 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenLit: Reformulating Single-Image Relighting as Video Generation
Dec 15, 2024



Manipulating the illumination within a single image represents a fundamental challenge in computer vision and graphics. This problem has been traditionally addressed using inverse rendering techniques, which require explicit 3D asset reconstruction and costly ray tracing simulations. Meanwhile, recent advancements in visual foundation models suggest that a new paradigm could soon be practical and possible -- one that replaces explicit physical models with networks that are trained on massive amounts of image and video data. In this paper, we explore the potential of exploiting video diffusion models, and in particular Stable Video Diffusion (SVD), in understanding the physical world to perform relighting tasks given a single image. Specifically, we introduce GenLit, a framework that distills the ability of a graphics engine to perform light manipulation into a video generation model, enabling users to directly insert and manipulate a point light in the 3D world within a given image and generate the results directly as a video sequence. We find that a model fine-tuned on only a small synthetic dataset (270 objects) is able to generalize to real images, enabling single-image relighting with realistic ray tracing effects and cast shadows. These results reveal the ability of video foundation models to capture rich information about lighting, material, and shape. Our findings suggest that such models, with minimal training, can be used for physically-based rendering without explicit physically asset reconstruction and complex ray tracing. This further suggests the potential of such models for controllable and physically accurate image synthesis tasks.
SPARK: Self-supervised Personalized Real-time Monocular Face Capture
Sep 12, 2024



Feedforward monocular face capture methods seek to reconstruct posed faces from a single image of a person. Current state of the art approaches have the ability to regress parametric 3D face models in real-time across a wide range of identities, lighting conditions and poses by leveraging large image datasets of human faces. These methods however suffer from clear limitations in that the underlying parametric face model only provides a coarse estimation of the face shape, thereby limiting their practical applicability in tasks that require precise 3D reconstruction (aging, face swapping, digital make-up, ...). In this paper, we propose a method for high-precision 3D face capture taking advantage of a collection of unconstrained videos of a subject as prior information. Our proposal builds on a two stage approach. We start with the reconstruction of a detailed 3D face avatar of the person, capturing both precise geometry and appearance from a collection of videos. We then use the encoder from a pre-trained monocular face reconstruction method, substituting its decoder with our personalized model, and proceed with transfer learning on the video collection. Using our pre-estimated image formation model, we obtain a more precise self-supervision objective, enabling improved expression and pose alignment. This results in a trained encoder capable of efficiently regressing pose and expression parameters in real-time from previously unseen images, which combined with our personalized geometry model yields more accurate and high fidelity mesh inference. Through extensive qualitative and quantitative evaluation, we showcase the superiority of our final model as compared to state-of-the-art baselines, and demonstrate its generalization ability to unseen pose, expression and lighting.
* SIGGRAPH Asia 2024 Conference Paper. Project page: https://kelianb.github.io/SPARK/
Re-Thinking Inverse Graphics With Large Language Models
Apr 23, 2024



Inverse graphics -- the task of inverting an image into physical variables that, when rendered, enable reproduction of the observed scene -- is a fundamental challenge in computer vision and graphics. Disentangling an image into its constituent elements, such as the shape, color, and material properties of the objects of the 3D scene that produced it, requires a comprehensive understanding of the environment. This requirement limits the ability of existing carefully engineered approaches to generalize across domains. Inspired by the zero-shot ability of large language models (LLMs) to generalize to novel contexts, we investigate the possibility of leveraging the broad world knowledge encoded in such models in solving inverse-graphics problems. To this end, we propose the Inverse-Graphics Large Language Model (IG-LLM), an inverse-graphics framework centered around an LLM, that autoregressively decodes a visual embedding into a structured, compositional 3D-scene representation. We incorporate a frozen pre-trained visual encoder and a continuous numeric head to enable end-to-end training. Through our investigation, we demonstrate the potential of LLMs to facilitate inverse graphics through next-token prediction, without the use of image-space supervision. Our analysis opens up new possibilities for precise spatial reasoning about images that exploit the visual knowledge of LLMs. We will release our code and data to ensure the reproducibility of our investigation and to facilitate future research at https://ig-llm.is.tue.mpg.de/
Explorative Inbetweening of Time and Space
Mar 21, 2024



We introduce bounded generation as a generalized task to control video generation to synthesize arbitrary camera and subject motion based only on a given start and end frame. Our objective is to fully leverage the inherent generalization capability of an image-to-video model without additional training or fine-tuning of the original model. This is achieved through the proposed new sampling strategy, which we call Time Reversal Fusion, that fuses the temporally forward and backward denoising paths conditioned on the start and end frame, respectively. The fused path results in a video that smoothly connects the two frames, generating inbetweening of faithful subject motion, novel views of static scenes, and seamless video looping when the two bounding frames are identical. We curate a diverse evaluation dataset of image pairs and compare against the closest existing methods. We find that Time Reversal Fusion outperforms related work on all subtasks, exhibiting the ability to generate complex motions and 3D-consistent views guided by bounded frames. See project page at https://time-reversal.github.io.
Adversarial Likelihood Estimation with One-way Flows
Jul 19, 2023



Generative Adversarial Networks (GANs) can produce high-quality samples, but do not provide an estimate of the probability density around the samples. However, it has been noted that maximizing the log-likelihood within an energy-based setting can lead to an adversarial framework where the discriminator provides unnormalized density (often called energy). We further develop this perspective, incorporate importance sampling, and show that 1) Wasserstein GAN performs a biased estimate of the partition function, and we propose instead to use an unbiased estimator; 2) when optimizing for likelihood, one must maximize generator entropy. This is hypothesized to provide a better mode coverage. Different from previous works, we explicitly compute the density of the generated samples. This is the key enabler to designing an unbiased estimator of the partition function and computation of the generator entropy term. The generator density is obtained via a new type of flow network, called one-way flow network, that is less constrained in terms of architecture, as it does not require to have a tractable inverse function. Our experimental results show that we converge faster, produce comparable sample quality to GANs with similar architecture, successfully avoid over-fitting to commonly used datasets and produce smooth low-dimensional latent representations of the training data.
Generalizing Neural Human Fitting to Unseen Poses With Articulated SE(3) Equivariance
Apr 20, 2023

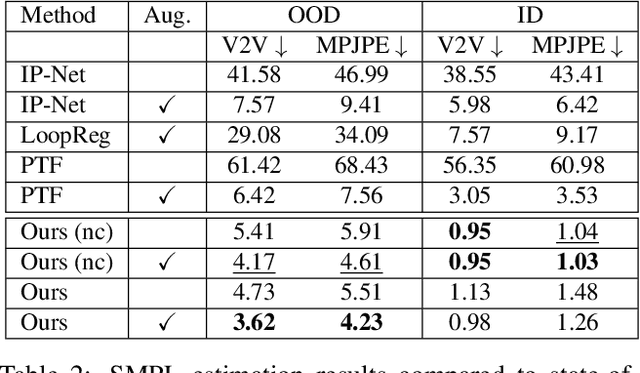

We address the problem of fitting a parametric human body model (SMPL) to point cloud data. Optimization-based methods require careful initialization and are prone to becoming trapped in local optima. Learning-based methods address this but do not generalize well when the input pose is far from those seen during training. For rigid point clouds, remarkable generalization has been achieved by leveraging SE(3)-equivariant networks, but these methods do not work on articulated objects. In this work we extend this idea to human bodies and propose ArtEq, a novel part-based SE(3)-equivariant neural architecture for SMPL model estimation from point clouds. Specifically, we learn a part detection network by leveraging local SO(3) invariance, and regress shape and pose using articulated SE(3) shape-invariant and pose-equivariant networks, all trained end-to-end. Our novel equivariant pose regression module leverages the permutation-equivariant property of self-attention layers to preserve rotational equivariance. Experimental results show that ArtEq can generalize to poses not seen during training, outperforming state-of-the-art methods by 74.5%, without requiring an optimization refinement step. Further, compared with competing works, our method is more than three orders of magnitude faster during inference and has 97.3% fewer parameters. The code and model will be available for research purposes at https://arteq.is.tue.mpg.de.
Towards Racially Unbiased Skin Tone Estimation via Scene Disambiguation
May 08, 2022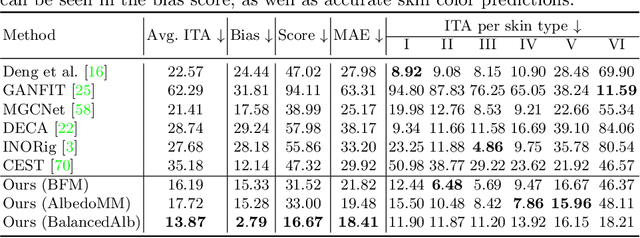
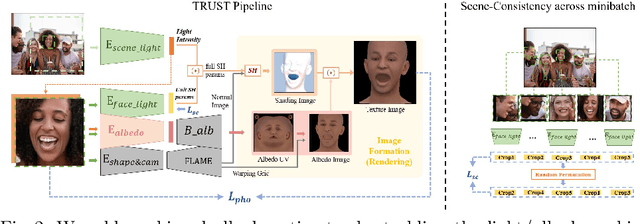
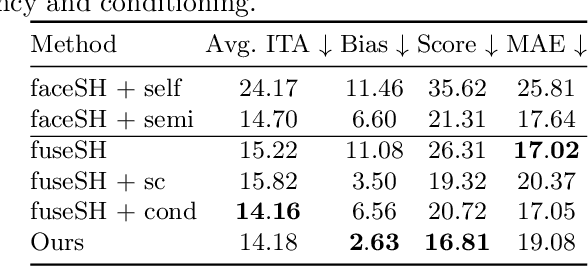

Virtual facial avatars will play an increasingly important role in immersive communication, games and the metaverse, and it is therefore critical that they be inclusive. This requires accurate recovery of the appearance, represented by albedo, regardless of age, sex, or ethnicity. While significant progress has been made on estimating 3D facial geometry, albedo estimation has received less attention. The task is fundamentally ambiguous because the observed color is a function of albedo and lighting, both of which are unknown. We find that current methods are biased towards light skin tones due to (1) strongly biased priors that prefer lighter pigmentation and (2) algorithmic solutions that disregard the light/albedo ambiguity. To address this, we propose a new evaluation dataset (FAIR) and an algorithm (TRUST) to improve albedo estimation and, hence, fairness. Specifically, we create the first facial albedo evaluation benchmark where subjects are balanced in terms of skin color, and measure accuracy using the Individual Typology Angle (ITA) metric. We then address the light/albedo ambiguity by building on a key observation: the image of the full scene -- as opposed to a cropped image of the face -- contains important information about lighting that can be used for disambiguation. TRUST regresses facial albedo by conditioning both on the face region and a global illumination signal obtained from the scene image. Our experimental results show significant improvement compared to state-of-the-art methods on albedo estimation, both in terms of accuracy and fairness. The evaluation benchmark and code will be made available for research purposes at https://trust.is.tue.mpg.de.