 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowInOne:Unifying Multimodal Generation as Image-in, Image-out Flow Matching
Apr 08, 2026Multimodal generation has long been dominated by text-driven pipelines where language dictates vision but cannot reason or create within it. We challenge this paradigm by asking whether all modalities, including textual descriptions, spatial layouts, and editing instructions, can be unified into a single visual representation. We present FlowInOne, a framework that reformulates multimodal generation as a purely visual flow, converting all inputs into visual prompts and enabling a clean image-in, image-out pipeline governed by a single flow matching model. This vision-centric formulation naturally eliminates cross-modal alignment bottlenecks, noise scheduling, and task-specific architectural branches, unifying text-to-image generation, layout-guided editing, and visual instruction following under one coherent paradigm. To support this, we introduce VisPrompt-5M, a large-scale dataset of 5 million visual prompt pairs spanning diverse tasks including physics-aware force dynamics and trajectory prediction, alongside VP-Bench, a rigorously curated benchmark assessing instruction faithfulness, spatial precision, visual realism, and content consistency. Extensive experiments demonstrate that FlowInOne achieves state-of-the-art performance across all unified generation tasks, surpassing both open-source models and competitive commercial systems, establishing a new foundation for fully vision-centric generative modeling where perception and creation coexist within a single continuous visual space.
The Scalability of Simplicity: Empirical Analysis of Vision-Language Learning with a Single Transformer
Apr 14, 2025



This paper introduces SAIL, a single transformer unified multimodal large language model (MLLM) that integrates raw pixel encoding and language decoding within a singular architecture. Unlike existing modular MLLMs, which rely on a pre-trained vision transformer (ViT), SAIL eliminates the need for a separate vision encoder, presenting a more minimalist architecture design. Instead of introducing novel architectural components, SAIL adapts mix-attention mechanisms and multimodal positional encodings to better align with the distinct characteristics of visual and textual modalities. We systematically compare SAIL's properties-including scalability, cross-modal information flow patterns, and visual representation capabilities-with those of modular MLLMs. By scaling both training data and model size, SAIL achieves performance comparable to modular MLLMs. Notably, the removal of pretrained ViT components enhances SAIL's scalability and results in significantly different cross-modal information flow patterns. Moreover, SAIL demonstrates strong visual representation capabilities, achieving results on par with ViT-22B in vision tasks such as semantic segmentation. Code and models are available at https://github.com/bytedance/SAIL.
Pixel-SAIL: Single Transformer For Pixel-Grounded Understanding
Apr 14, 2025



Multimodal Large Language Models (MLLMs) achieve remarkable performance for fine-grained pixel-level understanding tasks. However, all the works rely heavily on extra components, such as vision encoder (CLIP), segmentation experts, leading to high system complexity and limiting model scaling. In this work, our goal is to explore a highly simplified MLLM without introducing extra components. Our work is motivated by the recent works on Single trAnsformer as a unified vIsion-Language Model (SAIL) design, where these works jointly learn vision tokens and text tokens in transformers. We present Pixel-SAIL, a single transformer for pixel-wise MLLM tasks. In particular, we present three technical improvements on the plain baseline. First, we design a learnable upsampling module to refine visual token features. Secondly, we propose a novel visual prompt injection strategy to enable the single transformer to understand visual prompt inputs and benefit from the early fusion of visual prompt embeddings and vision tokens. Thirdly, we introduce a vision expert distillation strategy to efficiently enhance the single transformer's fine-grained feature extraction capability. In addition, we have collected a comprehensive pixel understanding benchmark (PerBench), using a manual check. It includes three tasks: detailed object description, visual prompt-based question answering, and visual-text referring segmentation. Extensive experiments on four referring segmentation benchmarks, one visual prompt benchmark, and our PerBench show that our Pixel-SAIL achieves comparable or even better results with a much simpler pipeline. Code and model will be released at https://github.com/magic-research/Sa2VA.
ShowUI: One Vision-Language-Action Model for GUI Visual Agent
Nov 26, 2024



Building Graphical User Interface (GUI) assistants holds significant promise for enhancing human workflow productivity. While most agents are language-based, relying on closed-source API with text-rich meta-information (e.g., HTML or accessibility tree), they show limitations in perceiving UI visuals as humans do, highlighting the need for GUI visual agents. In this work, we develop a vision-language-action model in digital world, namely ShowUI, which features the following innovations: (i) UI-Guided Visual Token Selection to reduce computational costs by formulating screenshots as an UI connected graph, adaptively identifying their redundant relationship and serve as the criteria for token selection during self-attention blocks; (ii) Interleaved Vision-Language-Action Streaming that flexibly unifies diverse needs within GUI tasks, enabling effective management of visual-action history in navigation or pairing multi-turn query-action sequences per screenshot to enhance training efficiency; (iii) Small-scale High-quality GUI Instruction-following Datasets by careful data curation and employing a resampling strategy to address significant data type imbalances. With above components, ShowUI, a lightweight 2B model using 256K data, achieves a strong 75.1% accuracy in zero-shot screenshot grounding. Its UI-guided token selection further reduces 33% of redundant visual tokens during training and speeds up the performance by 1.4x. Navigation experiments across web Mind2Web, mobile AITW, and online MiniWob environments further underscore the effectiveness and potential of our model in advancing GUI visual agents. The models are available at https://github.com/showlab/ShowUI.
ViT-Lens-2: Gateway to Omni-modal Intelligence
Nov 27, 2023



Aiming to advance AI agents, large foundation models significantly improve reasoning and instruction execution, yet the current focus on vision and language neglects the potential of perceiving diverse modalities in open-world environments. However, the success of data-driven vision and language models is costly or even infeasible to be reproduced for rare modalities. In this paper, we present ViT-Lens-2 that facilitates efficient omni-modal representation learning by perceiving novel modalities with a pretrained ViT and aligning them to a pre-defined space. Specifically, the modality-specific lens is tuned to project any-modal signals to an intermediate embedding space, which are then processed by a strong ViT with pre-trained visual knowledge. The encoded representations are optimized toward aligning with the modal-independent space, pre-defined by off-the-shelf foundation models. ViT-Lens-2 provides a unified solution for representation learning of increasing modalities with two appealing advantages: (i) Unlocking the great potential of pretrained ViTs to novel modalities effectively with efficient data regime; (ii) Enabling emergent downstream capabilities through modality alignment and shared ViT parameters. We tailor ViT-Lens-2 to learn representations for 3D point cloud, depth, audio, tactile and EEG, and set new state-of-the-art results across various understanding tasks, such as zero-shot classification. By seamlessly integrating ViT-Lens-2 into Multimodal Foundation Models, we enable Any-modality to Text and Image Generation in a zero-shot manner. Code and models are available at https://github.com/TencentARC/ViT-Lens.
ViT-Lens: Towards Omni-modal Representations
Aug 20, 2023



Though the success of CLIP-based training recipes in vision-language models, their scalability to more modalities (e.g., 3D, audio, etc.) is limited to large-scale data, which is expensive or even inapplicable for rare modalities. In this paper, we present ViT-Lens that facilitates efficient omni-modal representation learning by perceiving novel modalities with a pretrained ViT and aligning to a pre-defined space. Specifically, the modality-specific lens is tuned to project multimodal signals to the shared embedding space, which are then processed by a strong ViT that carries pre-trained image knowledge. The encoded multimodal representations are optimized toward aligning with the modal-independent space, pre-defined by off-the-shelf foundation models. A well-trained lens with a ViT backbone has the potential to serve as one of these foundation models, supervising the learning of subsequent modalities. ViT-Lens provides a unified solution for representation learning of increasing modalities with two appealing benefits: (i) Exploiting the pretrained ViT across tasks and domains effectively with efficient data regime; (ii) Emergent downstream capabilities of novel modalities are demonstrated due to the modality alignment space. We evaluate ViT-Lens in the context of 3D as an initial verification. In zero-shot 3D classification, ViT-Lens achieves substantial improvements over previous state-of-the-art, showing 52.0% accuracy on Objaverse-LVIS, 87.4% on ModelNet40, and 60.6% on ScanObjectNN. Furthermore, we enable zero-shot 3D question-answering by simply integrating the trained 3D lens into the InstructBLIP model without any adaptation. We will release the results of ViT-Lens on more modalities in the near future.
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
Dec 22, 2022



To reproduce the success of text-to-image (T2I) generation, recent works in text-to-video (T2V) generation employ large-scale text-video dataset for fine-tuning. However, such paradigm is computationally expensive. Humans have the amazing ability to learn new visual concepts from just one single exemplar. We hereby study a new T2V generation problem$\unicode{x2014}$One-Shot Video Generation, where only a single text-video pair is presented for training an open-domain T2V generator. Intuitively, we propose to adapt the T2I diffusion model pretrained on massive image data for T2V generation. We make two key observations: 1) T2I models are able to generate images that align well with the verb terms; 2) extending T2I models to generate multiple images concurrently exhibits surprisingly good content consistency. To further learn continuous motion, we propose Tune-A-Video with a tailored Sparse-Causal Attention, which generates videos from text prompts via an efficient one-shot tuning of pretrained T2I diffusion models. Tune-A-Video is capable of producing temporally-coherent videos over various applications such as change of subject or background, attribute editing, style transfer, demonstrating the versatility and effectiveness of our method.
Learning to Learn: How to Continuously Teach Humans and Machines
Nov 28, 2022



Our education system comprises a series of curricula. For example, when we learn mathematics at school, we learn in order from addition, to multiplication, and later to integration. Delineating a curriculum for teaching either a human or a machine shares the underlying goal of maximizing the positive knowledge transfer from early to later tasks and minimizing forgetting of the early tasks. Here, we exhaustively surveyed the effect of curricula on existing continual learning algorithms in the class-incremental setting, where algorithms must learn classes one at a time from a continuous stream of data. We observed that across a breadth of possible class orders (curricula), curricula influence the retention of information and that this effect is not just a product of stochasticity. Further, as a primary effort toward automated curriculum design, we proposed a method capable of designing and ranking effective curricula based on inter-class feature similarities. We compared the predicted curricula against empirically determined effectual curricula and observed significant overlaps between the two. To support the study of a curriculum designer, we conducted a series of human psychophysics experiments and contributed a new Continual Learning benchmark in object recognition. We assessed the degree of agreement in effective curricula between humans and machines. Surprisingly, our curriculum designer successfully predicts an optimal set of curricula that is effective for human learning. There are many considerations in curriculum design, such as timely student feedback and learning with multiple modalities. Our study is the first attempt to set a standard framework for the community to tackle the problem of teaching humans and machines to learn to learn continuously.
PCCT: Progressive Class-Center Triplet Loss for Imbalanced Medical Image Classification
Jul 11, 2022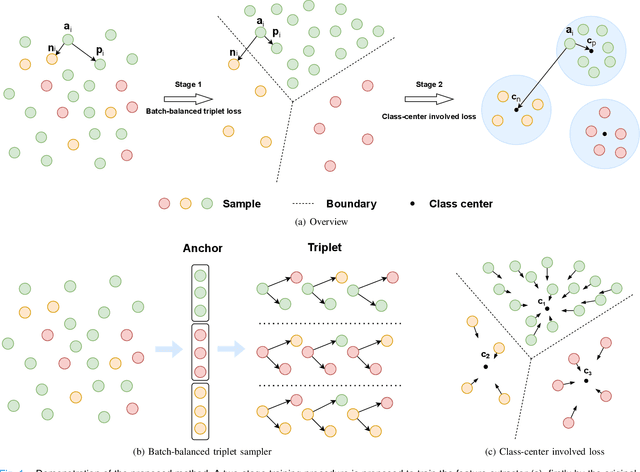
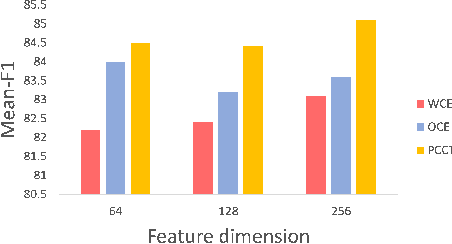

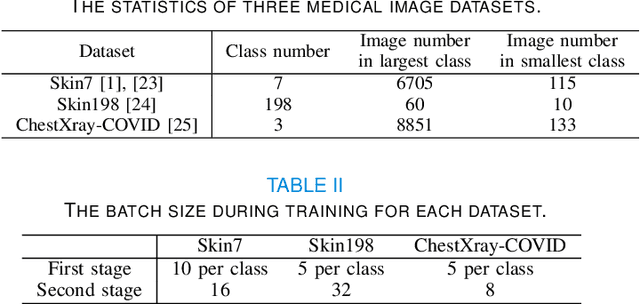
Imbalanced training data is a significant challenge for medical image classification. In this study, we propose a novel Progressive Class-Center Triplet (PCCT) framework to alleviate the class imbalance issue particularly for diagnosis of rare diseases, mainly by carefully designing the triplet sampling strategy and the triplet loss formation. Specifically, the PCCT framework includes two successive stages. In the first stage, PCCT trains the diagnosis system via a class-balanced triplet loss to coarsely separate distributions of different classes. In the second stage, the PCCT framework further improves the diagnosis system via a class-center involved triplet loss to cause a more compact distribution for each class. For the class-balanced triplet loss, triplets are sampled equally for each class at each training iteration, thus alleviating the imbalanced data issue. For the class-center involved triplet loss, the positive and negative samples in each triplet are replaced by their corresponding class centers, which enforces data representations of the same class closer to the class center. Furthermore, the class-center involved triplet loss is extended to the pair-wise ranking loss and the quadruplet loss, which demonstrates the generalization of the proposed framework. Extensive experiments support that the PCCT framework works effectively for medical image classification with imbalanced training images. On two skin image datasets and one chest X-ray dataset, the proposed approach respectively obtains the mean F1 score 86.2, 65.2, and 90.66 over all classes and 81.4, 63.87, and 81.92 for rare classes, achieving state-of-the-art performance and outperforming the widely used methods for the class imbalance issue.