 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Adversarial Training with Transformers
Jun 05, 2022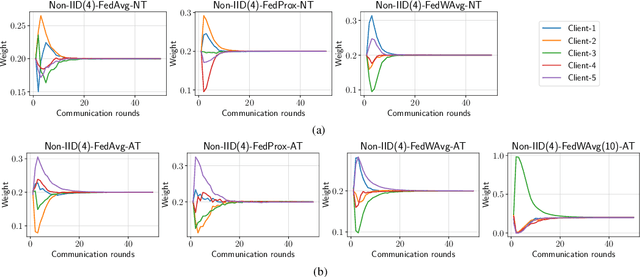
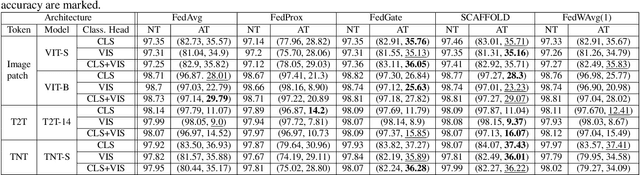
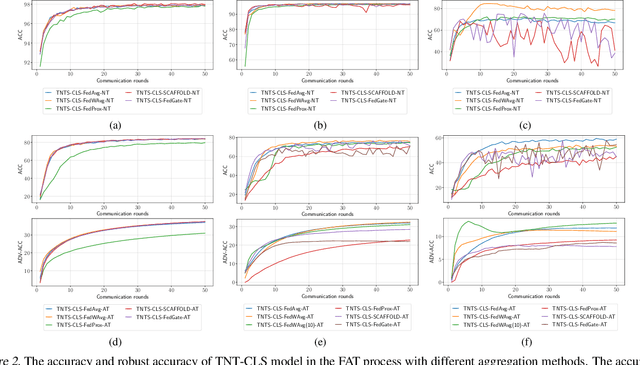
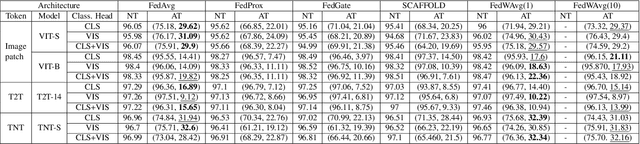
Federated learning (FL) has emerged to enable global model training over distributed clients' data while preserving its privacy. However, the global trained model is vulnerable to the evasion attacks especially, the adversarial examples (AEs), carefully crafted samples to yield false classification. Adversarial training (AT) is found to be the most promising approach against evasion attacks and it is widely studied for convolutional neural network (CNN). Recently, vision transformers have been found to be effective in many computer vision tasks. To the best of the authors' knowledge, there is no work that studied the feasibility of AT in a FL process for vision transformers. This paper investigates such feasibility with different federated model aggregation methods and different vision transformer models with different tokenization and classification head techniques. In order to improve the robust accuracy of the models with the not independent and identically distributed (Non-IID), we propose an extension to FedAvg aggregation method, called FedWAvg. By measuring the similarities between the last layer of the global model and the last layer of the client updates, FedWAvg calculates the weights to aggregate the local models updates. The experiments show that FedWAvg improves the robust accuracy when compared with other state-of-the-art aggregation methods.
OpenVVC: a Lightweight Software Decoder for the Versatile Video Coding Standard
May 24, 2022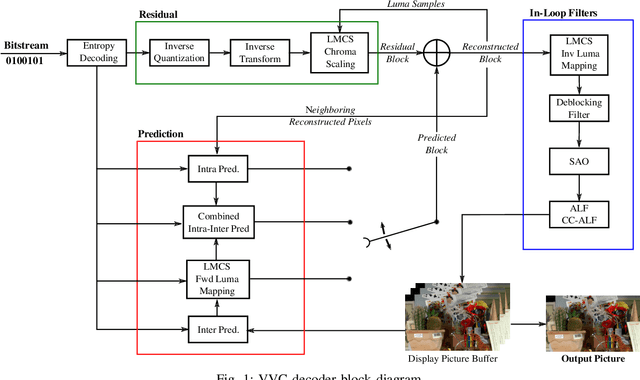
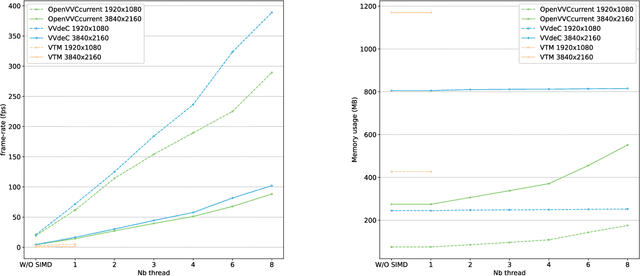
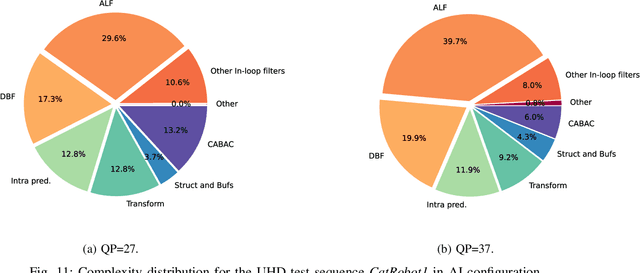
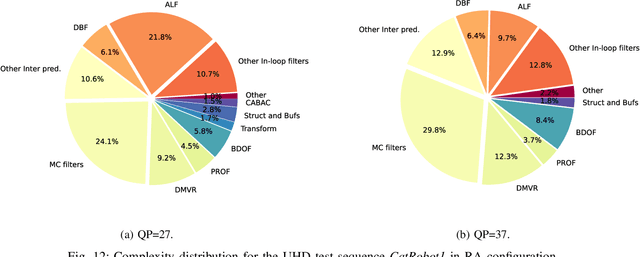
In the recent years, users requirements for higher resolution, coupled with the apparition of new multimedia applications, have created the need for a new video coding standard. The new generation video coding standard, called Versatile Video Coding (VVC), has been developed by the Joint Video Experts Team, and offers coding capability beyond the previous generation High Efficiency Video Coding (HEVC) standard. Due to the incorporation of more advanced and complex tools, the decoding complexity of VVC standard compared to HEVC has approximately doubled. This complexity increase raises new research challenges to achieve live software decoding. In this context, we developed OpenVVC, an open-source software decoder that supports a broad range of VVC functionalities. This paper presents the OpenVVC software architecture, its parallelism strategy as well as a detailed set of experimental results. By combining extensive data level parallelism with frame level parallelism, OpenVVC achieves real-time decoding of UHD video content. Moreover, the memory required by OpenVVC is remarkably low, which presents a great advantage for its integration on embedded platforms with low memory resources. The code of the OpenVVC decoder is publicly available at https://github.com/OpenVVC/OpenVVC
CAESR: Conditional Autoencoder and Super-Resolution for Learned Spatial Scalability
Feb 01, 2022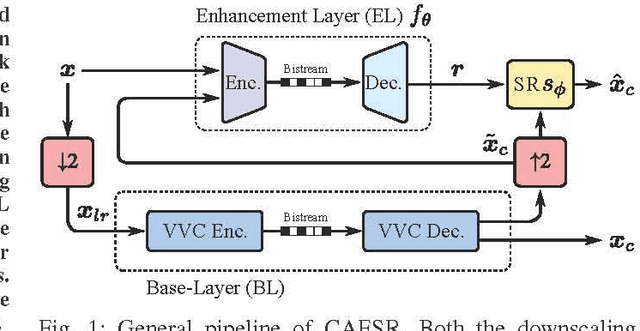
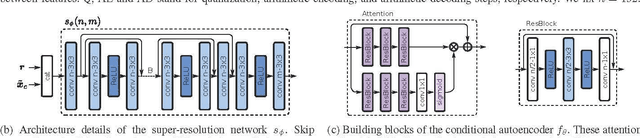
In this paper, we present CAESR, an hybrid learning-based coding approach for spatial scalability based on the versatile video coding (VVC) standard. Our framework considers a low-resolution signal encoded with VVC intra-mode as a base-layer (BL), and a deep conditional autoencoder with hyperprior (AE-HP) as an enhancement-layer (EL) model. The EL encoder takes as inputs both the upscaled BL reconstruction and the original image. Our approach relies on conditional coding that learns the optimal mixture of the source and the upscaled BL image, enabling better performance than residual coding. On the decoder side, a super-resolution (SR) module is used to recover high-resolution details and invert the conditional coding process. Experimental results have shown that our solution is competitive with the VVC full-resolution intra coding while being scalable.
Prediction-Aware Quality Enhancement of VVC Using CNN
Dec 08, 2021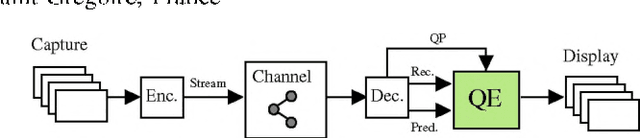

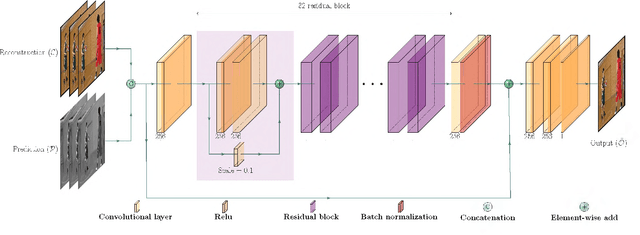
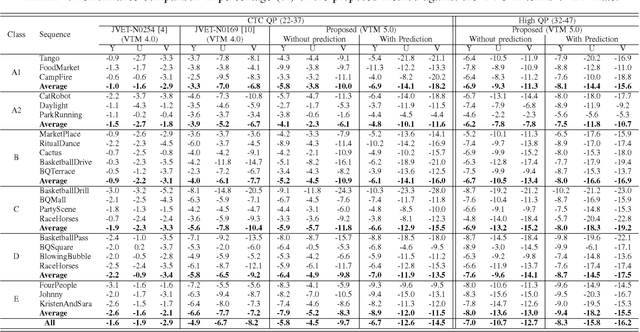
The upcoming video coding standard, Versatile Video Coding (VVC), has shown great improvement compared to its predecessor, High Efficiency Video Coding (HEVC), in terms of bitrate saving. Despite its substantial performance, compressed videos might still suffer from quality degradation at low bitrates due to coding artifacts such as blockiness, blurriness and ringing. In this work, we exploit Convolutional Neural Networks (CNN) to enhance quality of VVC coded frames after decoding in order to reduce low bitrate artifacts. The main contribution of this work is the use of coding information from the compressed bitstream. More precisely, the prediction information of intra frames is used for training the network in addition to the reconstruction information. The proposed method is applied on both luminance and chrominance components of intra coded frames of VVC. Experiments on VVC Test Model (VTM) show that, both in low and high bitrates, the use of coding information can improve the BD-rate performance by about 1% and 6% for luma and chroma components, respectively.
Perceptual Quality Assessment of HEVC and VVC Standards for 8K Video
Sep 17, 2021
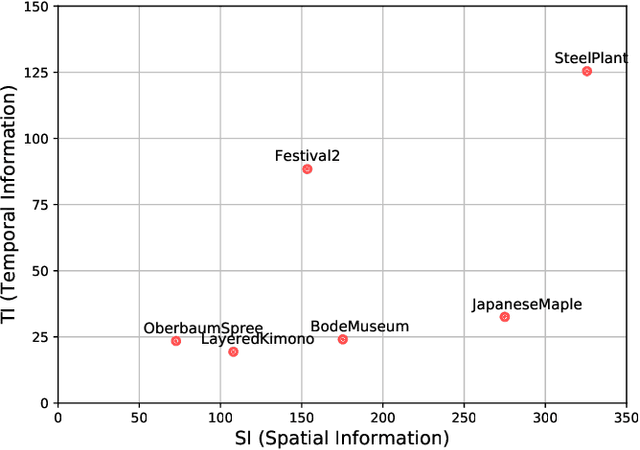
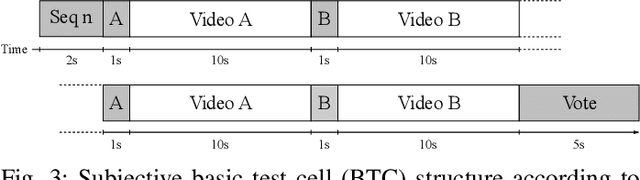

With the growing data consumption of emerging video applications and users requirement for higher resolutions, up to 8K, a huge effort has been made in video compression technologies. Recently, versatile video coding (VVC) has been standardized by the moving picture expert group (MPEG), providing a significant improvement in compression performance over its predecessor high efficiency video coding (HEVC). In this paper, we provide a comparative subjective quality evaluation between VVC and HEVC standards for 8K resolution videos. In addition, we evaluate the perceived quality improvement offered by 8K over UHD 4K resolution. The compression performance of both VVC and HEVC standards has been conducted in random access (RA) coding configuration, using their respective reference software, VVC test model (VTM-11) and HEVC test model (HM-16.20). Objective measurements, using PSNR, MS-SSIM and VMAF metrics have shown that the bitrate gains offered by VVC over HEVC for 8K video content are around 31%, 26% and 35%, respectively. Subjectively, VVC offers an average of 40% of bitrate reduction over HEVC for the same visual quality. A compression gain of 50% has been reached for some tested video sequences regarding a Student t-test analysis. In addition, for most tested scenes, a significant visual difference between uncompressed 4K and 8K has been noticed.
Lightweight Hardware Design of the Inverse Transform Module for 4K ASIC VVC Decoders
Jul 24, 2021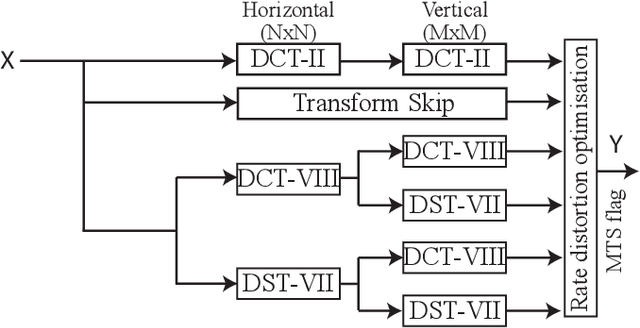
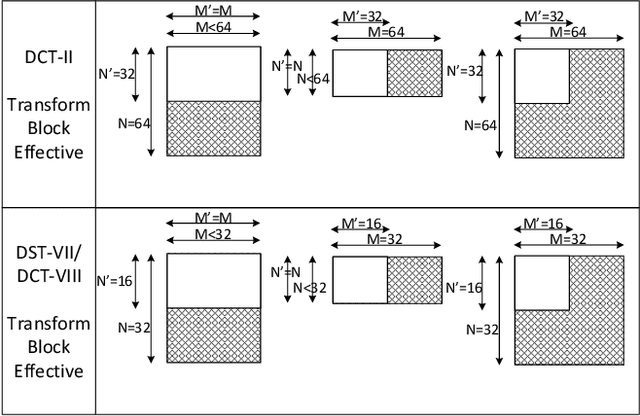
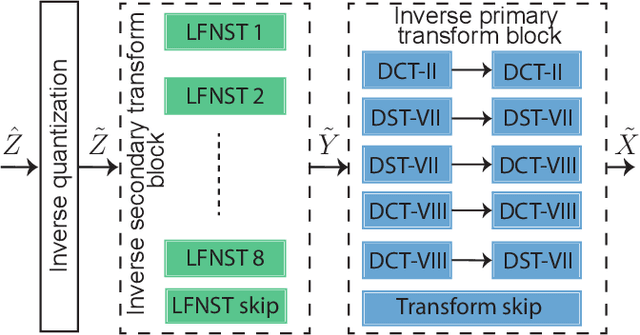
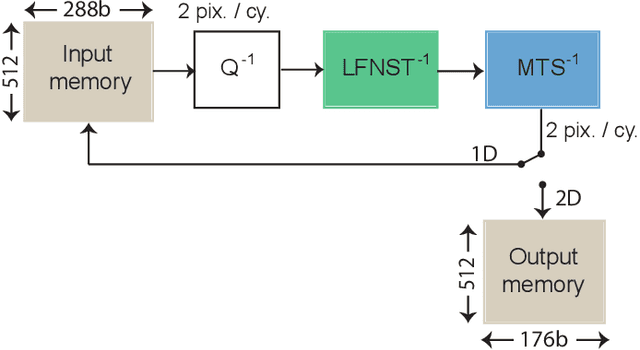
Versatile Video Coding (VVC) is the next generation video coding standard finalized in July 2020. VVC introduces new coding tools enhancing the coding efficiency compared to its predecessor High Efficiency Video Coding (HEVC). These new tools have a significant impact on the VVC software decoder complexity estimated to 2 times HEVC decoder complexity. In particular, the transform module includes in VVC separable and non-separable transforms named Multiple Transform Selection (MTS) and Low Frequency Non-Separable Transform (LFNST) tools, respectively. In this paper, we present an area-efficient hardware architecture of the inverse transform module for a VVC decoder. The proposed design uses a total of 64 regular multipliers in a pipelined architecture targeting ASIC platforms. It consists in a multi-standard architecture that supports the transform modules of recent MPEG standards including AVC, HEVC and VVC. The architecture leverages all primary and secondary transforms optimisations including butterfly decomposition, coefficients zeroing and the inherent linear relationship between the transforms. The synthesized results show that the proposed method sustains a constant throughput of 1 sample per cycle and a constant latency for all block sizes. The proposed hardware inverse transform module operates at 600 MHz frequency enabling to decode in real-time 4K video at 30 frames per second in 4:2:2 chroma sub-sampling format. The proposed module is integrated in an ASIC UHD decoder targeting energy-aware decoding of VVC videos on consumer devices.
Learning Vision Transformer with Squeeze and Excitation for Facial Expression Recognition
Jul 16, 2021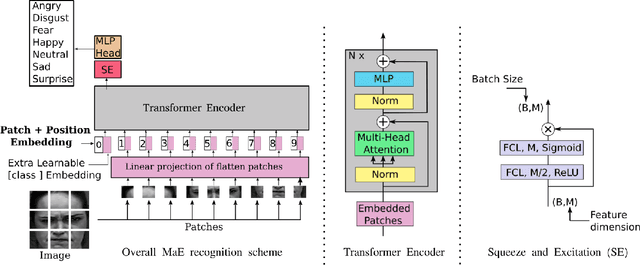
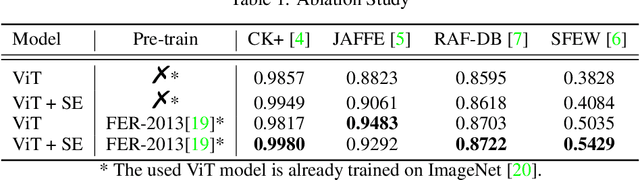
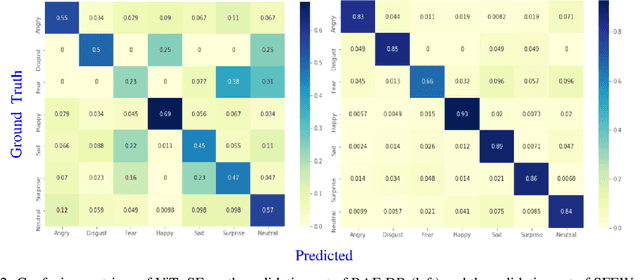
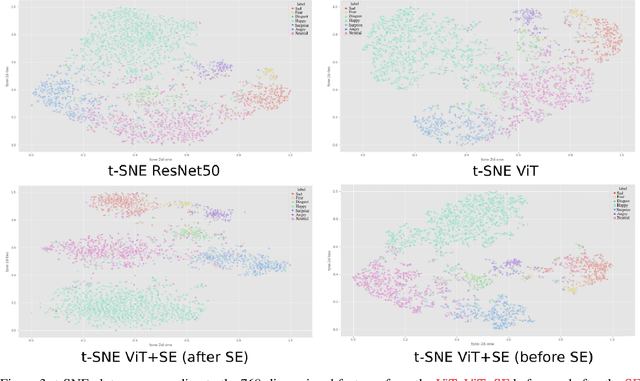
As various databases of facial expressions have been made accessible over the last few decades, the Facial Expression Recognition (FER) task has gotten a lot of interest. The multiple sources of the available databases raised several challenges for facial recognition task. These challenges are usually addressed by Convolution Neural Network (CNN) architectures. Different from CNN models, a Transformer model based on attention mechanism has been presented recently to address vision tasks. One of the major issue with Transformers is the need of a large data for training, while most FER databases are limited compared to other vision applications. Therefore, we propose in this paper to learn a vision Transformer jointly with a Squeeze and Excitation (SE) block for FER task. The proposed method is evaluated on different publicly available FER databases including CK+, JAFFE,RAF-DB and SFEW. Experiments demonstrate that our model outperforms state-of-the-art methods on CK+ and SFEW and achieves competitive results on JAFFE and RAF-DB.
Detect and Defense Against Adversarial Examples in Deep Learning using Natural Scene Statistics and Adaptive Denoising
Jul 12, 2021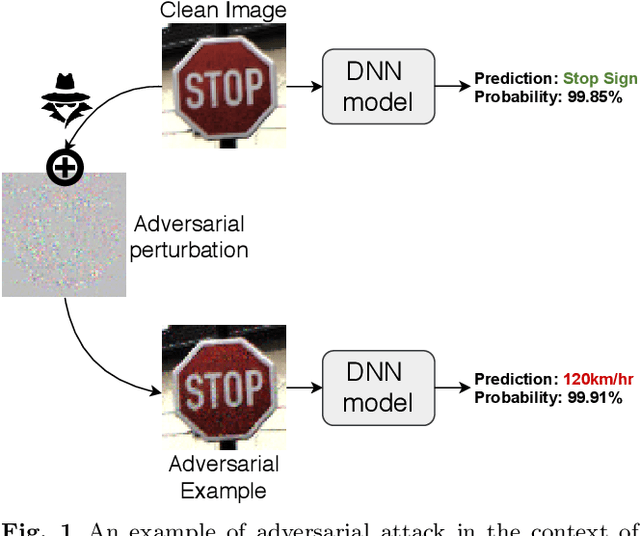
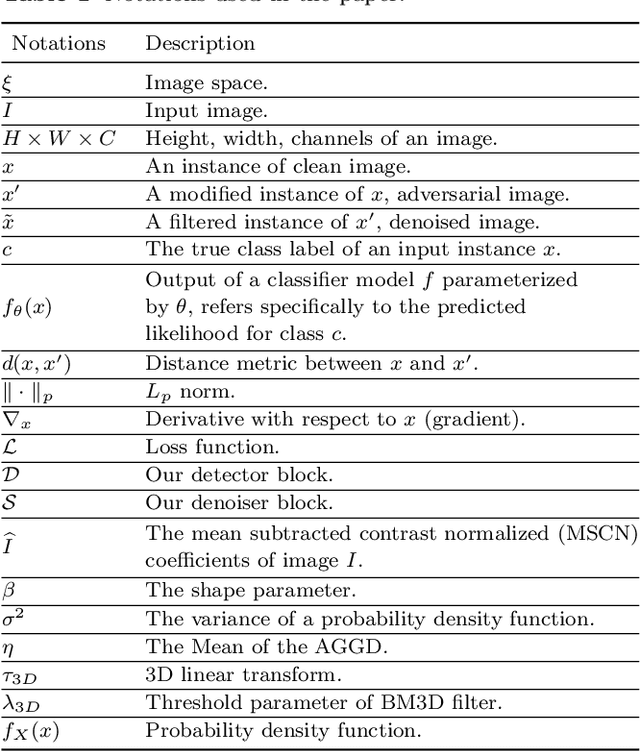
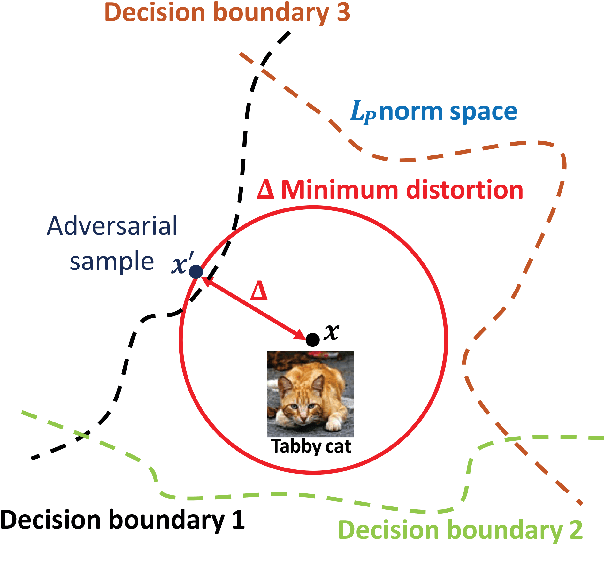
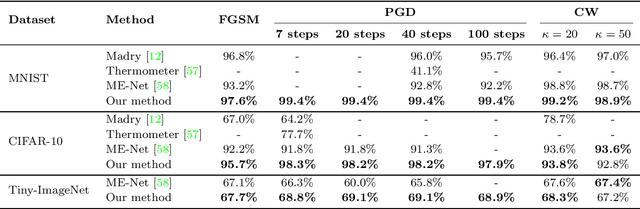
Despite the enormous performance of deepneural networks (DNNs), recent studies have shown theirvulnerability to adversarial examples (AEs), i.e., care-fully perturbed inputs designed to fool the targetedDNN. Currently, the literature is rich with many ef-fective attacks to craft such AEs. Meanwhile, many de-fenses strategies have been developed to mitigate thisvulnerability. However, these latter showed their effec-tiveness against specific attacks and does not general-ize well to different attacks. In this paper, we proposea framework for defending DNN classifier against ad-versarial samples. The proposed method is based on atwo-stage framework involving a separate detector anda denoising block. The detector aims to detect AEs bycharacterizing them through the use of natural scenestatistic (NSS), where we demonstrate that these statis-tical features are altered by the presence of adversarialperturbations. The denoiser is based on block matching3D (BM3D) filter fed by an optimum threshold valueestimated by a convolutional neural network (CNN) toproject back the samples detected as AEs into theirdata manifold. We conducted a complete evaluation onthree standard datasets namely MNIST, CIFAR-10 andTiny-ImageNet. The experimental results show that theproposed defense method outperforms the state-of-the-art defense techniques by improving the robustnessagainst a set of attacks under black-box, gray-box and white-box settings. The source code is available at: https://github.com/kherchouche-anouar/2DAE
Versatile Video Coding Standard: A Review from Coding Tools to Consumers Deployment
Jun 27, 2021
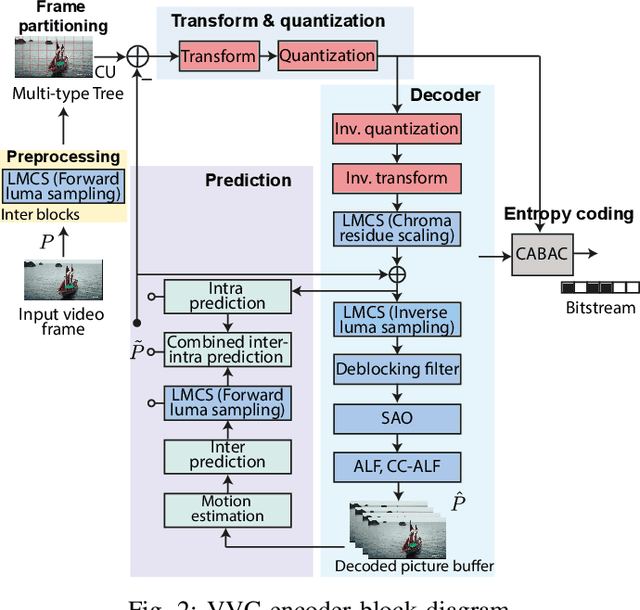
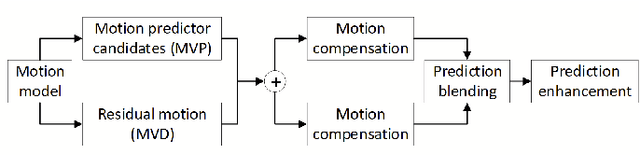
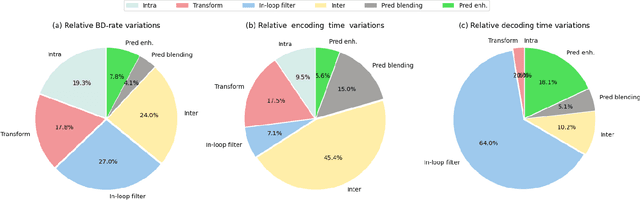
The amount of video content and the number of applications based on multimedia information increase each day. The development of new video coding standards is a challenge to increase the compression rate and other important features with a reasonable increase in the computational load. Video Experts Team (JVET) of ITU-T and the JCT group within ISO/IEC have worked together to standardize the Versatile Video Coding, approved finally in July 2020 as ITU-T H.266 | MPEG-I - Part 3 (ISO/IEC 23090-3) standard. This paper overviews some interesting consumer electronic use cases, the compression tools described in the standard, the current available real time implementations and the first industrial trials done with this standard.
Reveal of Vision Transformers Robustness against Adversarial Attacks
Jun 07, 2021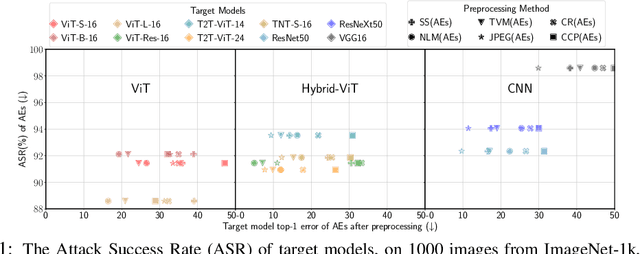
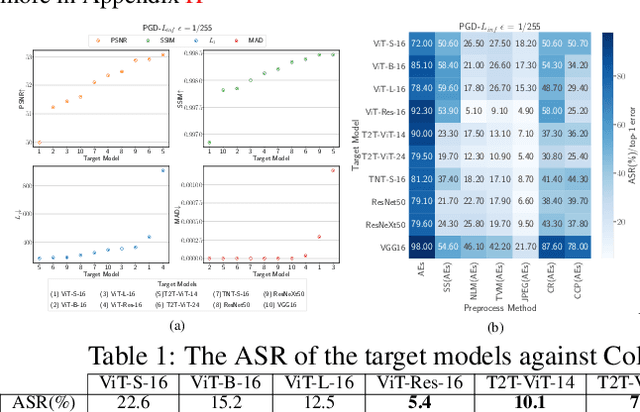
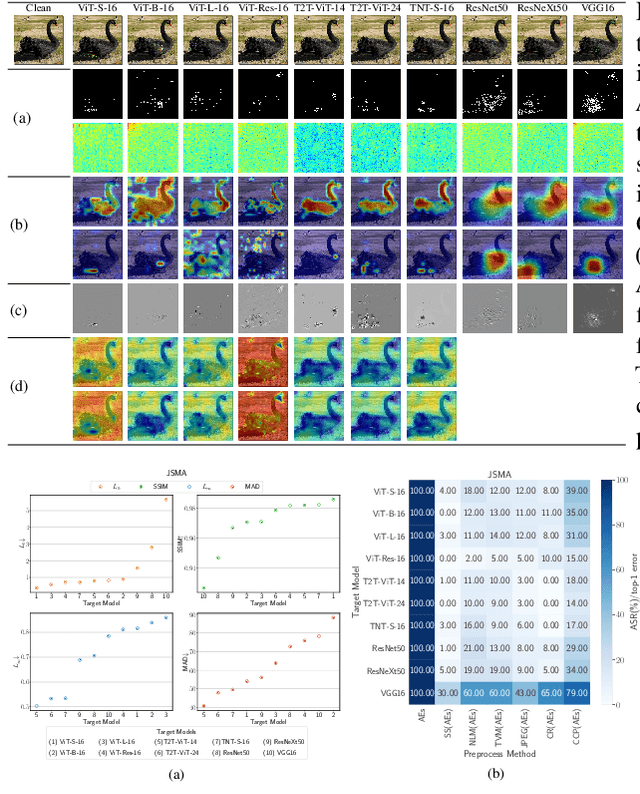
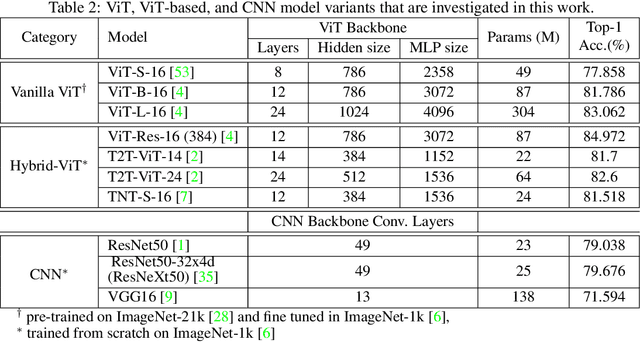
Attention-based networks have achieved state-of-the-art performance in many computer vision tasks, such as image classification. Unlike Convolutional Neural Network (CNN), the major part of the vanilla Vision Transformer (ViT) is the attention block that brings the power of mimicking the global context of the input image. This power is data hunger and hence, the larger the training data the better the performance. To overcome this limitation, many ViT-based networks, or hybrid-ViT, have been proposed to include local context during the training. The robustness of ViTs and its variants against adversarial attacks has not been widely invested in the literature. Some robustness attributes were revealed in few previous works and hence, more insight robustness attributes are yet unrevealed. This work studies the robustness of ViT variants 1) against different $L_p$-based adversarial attacks in comparison with CNNs and 2) under Adversarial Examples (AEs) after applying preprocessing defense methods. To that end, we run a set of experiments on 1000 images from ImageNet-1k and then provide an analysis that reveals that vanilla ViT or hybrid-ViT are more robust than CNNs. For instance, we found that 1) Vanilla ViTs or hybrid-ViTs are more robust than CNNs under $L_0$, $L_1$, $L_2$, $L_\infty$-based, and Color Channel Perturbations (CCP) attacks. 2) Vanilla ViTs are not responding to preprocessing defenses that mainly reduce the high frequency components while, hybrid-ViTs are more responsive to such defense. 3) CCP can be used as a preprocessing defense and larger ViT variants are found to be more responsive than other models. Furthermore, feature maps, attention maps, and Grad-CAM visualization jointly with image quality measures, and perturbations' energy spectrum are provided for an insight understanding of attention-based models.