 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiGen: Using Multimodal Generation in Simulation to Learn Multimodal Policies in Real
Jul 03, 2025Robots must integrate multiple sensory modalities to act effectively in the real world. Yet, learning such multimodal policies at scale remains challenging. Simulation offers a viable solution, but while vision has benefited from high-fidelity simulators, other modalities (e.g. sound) can be notoriously difficult to simulate. As a result, sim-to-real transfer has succeeded primarily in vision-based tasks, with multimodal transfer still largely unrealized. In this work, we tackle these challenges by introducing MultiGen, a framework that integrates large-scale generative models into traditional physics simulators, enabling multisensory simulation. We showcase our framework on the dynamic task of robot pouring, which inherently relies on multimodal feedback. By synthesizing realistic audio conditioned on simulation video, our method enables training on rich audiovisual trajectories -- without any real robot data. We demonstrate effective zero-shot transfer to real-world pouring with novel containers and liquids, highlighting the potential of generative modeling to both simulate hard-to-model modalities and close the multimodal sim-to-real gap.
Activation Reward Models for Few-Shot Model Alignment
Jul 02, 2025Aligning Large Language Models (LLMs) and Large Multimodal Models (LMMs) to human preferences is a central challenge in improving the quality of the models' generative outputs for real-world applications. A common approach is to use reward modeling to encode preferences, enabling alignment via post-training using reinforcement learning. However, traditional reward modeling is not easily adaptable to new preferences because it requires a separate reward model, commonly trained on large preference datasets. To address this, we introduce Activation Reward Models (Activation RMs) -- a novel few-shot reward modeling method that leverages activation steering to construct well-aligned reward signals using minimal supervision and no additional model finetuning. Activation RMs outperform existing few-shot reward modeling approaches such as LLM-as-a-judge with in-context learning, voting-based scoring, and token probability scoring on standard reward modeling benchmarks. Furthermore, we demonstrate the effectiveness of Activation RMs in mitigating reward hacking behaviors, highlighting their utility for safety-critical applications. Toward this end, we propose PreferenceHack, a novel few-shot setting benchmark, the first to test reward models on reward hacking in a paired preference format. Finally, we show that Activation RM achieves state-of-the-art performance on this benchmark, surpassing even GPT-4o.
Whole-Body Conditioned Egocentric Video Prediction
Jun 26, 2025



We train models to Predict Ego-centric Video from human Actions (PEVA), given the past video and an action represented by the relative 3D body pose. By conditioning on kinematic pose trajectories, structured by the joint hierarchy of the body, our model learns to simulate how physical human actions shape the environment from a first-person point of view. We train an auto-regressive conditional diffusion transformer on Nymeria, a large-scale dataset of real-world egocentric video and body pose capture. We further design a hierarchical evaluation protocol with increasingly challenging tasks, enabling a comprehensive analysis of the model's embodied prediction and control abilities. Our work represents an initial attempt to tackle the challenges of modeling complex real-world environments and embodied agent behaviors with video prediction from the perspective of a human.
LeVERB: Humanoid Whole-Body Control with Latent Vision-Language Instruction
Jun 16, 2025



Vision-language-action (VLA) models have demonstrated strong semantic understanding and zero-shot generalization, yet most existing systems assume an accurate low-level controller with hand-crafted action "vocabulary" such as end-effector pose or root velocity. This assumption confines prior work to quasi-static tasks and precludes the agile, whole-body behaviors required by humanoid whole-body control (WBC) tasks. To capture this gap in the literature, we start by introducing the first sim-to-real-ready, vision-language, closed-loop benchmark for humanoid WBC, comprising over 150 tasks from 10 categories. We then propose LeVERB: Latent Vision-Language-Encoded Robot Behavior, a hierarchical latent instruction-following framework for humanoid vision-language WBC, the first of its kind. At the top level, a vision-language policy learns a latent action vocabulary from synthetically rendered kinematic demonstrations; at the low level, a reinforcement-learned WBC policy consumes these latent verbs to generate dynamics-level commands. In our benchmark, LeVERB can zero-shot attain a 80% success rate on simple visual navigation tasks, and 58.5% success rate overall, outperforming naive hierarchical whole-body VLA implementation by 7.8 times.
Hidden in plain sight: VLMs overlook their visual representations
Jun 09, 2025Language provides a natural interface to specify and evaluate performance on visual tasks. To realize this possibility, vision language models (VLMs) must successfully integrate visual and linguistic information. Our work compares VLMs to a direct readout of their visual encoders to understand their ability to integrate across these modalities. Across a series of vision-centric benchmarks (e.g., depth estimation, correspondence), we find that VLMs perform substantially worse than their visual encoders, dropping to near-chance performance. We investigate these results through a series of analyses across the entire VLM: namely 1) the degradation of vision representations, 2) brittleness to task prompt, and 3) the language model's role in solving the task. We find that the bottleneck in performing these vision-centric tasks lies in this third category; VLMs are not effectively using visual information easily accessible throughout the entire model, and they inherit the language priors present in the LLM. Our work helps diagnose the failure modes of open-source VLMs, and presents a series of evaluations useful for future investigations into visual understanding within VLMs.
Search Arena: Analyzing Search-Augmented LLMs
Jun 05, 2025Search-augmented language models combine web search with Large Language Models (LLMs) to improve response groundedness and freshness. However, analyzing these systems remains challenging: existing datasets are limited in scale and narrow in scope, often constrained to static, single-turn, fact-checking questions. In this work, we introduce Search Arena, a crowd-sourced, large-scale, human-preference dataset of over 24,000 paired multi-turn user interactions with search-augmented LLMs. The dataset spans diverse intents and languages, and contains full system traces with around 12,000 human preference votes. Our analysis reveals that user preferences are influenced by the number of citations, even when the cited content does not directly support the attributed claims, uncovering a gap between perceived and actual credibility. Furthermore, user preferences vary across cited sources, revealing that community-driven platforms are generally preferred and static encyclopedic sources are not always appropriate and reliable. To assess performance across different settings, we conduct cross-arena analyses by testing search-augmented LLMs in a general-purpose chat environment and conventional LLMs in search-intensive settings. We find that web search does not degrade and may even improve performance in non-search settings; however, the quality in search settings is significantly affected if solely relying on the model's parametric knowledge. We open-sourced the dataset to support future research in this direction. Our dataset and code are available at: https://github.com/lmarena/search-arena.
REOrdering Patches Improves Vision Models
May 29, 2025Sequence models such as transformers require inputs to be represented as one-dimensional sequences. In vision, this typically involves flattening images using a fixed row-major (raster-scan) order. While full self-attention is permutation-equivariant, modern long-sequence transformers increasingly rely on architectural approximations that break this invariance and introduce sensitivity to patch ordering. We show that patch order significantly affects model performance in such settings, with simple alternatives like column-major or Hilbert curves yielding notable accuracy shifts. Motivated by this, we propose REOrder, a two-stage framework for discovering task-optimal patch orderings. First, we derive an information-theoretic prior by evaluating the compressibility of various patch sequences. Then, we learn a policy over permutations by optimizing a Plackett-Luce policy using REINFORCE. This approach enables efficient learning in a combinatorial permutation space. REOrder improves top-1 accuracy over row-major ordering on ImageNet-1K by up to 3.01% and Functional Map of the World by 13.35%.
Puzzled by Puzzles: When Vision-Language Models Can't Take a Hint
May 29, 2025Rebus puzzles, visual riddles that encode language through imagery, spatial arrangement, and symbolic substitution, pose a unique challenge to current vision-language models (VLMs). Unlike traditional image captioning or question answering tasks, rebus solving requires multi-modal abstraction, symbolic reasoning, and a grasp of cultural, phonetic and linguistic puns. In this paper, we investigate the capacity of contemporary VLMs to interpret and solve rebus puzzles by constructing a hand-generated and annotated benchmark of diverse English-language rebus puzzles, ranging from simple pictographic substitutions to spatially-dependent cues ("head" over "heels"). We analyze how different VLMs perform, and our findings reveal that while VLMs exhibit some surprising capabilities in decoding simple visual clues, they struggle significantly with tasks requiring abstract reasoning, lateral thinking, and understanding visual metaphors.
Visual Imitation Enables Contextual Humanoid Control
May 07, 2025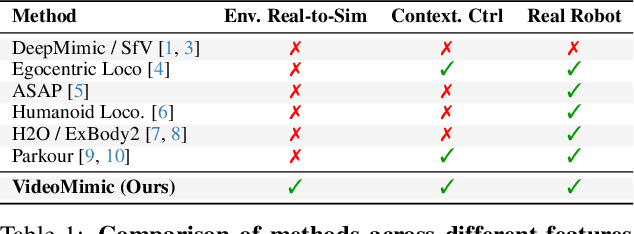
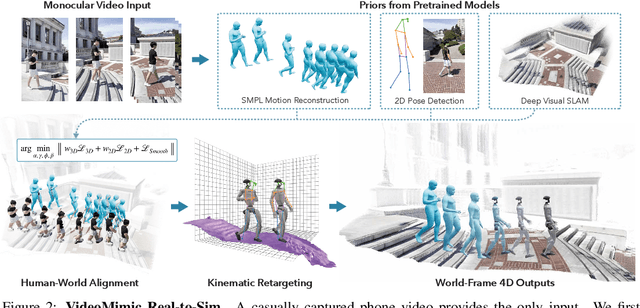


How can we teach humanoids to climb staircases and sit on chairs using the surrounding environment context? Arguably, the simplest way is to just show them-casually capture a human motion video and feed it to humanoids. We introduce VIDEOMIMIC, a real-to-sim-to-real pipeline that mines everyday videos, jointly reconstructs the humans and the environment, and produces whole-body control policies for humanoid robots that perform the corresponding skills. We demonstrate the results of our pipeline on real humanoid robots, showing robust, repeatable contextual control such as staircase ascents and descents, sitting and standing from chairs and benches, as well as other dynamic whole-body skills-all from a single policy, conditioned on the environment and global root commands. VIDEOMIMIC offers a scalable path towards teaching humanoids to operate in diverse real-world environments.
LISAT: Language-Instructed Segmentation Assistant for Satellite Imagery
May 05, 2025Segmentation models can recognize a pre-defined set of objects in images. However, models that can reason over complex user queries that implicitly refer to multiple objects of interest are still in their infancy. Recent advances in reasoning segmentation--generating segmentation masks from complex, implicit query text--demonstrate that vision-language models can operate across an open domain and produce reasonable outputs. However, our experiments show that such models struggle with complex remote-sensing imagery. In this work, we introduce LISAt, a vision-language model designed to describe complex remote-sensing scenes, answer questions about them, and segment objects of interest. We trained LISAt on a new curated geospatial reasoning-segmentation dataset, GRES, with 27,615 annotations over 9,205 images, and a multimodal pretraining dataset, PreGRES, containing over 1 million question-answer pairs. LISAt outperforms existing geospatial foundation models such as RS-GPT4V by over 10.04 % (BLEU-4) on remote-sensing description tasks, and surpasses state-of-the-art open-domain models on reasoning segmentation tasks by 143.36 % (gIoU). Our model, datasets, and code are available at https://lisat-bair.github.io/LISAt/