 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet
May 28, 2026We demonstrate that sparse autoencoders can extract interpretable features from Claude 3 Sonnet, a production-scale language model, addressing the open question of whether dictionary learning methods scale beyond small transformers. We trained sparse autoencoders with up to 34 million features on the model's middle layer residual stream, using scaling laws to guide hyperparameter selection. The resulting features are multilingual and multimodal (generalizing to images despite text-only training), respond to both concrete instances and abstract discussions of concepts, and can be used to steer model behavior in ways consistent with their interpretations. We find features corresponding to famous entities and locations, as well as more abstract concepts like sarcasm or errors in code. We also identify features relevant to ways in which language models might cause harm--including features representing deception, power-seeking, sycophancy, and bias--and show that these causally influence model outputs when manipulated. Additionally, we conduct analyses of feature interpretability, geometry, and computational function. However, significant limitations remain: our suite of features is incomplete, and we lack rigorous methods for evaluating whether our features faithfully capture model computations.
Clio: Privacy-Preserving Insights into Real-World AI Use
Dec 18, 2024How are AI assistants being used in the real world? While model providers in theory have a window into this impact via their users' data, both privacy concerns and practical challenges have made analyzing this data difficult. To address these issues, we present Clio (Claude insights and observations), a privacy-preserving platform that uses AI assistants themselves to analyze and surface aggregated usage patterns across millions of conversations, without the need for human reviewers to read raw conversations. We validate this can be done with a high degree of accuracy and privacy by conducting extensive evaluations. We demonstrate Clio's usefulness in two broad ways. First, we share insights about how models are being used in the real world from one million Claude.ai Free and Pro conversations, ranging from providing advice on hairstyles to providing guidance on Git operations and concepts. We also identify the most common high-level use cases on Claude.ai (coding, writing, and research tasks) as well as patterns that differ across languages (e.g., conversations in Japanese discuss elder care and aging populations at higher-than-typical rates). Second, we use Clio to make our systems safer by identifying coordinated attempts to abuse our systems, monitoring for unknown unknowns during critical periods like launches of new capabilities or major world events, and improving our existing monitoring systems. We also discuss the limitations of our approach, as well as risks and ethical concerns. By enabling analysis of real-world AI usage, Clio provides a scalable platform for empirically grounded AI safety and governance.
Rational Metareasoning for Large Language Models
Oct 07, 2024



Being prompted to engage in reasoning has emerged as a core technique for using large language models (LLMs), deploying additional inference-time compute to improve task performance. However, as LLMs increase in both size and adoption, inference costs are correspondingly becoming increasingly burdensome. How, then, might we optimize reasoning's cost-performance tradeoff? This work introduces a novel approach based on computational models of metareasoning used in cognitive science, training LLMs to selectively use intermediate reasoning steps only when necessary. We first develop a reward function that incorporates the Value of Computation by penalizing unnecessary reasoning, then use this reward function with Expert Iteration to train the LLM. Compared to few-shot chain-of-thought prompting and STaR, our method significantly reduces inference costs (20-37\% fewer tokens generated across three models) while maintaining task performance across diverse datasets.
Representational Alignment Supports Effective Machine Teaching
Jun 06, 2024



A good teacher should not only be knowledgeable; but should be able to communicate in a way that the student understands -- to share the student's representation of the world. In this work, we integrate insights from machine teaching and pragmatic communication with the burgeoning literature on representational alignment to characterize a utility curve defining a relationship between representational alignment and teacher capability for promoting student learning. To explore the characteristics of this utility curve, we design a supervised learning environment that disentangles representational alignment from teacher accuracy. We conduct extensive computational experiments with machines teaching machines, complemented by a series of experiments in which machines teach humans. Drawing on our findings that improved representational alignment with a student improves student learning outcomes (i.e., task accuracy), we design a classroom matching procedure that assigns students to teachers based on the utility curve. If we are to design effective machine teachers, it is not enough to build teachers that are accurate -- we want teachers that can align, representationally, to their students too.
Learning with Language-Guided State Abstractions
Mar 06, 2024We describe a framework for using natural language to design state abstractions for imitation learning. Generalizable policy learning in high-dimensional observation spaces is facilitated by well-designed state representations, which can surface important features of an environment and hide irrelevant ones. These state representations are typically manually specified, or derived from other labor-intensive labeling procedures. Our method, LGA (language-guided abstraction), uses a combination of natural language supervision and background knowledge from language models (LMs) to automatically build state representations tailored to unseen tasks. In LGA, a user first provides a (possibly incomplete) description of a target task in natural language; next, a pre-trained LM translates this task description into a state abstraction function that masks out irrelevant features; finally, an imitation policy is trained using a small number of demonstrations and LGA-generated abstract states. Experiments on simulated robotic tasks show that LGA yields state abstractions similar to those designed by humans, but in a fraction of the time, and that these abstractions improve generalization and robustness in the presence of spurious correlations and ambiguous specifications. We illustrate the utility of the learned abstractions on mobile manipulation tasks with a Spot robot.
How do Large Language Models Navigate Conflicts between Honesty and Helpfulness?
Feb 13, 2024In day-to-day communication, people often approximate the truth - for example, rounding the time or omitting details - in order to be maximally helpful to the listener. How do large language models (LLMs) handle such nuanced trade-offs? To address this question, we use psychological models and experiments designed to characterize human behavior to analyze LLMs. We test a range of LLMs and explore how optimization for human preferences or inference-time reasoning affects these trade-offs. We find that reinforcement learning from human feedback improves both honesty and helpfulness, while chain-of-thought prompting skews LLMs towards helpfulness over honesty. Finally, GPT-4 Turbo demonstrates human-like response patterns including sensitivity to the conversational framing and listener's decision context. Our findings reveal the conversational values internalized by LLMs and suggest that even these abstract values can, to a degree, be steered by zero-shot prompting.
Preference-Conditioned Language-Guided Abstraction
Feb 05, 2024



Learning from demonstrations is a common way for users to teach robots, but it is prone to spurious feature correlations. Recent work constructs state abstractions, i.e. visual representations containing task-relevant features, from language as a way to perform more generalizable learning. However, these abstractions also depend on a user's preference for what matters in a task, which may be hard to describe or infeasible to exhaustively specify using language alone. How do we construct abstractions to capture these latent preferences? We observe that how humans behave reveals how they see the world. Our key insight is that changes in human behavior inform us that there are differences in preferences for how humans see the world, i.e. their state abstractions. In this work, we propose using language models (LMs) to query for those preferences directly given knowledge that a change in behavior has occurred. In our framework, we use the LM in two ways: first, given a text description of the task and knowledge of behavioral change between states, we query the LM for possible hidden preferences; second, given the most likely preference, we query the LM to construct the state abstraction. In this framework, the LM is also able to ask the human directly when uncertain about its own estimate. We demonstrate our framework's ability to construct effective preference-conditioned abstractions in simulated experiments, a user study, as well as on a real Spot robot performing mobile manipulation tasks.
Deep de Finetti: Recovering Topic Distributions from Large Language Models
Dec 21, 2023Large language models (LLMs) can produce long, coherent passages of text, suggesting that LLMs, although trained on next-word prediction, must represent the latent structure that characterizes a document. Prior work has found that internal representations of LLMs encode one aspect of latent structure, namely syntax; here we investigate a complementary aspect, namely the document's topic structure. We motivate the hypothesis that LLMs capture topic structure by connecting LLM optimization to implicit Bayesian inference. De Finetti's theorem shows that exchangeable probability distributions can be represented as a mixture with respect to a latent generating distribution. Although text is not exchangeable at the level of syntax, exchangeability is a reasonable starting assumption for topic structure. We thus hypothesize that predicting the next token in text will lead LLMs to recover latent topic distributions. We examine this hypothesis using Latent Dirichlet Allocation (LDA), an exchangeable probabilistic topic model, as a target, and we show that the representations formed by LLMs encode both the topics used to generate synthetic data and those used to explain natural corpus data.
Words are all you need? Capturing human sensory similarity with textual descriptors
Jun 15, 2022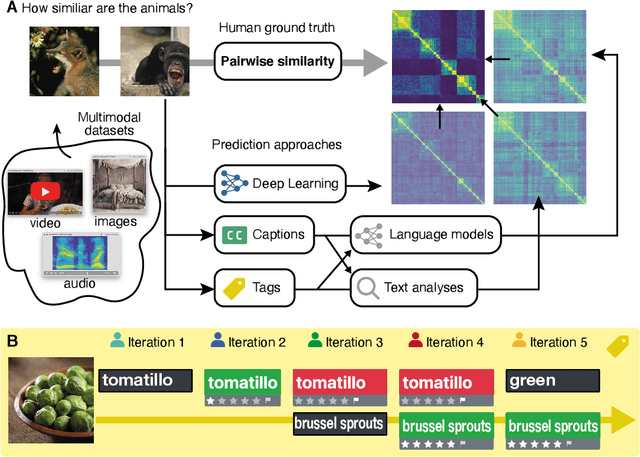
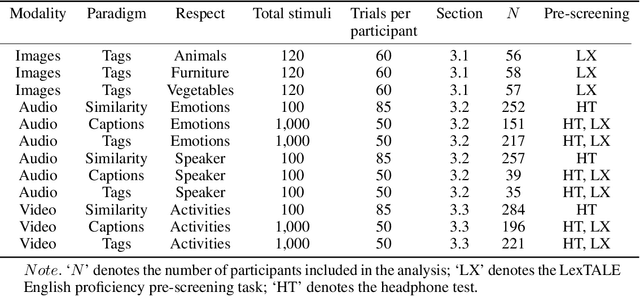

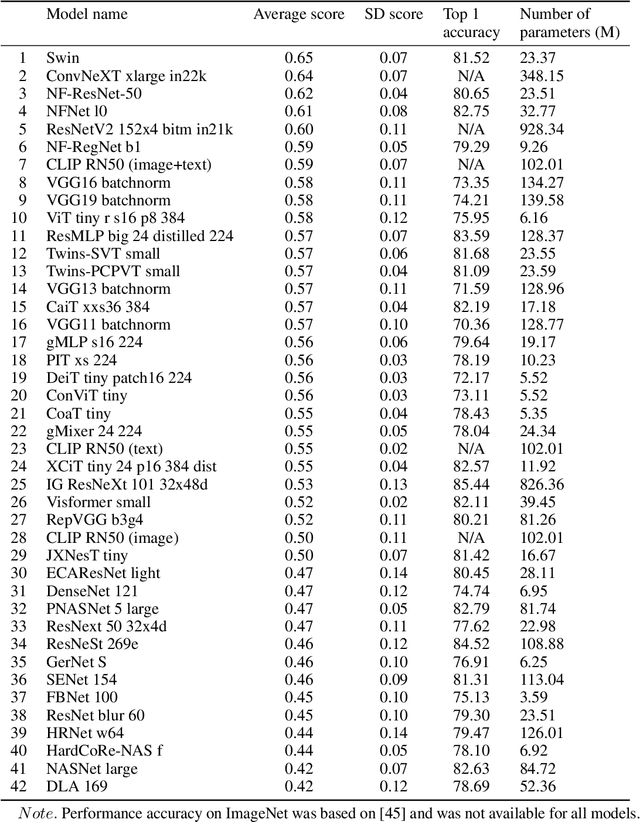
Recent advances in multimodal training use textual descriptions to significantly enhance machine understanding of images and videos. Yet, it remains unclear to what extent language can fully capture sensory experiences across different modalities. A well-established approach for characterizing sensory experiences relies on similarity judgments, namely, the degree to which people perceive two distinct stimuli as similar. We explore the relation between human similarity judgments and language in a series of large-scale behavioral studies ($N=1,823$ participants) across three modalities (images, audio, and video) and two types of text descriptors: simple word tags and free-text captions. In doing so, we introduce a novel adaptive pipeline for tag mining that is both efficient and domain-general. We show that our prediction pipeline based on text descriptors exhibits excellent performance, and we compare it against a comprehensive array of 611 baseline models based on vision-, audio-, and video-processing architectures. We further show that the degree to which textual descriptors and models predict human similarity varies across and within modalities. Taken together, these studies illustrate the value of integrating machine learning and cognitive science approaches to better understand the similarities and differences between human and machine representations. We present an interactive visualization at https://words-are-all-you-need.s3.amazonaws.com/index.html for exploring the similarity between stimuli as experienced by humans and different methods reported in the paper.
Linguistic communication as (inverse) reward design
Apr 11, 2022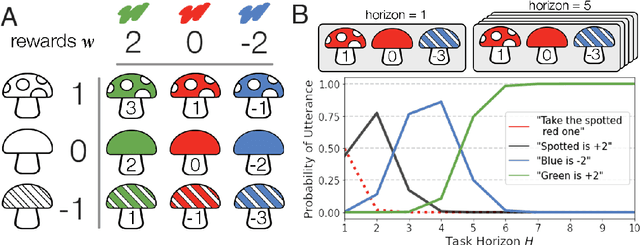
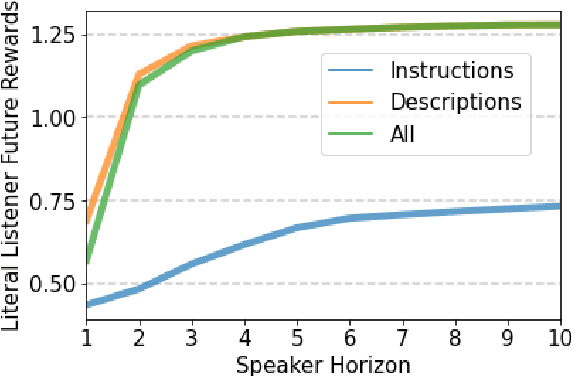
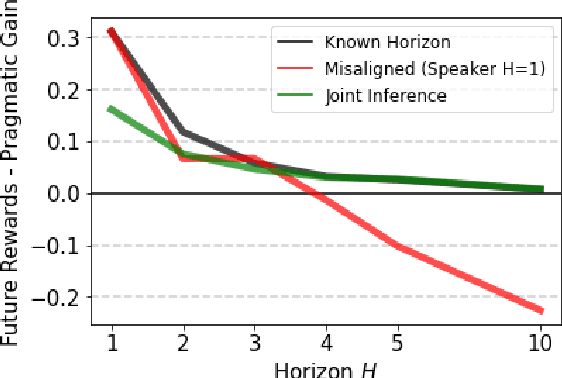
Natural language is an intuitive and expressive way to communicate reward information to autonomous agents. It encompasses everything from concrete instructions to abstract descriptions of the world. Despite this, natural language is often challenging to learn from: it is difficult for machine learning methods to make appropriate inferences from such a wide range of input. This paper proposes a generalization of reward design as a unifying principle to ground linguistic communication: speakers choose utterances to maximize expected rewards from the listener's future behaviors. We first extend reward design to incorporate reasoning about unknown future states in a linear bandit setting. We then define a speaker model which chooses utterances according to this objective. Simulations show that short-horizon speakers (reasoning primarily about a single, known state) tend to use instructions, while long-horizon speakers (reasoning primarily about unknown, future states) tend to describe the reward function. We then define a pragmatic listener which performs inverse reward design by jointly inferring the speaker's latent horizon and rewards. Our findings suggest that this extension of reward design to linguistic communication, including the notion of a latent speaker horizon, is a promising direction for achieving more robust alignment outcomes from natural language supervision.