 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavelet-guided Misalignment-aware Network for Visible-Infrared Object Detection
Jul 27, 2025Visible-infrared object detection aims to enhance the detection robustness by exploiting the complementary information of visible and infrared image pairs. However, its performance is often limited by frequent misalignments caused by resolution disparities, spatial displacements, and modality inconsistencies. To address this issue, we propose the Wavelet-guided Misalignment-aware Network (WMNet), a unified framework designed to adaptively address different cross-modal misalignment patterns. WMNet incorporates wavelet-based multi-frequency analysis and modality-aware fusion mechanisms to improve the alignment and integration of cross-modal features. By jointly exploiting low and high-frequency information and introducing adaptive guidance across modalities, WMNet alleviates the adverse effects of noise, illumination variation, and spatial misalignment. Furthermore, it enhances the representation of salient target features while suppressing spurious or misleading information, thereby promoting more accurate and robust detection. Extensive evaluations on the DVTOD, DroneVehicle, and M3FD datasets demonstrate that WMNet achieves state-of-the-art performance on misaligned cross-modal object detection tasks, confirming its effectiveness and practical applicability.
I Speak and You Find: Robust 3D Visual Grounding with Noisy and Ambiguous Speech Inputs
Jun 17, 2025Existing 3D visual grounding methods rely on precise text prompts to locate objects within 3D scenes. Speech, as a natural and intuitive modality, offers a promising alternative. Real-world speech inputs, however, often suffer from transcription errors due to accents, background noise, and varying speech rates, limiting the applicability of existing 3DVG methods. To address these challenges, we propose \textbf{SpeechRefer}, a novel 3DVG framework designed to enhance performance in the presence of noisy and ambiguous speech-to-text transcriptions. SpeechRefer integrates seamlessly with xisting 3DVG models and introduces two key innovations. First, the Speech Complementary Module captures acoustic similarities between phonetically related words and highlights subtle distinctions, generating complementary proposal scores from the speech signal. This reduces dependence on potentially erroneous transcriptions. Second, the Contrastive Complementary Module employs contrastive learning to align erroneous text features with corresponding speech features, ensuring robust performance even when transcription errors dominate. Extensive experiments on the SpeechRefer and peechNr3D datasets demonstrate that SpeechRefer improves the performance of existing 3DVG methods by a large margin, which highlights SpeechRefer's potential to bridge the gap between noisy speech inputs and reliable 3DVG, enabling more intuitive and practical multimodal systems.
Unified Representation Space for 3D Visual Grounding
Jun 17, 20253D visual grounding (3DVG) is a critical task in scene understanding that aims to identify objects in 3D scenes based on text descriptions. However, existing methods rely on separately pre-trained vision and text encoders, resulting in a significant gap between the two modalities in terms of spatial geometry and semantic categories. This discrepancy often causes errors in object positioning and classification. The paper proposes UniSpace-3D, which innovatively introduces a unified representation space for 3DVG, effectively bridging the gap between visual and textual features. Specifically, UniSpace-3D incorporates three innovative designs: i) a unified representation encoder that leverages the pre-trained CLIP model to map visual and textual features into a unified representation space, effectively bridging the gap between the two modalities; ii) a multi-modal contrastive learning module that further reduces the modality gap; iii) a language-guided query selection module that utilizes the positional and semantic information to identify object candidate points aligned with textual descriptions. Extensive experiments demonstrate that UniSpace-3D outperforms baseline models by at least 2.24% on the ScanRefer and Nr3D/Sr3D datasets. The code will be made available upon acceptance of the paper.
CrossTracker: Robust Multi-modal 3D Multi-Object Tracking via Cross Correction
Nov 28, 2024



The fusion of camera- and LiDAR-based detections offers a promising solution to mitigate tracking failures in 3D multi-object tracking (MOT). However, existing methods predominantly exploit camera detections to correct tracking failures caused by potential LiDAR detection problems, neglecting the reciprocal benefit of refining camera detections using LiDAR data. This limitation is rooted in their single-stage architecture, akin to single-stage object detectors, lacking a dedicated trajectory refinement module to fully exploit the complementary multi-modal information. To this end, we introduce CrossTracker, a novel two-stage paradigm for online multi-modal 3D MOT. CrossTracker operates in a coarse-to-fine manner, initially generating coarse trajectories and subsequently refining them through an independent refinement process. Specifically, CrossTracker incorporates three essential modules: i) a multi-modal modeling (M^3) module that, by fusing multi-modal information (images, point clouds, and even plane geometry extracted from images), provides a robust metric for subsequent trajectory generation. ii) a coarse trajectory generation (C-TG) module that generates initial coarse dual-stream trajectories, and iii) a trajectory refinement (TR) module that refines coarse trajectories through cross correction between camera and LiDAR streams. Comprehensive experiments demonstrate the superior performance of our CrossTracker over its eighteen competitors, underscoring its effectiveness in harnessing the synergistic benefits of camera and LiDAR sensors for robust multi-modal 3D MOT.
YOLOO: You Only Learn from Others Once
Sep 01, 2024



Multi-modal 3D multi-object tracking (MOT) typically necessitates extensive computational costs of deep neural networks (DNNs) to extract multi-modal representations. In this paper, we propose an intriguing question: May we learn from multiple modalities only during training to avoid multi-modal input in the inference phase? To answer it, we propose \textbf{YOLOO}, a novel multi-modal 3D MOT paradigm: You Only Learn from Others Once. YOLOO empowers the point cloud encoder to learn a unified tri-modal representation (UTR) from point clouds and other modalities, such as images and textual cues, all at once. Leveraging this UTR, YOLOO achieves efficient tracking solely using the point cloud encoder without compromising its performance, fundamentally obviating the need for computationally intensive DNNs. Specifically, YOLOO includes two core components: a unified tri-modal encoder (UTEnc) and a flexible geometric constraint (F-GC) module. UTEnc integrates a point cloud encoder with image and text encoders adapted from pre-trained CLIP. It seamlessly fuses point cloud information with rich visual-textual knowledge from CLIP into the point cloud encoder, yielding highly discriminative UTRs that facilitate the association between trajectories and detections. Additionally, F-GC filters out mismatched associations with similar representations but significant positional discrepancies. It further enhances the robustness of UTRs without requiring any scene-specific tuning, addressing a key limitation of customized geometric constraints (e.g., 3D IoU). Lastly, high-quality 3D trajectories are generated by a traditional data association component. By integrating these advancements into a multi-modal 3D MOT scheme, our YOLOO achieves substantial gains in both robustness and efficiency.
PointeNet: A Lightweight Framework for Effective and Efficient Point Cloud Analysis
Dec 20, 2023



Current methodologies in point cloud analysis predominantly explore 3D geometries, often achieved through the introduction of intricate learnable geometric extractors in the encoder or by deepening networks with repeated blocks. However, these approaches inevitably lead to a significant number of learnable parameters, resulting in substantial computational costs and imposing memory burdens on CPU/GPU. Additionally, the existing strategies are primarily tailored for object-level point cloud classification and segmentation tasks, with limited extensions to crucial scene-level applications, such as autonomous driving. In response to these limitations, we introduce PointeNet, an efficient network designed specifically for point cloud analysis. PointeNet distinguishes itself with its lightweight architecture, low training cost, and plug-and-play capability, effectively capturing representative features. The network consists of a Multivariate Geometric Encoding (MGE) module and an optional Distance-aware Semantic Enhancement (DSE) module. The MGE module employs operations of sampling, grouping, and multivariate geometric aggregation to lightweightly capture and adaptively aggregate multivariate geometric features, providing a comprehensive depiction of 3D geometries. The DSE module, designed for real-world autonomous driving scenarios, enhances the semantic perception of point clouds, particularly for distant points. Our method demonstrates flexibility by seamlessly integrating with a classification/segmentation head or embedding into off-the-shelf 3D object detection networks, achieving notable performance improvements at a minimal cost. Extensive experiments on object-level datasets, including ModelNet40, ScanObjectNN, ShapeNetPart, and the scene-level dataset KITTI, demonstrate the superior performance of PointeNet over state-of-the-art methods in point cloud analysis.
PointSee: Image Enhances Point Cloud
Nov 03, 2022



There is a trend to fuse multi-modal information for 3D object detection (3OD). However, the challenging problems of low lightweightness, poor flexibility of plug-and-play, and inaccurate alignment of features are still not well-solved, when designing multi-modal fusion newtorks. We propose PointSee, a lightweight, flexible and effective multi-modal fusion solution to facilitate various 3OD networks by semantic feature enhancement of LiDAR point clouds assembled with scene images. Beyond the existing wisdom of 3OD, PointSee consists of a hidden module (HM) and a seen module (SM): HM decorates LiDAR point clouds using 2D image information in an offline fusion manner, leading to minimal or even no adaptations of existing 3OD networks; SM further enriches the LiDAR point clouds by acquiring point-wise representative semantic features, leading to enhanced performance of existing 3OD networks. Besides the new architecture of PointSee, we propose a simple yet efficient training strategy, to ease the potential inaccurate regressions of 2D object detection networks. Extensive experiments on the popular outdoor/indoor benchmarks show numerical improvements of our PointSee over twenty-two state-of-the-arts.
PSFormer: Point Transformer for 3D Salient Object Detection
Oct 28, 2022



We propose PSFormer, an effective point transformer model for 3D salient object detection. PSFormer is an encoder-decoder network that takes full advantage of transformers to model the contextual information in both multi-scale point- and scene-wise manners. In the encoder, we develop a Point Context Transformer (PCT) module to capture region contextual features at the point level; PCT contains two different transformers to excavate the relationship among points. In the decoder, we develop a Scene Context Transformer (SCT) module to learn context representations at the scene level; SCT contains both Upsampling-and-Transformer blocks and Multi-context Aggregation units to integrate the global semantic and multi-level features from the encoder into the global scene context. Experiments show clear improvements of PSFormer over its competitors and validate that PSFormer is more robust to challenging cases such as small objects, multiple objects, and objects with complex structures.
PV-RCNN++: Semantical Point-Voxel Feature Interaction for 3D Object Detection
Aug 29, 2022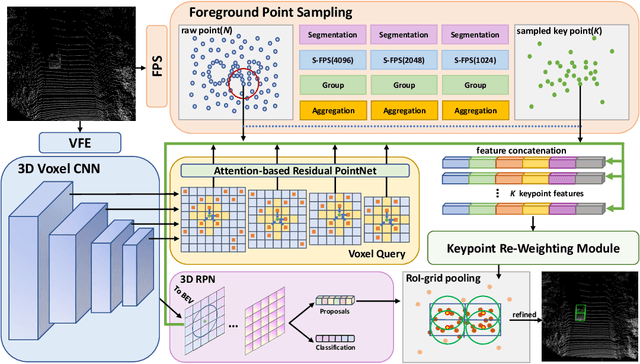
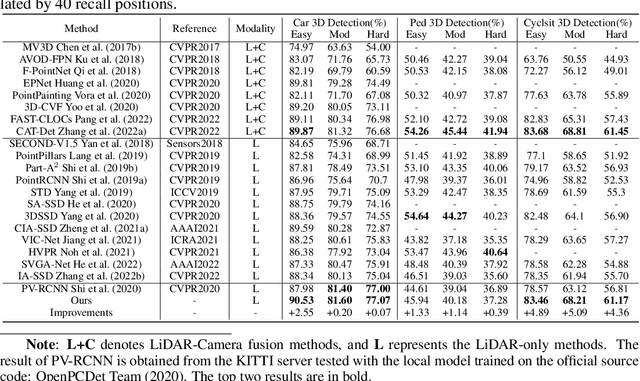
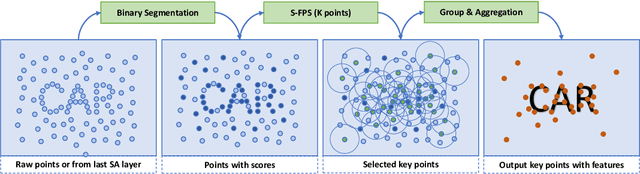
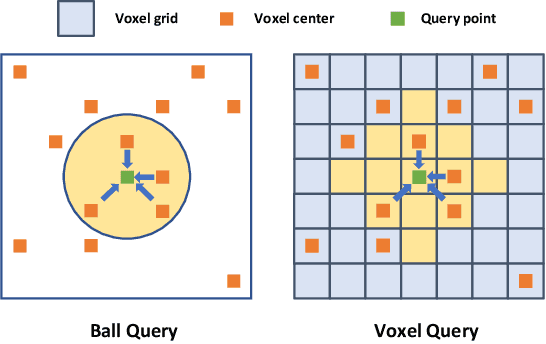
Large imbalance often exists between the foreground points (i.e., objects) and the background points in outdoor LiDAR point clouds. It hinders cutting-edge detectors from focusing on informative areas to produce accurate 3D object detection results. This paper proposes a novel object detection network by semantical point-voxel feature interaction, dubbed PV-RCNN++. Unlike most of existing methods, PV-RCNN++ explores the semantic information to enhance the quality of object detection. First, a semantic segmentation module is proposed to retain more discriminative foreground keypoints. Such a module will guide our PV-RCNN++ to integrate more object-related point-wise and voxel-wise features in the pivotal areas. Then, to make points and voxels interact efficiently, we utilize voxel query based on Manhattan distance to quickly sample voxel-wise features around keypoints. Such the voxel query will reduce the time complexity from O(N) to O(K), compared to the ball query. Further, to avoid being stuck in learning only local features, an attention-based residual PointNet module is designed to expand the receptive field to adaptively aggregate the neighboring voxel-wise features into keypoints. Extensive experiments on the KITTI dataset show that PV-RCNN++ achieves 81.60$\%$, 40.18$\%$, 68.21$\%$ 3D mAP on Car, Pedestrian, and Cyclist, achieving comparable or even better performance to the state-of-the-arts.