 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkywork-Reward-V2: Scaling Preference Data Curation via Human-AI Synergy
Jul 02, 2025Despite the critical role of reward models (RMs) in reinforcement learning from human feedback (RLHF), current state-of-the-art open RMs perform poorly on most existing evaluation benchmarks, failing to capture the spectrum of nuanced and sophisticated human preferences. Even approaches that incorporate advanced training techniques have not yielded meaningful performance improvements. We hypothesize that this brittleness stems primarily from limitations in preference datasets, which are often narrowly scoped, synthetically labeled, or lack rigorous quality control. To address these challenges, we present a large-scale preference dataset comprising 40 million preference pairs, named SynPref-40M. To enable data curation at scale, we design a human-AI synergistic two-stage pipeline that leverages the complementary strengths of human annotation quality and AI scalability. In this pipeline, humans provide verified annotations, while large language models perform automatic curation based on human guidance. Training on this preference mixture, we introduce Skywork-Reward-V2, a suite of eight reward models ranging from 0.6B to 8B parameters, trained on a carefully curated subset of 26 million preference pairs from SynPref-40M. We demonstrate that Skywork-Reward-V2 is versatile across a wide range of capabilities, including alignment with human preferences, objective correctness, safety, resistance to stylistic biases, and best-of-N scaling, achieving state-of-the-art performance across seven major reward model benchmarks. Ablation studies confirm that the effectiveness of our approach stems not only from data scale but also from high-quality curation. The Skywork-Reward-V2 series represents substantial progress in open reward models, highlighting the untapped potential of existing preference datasets and demonstrating how human-AI curation synergy can unlock significantly higher data quality.
MedSeg-R: Reasoning Segmentation in Medical Images with Multimodal Large Language Models
Jun 12, 2025



Medical image segmentation is crucial for clinical diagnosis, yet existing models are limited by their reliance on explicit human instructions and lack the active reasoning capabilities to understand complex clinical questions. While recent advancements in multimodal large language models (MLLMs) have improved medical question-answering (QA) tasks, most methods struggle to generate precise segmentation masks, limiting their application in automatic medical diagnosis. In this paper, we introduce medical image reasoning segmentation, a novel task that aims to generate segmentation masks based on complex and implicit medical instructions. To address this, we propose MedSeg-R, an end-to-end framework that leverages the reasoning abilities of MLLMs to interpret clinical questions while also capable of producing corresponding precise segmentation masks for medical images. It is built on two core components: 1) a global context understanding module that interprets images and comprehends complex medical instructions to generate multi-modal intermediate tokens, and 2) a pixel-level grounding module that decodes these tokens to produce precise segmentation masks and textual responses. Furthermore, we introduce MedSeg-QA, a large-scale dataset tailored for the medical image reasoning segmentation task. It includes over 10,000 image-mask pairs and multi-turn conversations, automatically annotated using large language models and refined through physician reviews. Experiments show MedSeg-R's superior performance across several benchmarks, achieving high segmentation accuracy and enabling interpretable textual analysis of medical images.
Mitigating Posterior Salience Attenuation in Long-Context LLMs with Positional Contrastive Decoding
Jun 11, 2025



While Large Language Models (LLMs) support long contexts, they struggle with performance degradation within the context window. Current solutions incur prohibitive training costs, leaving statistical behaviors and cost-effective approaches underexplored. From the decoding perspective, we identify the Posterior Salience Attenuation (PSA) phenomenon, where the salience ratio correlates with long-text performance degradation. Notably, despite the attenuation, gold tokens still occupy high-ranking positions in the decoding space. Motivated by it, we propose the training-free Positional Contrastive Decoding (PCD) that contrasts the logits derived from long-aware attention with those from designed local-aware attention, enabling the model to focus on the gains introduced by large-scale short-to-long training. Through the analysis of long-term decay simulation, we demonstrate that PCD effectively alleviates attention score degradation. Experimental results show that PCD achieves state-of-the-art performance on long-context benchmarks.
Tackling View-Dependent Semantics in 3D Language Gaussian Splatting
May 30, 2025Recent advancements in 3D Gaussian Splatting (3D-GS) enable high-quality 3D scene reconstruction from RGB images. Many studies extend this paradigm for language-driven open-vocabulary scene understanding. However, most of them simply project 2D semantic features onto 3D Gaussians and overlook a fundamental gap between 2D and 3D understanding: a 3D object may exhibit various semantics from different viewpoints--a phenomenon we term view-dependent semantics. To address this challenge, we propose LaGa (Language Gaussians), which establishes cross-view semantic connections by decomposing the 3D scene into objects. Then, it constructs view-aggregated semantic representations by clustering semantic descriptors and reweighting them based on multi-view semantics. Extensive experiments demonstrate that LaGa effectively captures key information from view-dependent semantics, enabling a more comprehensive understanding of 3D scenes. Notably, under the same settings, LaGa achieves a significant improvement of +18.7% mIoU over the previous SOTA on the LERF-OVS dataset. Our code is available at: https://github.com/SJTU-DeepVisionLab/LaGa.
On the Convergence Analysis of Muon
May 29, 2025The majority of parameters in neural networks are naturally represented as matrices. However, most commonly used optimizers treat these matrix parameters as flattened vectors during optimization, potentially overlooking their inherent structural properties. Recently, an optimizer called Muon has been proposed, specifically designed to optimize matrix-structured parameters. Extensive empirical evidence shows that Muon can significantly outperform traditional optimizers when training neural networks. Nonetheless, the theoretical understanding of Muon's convergence behavior and the reasons behind its superior performance remain limited. In this work, we present a comprehensive convergence rate analysis of Muon and its comparison with Gradient Descent (GD). We further characterize the conditions under which Muon can outperform GD. Our theoretical results reveal that Muon can benefit from the low-rank and approximate blockwise diagonal structure of Hessian matrices -- phenomena widely observed in practical neural network training. Our experimental results support and corroborate the theoretical findings.
Weight Spectra Induced Efficient Model Adaptation
May 29, 2025Large-scale foundation models have demonstrated remarkable versatility across a wide range of downstream tasks. However, fully fine-tuning these models incurs prohibitive computational costs, motivating the development of Parameter-Efficient Fine-Tuning (PEFT) methods such as LoRA, which introduces low-rank updates to pre-trained weights. Despite their empirical success, the underlying mechanisms by which PEFT modifies model parameters remain underexplored. In this work, we present a systematic investigation into the structural changes of weight matrices during fully fine-tuning. Through singular value decomposition (SVD), we reveal that fine-tuning predominantly amplifies the top singular values while leaving the remainder largely intact, suggesting that task-specific knowledge is injected into a low-dimensional subspace. Furthermore, we find that the dominant singular vectors are reoriented in task-specific directions, whereas the non-dominant subspace remains stable. Building on these insights, we propose a novel method that leverages learnable rescaling of top singular directions, enabling precise modulation of the most influential components without disrupting the global structure. Our approach achieves consistent improvements over strong baselines across multiple tasks, highlighting the efficacy of structurally informed fine-tuning.
Skywork Open Reasoner 1 Technical Report
May 29, 2025The success of DeepSeek-R1 underscores the significant role of reinforcement learning (RL) in enhancing the reasoning capabilities of large language models (LLMs). In this work, we present Skywork-OR1, an effective and scalable RL implementation for long Chain-of-Thought (CoT) models. Building on the DeepSeek-R1-Distill model series, our RL approach achieves notable performance gains, increasing average accuracy across AIME24, AIME25, and LiveCodeBench from 57.8% to 72.8% (+15.0%) for the 32B model and from 43.6% to 57.5% (+13.9%) for the 7B model. Our Skywork-OR1-32B model surpasses both DeepSeek-R1 and Qwen3-32B on the AIME24 and AIME25 benchmarks, while achieving comparable results on LiveCodeBench. The Skywork-OR1-7B and Skywork-OR1-Math-7B models demonstrate competitive reasoning capabilities among models of similar size. We perform comprehensive ablation studies on the core components of our training pipeline to validate their effectiveness. Additionally, we thoroughly investigate the phenomenon of entropy collapse, identify key factors affecting entropy dynamics, and demonstrate that mitigating premature entropy collapse is critical for improved test performance. To support community research, we fully open-source our model weights, training code, and training datasets.
MAP: Revisiting Weight Decomposition for Low-Rank Adaptation
May 29, 2025
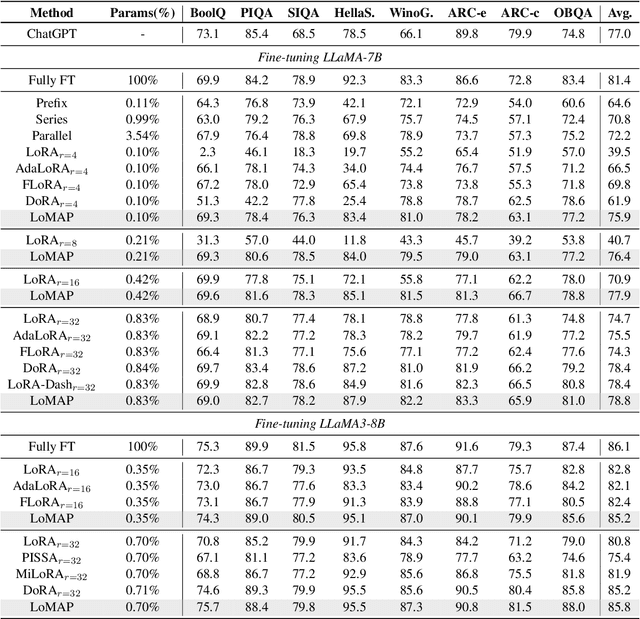
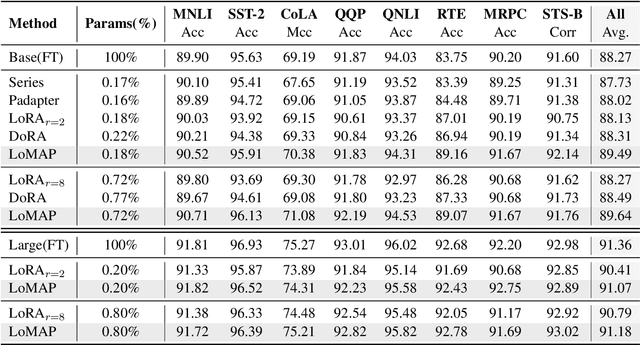

The rapid development of large language models has revolutionized natural language processing, but their fine-tuning remains computationally expensive, hindering broad deployment. Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, have emerged as solutions. Recent work like DoRA attempts to further decompose weight adaptation into direction and magnitude components. However, existing formulations often define direction heuristically at the column level, lacking a principled geometric foundation. In this paper, we propose MAP, a novel framework that reformulates weight matrices as high-dimensional vectors and decouples their adaptation into direction and magnitude in a rigorous manner. MAP normalizes the pre-trained weights, learns a directional update, and introduces two scalar coefficients to independently scale the magnitude of the base and update vectors. This design enables more interpretable and flexible adaptation, and can be seamlessly integrated into existing PEFT methods. Extensive experiments show that MAP significantly improves performance when coupling with existing methods, offering a simple yet powerful enhancement to existing PEFT methods. Given the universality and simplicity of MAP, we hope it can serve as a default setting for designing future PEFT methods.
Revisiting Sparsity Constraint Under High-Rank Property in Partial Multi-Label Learning
May 27, 2025Partial Multi-Label Learning (PML) extends the multi-label learning paradigm to scenarios where each sample is associated with a candidate label set containing both ground-truth labels and noisy labels. Existing PML methods commonly rely on two assumptions: sparsity of the noise label matrix and low-rankness of the ground-truth label matrix. However, these assumptions are inherently conflicting and impractical for real-world scenarios, where the true label matrix is typically full-rank or close to full-rank. To address these limitations, we demonstrate that the sparsity constraint contributes to the high-rank property of the predicted label matrix. Based on this, we propose a novel method Schirn, which introduces a sparsity constraint on the noise label matrix while enforcing a high-rank property on the predicted label matrix. Extensive experiments demonstrate the superior performance of Schirn compared to state-of-the-art methods, validating its effectiveness in tackling real-world PML challenges.
Reward-Driven Interaction: Enhancing Proactive Dialogue Agents through User Satisfaction Prediction
May 24, 2025Reward-driven proactive dialogue agents require precise estimation of user satisfaction as an intrinsic reward signal to determine optimal interaction strategies. Specifically, this framework triggers clarification questions when detecting potential user dissatisfaction during interactions in the industrial dialogue system. Traditional works typically rely on training a neural network model based on weak labels which are generated by a simple model trained on user actions after current turn. However, existing methods suffer from two critical limitations in real-world scenarios: (1) Noisy Reward Supervision, dependence on weak labels derived from post-hoc user actions introduces bias, particularly failing to capture satisfaction signals in ASR-error-induced utterances; (2) Long-Tail Feedback Sparsity, the power-law distribution of user queries causes reward prediction accuracy to drop in low-frequency domains. The noise in the weak labels and a power-law distribution of user utterances results in that the model is hard to learn good representation of user utterances and sessions. To address these limitations, we propose two auxiliary tasks to improve the representation learning of user utterances and sessions that enhance user satisfaction prediction. The first one is a contrastive self-supervised learning task, which helps the model learn the representation of rare user utterances and identify ASR errors. The second one is a domain-intent classification task, which aids the model in learning the representation of user sessions from long-tailed domains and improving the model's performance on such domains. The proposed method is evaluated on DuerOS, demonstrating significant improvements in the accuracy of error recognition on rare user utterances and long-tailed domains.