 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLBF:Learnable Bilateral Filter For Point Cloud Denoising
Oct 28, 2022



Bilateral filter (BF) is a fast, lightweight and effective tool for image denoising and well extended to point cloud denoising. However, it often involves continual yet manual parameter adjustment; this inconvenience discounts the efficiency and user experience to obtain satisfied denoising results. We propose LBF, an end-to-end learnable bilateral filtering network for point cloud denoising; to our knowledge, this is the first time. Unlike the conventional BF and its variants that receive the same parameters for a whole point cloud, LBF learns adaptive parameters for each point according its geometric characteristic (e.g., corner, edge, plane), avoiding remnant noise, wrongly-removed geometric details, and distorted shapes. Besides the learnable paradigm of BF, we have two cores to facilitate LBF. First, different from the local BF, LBF possesses a global-scale feature perception ability by exploiting multi-scale patches of each point. Second, LBF formulates a geometry-aware bi-directional projection loss, leading the denoising results to being faithful to their underlying surfaces. Users can apply our LBF without any laborious parameter tuning to achieve the optimal denoising results. Experiments show clear improvements of LBF over its competitors on both synthetic and real-scanned datasets.
PSFormer: Point Transformer for 3D Salient Object Detection
Oct 28, 2022



We propose PSFormer, an effective point transformer model for 3D salient object detection. PSFormer is an encoder-decoder network that takes full advantage of transformers to model the contextual information in both multi-scale point- and scene-wise manners. In the encoder, we develop a Point Context Transformer (PCT) module to capture region contextual features at the point level; PCT contains two different transformers to excavate the relationship among points. In the decoder, we develop a Scene Context Transformer (SCT) module to learn context representations at the scene level; SCT contains both Upsampling-and-Transformer blocks and Multi-context Aggregation units to integrate the global semantic and multi-level features from the encoder into the global scene context. Experiments show clear improvements of PSFormer over its competitors and validate that PSFormer is more robust to challenging cases such as small objects, multiple objects, and objects with complex structures.
SPCNet: Stepwise Point Cloud Completion Network
Sep 05, 2022
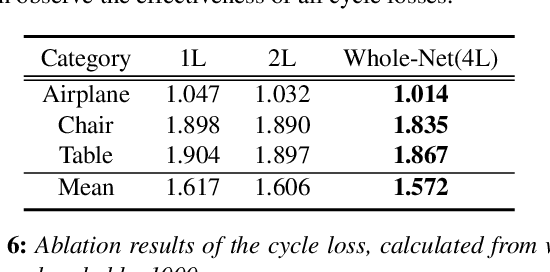
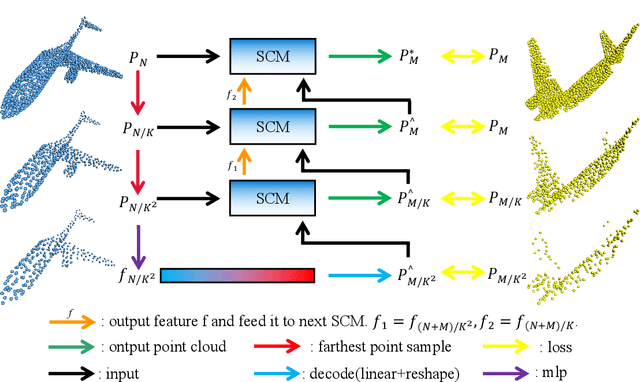
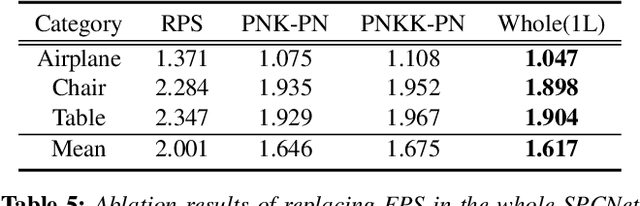
How will you repair a physical object with large missings? You may first recover its global yet coarse shape and stepwise increase its local details. We are motivated to imitate the above physical repair procedure to address the point cloud completion task. We propose a novel stepwise point cloud completion network (SPCNet) for various 3D models with large missings. SPCNet has a hierarchical bottom-to-up network architecture. It fulfills shape completion in an iterative manner, which 1) first infers the global feature of the coarse result; 2) then infers the local feature with the aid of global feature; and 3) finally infers the detailed result with the help of local feature and coarse result. Beyond the wisdom of simulating the physical repair, we newly design a cycle loss %based training strategy to enhance the generalization and robustness of SPCNet. Extensive experiments clearly show the superiority of our SPCNet over the state-of-the-art methods on 3D point clouds with large missings.
SO-Pose: SO-Equivariance Learning for 6D Object Pose Estimation
Aug 17, 2022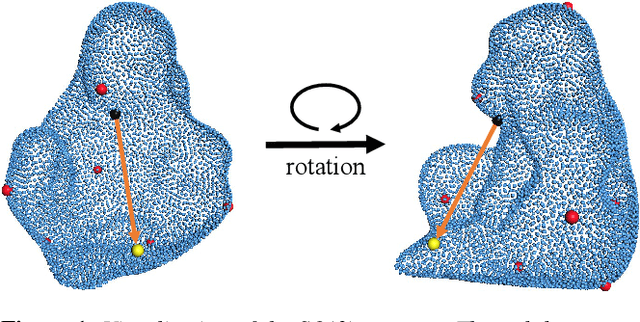
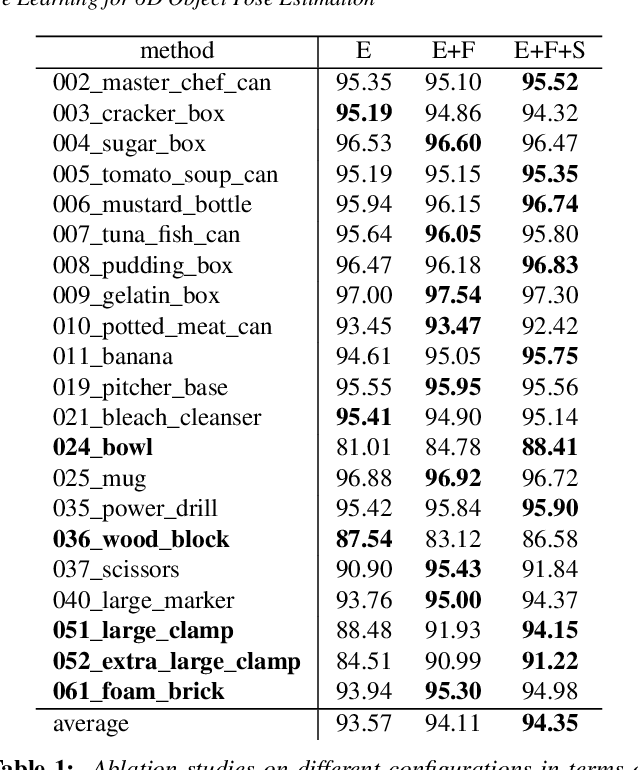

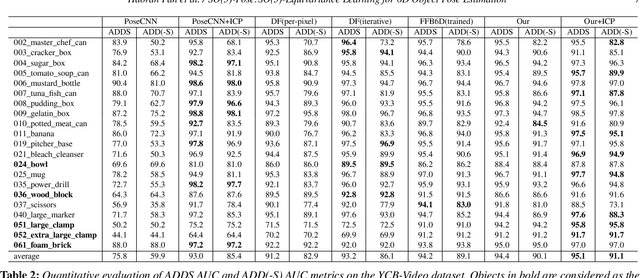
6D pose estimation of rigid objects from RGB-D images is crucial for object grasping and manipulation in robotics. Although RGB channels and the depth (D) channel are often complementary, providing respectively the appearance and geometry information, it is still non-trivial how to fully benefit from the two cross-modal data. From the simple yet new observation, when an object rotates, its semantic label is invariant to the pose while its keypoint offset direction is variant to the pose. To this end, we present SO(3)-Pose, a new representation learning network to explore SO(3)-equivariant and SO(3)-invariant features from the depth channel for pose estimation. The SO(3)-invariant features facilitate to learn more distinctive representations for segmenting objects with similar appearance from RGB channels. The SO(3)-equivariant features communicate with RGB features to deduce the (missed) geometry for detecting keypoints of an object with the reflective surface from the depth channel. Unlike most of existing pose estimation methods, our SO(3)-Pose not only implements the information communication between the RGB and depth channels, but also naturally absorbs the SO(3)-equivariance geometry knowledge from depth images, leading to better appearance and geometry representation learning. Comprehensive experiments show that our method achieves the state-of-the-art performance on three benchmarks.
CF-YOLO: Cross Fusion YOLO for Object Detection in Adverse Weather with a High-quality Real Snow Dataset
Jun 03, 2022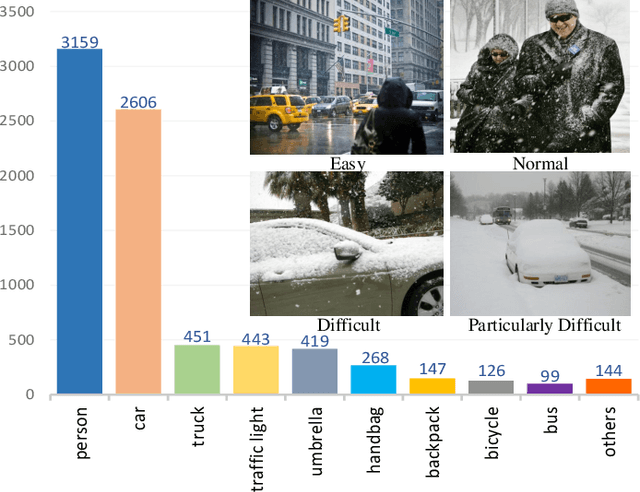
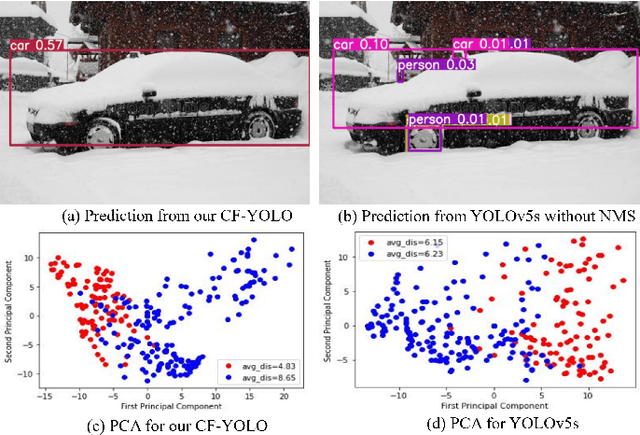
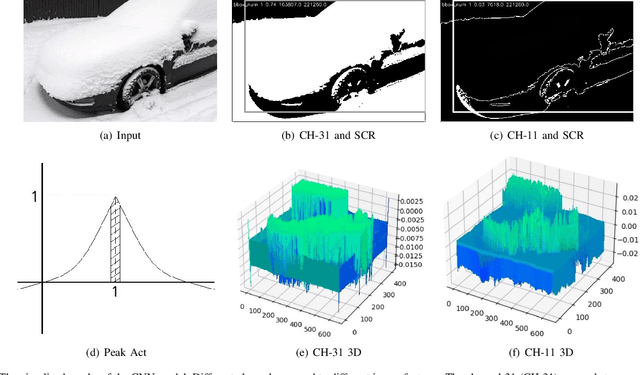
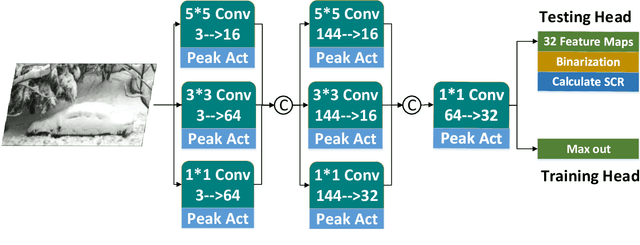
Snow is one of the toughest adverse weather conditions for object detection (OD). Currently, not only there is a lack of snowy OD datasets to train cutting-edge detectors, but also these detectors have difficulties learning latent information beneficial for detection in snow. To alleviate the two above problems, we first establish a real-world snowy OD dataset, named RSOD. Besides, we develop an unsupervised training strategy with a distinctive activation function, called $Peak \ Act$, to quantitatively evaluate the effect of snow on each object. Peak Act helps grading the images in RSOD into four-difficulty levels. To our knowledge, RSOD is the first quantitatively evaluated and graded snowy OD dataset. Then, we propose a novel Cross Fusion (CF) block to construct a lightweight OD network based on YOLOv5s (call CF-YOLO). CF is a plug-and-play feature aggregation module, which integrates the advantages of Feature Pyramid Network and Path Aggregation Network in a simpler yet more flexible form. Both RSOD and CF lead our CF-YOLO to possess an optimization ability for OD in real-world snow. That is, CF-YOLO can handle unfavorable detection problems of vagueness, distortion and covering of snow. Experiments show that our CF-YOLO achieves better detection results on RSOD, compared to SOTAs. The code and dataset are available at https://github.com/qqding77/CF-YOLO-and-RSOD.
CPPF: Towards Robust Category-Level 9D Pose Estimation in the Wild
Mar 27, 2022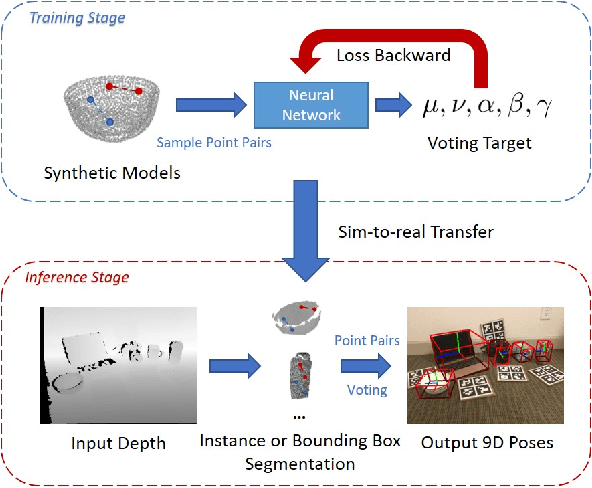
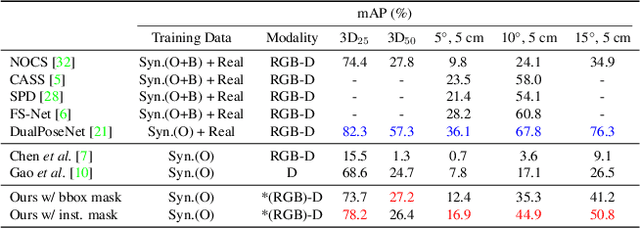
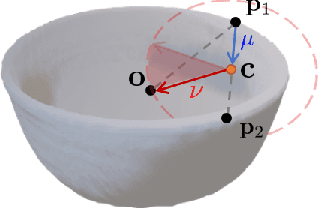
In this paper, we tackle the problem of category-level 9D pose estimation in the wild, given a single RGB-D frame. Using supervised data of real-world 9D poses is tedious and erroneous, and also fails to generalize to unseen scenarios. Besides, category-level pose estimation requires a method to be able to generalize to unseen objects at test time, which is also challenging. Drawing inspirations from traditional point pair features (PPFs), in this paper, we design a novel Category-level PPF (CPPF) voting method to achieve accurate, robust and generalizable 9D pose estimation in the wild. To obtain robust pose estimation, we sample numerous point pairs on an object, and for each pair our model predicts necessary SE(3)-invariant voting statistics on object centers, orientations and scales. A novel coarse-to-fine voting algorithm is proposed to eliminate noisy point pair samples and generate final predictions from the population. To get rid of false positives in the orientation voting process, an auxiliary binary disambiguating classification task is introduced for each sampled point pair. In order to detect objects in the wild, we carefully design our sim-to-real pipeline by training on synthetic point clouds only, unless objects have ambiguous poses in geometry. Under this circumstance, color information is leveraged to disambiguate these poses. Results on standard benchmarks show that our method is on par with current state of the arts with real-world training data. Extensive experiments further show that our method is robust to noise and gives promising results under extremely challenging scenarios. Our code is available on https://github.com/qq456cvb/CPPF.
Understanding Pixel-level 2D Image Semantics with 3D Keypoint Knowledge Engine
Nov 21, 2021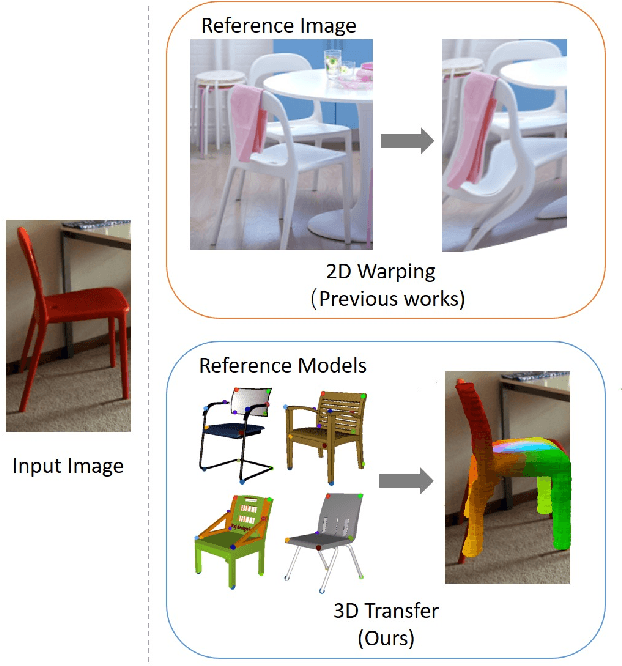

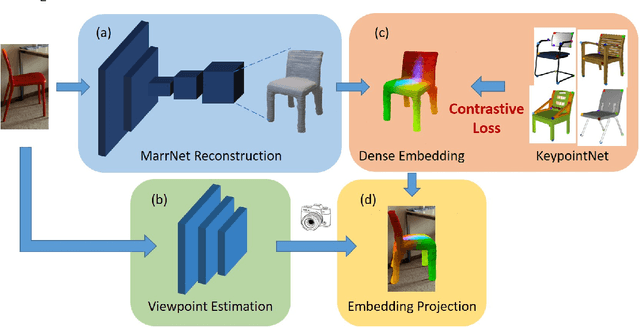

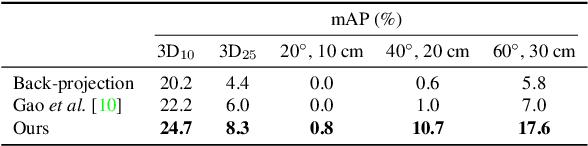
Pixel-level 2D object semantic understanding is an important topic in computer vision and could help machine deeply understand objects (e.g. functionality and affordance) in our daily life. However, most previous methods directly train on correspondences in 2D images, which is end-to-end but loses plenty of information in 3D spaces. In this paper, we propose a new method on predicting image corresponding semantics in 3D domain and then projecting them back onto 2D images to achieve pixel-level understanding. In order to obtain reliable 3D semantic labels that are absent in current image datasets, we build a large scale keypoint knowledge engine called KeypointNet, which contains 103,450 keypoints and 8,234 3D models from 16 object categories. Our method leverages the advantages in 3D vision and can explicitly reason about objects self-occlusion and visibility. We show that our method gives comparative and even superior results on standard semantic benchmarks.
PRIN/SPRIN: On Extracting Point-wise Rotation Invariant Features
Feb 24, 2021
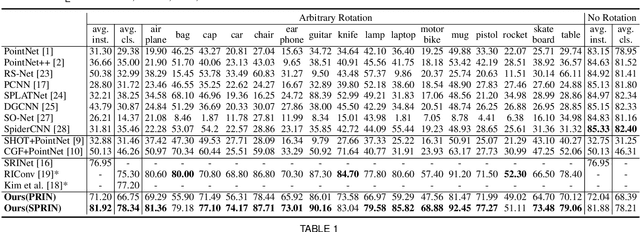

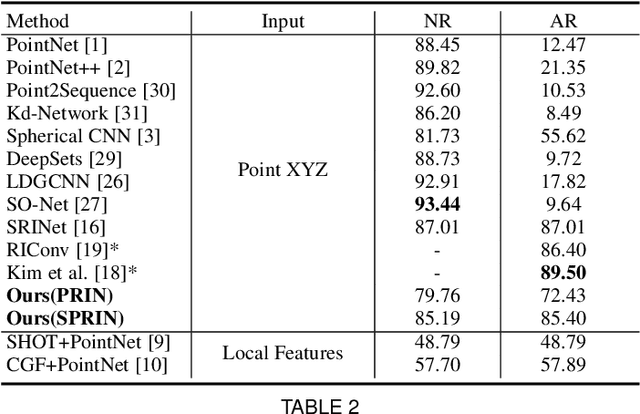
Point cloud analysis without pose priors is very challenging in real applications, as the orientations of point clouds are often unknown. In this paper, we propose a brand new point-set learning framework PRIN, namely, Point-wise Rotation Invariant Network, focusing on rotation invariant feature extraction in point clouds analysis. We construct spherical signals by Density Aware Adaptive Sampling to deal with distorted point distributions in spherical space. Spherical Voxel Convolution and Point Re-sampling are proposed to extract rotation invariant features for each point. In addition, we extend PRIN to a sparse version called SPRIN, which directly operates on sparse point clouds. Both PRIN and SPRIN can be applied to tasks ranging from object classification, part segmentation, to 3D feature matching and label alignment. Results show that, on the dataset with randomly rotated point clouds, SPRIN demonstrates better performance than state-of-the-art methods without any data augmentation. We also provide thorough theoretical proof and analysis for point-wise rotation invariance achieved by our methods. Our code is available on https://github.com/qq456cvb/SPRIN.
Deep Texture-Aware Features for Camouflaged Object Detection
Feb 05, 2021
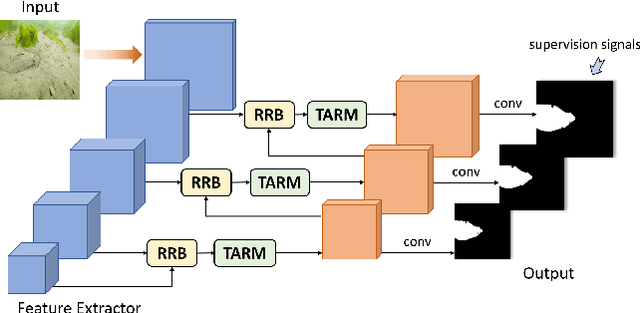

Camouflaged object detection is a challenging task that aims to identify objects having similar texture to the surroundings. This paper presents to amplify the subtle texture difference between camouflaged objects and the background for camouflaged object detection by formulating multiple texture-aware refinement modules to learn the texture-aware features in a deep convolutional neural network. The texture-aware refinement module computes the covariance matrices of feature responses to extract the texture information, designs an affinity loss to learn a set of parameter maps that help to separate the texture between camouflaged objects and the background, and adopts a boundary-consistency loss to explore the object detail structures.We evaluate our network on the benchmark dataset for camouflaged object detection both qualitatively and quantitatively. Experimental results show that our approach outperforms various state-of-the-art methods by a large margin.
Canonical Voting: Towards Robust Oriented Bounding Box Detection in 3D Scenes
Nov 24, 2020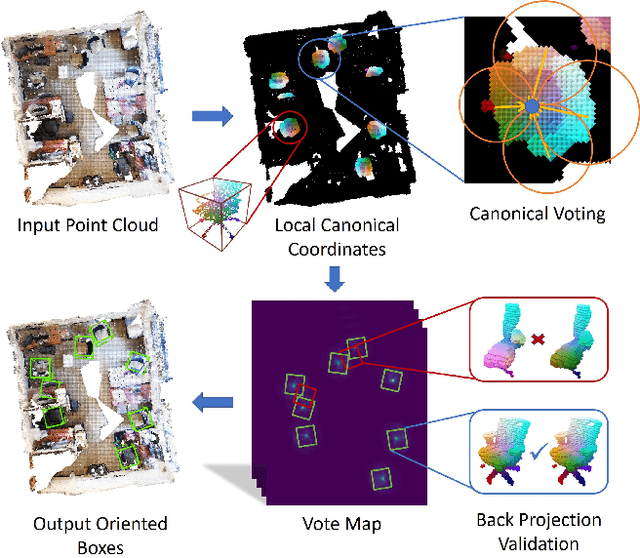

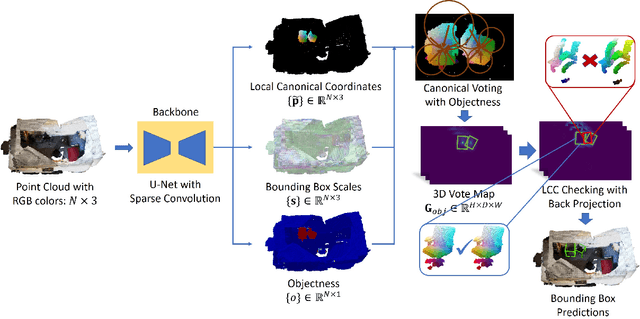
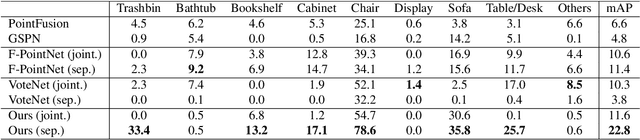
3D object detection has attracted much attention thanks to the advances in sensors and deep learning methods for point clouds. Current state-of-the-art methods like VoteNet regress direct offset towards object centers and box orientations with an additional Multi-Layer-Perceptron network. Both their offset and orientation predictions are not accurate due to the fundamental difficulty in rotation classification. In the work, we disentangle the direct offset into Local Canonical Coordinates (LCC), box scales and box orientations. Only LCC and box scales are regressed while box orientations are generated by a canonical voting scheme. Finally, a LCC-aware back-projection checking algorithm iteratively cuts out bounding boxes from the generated vote maps, with the elimination of false positives. Our model achieves state-of-the-art performance on challenging large-scale datasets of real point cloud scans: ScanNet, SceneNN with 11.4 and 5.3 mAP improvement respectively. Code is available on https://github.com/qq456cvb/CanonicalVoting.