 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrickNet: Graph-Backed Generative Brick Assembly
Apr 24, 2026We train a language model to generate LEGO-brick build sequences. While prior work has been restricted to discrete, voxel-like towers, we consider a much broader set of pieces, encompassing thousands of part types with diverse connection semantics. To enable this, we first collect a large-scale dataset of over 100,000 human-designed LDraw brick objects and scenes. The complexity of our setting makes it challenging to autoregressively assemble structures that satisfy physical constraints. When predicting block pose directly, build sequences quickly become invalid after a small number of steps. Although pieces are placed in 3D space, it is the spatial relationships of the parts which define the whole. With this in mind, we design a graph-based program representation that parametrizes structure through connectivity, improving the physical grounding of generated sequences. To enable future applications, we make our dataset and models available for research purposes. https://kulits.github.io/BrickNet
Generative Zoo
Dec 11, 2024



The model-based estimation of 3D animal pose and shape from images enables computational modeling of animal behavior. Training models for this purpose requires large amounts of labeled image data with precise pose and shape annotations. However, capturing such data requires the use of multi-view or marker-based motion-capture systems, which are impractical to adapt to wild animals in situ and impossible to scale across a comprehensive set of animal species. Some have attempted to address the challenge of procuring training data by pseudo-labeling individual real-world images through manual 2D annotation, followed by 3D-parameter optimization to those labels. While this approach may produce silhouette-aligned samples, the obtained pose and shape parameters are often implausible due to the ill-posed nature of the monocular fitting problem. Sidestepping real-world ambiguity, others have designed complex synthetic-data-generation pipelines leveraging video-game engines and collections of artist-designed 3D assets. Such engines yield perfect ground-truth annotations but are often lacking in visual realism and require considerable manual effort to adapt to new species or environments. Motivated by these shortcomings, we propose an alternative approach to synthetic-data generation: rendering with a conditional image-generation model. We introduce a pipeline that samples a diverse set of poses and shapes for a variety of mammalian quadrupeds and generates realistic images with corresponding ground-truth pose and shape parameters. To demonstrate the scalability of our approach, we introduce GenZoo, a synthetic dataset containing one million images of distinct subjects. We train a 3D pose and shape regressor on GenZoo, which achieves state-of-the-art performance on a real-world animal pose and shape estimation benchmark, despite being trained solely on synthetic data. https://genzoo.is.tue.mpg.de
Reconstructing Animals and the Wild
Nov 27, 2024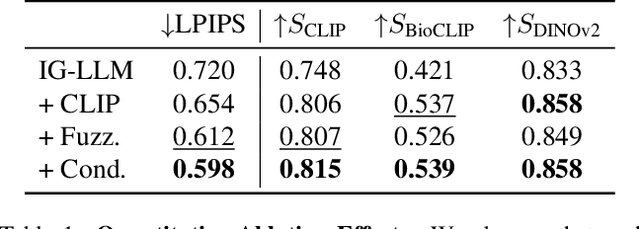



The idea of 3D reconstruction as scene understanding is foundational in computer vision. Reconstructing 3D scenes from 2D visual observations requires strong priors to disambiguate structure. Much work has been focused on the anthropocentric, which, characterized by smooth surfaces, coherent normals, and regular edges, allows for the integration of strong geometric inductive biases. Here, we consider a more challenging problem where such assumptions do not hold: the reconstruction of natural scenes containing trees, bushes, boulders, and animals. While numerous works have attempted to tackle the problem of reconstructing animals in the wild, they have focused solely on the animal, neglecting environmental context. This limits their usefulness for analysis tasks, as animals exist inherently within the 3D world, and information is lost when environmental factors are disregarded. We propose a method to reconstruct natural scenes from single images. We base our approach on recent advances leveraging the strong world priors ingrained in Large Language Models and train an autoregressive model to decode a CLIP embedding into a structured compositional scene representation, encompassing both animals and the wild (RAW). To enable this, we propose a synthetic dataset comprising one million images and thousands of assets. Our approach, having been trained solely on synthetic data, generalizes to the task of reconstructing animals and their environments in real-world images. We will release our dataset and code to encourage future research at https://raw.is.tue.mpg.de/
Re-Thinking Inverse Graphics With Large Language Models
Apr 23, 2024



Inverse graphics -- the task of inverting an image into physical variables that, when rendered, enable reproduction of the observed scene -- is a fundamental challenge in computer vision and graphics. Disentangling an image into its constituent elements, such as the shape, color, and material properties of the objects of the 3D scene that produced it, requires a comprehensive understanding of the environment. This requirement limits the ability of existing carefully engineered approaches to generalize across domains. Inspired by the zero-shot ability of large language models (LLMs) to generalize to novel contexts, we investigate the possibility of leveraging the broad world knowledge encoded in such models in solving inverse-graphics problems. To this end, we propose the Inverse-Graphics Large Language Model (IG-LLM), an inverse-graphics framework centered around an LLM, that autoregressively decodes a visual embedding into a structured, compositional 3D-scene representation. We incorporate a frozen pre-trained visual encoder and a continuous numeric head to enable end-to-end training. Through our investigation, we demonstrate the potential of LLMs to facilitate inverse graphics through next-token prediction, without the use of image-space supervision. Our analysis opens up new possibilities for precise spatial reasoning about images that exploit the visual knowledge of LLMs. We will release our code and data to ensure the reproducibility of our investigation and to facilitate future research at https://ig-llm.is.tue.mpg.de/
Text-Guided Generation and Editing of Compositional 3D Avatars
Sep 13, 2023



Our goal is to create a realistic 3D facial avatar with hair and accessories using only a text description. While this challenge has attracted significant recent interest, existing methods either lack realism, produce unrealistic shapes, or do not support editing, such as modifications to the hairstyle. We argue that existing methods are limited because they employ a monolithic modeling approach, using a single representation for the head, face, hair, and accessories. Our observation is that the hair and face, for example, have very different structural qualities that benefit from different representations. Building on this insight, we generate avatars with a compositional model, in which the head, face, and upper body are represented with traditional 3D meshes, and the hair, clothing, and accessories with neural radiance fields (NeRF). The model-based mesh representation provides a strong geometric prior for the face region, improving realism while enabling editing of the person's appearance. By using NeRFs to represent the remaining components, our method is able to model and synthesize parts with complex geometry and appearance, such as curly hair and fluffy scarves. Our novel system synthesizes these high-quality compositional avatars from text descriptions. The experimental results demonstrate that our method, Text-guided generation and Editing of Compositional Avatars (TECA), produces avatars that are more realistic than those of recent methods while being editable because of their compositional nature. For example, our TECA enables the seamless transfer of compositional features like hairstyles, scarves, and other accessories between avatars. This capability supports applications such as virtual try-on.
Reconstructing Signing Avatars From Video Using Linguistic Priors
Apr 20, 2023



Sign language (SL) is the primary method of communication for the 70 million Deaf people around the world. Video dictionaries of isolated signs are a core SL learning tool. Replacing these with 3D avatars can aid learning and enable AR/VR applications, improving access to technology and online media. However, little work has attempted to estimate expressive 3D avatars from SL video; occlusion, noise, and motion blur make this task difficult. We address this by introducing novel linguistic priors that are universally applicable to SL and provide constraints on 3D hand pose that help resolve ambiguities within isolated signs. Our method, SGNify, captures fine-grained hand pose, facial expression, and body movement fully automatically from in-the-wild monocular SL videos. We evaluate SGNify quantitatively by using a commercial motion-capture system to compute 3D avatars synchronized with monocular video. SGNify outperforms state-of-the-art 3D body-pose- and shape-estimation methods on SL videos. A perceptual study shows that SGNify's 3D reconstructions are significantly more comprehensible and natural than those of previous methods and are on par with the source videos. Code and data are available at $\href{http://sgnify.is.tue.mpg.de}{\text{sgnify.is.tue.mpg.de}}$.
Generalizing Neural Human Fitting to Unseen Poses With Articulated SE(3) Equivariance
Apr 20, 2023

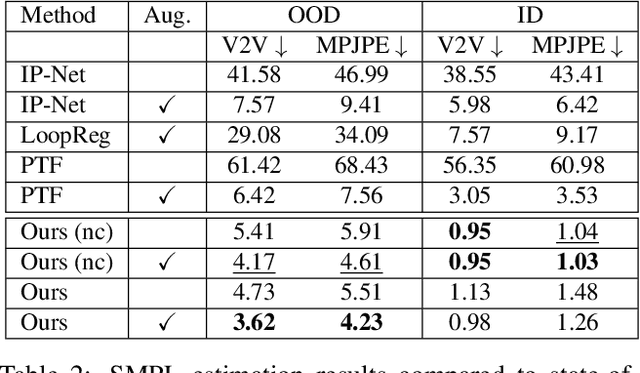

We address the problem of fitting a parametric human body model (SMPL) to point cloud data. Optimization-based methods require careful initialization and are prone to becoming trapped in local optima. Learning-based methods address this but do not generalize well when the input pose is far from those seen during training. For rigid point clouds, remarkable generalization has been achieved by leveraging SE(3)-equivariant networks, but these methods do not work on articulated objects. In this work we extend this idea to human bodies and propose ArtEq, a novel part-based SE(3)-equivariant neural architecture for SMPL model estimation from point clouds. Specifically, we learn a part detection network by leveraging local SO(3) invariance, and regress shape and pose using articulated SE(3) shape-invariant and pose-equivariant networks, all trained end-to-end. Our novel equivariant pose regression module leverages the permutation-equivariant property of self-attention layers to preserve rotational equivariance. Experimental results show that ArtEq can generalize to poses not seen during training, outperforming state-of-the-art methods by 74.5%, without requiring an optimization refinement step. Further, compared with competing works, our method is more than three orders of magnitude faster during inference and has 97.3% fewer parameters. The code and model will be available for research purposes at https://arteq.is.tue.mpg.de.
The Caltech Fish Counting Dataset: A Benchmark for Multiple-Object Tracking and Counting
Jul 19, 2022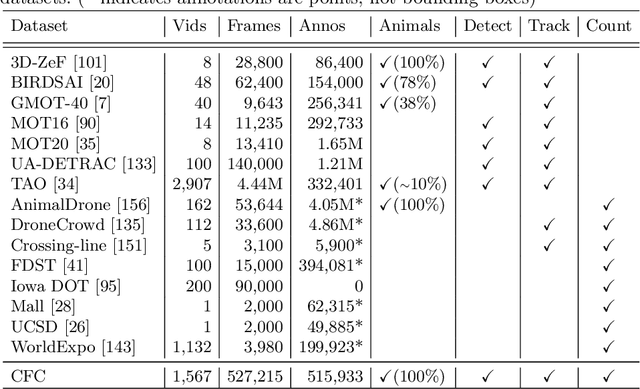
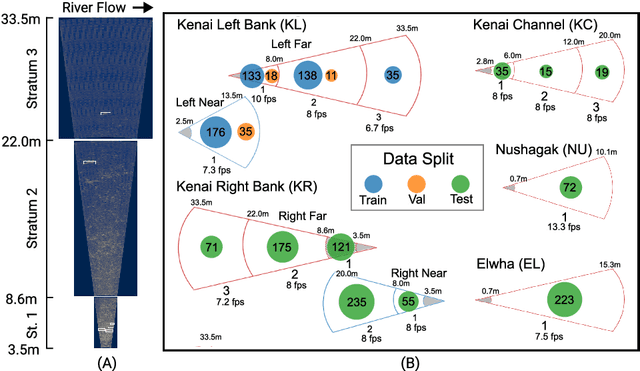
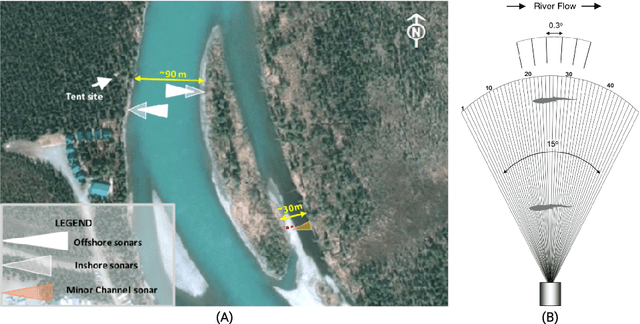

We present the Caltech Fish Counting Dataset (CFC), a large-scale dataset for detecting, tracking, and counting fish in sonar videos. We identify sonar videos as a rich source of data for advancing low signal-to-noise computer vision applications and tackling domain generalization in multiple-object tracking (MOT) and counting. In comparison to existing MOT and counting datasets, which are largely restricted to videos of people and vehicles in cities, CFC is sourced from a natural-world domain where targets are not easily resolvable and appearance features cannot be easily leveraged for target re-identification. With over half a million annotations in over 1,500 videos sourced from seven different sonar cameras, CFC allows researchers to train MOT and counting algorithms and evaluate generalization performance at unseen test locations. We perform extensive baseline experiments and identify key challenges and opportunities for advancing the state of the art in generalization in MOT and counting.
ElephantBook: A Semi-Automated Human-in-the-Loop System for Elephant Re-Identification
Jun 30, 2021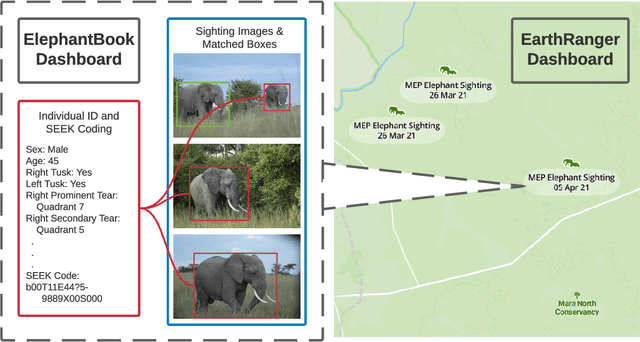
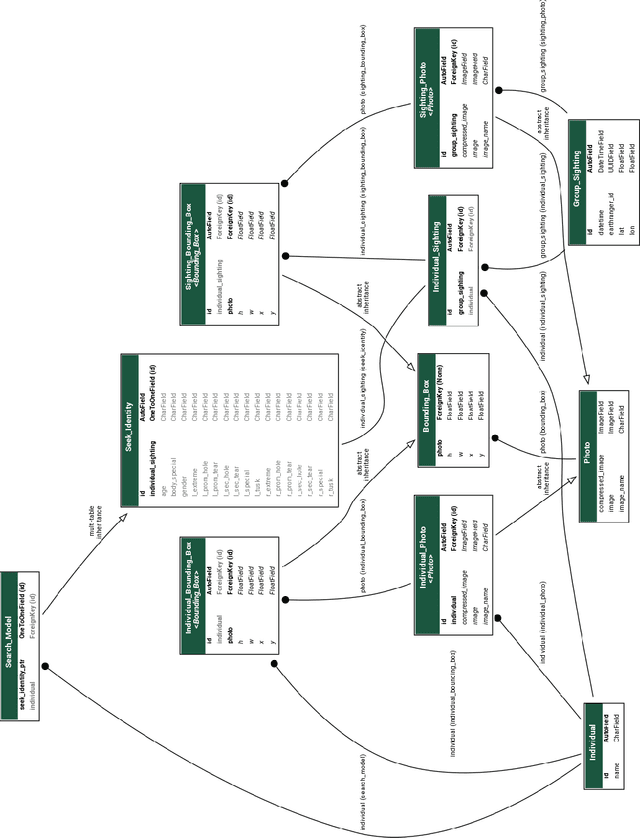
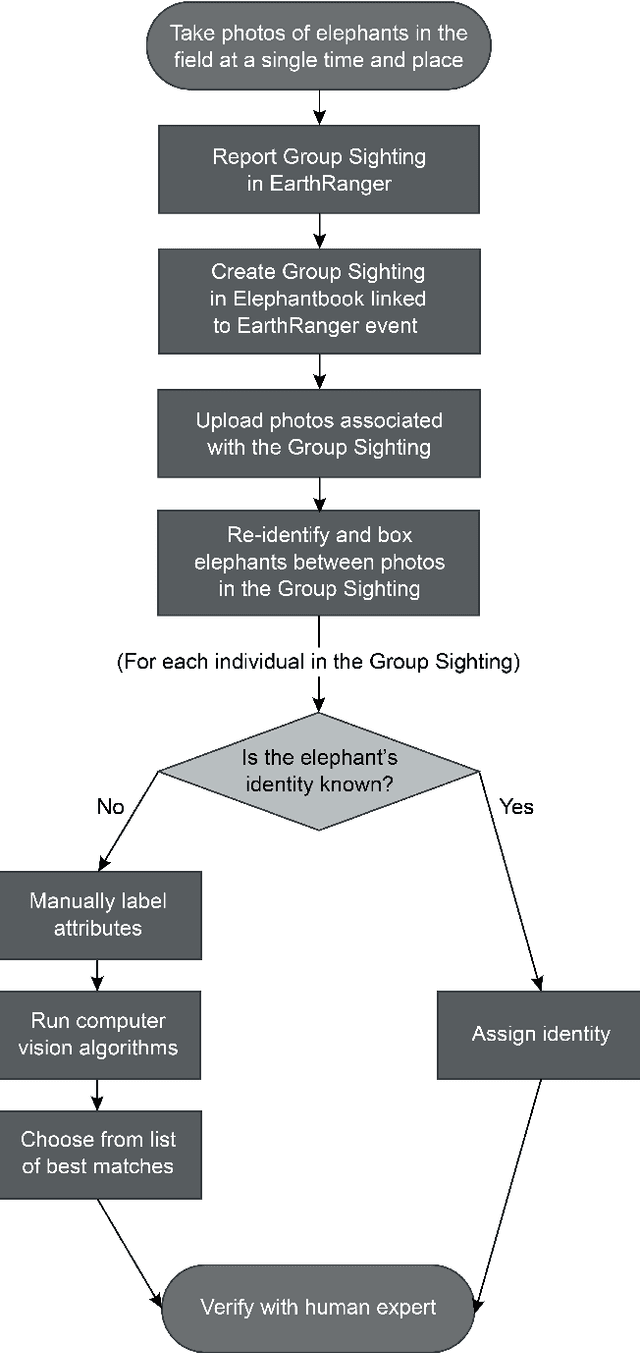

African elephants are vital to their ecosystems, but their populations are threatened by a rise in human-elephant conflict and poaching. Monitoring population dynamics is essential in conservation efforts; however, tracking elephants is a difficult task, usually relying on the invasive and sometimes dangerous placement of GPS collars. Although there have been many recent successes in the use of computer vision techniques for automated identification of other species, identification of elephants is extremely difficult and typically requires expertise as well as familiarity with elephants in the population. We have built and deployed a web-based platform and database for human-in-the-loop re-identification of elephants combining manual attribute labeling and state-of-the-art computer vision algorithms, known as ElephantBook. Our system is currently in use at the Mara Elephant Project, helping monitor the protected and at-risk population of elephants in the Greater Maasai Mara ecosystem. ElephantBook makes elephant re-identification usable by non-experts and scalable for use by multiple conservation NGOs.
Generalized Unsupervised Clustering of Hyperspectral Images of Geological Targets in the Near Infrared
Jun 24, 2021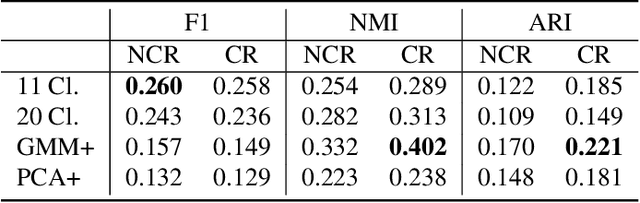

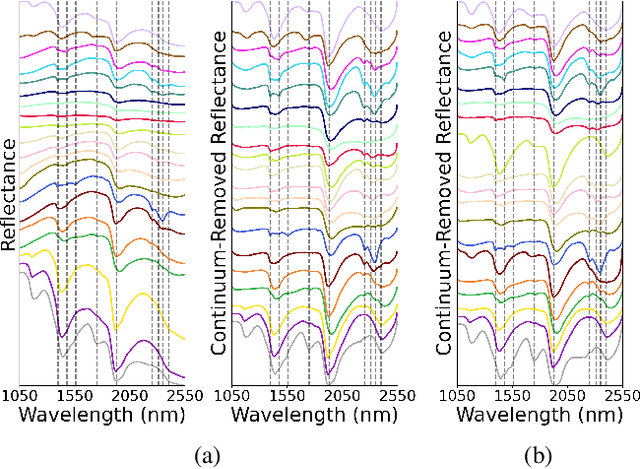
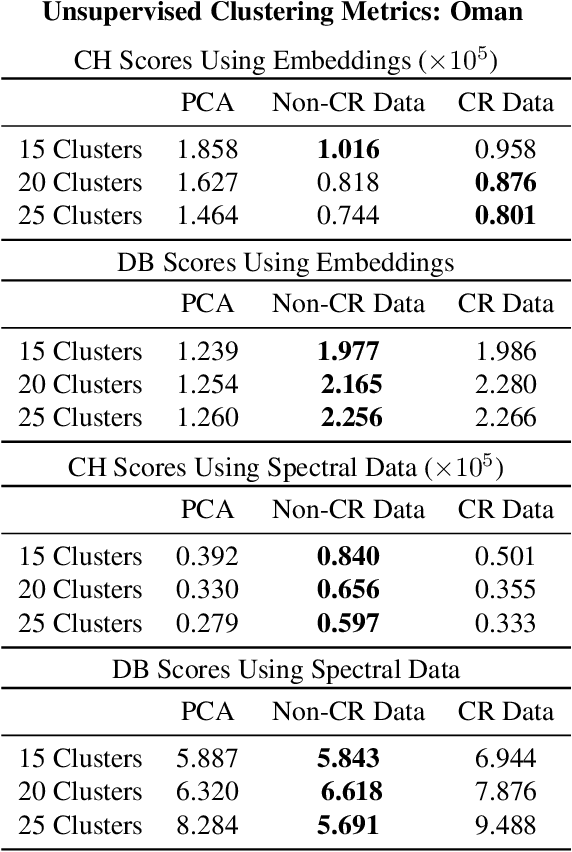
The application of infrared hyperspectral imagery to geological problems is becoming more popular as data become more accessible and cost-effective. Clustering and classifying spectrally similar materials is often a first step in applications ranging from economic mineral exploration on Earth to planetary exploration on Mars. Semi-manual classification guided by expertly developed spectral parameters can be time consuming and biased, while supervised methods require abundant labeled data and can be difficult to generalize. Here we develop a fully unsupervised workflow for feature extraction and clustering informed by both expert spectral geologist input and quantitative metrics. Our pipeline uses a lightweight autoencoder followed by Gaussian mixture modeling to map the spectral diversity within any image. We validate the performance of our pipeline at submillimeter-scale with expert-labelled data from the Oman ophiolite drill core and evaluate performance at meters-scale with partially classified orbital data of Jezero Crater on Mars (the landing site for the Perseverance rover). We additionally examine the effects of various preprocessing techniques used in traditional analysis of hyperspectral imagery. This pipeline provides a fast and accurate clustering map of similar geological materials and consistently identifies and separates major mineral classes in both laboratory imagery and remote sensing imagery. We refer to our pipeline as "Generalized Pipeline for Spectroscopic Unsupervised clustering of Minerals (GyPSUM)."