 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWei Ji
Cross2StrA: Unpaired Cross-lingual Image Captioning with Cross-lingual Cross-modal Structure-pivoted Alignment
May 25, 2023
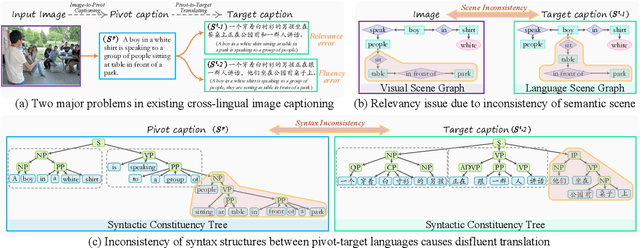
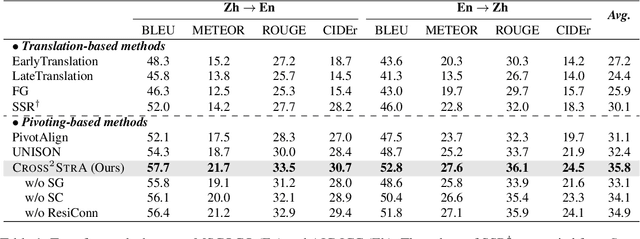
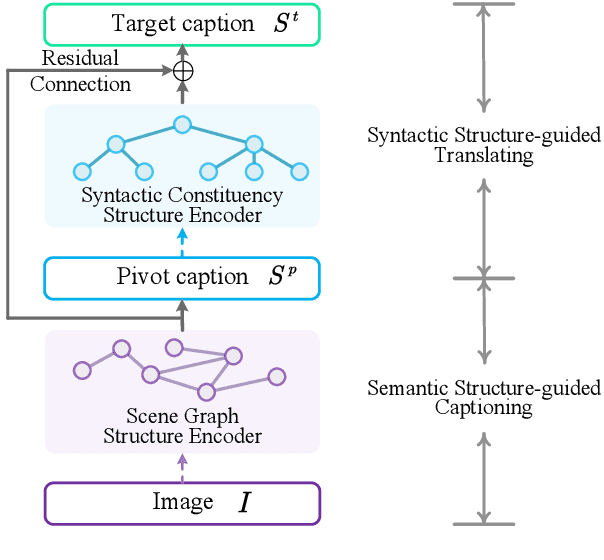
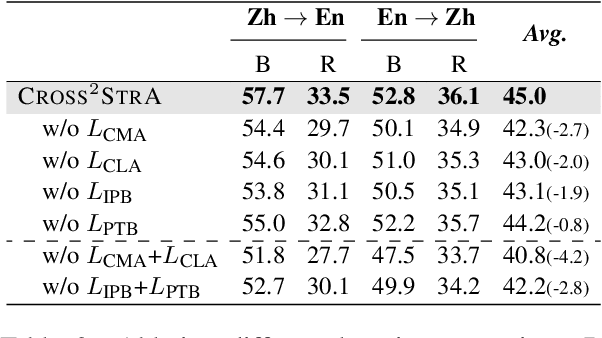
Unpaired cross-lingual image captioning has long suffered from irrelevancy and disfluency issues, due to the inconsistencies of the semantic scene and syntax attributes during transfer. In this work, we propose to address the above problems by incorporating the scene graph (SG) structures and the syntactic constituency (SC) trees. Our captioner contains the semantic structure-guided image-to-pivot captioning and the syntactic structure-guided pivot-to-target translation, two of which are joined via pivot language. We then take the SG and SC structures as pivoting, performing cross-modal semantic structure alignment and cross-lingual syntactic structure alignment learning. We further introduce cross-lingual&cross-modal back-translation training to fully align the captioning and translation stages. Experiments on English-Chinese transfers show that our model shows great superiority in improving captioning relevancy and fluency.
Generating Visual Spatial Description via Holistic 3D Scene Understanding
May 19, 2023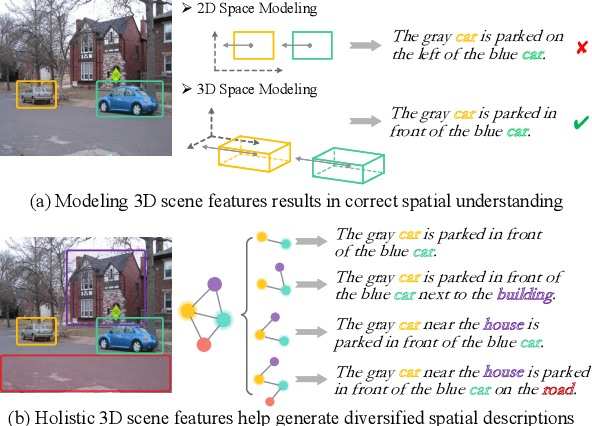

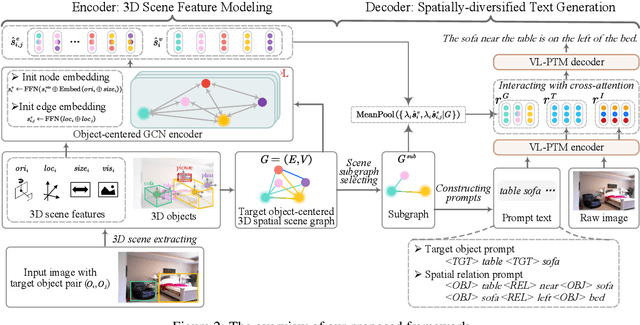

Visual spatial description (VSD) aims to generate texts that describe the spatial relations of the given objects within images. Existing VSD work merely models the 2D geometrical vision features, thus inevitably falling prey to the problem of skewed spatial understanding of target objects. In this work, we investigate the incorporation of 3D scene features for VSD. With an external 3D scene extractor, we obtain the 3D objects and scene features for input images, based on which we construct a target object-centered 3D spatial scene graph (Go3D-S2G), such that we model the spatial semantics of target objects within the holistic 3D scenes. Besides, we propose a scene subgraph selecting mechanism, sampling topologically-diverse subgraphs from Go3D-S2G, where the diverse local structure features are navigated to yield spatially-diversified text generation. Experimental results on two VSD datasets demonstrate that our framework outperforms the baselines significantly, especially improving on the cases with complex visual spatial relations. Meanwhile, our method can produce more spatially-diversified generation. Code is available at https://github.com/zhaoyucs/VSD.
Transfer Visual Prompt Generator across LLMs
May 02, 2023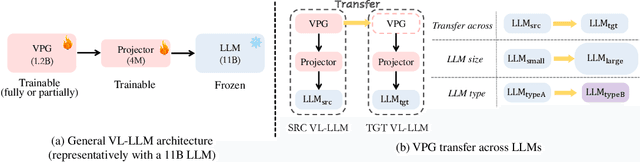

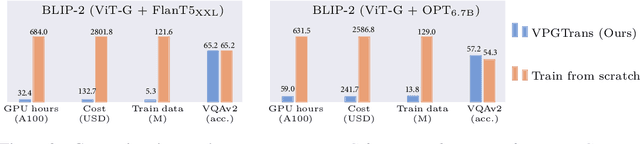

While developing a new vision-language LLM (VL-LLM) by pre-training on tremendous image-text pairs from scratch can be exceedingly resource-consuming, connecting an existing LLM with a comparatively lightweight visual prompt generator (VPG) becomes a feasible paradigm. However, further tuning the VPG part of the VL-LLM still suffers from indispensable computational costs, i.e., requiring thousands of GPU hours and millions of training data. One alternative solution is to transfer an existing VPG from any existing VL-LLMs for the target VL-LLM. In this work, we for the first time investigate the VPG transferability across LLMs, and explore a solution to reduce the cost of VPG transfer. We first study the VPG transfer across different LLM sizes (e.g., small-to-large), and across different LLM types, through which we diagnose the key factors to maximize the transfer efficiency. Based on our observation, we design a two-stage transfer framework named VPGTrans, which is simple yet highly effective. Through extensive experiments, we demonstrate that VPGTrans helps significantly speed up the transfer learning process without compromising performance. Remarkably, it helps achieve the VPG transfer from BLIP-2 OPT$_\text{2.7B}$ to BLIP-2 OPT$_\text{6.7B}$ with over 10 times speed-up and 10.7% training data compared with connecting a VPG to OPT$_\text{6.7B}$ from scratch. Further, a series of intriguing findings and potential rationales behind them are provided and discussed. Finally, we showcase the practical value of our VPGTrans approach, by customizing two novel VL-LLMs, including VL-LLaMA and VL-Vicuna, with recently released LLaMA and Vicuna LLMs.
Segment Anything Is Not Always Perfect: An Investigation of SAM on Different Real-world Applications
Apr 13, 2023



Recently, Meta AI Research approaches a general, promptable Segment Anything Model (SAM) pre-trained on an unprecedentedly large segmentation dataset (SA-1B). Without a doubt, the emergence of SAM will yield significant benefits for a wide array of practical image segmentation applications. In this study, we conduct a series of intriguing investigations into the performance of SAM across various applications, particularly in the fields of natural images, agriculture, manufacturing, remote sensing, and healthcare. We analyze and discuss the benefits and limitations of SAM and provide an outlook on future development of segmentation tasks. Note that our work does not intend to propose new algorithms or theories, but rather provide a comprehensive view of SAM in practice. This work is expected to provide insights that facilitate future research activities toward generic segmentation.
Visually-Prompted Language Model for Fine-Grained Scene Graph Generation in an Open World
Mar 23, 2023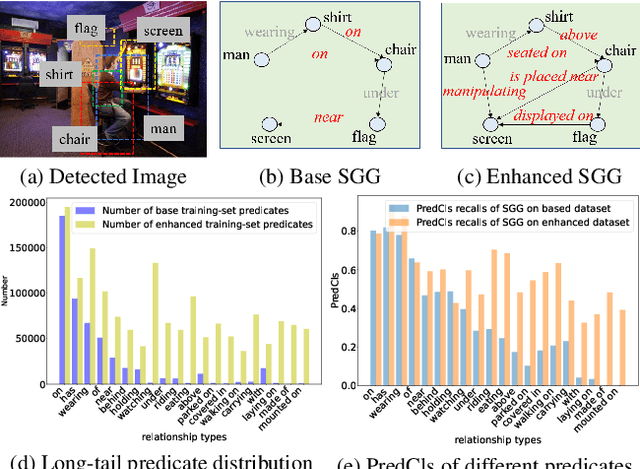
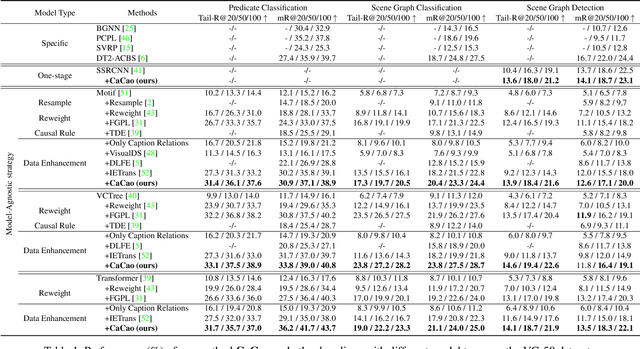
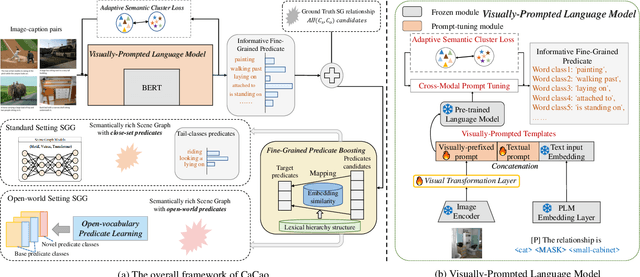
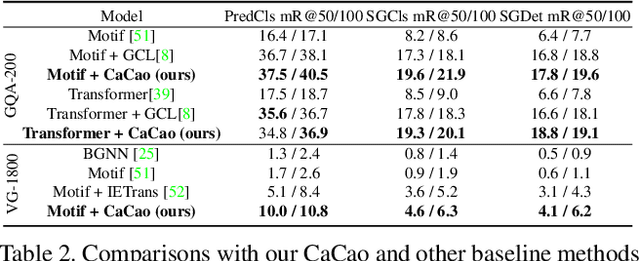
Scene Graph Generation (SGG) aims to extract <subject, predicate, object> relationships in images for vision understanding. Although recent works have made steady progress on SGG, they still suffer long-tail distribution issues that tail-predicates are more costly to train and hard to distinguish due to a small amount of annotated data compared to frequent predicates. Existing re-balancing strategies try to haddle it via prior rules but are still confined to pre-defined conditions, which are not scalable for various models and datasets. In this paper, we propose a Cross-modal prediCate boosting (CaCao) framework, where a visually-prompted language model is learned to generate diverse fine-grained predicates in a low-resource way. The proposed CaCao can be applied in a plug-and-play fashion and automatically strengthen existing SGG to tackle the long-tailed problem. Based on that, we further introduce a novel Entangled cross-modal prompt approach for open-world predicate scene graph generation (Epic), where models can generalize to unseen predicates in a zero-shot manner. Comprehensive experiments on three benchmark datasets show that CaCao consistently boosts the performance of multiple scene graph generation models in a model-agnostic way. Moreover, our Epic achieves competitive performance on open-world predicate prediction.
Gradient-Regulated Meta-Prompt Learning for Generalizable Vision-Language Models
Mar 12, 2023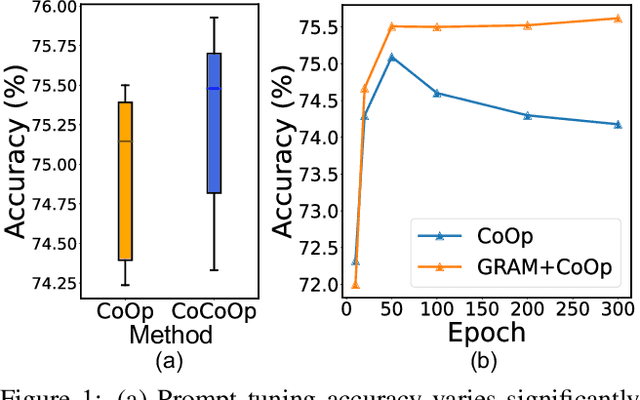
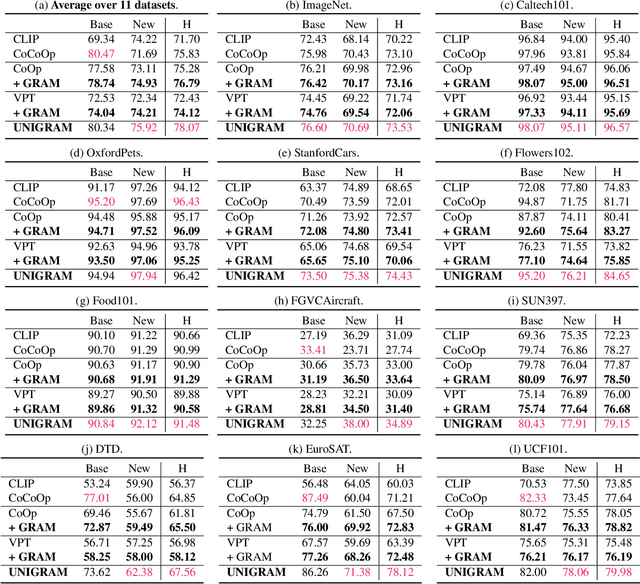
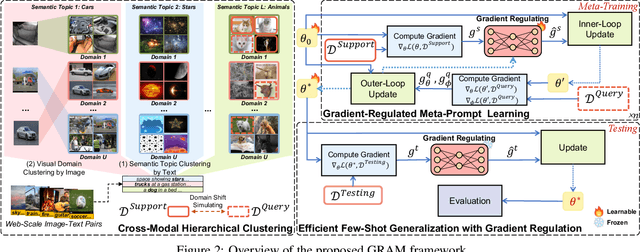
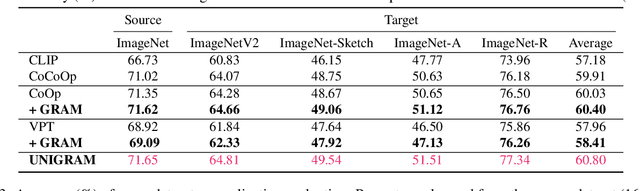
Prompt tuning, a recently emerging paradigm, enables the powerful vision-language pre-training models to adapt to downstream tasks in a parameter -- and data -- efficient way, by learning the ``soft prompts'' to condition frozen pre-training models. Though effective, it is particularly problematic in the few-shot scenario, where prompt tuning performance is sensitive to the initialization and requires a time-consuming process to find a good initialization, thus restricting the fast adaptation ability of the pre-training models. In addition, prompt tuning could undermine the generalizability of the pre-training models, because the learnable prompt tokens are easy to overfit to the limited training samples. To address these issues, we introduce a novel Gradient-RegulAted Meta-prompt learning (GRAM) framework that jointly meta-learns an efficient soft prompt initialization for better adaptation and a lightweight gradient regulating function for strong cross-domain generalizability in a meta-learning paradigm using only the unlabeled image-text pre-training data. Rather than designing a specific prompt tuning method, our GRAM can be easily incorporated into various prompt tuning methods in a model-agnostic way, and comprehensive experiments show that GRAM brings about consistent improvement for them in several settings (i.e., few-shot learning, cross-domain generalization, cross-dataset generalization, etc.) over 11 datasets. Further, experiments show that GRAM enables the orthogonal methods of textual and visual prompt tuning to work in a mutually-enhanced way, offering better generalizability beyond the uni-modal prompt tuning methods.
Scalable Attribution of Adversarial Attacks via Multi-Task Learning
Feb 25, 2023

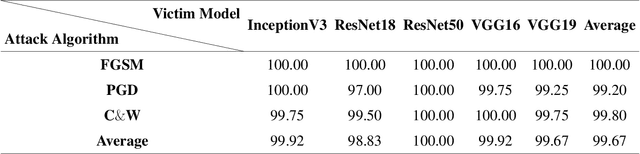
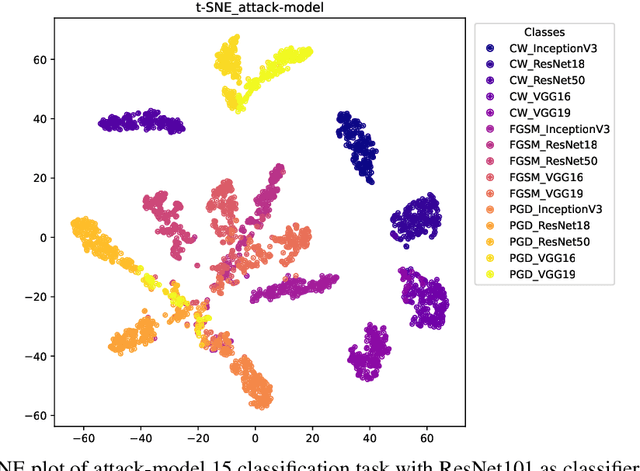
Deep neural networks (DNNs) can be easily fooled by adversarial attacks during inference phase when attackers add imperceptible perturbations to original examples, i.e., adversarial examples. Many works focus on adversarial detection and adversarial training to defend against adversarial attacks. However, few works explore the tool-chains behind adversarial examples, which can help defenders to seize the clues about the originator of the attack, their goals, and provide insight into the most effective defense algorithm against corresponding attacks. With such a gap, it is necessary to develop techniques that can recognize tool-chains that are leveraged to generate the adversarial examples, which is called Adversarial Attribution Problem (AAP). In this paper, AAP is defined as the recognition of three signatures, i.e., {\em attack algorithm}, {\em victim model} and {\em hyperparameter}. Current works transfer AAP into single label classification task and ignore the relationship between these signatures. The former will meet combination explosion problem as the number of signatures is increasing. The latter dictates that we cannot treat AAP simply as a single task problem. We first conduct some experiments to validate the attributability of adversarial examples. Furthermore, we propose a multi-task learning framework named Multi-Task Adversarial Attribution (MTAA) to recognize the three signatures simultaneously. MTAA contains perturbation extraction module, adversarial-only extraction module and classification and regression module. It takes the relationship between attack algorithm and corresponding hyperparameter into account and uses the uncertainty weighted loss to adjust the weights of three recognition tasks. The experimental results on MNIST and ImageNet show the feasibility and scalability of the proposed framework as well as its effectiveness in dealing with false alarms.
MRTNet: Multi-Resolution Temporal Network for Video Sentence Grounding
Dec 27, 2022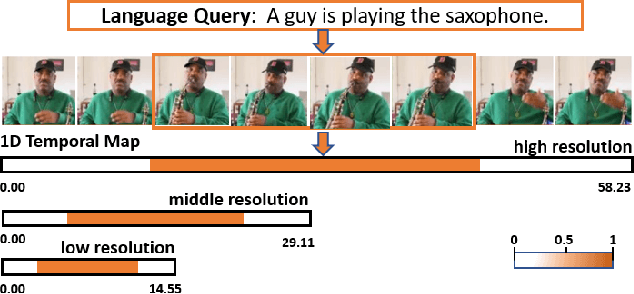
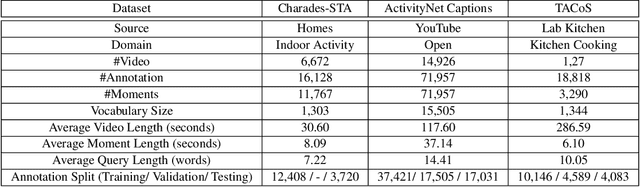
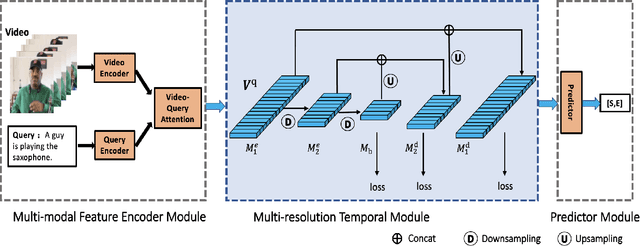

Given an untrimmed video and natural language query, video sentence grounding aims to localize the target temporal moment in the video. Existing methods mainly tackle this task by matching and aligning semantics of the descriptive sentence and video segments on a single temporal resolution, while neglecting the temporal consistency of video content in different resolutions. In this work, we propose a novel multi-resolution temporal video sentence grounding network: MRTNet, which consists of a multi-modal feature encoder, a Multi-Resolution Temporal (MRT) module, and a predictor module. MRT module is an encoder-decoder network, and output features in the decoder part are in conjunction with Transformers to predict the final start and end timestamps. Particularly, our MRT module is hot-pluggable, which means it can be seamlessly incorporated into any anchor-free models. Besides, we utilize a hybrid loss to supervise cross-modal features in MRT module for more accurate grounding in three scales: frame-level, clip-level and sequence-level. Extensive experiments on three prevalent datasets have shown the effectiveness of MRTNet.
Multi-queue Momentum Contrast for Microvideo-Product Retrieval
Dec 22, 2022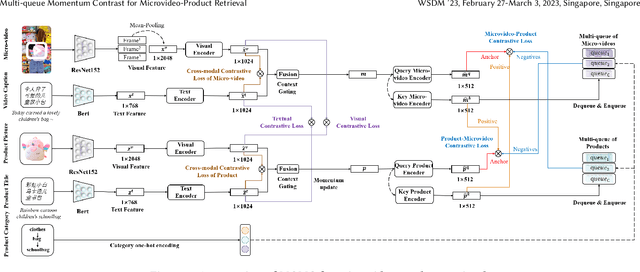
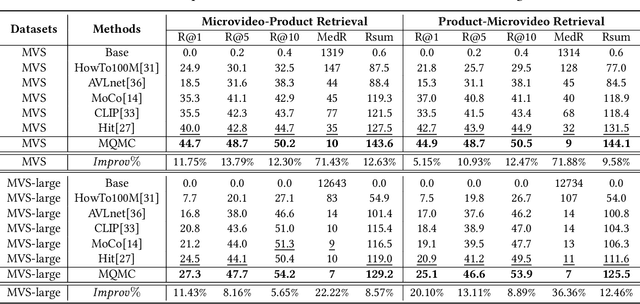
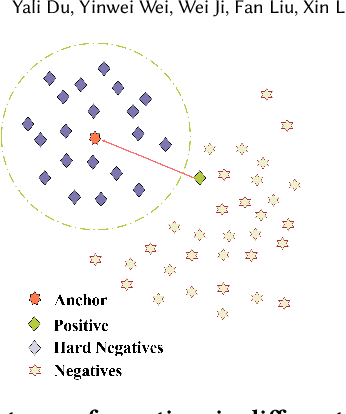
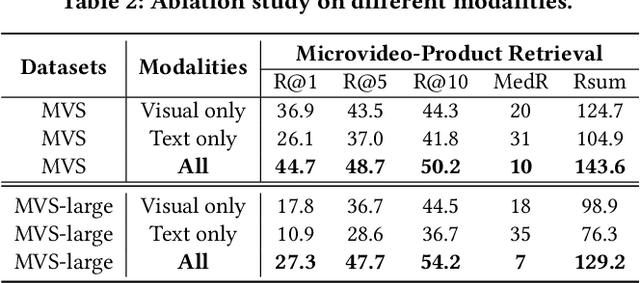
The booming development and huge market of micro-videos bring new e-commerce channels for merchants. Currently, more micro-video publishers prefer to embed relevant ads into their micro-videos, which not only provides them with business income but helps the audiences to discover their interesting products. However, due to the micro-video recording by unprofessional equipment, involving various topics and including multiple modalities, it is challenging to locate the products related to micro-videos efficiently, appropriately, and accurately. We formulate the microvideo-product retrieval task, which is the first attempt to explore the retrieval between the multi-modal and multi-modal instances. A novel approach named Multi-Queue Momentum Contrast (MQMC) network is proposed for bidirectional retrieval, consisting of the uni-modal feature and multi-modal instance representation learning. Moreover, a discriminative selection strategy with a multi-queue is used to distinguish the importance of different negatives based on their categories. We collect two large-scale microvideo-product datasets (MVS and MVS-large) for evaluation and manually construct the hierarchical category ontology, which covers sundry products in daily life. Extensive experiments show that MQMC outperforms the state-of-the-art baselines. Our replication package (including code, dataset, etc.) is publicly available at https://github.com/duyali2000/MQMC.