 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
EvoPrompting: Language Models for Code-Level Neural Architecture Search
Feb 28, 2023



Given the recent impressive accomplishments of language models (LMs) for code generation, we explore the use of LMs as adaptive mutation and crossover operators for an evolutionary neural architecture search (NAS) algorithm. While NAS still proves too difficult a task for LMs to succeed at solely through prompting, we find that the combination of evolutionary prompt engineering with soft prompt-tuning, a method we term EvoPrompting, consistently finds diverse and high performing models. We first demonstrate that EvoPrompting is effective on the computationally efficient MNIST-1D dataset, where EvoPrompting produces convolutional architecture variants that outperform both those designed by human experts and naive few-shot prompting in terms of accuracy and model size. We then apply our method to searching for graph neural networks on the CLRS Algorithmic Reasoning Benchmark, where EvoPrompting is able to design novel architectures that outperform current state-of-the-art models on 21 out of 30 algorithmic reasoning tasks while maintaining similar model size. EvoPrompting is successful at designing accurate and efficient neural network architectures across a variety of machine learning tasks, while also being general enough for easy adaptation to other tasks beyond neural network design.
Unified Functional Hashing in Automatic Machine Learning
Feb 10, 2023



The field of Automatic Machine Learning (AutoML) has recently attained impressive results, including the discovery of state-of-the-art machine learning solutions, such as neural image classifiers. This is often done by applying an evolutionary search method, which samples multiple candidate solutions from a large space and evaluates the quality of each candidate through a long training process. As a result, the search tends to be slow. In this paper, we show that large efficiency gains can be obtained by employing a fast unified functional hash, especially through the functional equivalence caching technique, which we also present. The central idea is to detect by hashing when the search method produces equivalent candidates, which occurs very frequently, and this way avoid their costly re-evaluation. Our hash is "functional" in that it identifies equivalent candidates even if they were represented or coded differently, and it is "unified" in that the same algorithm can hash arbitrary representations; e.g. compute graphs, imperative code, or lambda functions. As evidence, we show dramatic improvements on multiple AutoML domains, including neural architecture search and algorithm discovery. Finally, we consider the effect of hash collisions, evaluation noise, and search distribution through empirical analysis. Altogether, we hope this paper may serve as a guide to hashing techniques in AutoML.
Transcending Scaling Laws with 0.1% Extra Compute
Oct 20, 2022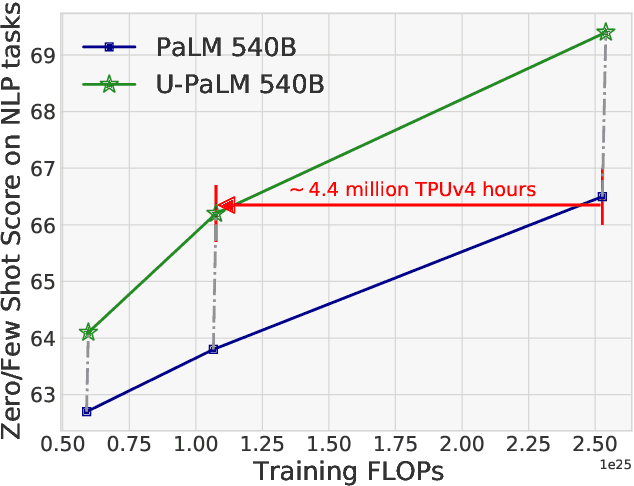
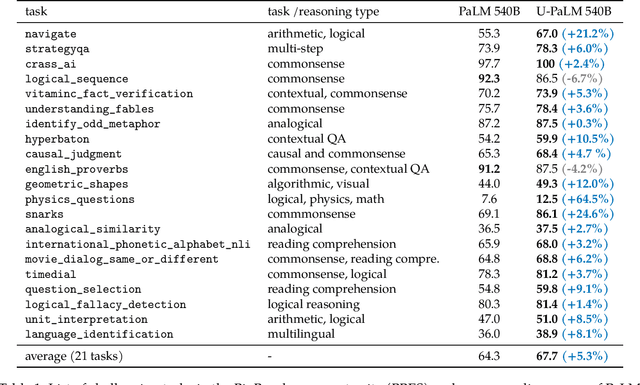
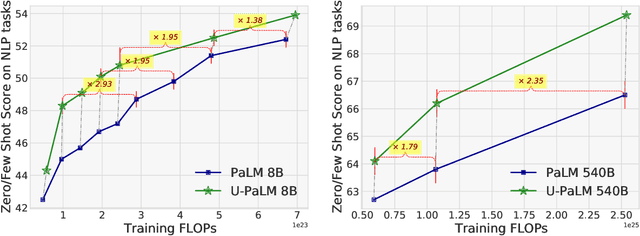
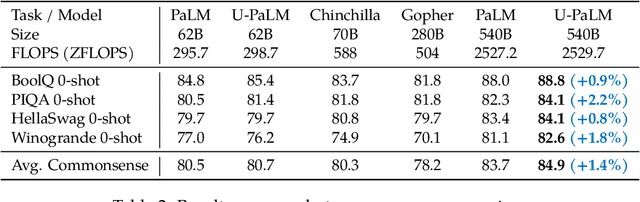
Scaling language models improves performance but comes with significant computational costs. This paper proposes UL2R, a method that substantially improves existing language models and their scaling curves with a relatively tiny amount of extra compute. The key idea is to continue training a state-of-the-art large language model (e.g., PaLM) on a few more steps with UL2's mixture-of-denoiser objective. We show that, with almost negligible extra computational costs and no new sources of data, we are able to substantially improve the scaling properties of large language models on downstream metrics. In this paper, we continue training PaLM with UL2R, introducing a new set of models at 8B, 62B, and 540B scale which we call U-PaLM. Impressively, at 540B scale, we show an approximately 2x computational savings rate where U-PaLM achieves the same performance as the final PaLM 540B model at around half its computational budget (i.e., saving $\sim$4.4 million TPUv4 hours). We further show that this improved scaling curve leads to 'emergent abilities' on challenging BIG-Bench tasks -- for instance, U-PaLM does much better than PaLM on some tasks or demonstrates better quality at much smaller scale (62B as opposed to 540B). Overall, we show that U-PaLM outperforms PaLM on many few-shot setups, i.e., English NLP tasks (e.g., commonsense reasoning, question answering), reasoning tasks with chain-of-thought (e.g., GSM8K), multilingual tasks (MGSM, TydiQA), MMLU and challenging BIG-Bench tasks. Finally, we provide qualitative examples showing the new capabilities of U-PaLM for single and multi-span infilling.
Primer: Searching for Efficient Transformers for Language Modeling
Sep 17, 2021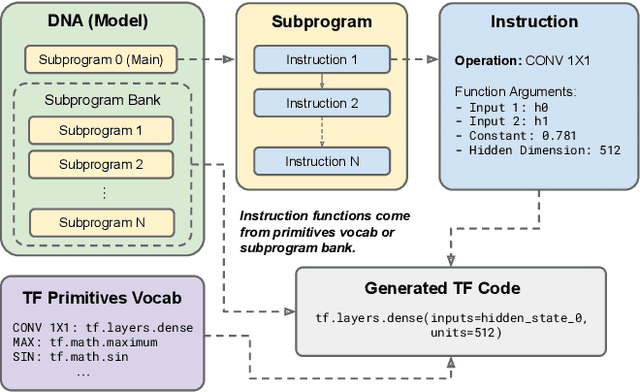
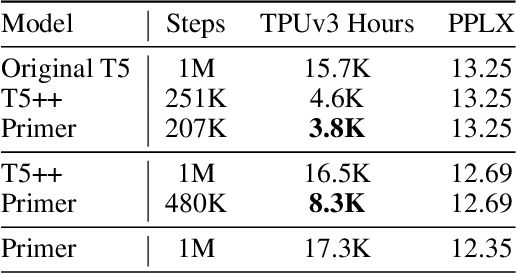
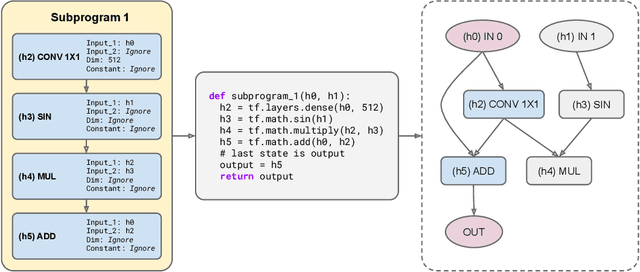
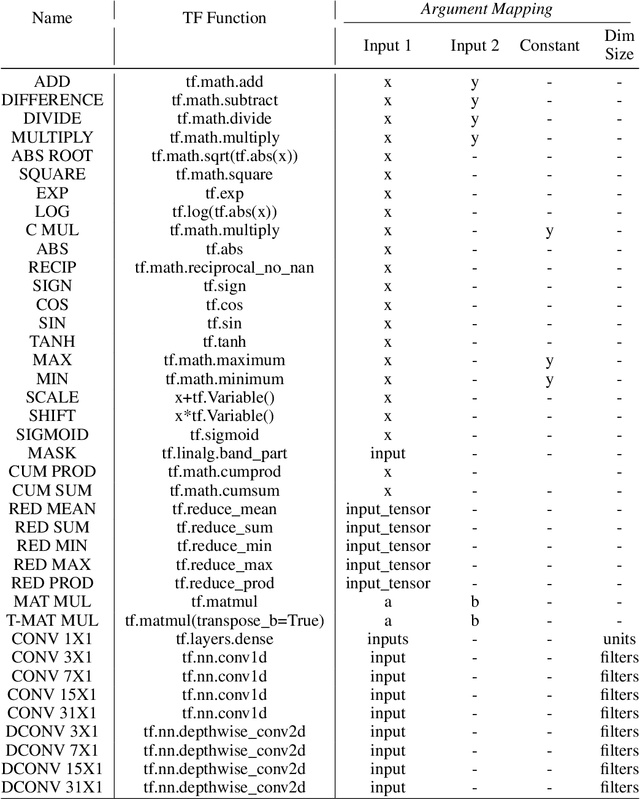
Large Transformer models have been central to recent advances in natural language processing. The training and inference costs of these models, however, have grown rapidly and become prohibitively expensive. Here we aim to reduce the costs of Transformers by searching for a more efficient variant. Compared to previous approaches, our search is performed at a lower level, over the primitives that define a Transformer TensorFlow program. We identify an architecture, named Primer, that has a smaller training cost than the original Transformer and other variants for auto-regressive language modeling. Primer's improvements can be mostly attributed to two simple modifications: squaring ReLU activations and adding a depthwise convolution layer after each Q, K, and V projection in self-attention. Experiments show Primer's gains over Transformer increase as compute scale grows and follow a power law with respect to quality at optimal model sizes. We also verify empirically that Primer can be dropped into different codebases to significantly speed up training without additional tuning. For example, at a 500M parameter size, Primer improves the original T5 architecture on C4 auto-regressive language modeling, reducing the training cost by 4X. Furthermore, the reduced training cost means Primer needs much less compute to reach a target one-shot performance. For instance, in a 1.9B parameter configuration similar to GPT-3 XL, Primer uses 1/3 of the training compute to achieve the same one-shot performance as Transformer. We open source our models and several comparisons in T5 to help with reproducibility.
Pay Attention to MLPs
Jun 01, 2021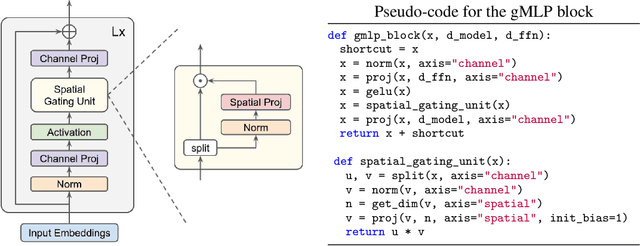
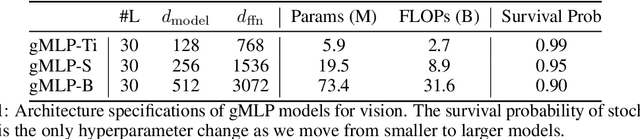
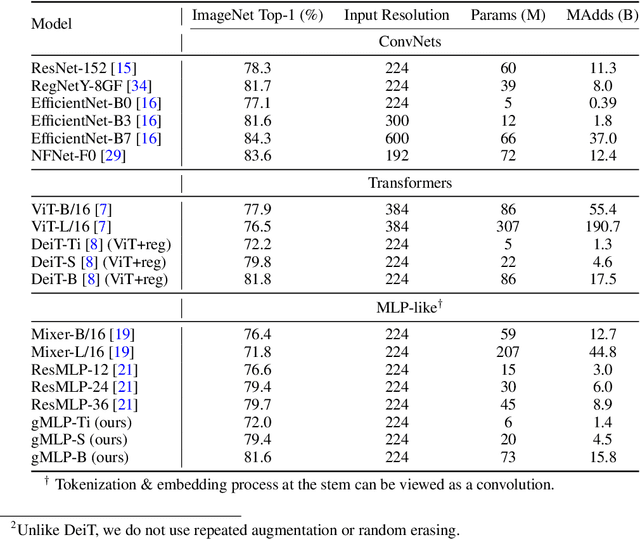
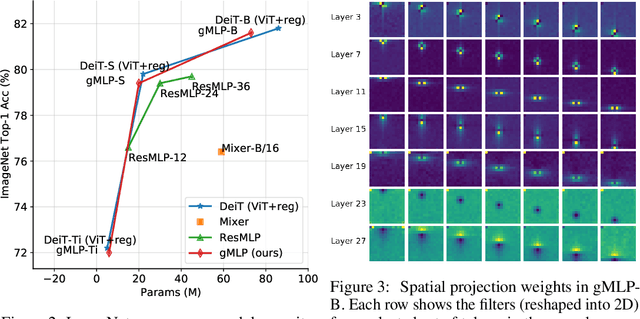
Transformers have become one of the most important architectural innovations in deep learning and have enabled many breakthroughs over the past few years. Here we propose a simple network architecture, gMLP, based on MLPs with gating, and show that it can perform as well as Transformers in key language and vision applications. Our comparisons show that self-attention is not critical for Vision Transformers, as gMLP can achieve the same accuracy. For BERT, our model achieves parity with Transformers on pretraining perplexity and is better on some downstream NLP tasks. On finetuning tasks where gMLP performs worse, making the gMLP model substantially larger can close the gap with Transformers. In general, our experiments show that gMLP can scale as well as Transformers over increased data and compute.
MUFASA: Multimodal Fusion Architecture Search for Electronic Health Records
Feb 03, 2021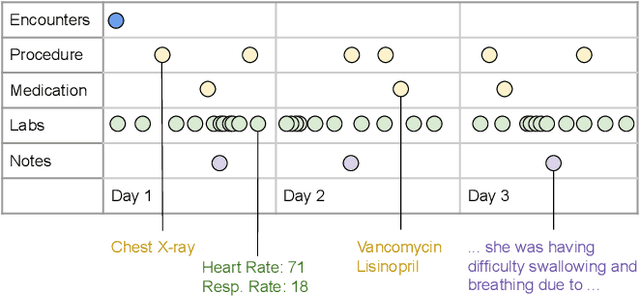
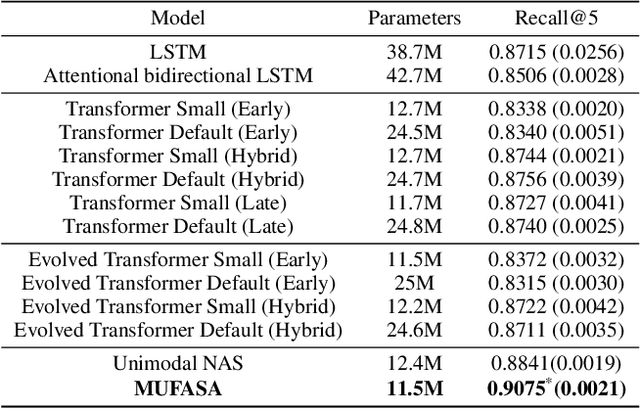
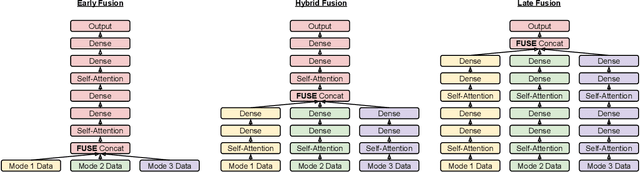

One important challenge of applying deep learning to electronic health records (EHR) is the complexity of their multimodal structure. EHR usually contains a mixture of structured (codes) and unstructured (free-text) data with sparse and irregular longitudinal features -- all of which doctors utilize when making decisions. In the deep learning regime, determining how different modality representations should be fused together is a difficult problem, which is often addressed by handcrafted modeling and intuition. In this work, we extend state-of-the-art neural architecture search (NAS) methods and propose MUltimodal Fusion Architecture SeArch (MUFASA) to simultaneously search across multimodal fusion strategies and modality-specific architectures for the first time. We demonstrate empirically that our MUFASA method outperforms established unimodal NAS on public EHR data with comparable computation costs. In addition, MUFASA produces architectures that outperform Transformer and Evolved Transformer. Compared with these baselines on CCS diagnosis code prediction, our discovered models improve top-5 recall from 0.88 to 0.91 and demonstrate the ability to generalize to other EHR tasks. Studying our top architecture in depth, we provide empirical evidence that MUFASA's improvements are derived from its ability to both customize modeling for each data modality and find effective fusion strategies.
AutoML-Zero: Evolving Machine Learning Algorithms From Scratch
Mar 06, 2020
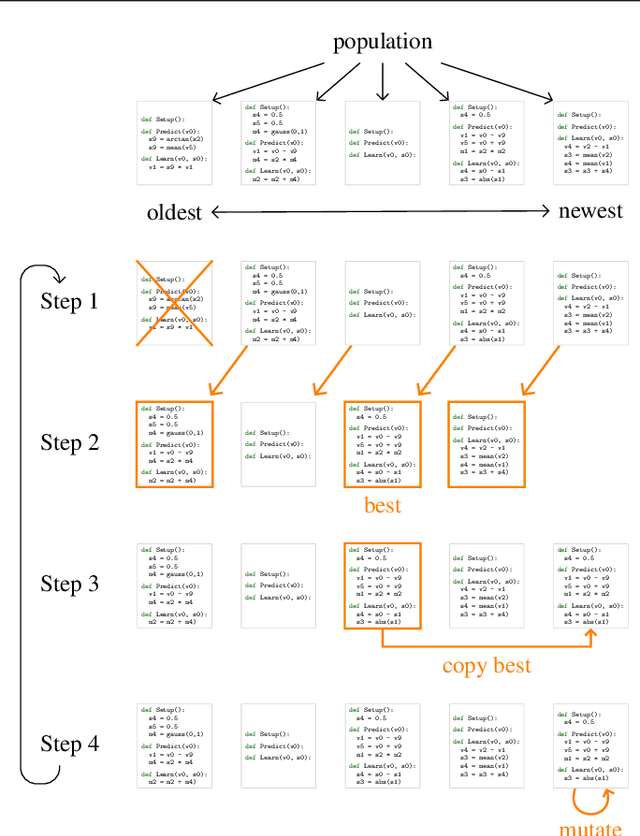

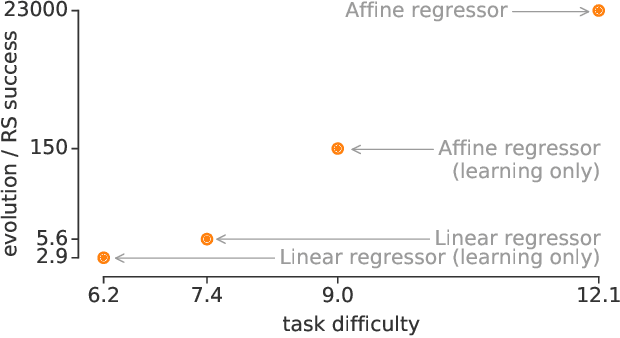
Machine learning research has advanced in multiple aspects, including model structures and learning methods. The effort to automate such research, known as AutoML, has also made significant progress. However, this progress has largely focused on the architecture of neural networks, where it has relied on sophisticated expert-designed layers as building blocks---or similarly restrictive search spaces. Our goal is to show that AutoML can go further: it is possible today to automatically discover complete machine learning algorithms just using basic mathematical operations as building blocks. We demonstrate this by introducing a novel framework that significantly reduces human bias through a generic search space. Despite the vastness of this space, evolutionary search can still discover two-layer neural networks trained by backpropagation. These simple neural networks can then be surpassed by evolving directly on tasks of interest, e.g. CIFAR-10 variants, where modern techniques emerge in the top algorithms, such as bilinear interactions, normalized gradients, and weight averaging. Moreover, evolution adapts algorithms to different task types: e.g., dropout-like techniques appear when little data is available. We believe these preliminary successes in discovering machine learning algorithms from scratch indicate a promising new direction for the field.
Towards a Human-like Open-Domain Chatbot
Feb 27, 2020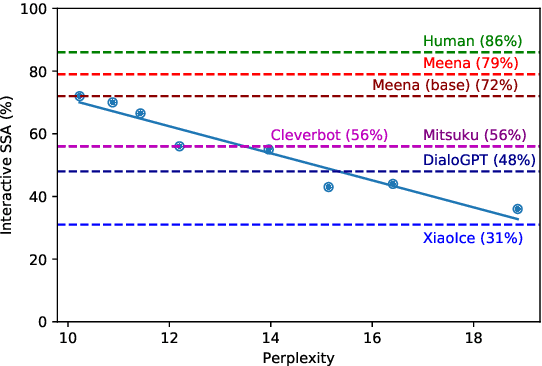

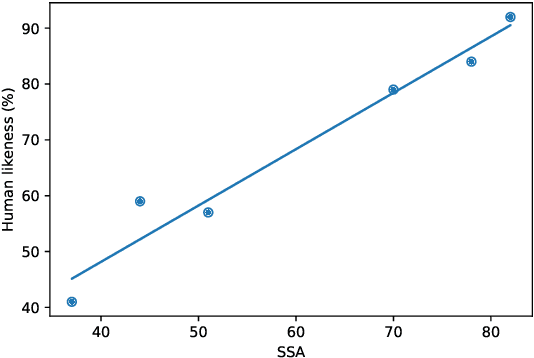

We present Meena, a multi-turn open-domain chatbot trained end-to-end on data mined and filtered from public domain social media conversations. This 2.6B parameter neural network is simply trained to minimize perplexity of the next token. We also propose a human evaluation metric called Sensibleness and Specificity Average (SSA), which captures key elements of a human-like multi-turn conversation. Our experiments show strong correlation between perplexity and SSA. The fact that the best perplexity end-to-end trained Meena scores high on SSA (72% on multi-turn evaluation) suggests that a human-level SSA of 86% is potentially within reach if we can better optimize perplexity. Additionally, the full version of Meena (with a filtering mechanism and tuned decoding) scores 79% SSA, 23% higher in absolute SSA than the existing chatbots we evaluated.
The Evolved Transformer
Feb 15, 2019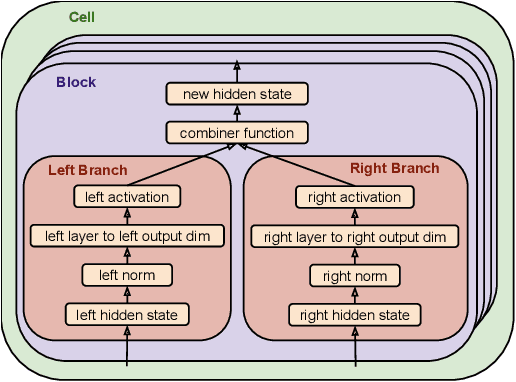
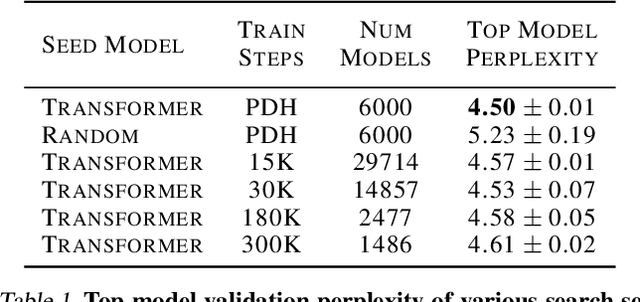
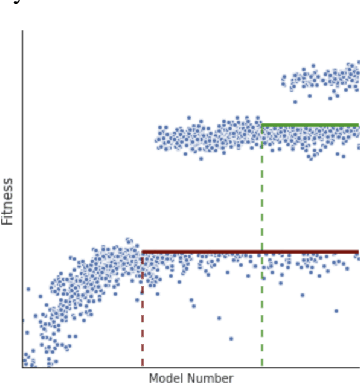
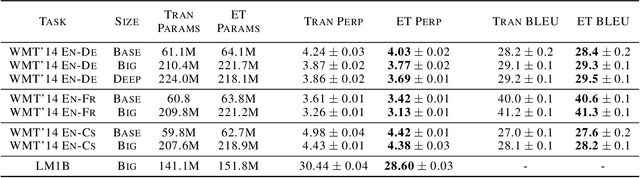
Recent works have highlighted the strengths of the Transformer architecture for dealing with sequence tasks. At the same time, neural architecture search has advanced to the point where it can outperform human-designed models. The goal of this work is to use architecture search to find a better Transformer architecture. We first construct a large search space inspired by the recent advances in feed-forward sequential models and then run evolutionary architecture search, seeding our initial population with the Transformer. To effectively run this search on the computationally expensive WMT 2014 English-German translation task, we develop the progressive dynamic hurdles method, which allows us to dynamically allocate more resources to more promising candidate models. The architecture found in our experiments - the Evolved Transformer - demonstrates consistent improvement over the Transformer on four well-established language tasks: WMT 2014 English-German, WMT 2014 English-French, WMT 2014 English-Czech and LM1B. At big model size, the Evolved Transformer is twice as efficient as the Transformer in FLOPS without loss in quality. At a much smaller - mobile-friendly - model size of ~7M parameters, the Evolved Transformer outperforms the Transformer by 0.7 BLEU on WMT'14 English-German.