 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Evolution with Binary Discriminators for ML Program Search
Feb 08, 2024How to automatically design better machine learning programs is an open problem within AutoML. While evolution has been a popular tool to search for better ML programs, using learning itself to guide the search has been less successful and less understood on harder problems but has the promise to dramatically increase the speed and final performance of the optimization process. We propose guiding evolution with a binary discriminator, trained online to distinguish which program is better given a pair of programs. The discriminator selects better programs without having to perform a costly evaluation and thus speed up the convergence of evolution. Our method can encode a wide variety of ML components including symbolic optimizers, neural architectures, RL loss functions, and symbolic regression equations with the same directed acyclic graph representation. By combining this representation with modern GNNs and an adaptive mutation strategy, we demonstrate our method can speed up evolution across a set of diverse problems including a 3.7x speedup on the symbolic search for ML optimizers and a 4x speedup for RL loss functions.
AutoNumerics-Zero: Automated Discovery of State-of-the-Art Mathematical Functions
Dec 13, 2023Computers calculate transcendental functions by approximating them through the composition of a few limited-precision instructions. For example, an exponential can be calculated with a Taylor series. These approximation methods were developed over the centuries by mathematicians, who emphasized the attainability of arbitrary precision. Computers, however, operate on few limited precision types, such as the popular float32. In this study, we show that when aiming for limited precision, existing approximation methods can be outperformed by programs automatically discovered from scratch by a simple evolutionary algorithm. In particular, over real numbers, our method can approximate the exponential function reaching orders of magnitude more precision for a given number of operations when compared to previous approaches. More practically, over float32 numbers and constrained to less than 1 ULP of error, the same method attains a speedup over baselines by generating code that triggers better XLA/LLVM compilation paths. In other words, in both cases, evolution searched a vast space of possible programs, without knowledge of mathematics, to discover previously unknown optimized approximations to high precision, for the first time. We also give evidence that these results extend beyond the exponential. The ubiquity of transcendental functions suggests that our method has the potential to reduce the cost of scientific computing applications.
Discovering Adaptable Symbolic Algorithms from Scratch
Jul 31, 2023



Autonomous robots deployed in the real world will need control policies that rapidly adapt to environmental changes. To this end, we propose AutoRobotics-Zero (ARZ), a method based on AutoML-Zero that discovers zero-shot adaptable policies from scratch. In contrast to neural network adaption policies, where only model parameters are optimized, ARZ can build control algorithms with the full expressive power of a linear register machine. We evolve modular policies that tune their model parameters and alter their inference algorithm on-the-fly to adapt to sudden environmental changes. We demonstrate our method on a realistic simulated quadruped robot, for which we evolve safe control policies that avoid falling when individual limbs suddenly break. This is a challenging task in which two popular neural network baselines fail. Finally, we conduct a detailed analysis of our method on a novel and challenging non-stationary control task dubbed Cataclysmic Cartpole. Results confirm our findings that ARZ is significantly more robust to sudden environmental changes and can build simple, interpretable control policies.
Symbolic Discovery of Optimization Algorithms
Feb 17, 2023



We present a method to formulate algorithm discovery as program search, and apply it to discover optimization algorithms for deep neural network training. We leverage efficient search techniques to explore an infinite and sparse program space. To bridge the large generalization gap between proxy and target tasks, we also introduce program selection and simplification strategies. Our method discovers a simple and effective optimization algorithm, $\textbf{Lion}$ ($\textit{Evo$\textbf{L}$ved S$\textbf{i}$gn M$\textbf{o}$me$\textbf{n}$tum}$). It is more memory-efficient than Adam as it only keeps track of the momentum. Different from adaptive optimizers, its update has the same magnitude for each parameter calculated through the sign operation. We compare Lion with widely used optimizers, such as Adam and Adafactor, for training a variety of models on different tasks. On image classification, Lion boosts the accuracy of ViT by up to 2% on ImageNet and saves up to 5x the pre-training compute on JFT. On vision-language contrastive learning, we achieve 88.3% $\textit{zero-shot}$ and 91.1% $\textit{fine-tuning}$ accuracy on ImageNet, surpassing the previous best results by 2% and 0.1%, respectively. On diffusion models, Lion outperforms Adam by achieving a better FID score and reducing the training compute by up to 2.3x. For autoregressive, masked language modeling, and fine-tuning, Lion exhibits a similar or better performance compared to Adam. Our analysis of Lion reveals that its performance gain grows with the training batch size. It also requires a smaller learning rate than Adam due to the larger norm of the update produced by the sign function. Additionally, we examine the limitations of Lion and identify scenarios where its improvements are small or not statistically significant. The implementation of Lion is publicly available.
Unified Functional Hashing in Automatic Machine Learning
Feb 10, 2023



The field of Automatic Machine Learning (AutoML) has recently attained impressive results, including the discovery of state-of-the-art machine learning solutions, such as neural image classifiers. This is often done by applying an evolutionary search method, which samples multiple candidate solutions from a large space and evaluates the quality of each candidate through a long training process. As a result, the search tends to be slow. In this paper, we show that large efficiency gains can be obtained by employing a fast unified functional hash, especially through the functional equivalence caching technique, which we also present. The central idea is to detect by hashing when the search method produces equivalent candidates, which occurs very frequently, and this way avoid their costly re-evaluation. Our hash is "functional" in that it identifies equivalent candidates even if they were represented or coded differently, and it is "unified" in that the same algorithm can hash arbitrary representations; e.g. compute graphs, imperative code, or lambda functions. As evidence, we show dramatic improvements on multiple AutoML domains, including neural architecture search and algorithm discovery. Finally, we consider the effect of hash collisions, evaluation noise, and search distribution through empirical analysis. Altogether, we hope this paper may serve as a guide to hashing techniques in AutoML.
PyGlove: Efficiently Exchanging ML Ideas as Code
Feb 03, 2023



The increasing complexity and scale of machine learning (ML) has led to the need for more efficient collaboration among multiple teams. For example, when a research team invents a new architecture like "ResNet," it is desirable for multiple engineering teams to adopt it. However, the effort required for each team to study and understand the invention does not scale well with the number of teams or inventions. In this paper, we present an extension of our PyGlove library to easily and scalably share ML ideas. PyGlove represents ideas as symbolic rule-based patches, enabling researchers to write down the rules for models they have not seen. For example, an inventor can write rules that will "add skip-connections." This permits a network effect among teams: at once, any team can issue patches to all other teams. Such a network effect allows users to quickly surmount the cost of adopting PyGlove by writing less code quicker, providing a benefit that scales with time. We describe the new paradigm of organizing ML through symbolic patches and compare it to existing approaches. We also perform a case study of a large codebase where PyGlove led to an 80% reduction in the number of lines of code.
Multi-objective evolution for Generalizable Policy Gradient Algorithms
Apr 08, 2022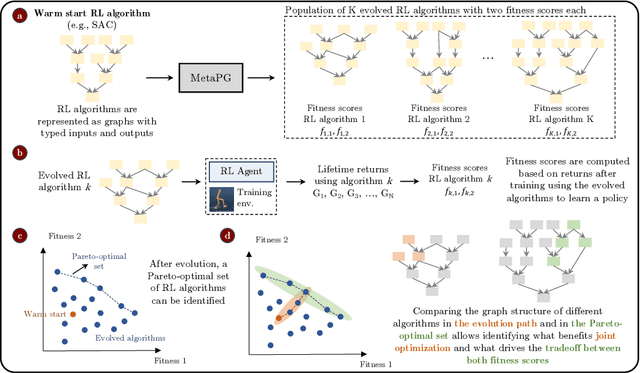
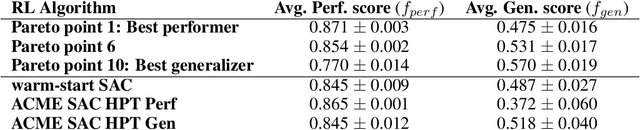
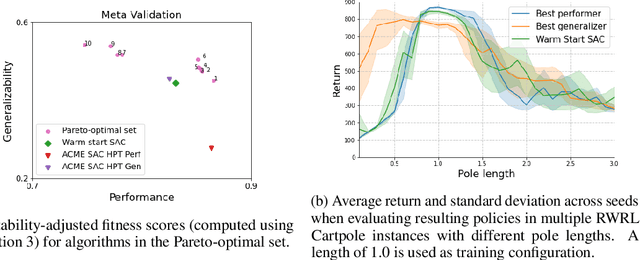
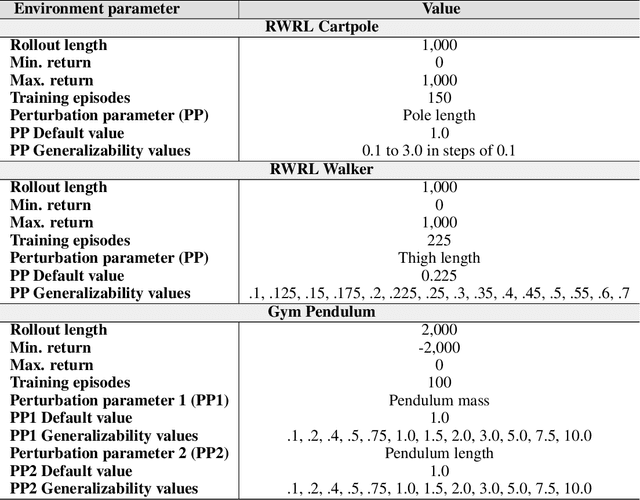
Performance, generalizability, and stability are three Reinforcement Learning (RL) challenges relevant to many practical applications in which they present themselves in combination. Still, state-of-the-art RL algorithms fall short when addressing multiple RL objectives simultaneously and current human-driven design practices might not be well-suited for multi-objective RL. In this paper we present MetaPG, an evolutionary method that discovers new RL algorithms represented as graphs, following a multi-objective search criteria in which different RL objectives are encoded in separate fitness scores. Our findings show that, when using a graph-based implementation of Soft Actor-Critic (SAC) to initialize the population, our method is able to find new algorithms that improve upon SAC's performance and generalizability by 3% and 17%, respectively, and reduce instability up to 65%. In addition, we analyze the graph structure of the best algorithms in the population and offer an interpretation of specific elements that help trading performance for generalizability and vice versa. We validate our findings in three different continuous control tasks: RWRL Cartpole, RWRL Walker, and Gym Pendulum.
PyGlove: Symbolic Programming for Automated Machine Learning
Jan 21, 2021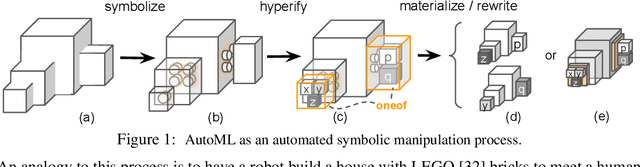
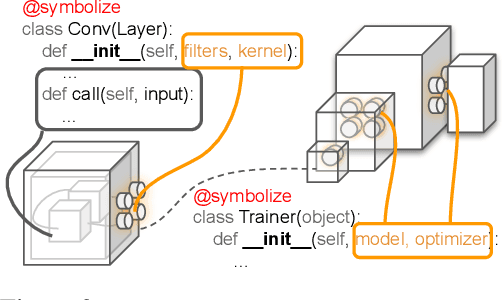

Neural networks are sensitive to hyper-parameter and architecture choices. Automated Machine Learning (AutoML) is a promising paradigm for automating these choices. Current ML software libraries, however, are quite limited in handling the dynamic interactions among the components of AutoML. For example, efficientNAS algorithms, such as ENAS and DARTS, typically require an implementation coupling between the search space and search algorithm, the two key components in AutoML. Furthermore, implementing a complex search flow, such as searching architectures within a loop of searching hardware configurations, is difficult. To summarize, changing the search space, search algorithm, or search flow in current ML libraries usually requires a significant change in the program logic. In this paper, we introduce a new way of programming AutoML based on symbolic programming. Under this paradigm, ML programs are mutable, thus can be manipulated easily by another program. As a result, AutoML can be reformulated as an automated process of symbolic manipulation. With this formulation, we decouple the triangle of the search algorithm, the search space and the child program. This decoupling makes it easy to change the search space and search algorithm (without and with weight sharing), as well as to add search capabilities to existing code and implement complex search flows. We then introduce PyGlove, a new Python library that implements this paradigm. Through case studies on ImageNet and NAS-Bench-101, we show that with PyGlove users can easily convert a static program into a search space, quickly iterate on the search spaces and search algorithms, and craft complex search flows to achieve better results.
Evolving Reinforcement Learning Algorithms
Jan 08, 2021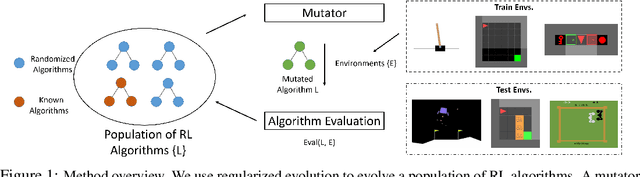
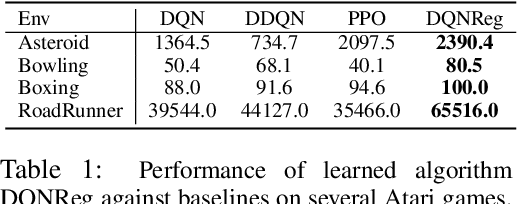
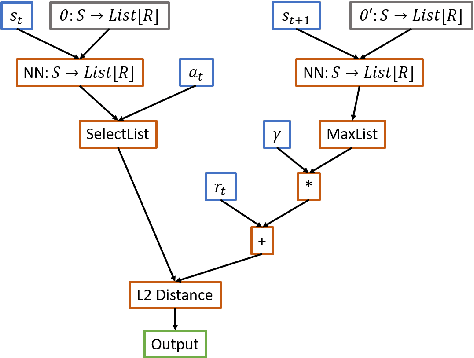
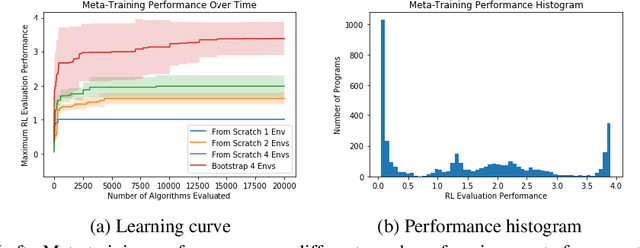
We propose a method for meta-learning reinforcement learning algorithms by searching over the space of computational graphs which compute the loss function for a value-based model-free RL agent to optimize. The learned algorithms are domain-agnostic and can generalize to new environments not seen during training. Our method can both learn from scratch and bootstrap off known existing algorithms, like DQN, enabling interpretable modifications which improve performance. Learning from scratch on simple classical control and gridworld tasks, our method rediscovers the temporal-difference (TD) algorithm. Bootstrapped from DQN, we highlight two learned algorithms which obtain good generalization performance over other classical control tasks, gridworld type tasks, and Atari games. The analysis of the learned algorithm behavior shows resemblance to recently proposed RL algorithms that address overestimation in value-based methods.
AutoML-Zero: Evolving Machine Learning Algorithms From Scratch
Mar 06, 2020
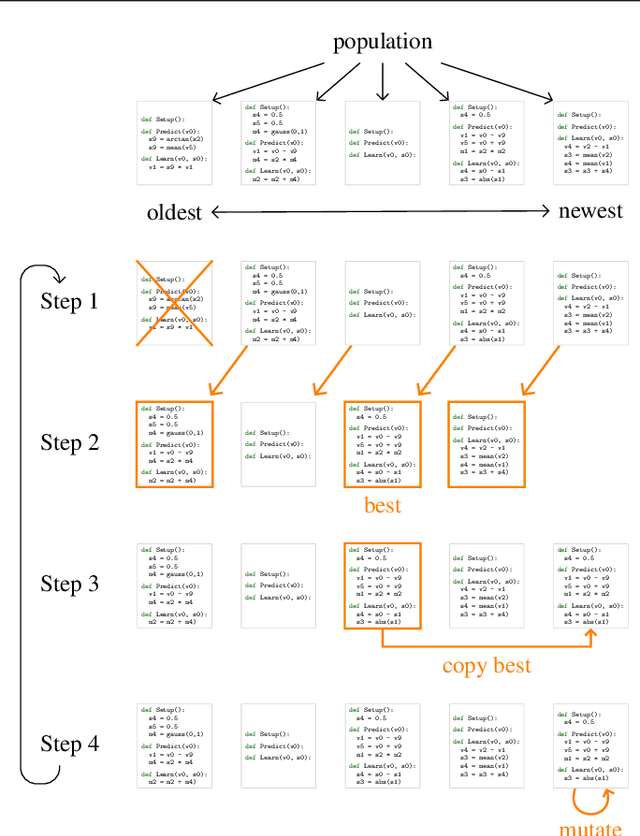

Machine learning research has advanced in multiple aspects, including model structures and learning methods. The effort to automate such research, known as AutoML, has also made significant progress. However, this progress has largely focused on the architecture of neural networks, where it has relied on sophisticated expert-designed layers as building blocks---or similarly restrictive search spaces. Our goal is to show that AutoML can go further: it is possible today to automatically discover complete machine learning algorithms just using basic mathematical operations as building blocks. We demonstrate this by introducing a novel framework that significantly reduces human bias through a generic search space. Despite the vastness of this space, evolutionary search can still discover two-layer neural networks trained by backpropagation. These simple neural networks can then be surpassed by evolving directly on tasks of interest, e.g. CIFAR-10 variants, where modern techniques emerge in the top algorithms, such as bilinear interactions, normalized gradients, and weight averaging. Moreover, evolution adapts algorithms to different task types: e.g., dropout-like techniques appear when little data is available. We believe these preliminary successes in discovering machine learning algorithms from scratch indicate a promising new direction for the field.