 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensorFlow Agents: Efficient Batched Reinforcement Learning in TensorFlow
Oct 31, 2018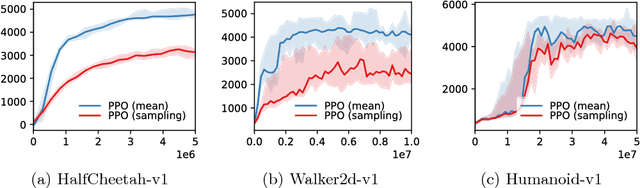
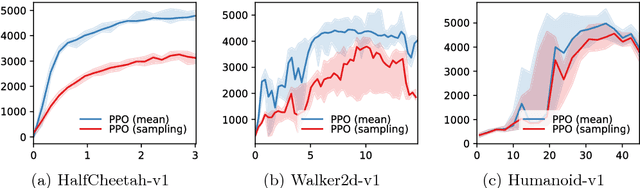
We introduce TensorFlow Agents, an efficient infrastructure paradigm for building parallel reinforcement learning algorithms in TensorFlow. We simulate multiple environments in parallel, and group them to perform the neural network computation on a batch rather than individual observations. This allows the TensorFlow execution engine to parallelize computation, without the need for manual synchronization. Environments are stepped in separate Python processes to progress them in parallel without interference of the global interpreter lock. As part of this project, we introduce BatchPPO, an efficient implementation of the proximal policy optimization algorithm. By open sourcing TensorFlow Agents, we hope to provide a flexible starting point for future projects that accelerates future research in the field.
Classification of crystallization outcomes using deep convolutional neural networks
May 26, 2018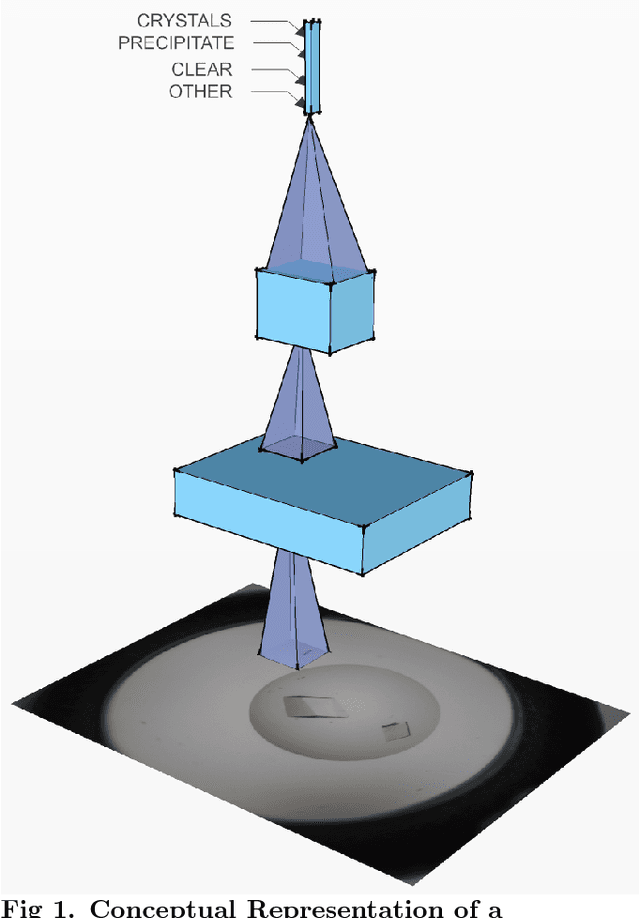
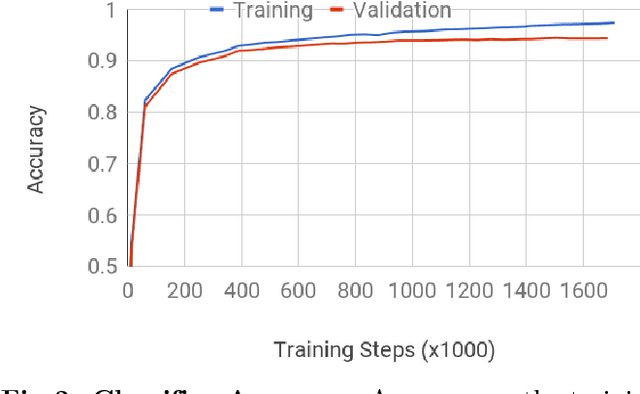
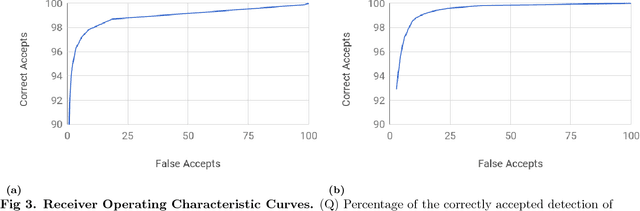
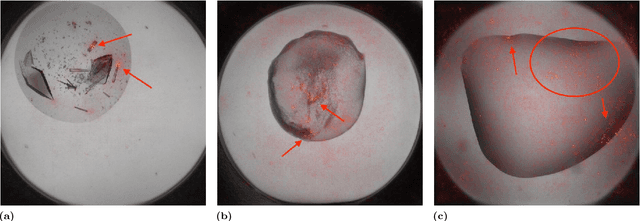
The Machine Recognition of Crystallization Outcomes (MARCO) initiative has assembled roughly half a million annotated images of macromolecular crystallization experiments from various sources and setups. Here, state-of-the-art machine learning algorithms are trained and tested on different parts of this data set. We find that more than 94% of the test images can be correctly labeled, irrespective of their experimental origin. Because crystal recognition is key to high-density screening and the systematic analysis of crystallization experiments, this approach opens the door to both industrial and fundamental research applications.
Sim-to-Real: Learning Agile Locomotion For Quadruped Robots
May 16, 2018

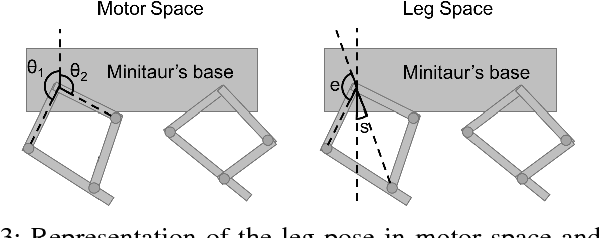
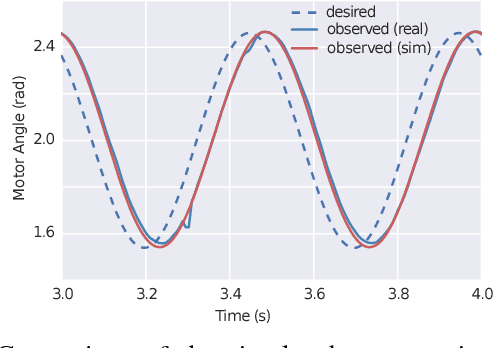
Designing agile locomotion for quadruped robots often requires extensive expertise and tedious manual tuning. In this paper, we present a system to automate this process by leveraging deep reinforcement learning techniques. Our system can learn quadruped locomotion from scratch using simple reward signals. In addition, users can provide an open loop reference to guide the learning process when more control over the learned gait is needed. The control policies are learned in a physics simulator and then deployed on real robots. In robotics, policies trained in simulation often do not transfer to the real world. We narrow this reality gap by improving the physics simulator and learning robust policies. We improve the simulation using system identification, developing an accurate actuator model and simulating latency. We learn robust controllers by randomizing the physical environments, adding perturbations and designing a compact observation space. We evaluate our system on two agile locomotion gaits: trotting and galloping. After learning in simulation, a quadruped robot can successfully perform both gaits in the real world.
Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping
Sep 25, 2017


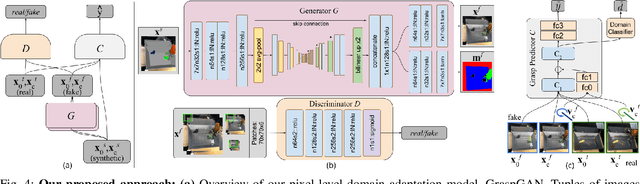
Instrumenting and collecting annotated visual grasping datasets to train modern machine learning algorithms can be extremely time-consuming and expensive. An appealing alternative is to use off-the-shelf simulators to render synthetic data for which ground-truth annotations are generated automatically. Unfortunately, models trained purely on simulated data often fail to generalize to the real world. We study how randomized simulated environments and domain adaptation methods can be extended to train a grasping system to grasp novel objects from raw monocular RGB images. We extensively evaluate our approaches with a total of more than 25,000 physical test grasps, studying a range of simulation conditions and domain adaptation methods, including a novel extension of pixel-level domain adaptation that we term the GraspGAN. We show that, by using synthetic data and domain adaptation, we are able to reduce the number of real-world samples needed to achieve a given level of performance by up to 50 times, using only randomly generated simulated objects. We also show that by using only unlabeled real-world data and our GraspGAN methodology, we obtain real-world grasping performance without any real-world labels that is similar to that achieved with 939,777 labeled real-world samples.
YouTube-BoundingBoxes: A Large High-Precision Human-Annotated Data Set for Object Detection in Video
Mar 24, 2017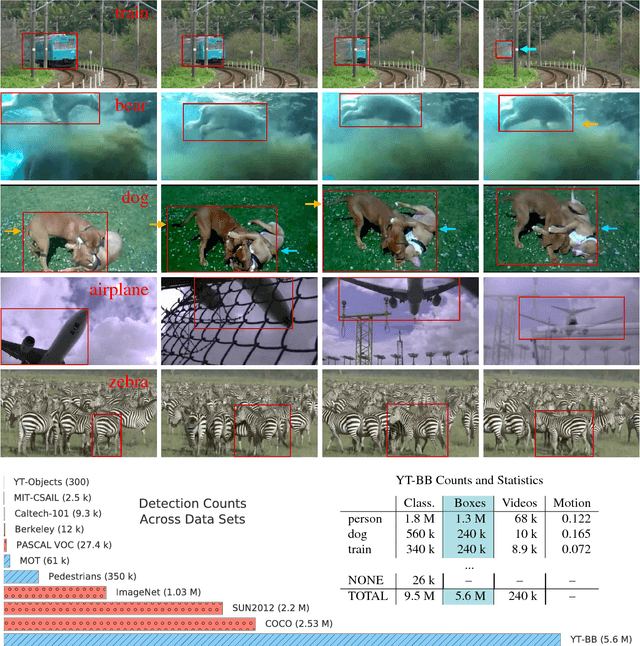
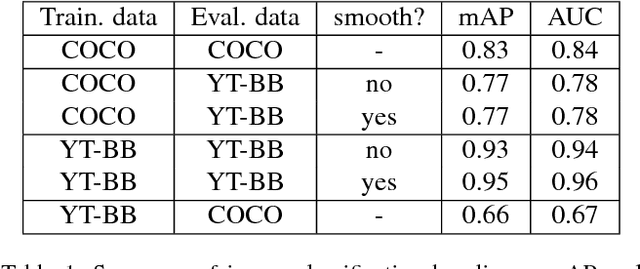
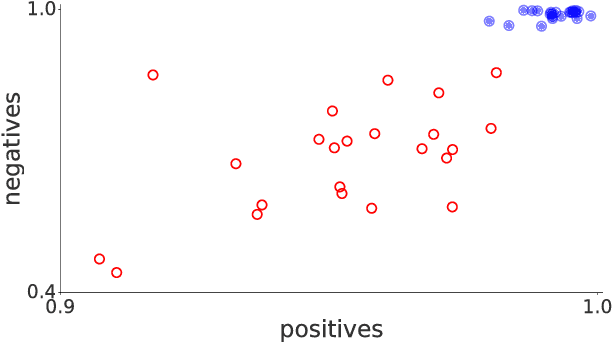

We introduce a new large-scale data set of video URLs with densely-sampled object bounding box annotations called YouTube-BoundingBoxes (YT-BB). The data set consists of approximately 380,000 video segments about 19s long, automatically selected to feature objects in natural settings without editing or post-processing, with a recording quality often akin to that of a hand-held cell phone camera. The objects represent a subset of the MS COCO label set. All video segments were human-annotated with high-precision classification labels and bounding boxes at 1 frame per second. The use of a cascade of increasingly precise human annotations ensures a label accuracy above 95% for every class and tight bounding boxes. Finally, we train and evaluate well-known deep network architectures and report baseline figures for per-frame classification and localization to provide a point of comparison for future work. We also demonstrate how the temporal contiguity of video can potentially be used to improve such inferences. Please see the PDF file to find the URL to download the data. We hope the availability of such large curated corpus will spur new advances in video object detection and tracking.
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
Aug 23, 2016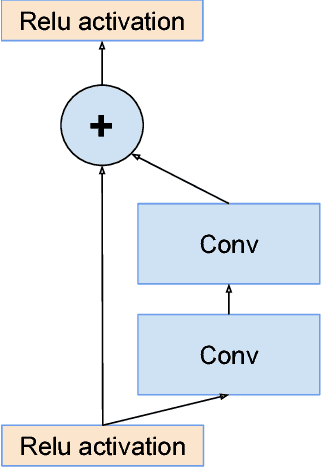
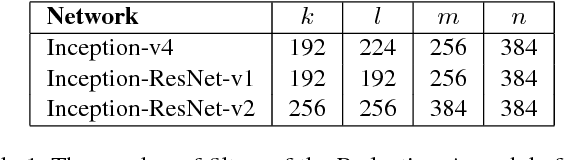
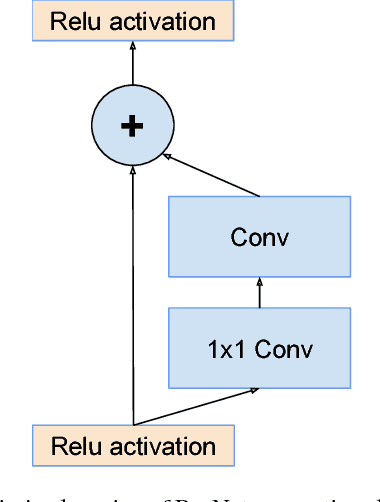
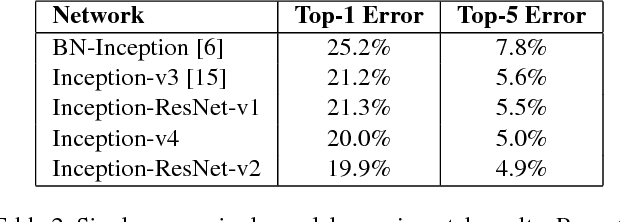
Very deep convolutional networks have been central to the largest advances in image recognition performance in recent years. One example is the Inception architecture that has been shown to achieve very good performance at relatively low computational cost. Recently, the introduction of residual connections in conjunction with a more traditional architecture has yielded state-of-the-art performance in the 2015 ILSVRC challenge; its performance was similar to the latest generation Inception-v3 network. This raises the question of whether there are any benefit in combining the Inception architecture with residual connections. Here we give clear empirical evidence that training with residual connections accelerates the training of Inception networks significantly. There is also some evidence of residual Inception networks outperforming similarly expensive Inception networks without residual connections by a thin margin. We also present several new streamlined architectures for both residual and non-residual Inception networks. These variations improve the single-frame recognition performance on the ILSVRC 2012 classification task significantly. We further demonstrate how proper activation scaling stabilizes the training of very wide residual Inception networks. With an ensemble of three residual and one Inception-v4, we achieve 3.08 percent top-5 error on the test set of the ImageNet classification (CLS) challenge
TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
Mar 16, 2016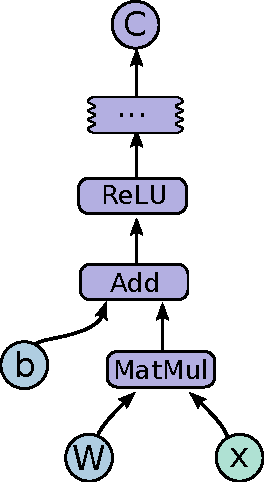

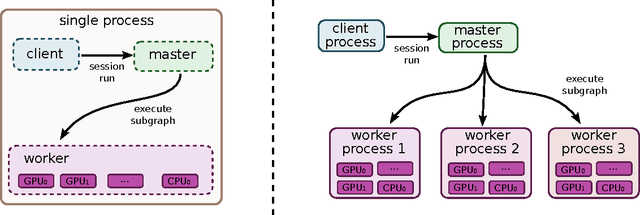
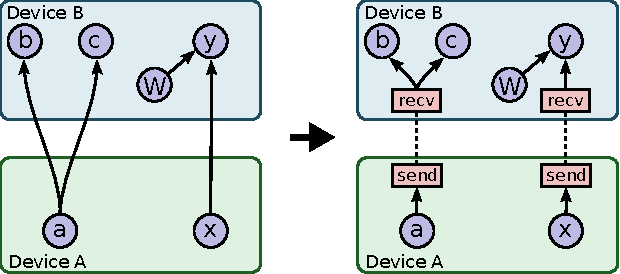
TensorFlow is an interface for expressing machine learning algorithms, and an implementation for executing such algorithms. A computation expressed using TensorFlow can be executed with little or no change on a wide variety of heterogeneous systems, ranging from mobile devices such as phones and tablets up to large-scale distributed systems of hundreds of machines and thousands of computational devices such as GPU cards. The system is flexible and can be used to express a wide variety of algorithms, including training and inference algorithms for deep neural network models, and it has been used for conducting research and for deploying machine learning systems into production across more than a dozen areas of computer science and other fields, including speech recognition, computer vision, robotics, information retrieval, natural language processing, geographic information extraction, and computational drug discovery. This paper describes the TensorFlow interface and an implementation of that interface that we have built at Google. The TensorFlow API and a reference implementation were released as an open-source package under the Apache 2.0 license in November, 2015 and are available at www.tensorflow.org.
Rethinking the Inception Architecture for Computer Vision
Dec 11, 2015
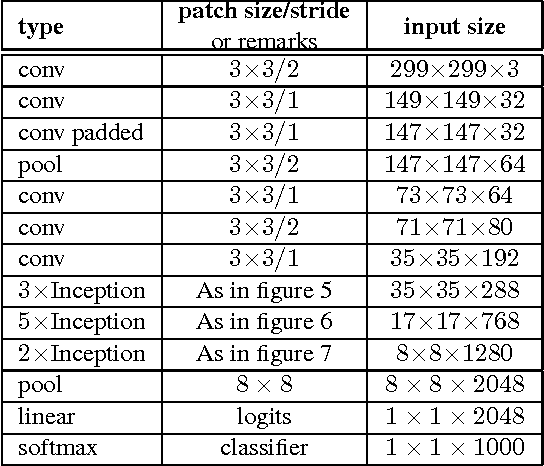
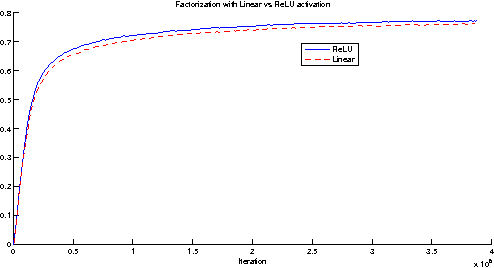
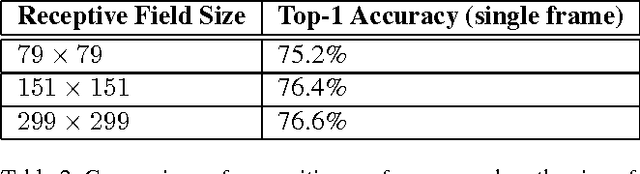
Convolutional networks are at the core of most state-of-the-art computer vision solutions for a wide variety of tasks. Since 2014 very deep convolutional networks started to become mainstream, yielding substantial gains in various benchmarks. Although increased model size and computational cost tend to translate to immediate quality gains for most tasks (as long as enough labeled data is provided for training), computational efficiency and low parameter count are still enabling factors for various use cases such as mobile vision and big-data scenarios. Here we explore ways to scale up networks in ways that aim at utilizing the added computation as efficiently as possible by suitably factorized convolutions and aggressive regularization. We benchmark our methods on the ILSVRC 2012 classification challenge validation set demonstrate substantial gains over the state of the art: 21.2% top-1 and 5.6% top-5 error for single frame evaluation using a network with a computational cost of 5 billion multiply-adds per inference and with using less than 25 million parameters. With an ensemble of 4 models and multi-crop evaluation, we report 3.5% top-5 error on the validation set (3.6% error on the test set) and 17.3% top-1 error on the validation set.
Going Deeper with Convolutions
Sep 17, 2014
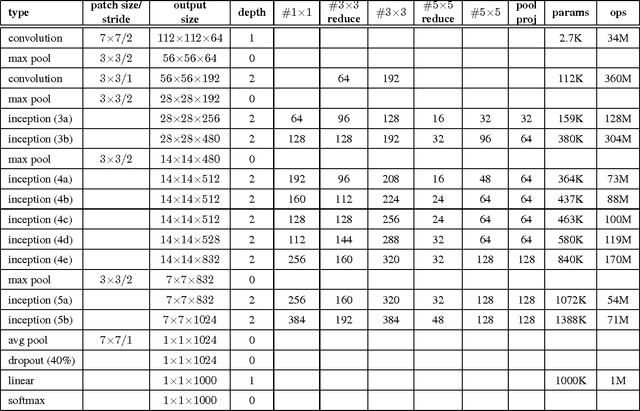
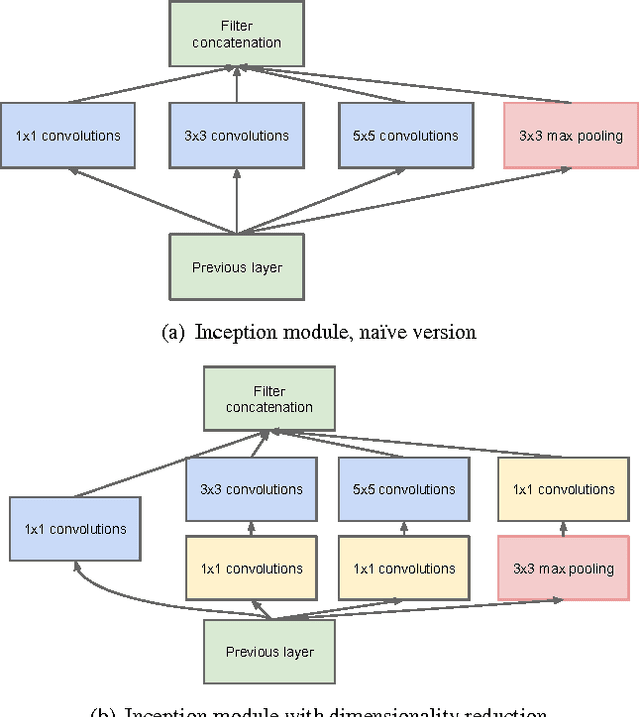
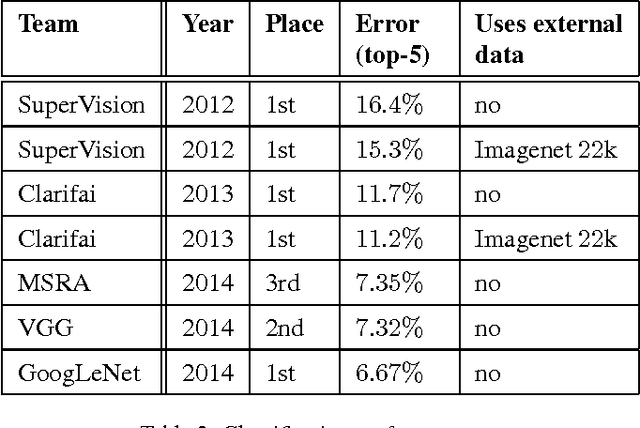
We propose a deep convolutional neural network architecture codenamed "Inception", which was responsible for setting the new state of the art for classification and detection in the ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC 2014). The main hallmark of this architecture is the improved utilization of the computing resources inside the network. This was achieved by a carefully crafted design that allows for increasing the depth and width of the network while keeping the computational budget constant. To optimize quality, the architectural decisions were based on the Hebbian principle and the intuition of multi-scale processing. One particular incarnation used in our submission for ILSVRC 2014 is called GoogLeNet, a 22 layers deep network, the quality of which is assessed in the context of classification and detection.