 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrackTeller: Temporal Multimodal 3D Grounding for Behavior-Dependent Object References
Dec 25, 2025Understanding natural-language references to objects in dynamic 3D driving scenes is essential for interactive autonomous systems. In practice, many referring expressions describe targets through recent motion or short-term interactions, which cannot be resolved from static appearance or geometry alone. We study temporal language-based 3D grounding, where the objective is to identify the referred object in the current frame by leveraging multi-frame observations. We propose TrackTeller, a temporal multimodal grounding framework that integrates LiDAR-image fusion, language-conditioned decoding, and temporal reasoning in a unified architecture. TrackTeller constructs a shared UniScene representation aligned with textual semantics, generates language-aware 3D proposals, and refines grounding decisions using motion history and short-term dynamics. Experiments on the NuPrompt benchmark demonstrate that TrackTeller consistently improves language-grounded tracking performance, outperforming strong baselines with a 70% relative improvement in Average Multi-Object Tracking Accuracy and a 3.15-3.4 times reduction in False Alarm Frequency.
MatE: Material Extraction from Single-Image via Geometric Prior
Dec 20, 2025The creation of high-fidelity, physically-based rendering (PBR) materials remains a bottleneck in many graphics pipelines, typically requiring specialized equipment and expert-driven post-processing. To democratize this process, we present MatE, a novel method for generating tileable PBR materials from a single image taken under unconstrained, real-world conditions. Given an image and a user-provided mask, MatE first performs coarse rectification using an estimated depth map as a geometric prior, and then employs a dual-branch diffusion model. Leveraging a learned consistency from rotation-aligned and scale-aligned training data, this model further rectify residual distortions from the coarse result and translate it into a complete set of material maps, including albedo, normal, roughness and height. Our framework achieves invariance to the unknown illumination and perspective of the input image, allowing for the recovery of intrinsic material properties from casual captures. Through comprehensive experiments on both synthetic and real-world data, we demonstrate the efficacy and robustness of our approach, enabling users to create realistic materials from real-world image.
Anchoring Values in Temporal and Group Dimensions for Flow Matching Model Alignment
Dec 13, 2025Group Relative Policy Optimization (GRPO) has proven highly effective in enhancing the alignment capabilities of Large Language Models (LLMs). However, current adaptations of GRPO for the flow matching-based image generation neglect a foundational conflict between its core principles and the distinct dynamics of the visual synthesis process. This mismatch leads to two key limitations: (i) Uniformly applying a sparse terminal reward across all timesteps impairs temporal credit assignment, ignoring the differing criticality of generation phases from early structure formation to late-stage tuning. (ii) Exclusive reliance on relative, intra-group rewards causes the optimization signal to fade as training converges, leading to the optimization stagnation when reward diversity is entirely depleted. To address these limitations, we propose Value-Anchored Group Policy Optimization (VGPO), a framework that redefines value estimation across both temporal and group dimensions. Specifically, VGPO transforms the sparse terminal reward into dense, process-aware value estimates, enabling precise credit assignment by modeling the expected cumulative reward at each generative stage. Furthermore, VGPO replaces standard group normalization with a novel process enhanced by absolute values to maintain a stable optimization signal even as reward diversity declines. Extensive experiments on three benchmarks demonstrate that VGPO achieves state-of-the-art image quality while simultaneously improving task-specific accuracy, effectively mitigating reward hacking. Project webpage: https://yawen-shao.github.io/VGPO/.
Beyond Randomness: Understand the Order of the Noise in Diffusion
Nov 11, 2025
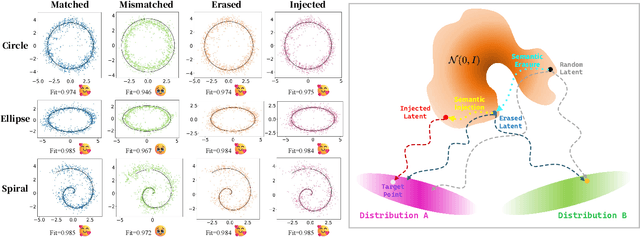


In text-driven content generation (T2C) diffusion model, semantic of generated content is mostly attributed to the process of text embedding and attention mechanism interaction. The initial noise of the generation process is typically characterized as a random element that contributes to the diversity of the generated content. Contrary to this view, this paper reveals that beneath the random surface of noise lies strong analyzable patterns. Specifically, this paper first conducts a comprehensive analysis of the impact of random noise on the model's generation. We found that noise not only contains rich semantic information, but also allows for the erasure of unwanted semantics from it in an extremely simple way based on information theory, and using the equivalence between the generation process of diffusion model and semantic injection to inject semantics into the cleaned noise. Then, we mathematically decipher these observations and propose a simple but efficient training-free and universal two-step "Semantic Erasure-Injection" process to modulate the initial noise in T2C diffusion model. Experimental results demonstrate that our method is consistently effective across various T2C models based on both DiT and UNet architectures and presents a novel perspective for optimizing the generation of diffusion model, providing a universal tool for consistent generation.
AliTok: Towards Sequence Modeling Alignment between Tokenizer and Autoregressive Model
Jun 05, 2025Autoregressive image generation aims to predict the next token based on previous ones. However, existing image tokenizers encode tokens with bidirectional dependencies during the compression process, which hinders the effective modeling by autoregressive models. In this paper, we propose a novel Aligned Tokenizer (AliTok), which utilizes a causal decoder to establish unidirectional dependencies among encoded tokens, thereby aligning the token modeling approach between the tokenizer and autoregressive model. Furthermore, by incorporating prefix tokens and employing two-stage tokenizer training to enhance reconstruction consistency, AliTok achieves great reconstruction performance while being generation-friendly. On ImageNet-256 benchmark, using a standard decoder-only autoregressive model as the generator with only 177M parameters, AliTok achieves a gFID score of 1.50 and an IS of 305.9. When the parameter count is increased to 662M, AliTok achieves a gFID score of 1.35, surpassing the state-of-the-art diffusion method with 10x faster sampling speed. The code and weights are available at https://github.com/ali-vilab/alitok.
GRACE: Estimating Geometry-level 3D Human-Scene Contact from 2D Images
May 10, 2025

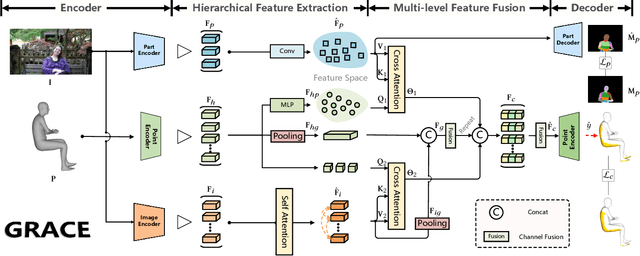

Estimating the geometry level of human-scene contact aims to ground specific contact surface points at 3D human geometries, which provides a spatial prior and bridges the interaction between human and scene, supporting applications such as human behavior analysis, embodied AI, and AR/VR. To complete the task, existing approaches predominantly rely on parametric human models (e.g., SMPL), which establish correspondences between images and contact regions through fixed SMPL vertex sequences. This actually completes the mapping from image features to an ordered sequence. However, this approach lacks consideration of geometry, limiting its generalizability in distinct human geometries. In this paper, we introduce GRACE (Geometry-level Reasoning for 3D Human-scene Contact Estimation), a new paradigm for 3D human contact estimation. GRACE incorporates a point cloud encoder-decoder architecture along with a hierarchical feature extraction and fusion module, enabling the effective integration of 3D human geometric structures with 2D interaction semantics derived from images. Guided by visual cues, GRACE establishes an implicit mapping from geometric features to the vertex space of the 3D human mesh, thereby achieving accurate modeling of contact regions. This design ensures high prediction accuracy and endows the framework with strong generalization capability across diverse human geometries. Extensive experiments on multiple benchmark datasets demonstrate that GRACE achieves state-of-the-art performance in contact estimation, with additional results further validating its robust generalization to unstructured human point clouds.
Event-Based Eye Tracking. 2025 Event-based Vision Workshop
Apr 25, 2025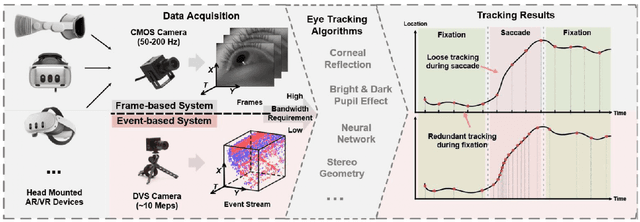
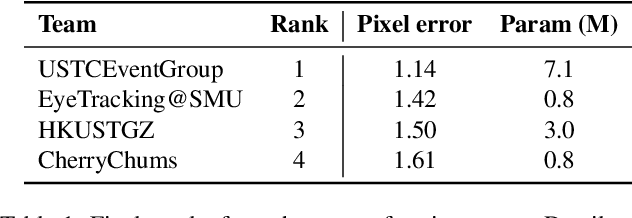
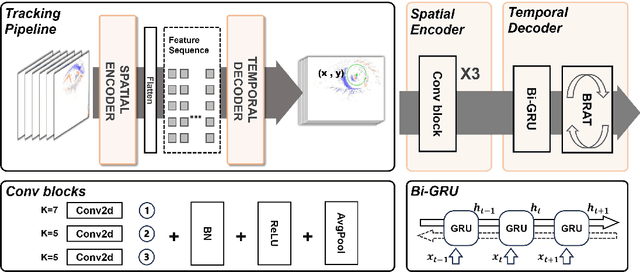

This survey serves as a review for the 2025 Event-Based Eye Tracking Challenge organized as part of the 2025 CVPR event-based vision workshop. This challenge focuses on the task of predicting the pupil center by processing event camera recorded eye movement. We review and summarize the innovative methods from teams rank the top in the challenge to advance future event-based eye tracking research. In each method, accuracy, model size, and number of operations are reported. In this survey, we also discuss event-based eye tracking from the perspective of hardware design.
Event Signal Filtering via Probability Flux Estimation
Apr 10, 2025Events offer a novel paradigm for capturing scene dynamics via asynchronous sensing, but their inherent randomness often leads to degraded signal quality. Event signal filtering is thus essential for enhancing fidelity by reducing this internal randomness and ensuring consistent outputs across diverse acquisition conditions. Unlike traditional time series that rely on fixed temporal sampling to capture steady-state behaviors, events encode transient dynamics through polarity and event intervals, making signal modeling significantly more complex. To address this, the theoretical foundation of event generation is revisited through the lens of diffusion processes. The state and process information within events is modeled as continuous probability flux at threshold boundaries of the underlying irradiance diffusion. Building on this insight, a generative, online filtering framework called Event Density Flow Filter (EDFilter) is introduced. EDFilter estimates event correlation by reconstructing the continuous probability flux from discrete events using nonparametric kernel smoothing, and then resamples filtered events from this flux. To optimize fidelity over time, spatial and temporal kernels are employed in a time-varying optimization framework. A fast recursive solver with O(1) complexity is proposed, leveraging state-space models and lookup tables for efficient likelihood computation. Furthermore, a new real-world benchmark Rotary Event Dataset (RED) is released, offering microsecond-level ground truth irradiance for full-reference event filtering evaluation. Extensive experiments validate EDFilter's performance across tasks like event filtering, super-resolution, and direct event-based blob tracking. Significant gains in downstream applications such as SLAM and video reconstruction underscore its robustness and effectiveness.
SIGMAN:Scaling 3D Human Gaussian Generation with Millions of Assets
Apr 09, 20253D human digitization has long been a highly pursued yet challenging task. Existing methods aim to generate high-quality 3D digital humans from single or multiple views, but remain primarily constrained by current paradigms and the scarcity of 3D human assets. Specifically, recent approaches fall into several paradigms: optimization-based and feed-forward (both single-view regression and multi-view generation with reconstruction). However, they are limited by slow speed, low quality, cascade reasoning, and ambiguity in mapping low-dimensional planes to high-dimensional space due to occlusion and invisibility, respectively. Furthermore, existing 3D human assets remain small-scale, insufficient for large-scale training. To address these challenges, we propose a latent space generation paradigm for 3D human digitization, which involves compressing multi-view images into Gaussians via a UV-structured VAE, along with DiT-based conditional generation, we transform the ill-posed low-to-high-dimensional mapping problem into a learnable distribution shift, which also supports end-to-end inference. In addition, we employ the multi-view optimization approach combined with synthetic data to construct the HGS-1M dataset, which contains $1$ million 3D Gaussian assets to support the large-scale training. Experimental results demonstrate that our paradigm, powered by large-scale training, produces high-quality 3D human Gaussians with intricate textures, facial details, and loose clothing deformation.
VideoGen-Eval: Agent-based System for Video Generation Evaluation
Mar 30, 2025



The rapid advancement of video generation has rendered existing evaluation systems inadequate for assessing state-of-the-art models, primarily due to simple prompts that cannot showcase the model's capabilities, fixed evaluation operators struggling with Out-of-Distribution (OOD) cases, and misalignment between computed metrics and human preferences. To bridge the gap, we propose VideoGen-Eval, an agent evaluation system that integrates LLM-based content structuring, MLLM-based content judgment, and patch tools designed for temporal-dense dimensions, to achieve a dynamic, flexible, and expandable video generation evaluation. Additionally, we introduce a video generation benchmark to evaluate existing cutting-edge models and verify the effectiveness of our evaluation system. It comprises 700 structured, content-rich prompts (both T2V and I2V) and over 12,000 videos generated by 20+ models, among them, 8 cutting-edge models are selected as quantitative evaluation for the agent and human. Extensive experiments validate that our proposed agent-based evaluation system demonstrates strong alignment with human preferences and reliably completes the evaluation, as well as the diversity and richness of the benchmark.