchmark is built via program-graphics correspondence, hence requiring minimal human efforts. We evaluate current LLMs on our benchmark to elucidate a preliminary assessment of their ability to reason about visual scenes from programs. We find that this task distinguishes existing LLMs and models considered good at reasoning perform better. Lastly, we introduce Symbolic Instruction Tuning (SIT) to improve this ability. Specifically, we query GPT4-o with questions and images generated by symbolic programs. Such data are then used to finetune an LLM. We also find that SIT data can improve the general instruction following ability of LLMs.
Representational Alignment Supports Effective Machine Teaching
Jun 06, 2024A good teacher should not only be knowledgeable; but should be able to communicate in a way that the student understands -- to share the student's representation of the world. In this work, we integrate insights from machine teaching and pragmatic communication with the burgeoning literature on representational alignment to characterize a utility curve defining a relationship between representational alignment and teacher capability for promoting student learning. To explore the characteristics of this utility curve, we design a supervised learning environment that disentangles representational alignment from teacher accuracy. We conduct extensive computational experiments with machines teaching machines, complemented by a series of experiments in which machines teach humans. Drawing on our findings that improved representational alignment with a student improves student learning outcomes (i.e., task accuracy), we design a classroom matching procedure that assigns students to teachers based on the utility curve. If we are to design effective machine teachers, it is not enough to build teachers that are accurate -- we want teachers that can align, representationally, to their students too.
Verbalized Machine Learning: Revisiting Machine Learning with Language Models
Jun 06, 2024Motivated by the large progress made by large language models (LLMs), we introduce the framework of verbalized machine learning (VML). In contrast to conventional machine learning models that are typically optimized over a continuous parameter space, VML constrains the parameter space to be human-interpretable natural language. Such a constraint leads to a new perspective of function approximation, where an LLM with a text prompt can be viewed as a function parameterized by the text prompt. Guided by this perspective, we revisit classical machine learning problems, such as regression and classification, and find that these problems can be solved by an LLM-parameterized learner and optimizer. The major advantages of VML include (1) easy encoding of inductive bias: prior knowledge about the problem and hypothesis class can be encoded in natural language and fed into the LLM-parameterized learner; (2) automatic model class selection: the optimizer can automatically select a concrete model class based on data and verbalized prior knowledge, and it can update the model class during training; and (3) interpretable learner updates: the LLM-parameterized optimizer can provide explanations for why each learner update is performed. We conduct several studies to empirically evaluate the effectiveness of VML, and hope that VML can serve as a stepping stone to stronger interpretability and trustworthiness in ML.
ChatHuman: Language-driven 3D Human Understanding with Retrieval-Augmented Tool Reasoning
May 07, 2024



Numerous methods have been proposed to detect, estimate, and analyze properties of people in images, including the estimation of 3D pose, shape, contact, human-object interaction, emotion, and more. Each of these methods works in isolation instead of synergistically. Here we address this problem and build a language-driven human understanding system -- ChatHuman, which combines and integrates the skills of many different methods. To do so, we finetune a Large Language Model (LLM) to select and use a wide variety of existing tools in response to user inputs. In doing so, ChatHuman is able to combine information from multiple tools to solve problems more accurately than the individual tools themselves and to leverage tool output to improve its ability to reason about humans. The novel features of ChatHuman include leveraging academic publications to guide the application of 3D human-related tools, employing a retrieval-augmented generation model to generate in-context-learning examples for handling new tools, and discriminating and integrating tool results to enhance 3D human understanding. Our experiments show that ChatHuman outperforms existing models in both tool selection accuracy and performance across multiple 3D human-related tasks. ChatHuman is a step towards consolidating diverse methods for human analysis into a single, powerful, system for 3D human reasoning.
Re-Thinking Inverse Graphics With Large Language Models
Apr 23, 2024Inverse graphics -- the task of inverting an image into physical variables that, when rendered, enable reproduction of the observed scene -- is a fundamental challenge in computer vision and graphics. Disentangling an image into its constituent elements, such as the shape, color, and material properties of the objects of the 3D scene that produced it, requires a comprehensive understanding of the environment. This requirement limits the ability of existing carefully engineered approaches to generalize across domains. Inspired by the zero-shot ability of large language models (LLMs) to generalize to novel contexts, we investigate the possibility of leveraging the broad world knowledge encoded in such models in solving inverse-graphics problems. To this end, we propose the Inverse-Graphics Large Language Model (IG-LLM), an inverse-graphics framework centered around an LLM, that autoregressively decodes a visual embedding into a structured, compositional 3D-scene representation. We incorporate a frozen pre-trained visual encoder and a continuous numeric head to enable end-to-end training. Through our investigation, we demonstrate the potential of LLMs to facilitate inverse graphics through next-token prediction, without the use of image-space supervision. Our analysis opens up new possibilities for precise spatial reasoning about images that exploit the visual knowledge of LLMs. We will release our code and data to ensure the reproducibility of our investigation and to facilitate future research at https://ig-llm.is.tue.mpg.de/