 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecon: Reconstruction-Guided Reasoning Synthesis for User Modeling
May 26, 2026User modeling aims to use language models (LMs) to mimic an individual's behavior from a corpus of past context-action pairs (e.g., conversation turns), enabling the simulation of users in settings like behavioral science, human-AI collaboration, and market research. Recent approaches augment these corpora with synthesized reasoning traces, typically generated by conditioning on both context and action. However, such conditioning constitutes post-hoc rationalization rather than reasoning: the trace is guaranteed to justify the action, but may not encode the underlying latent causal decision paths. We propose Recon, which uses action reconstruction to score reasoning traces by their predictive power: given a context and candidate reasoning, a reconstruction model predicts the action, and reconstruction fidelity determines reasoning quality. Across four domains, Recon achieves a 54.7% win rate over Backward Synthesis, a standard post-hoc rationalization baseline. Further, we find that training a reasoning synthesis model with rewards derived from Recon improves downstream user modeling performance, achieving a win rate of up to 70.0% over baselines. We further show that Recon-synthesized reasoning transfers across models, and improves user modeling beyond the reconstruction model. Our work demonstrates that post-hoc rationalization is insufficient for reasoning synthesis, and that useful and interpretable reasoning should naturally elicit the action from the context.
Retrieval-Augmented Tutoring for Algorithm Tracing and Problem-Solving in AI Education
May 13, 2026Students learning algorithms often need support as they interpret traces, debug reasoning errors, and apply procedures across unfamiliar problem instances. In this paper, we present KITE (Knowledge-Informed Tutoring Engine), a Retrieval-Augmented Generation (RAG)-based intelligent tutoring system designed to serve as a classroom teaching assistant for algorithmic reasoning and problem-solving tasks. KITE uses an intent-aware Socratic response strategy to tailor support to different student needs, responding with targeted hints, guiding questions, and progressive scaffolding intended to strengthen students' algorithmic problem-solving ability. To keep responses aligned with course content, KITE uses a multimodal RAG pipeline that retrieves relevant information from course materials. We evaluate KITE using three forms of assessment: RAGAs-based metrics for response grounding and quality, expert evaluation of pedagogical quality, and a simulated student pipeline in which a weaker language model interacts with KITE across two-turn dialogues and produces revised answers after receiving feedback. Results indicate that KITE produces contextually grounded and pedagogically appropriate responses. Further, using simulated students, KITE's feedback helped the student models produce more accurate follow-up responses on procedural and tracing questions, suggesting that its scaffolding can support algorithmic problem-solving. This work contributes a tutoring architecture and an evaluation approach for assessing retrieval-grounded explanations and scaffolded problem-solving feedback.
The Missing Evaluation Axis: What 10,000 Student Submissions Reveal About AI Tutor Effectiveness
May 07, 2026Current Artificial Intelligence (AI)-based tutoring systems (AI tutors) are primarily evaluated based on the pedagogical quality of their feedback messages. While important, pedagogy alone is insufficient because it ignores a critical question: what do students actually do with the feedback they receive? We argue that AI tutor evaluation should be extended with a behavioral dimension grounded in student interaction data, which complements pedagogical assessment. We propose an evaluation framework and apply it to 10,235 code submissions with corresponding AI tutor feedback from an introductory undergraduate programming course to measure whether students act on tutor feedback and whether those actions are applied correctly. Using this framework to compare two deployed AI tutors across different semesters in a large-scale introductory computer science course reveals substantial differences in student engagement patterns that are not captured by pedagogy-only evaluation. Moreover, these engagement-based behavioral signals are more strongly associated with student perception of helpful feedback than pedagogical quality alone, providing a more complete and actionable picture of AI tutor performance.
Cooperate to Compete: Strategic Coordination in Multi-Agent Conquest
Apr 28, 2026Language Model (LM)-based agents remain largely untested in mixed-motive settings where agents must leverage short-term cooperation for long-term competitive goals (e.g., multi-party politics). We introduce Cooperate to Compete (C2C), a multi-agent environment where players can engage in private negotiations while competing to be the first to achieve their secret objective. Players have asymmetric objectives and negotiations are non-binding, allowing alliances to form and break as players' short-term interests align and diverge. We run AI only games and conduct a user study pitting human players against AI opponents. We identify significant differences between human and AI negotiation behaviors, finding that humans favor lower-complexity deals and are significantly less reliable partners compared to LM-based agents. We also find that humans are more aggressive negotiators, accepting deals without a counteroffer only 56.3% of the time compared to 67.6% for LM-based agents. Through targeted prompting inspired by these findings, we modify agents' negotiation behavior and improve win rates from 22.2% to 32.7%. We run over 1,100 games with over 16,000 private conversations totaling 15.2 million tokens and over 150,000 player actions. Our results establish C2C as a testbed for studying and building LM-based agents that can navigate the sophisticated coordination required for real-world deployments. The game, code, and dataset may be found at https://negotiationgame.io/c2c.
Personalized Worked Example Generation from Student Code Submissions using Pattern-based Knowledge Components
Apr 27, 2026Adaptive programming practice often relies on fixed libraries of worked examples and practice problems, which require substantial authoring effort and may not correspond well to the logical errors and partial solutions students produce while writing code. As a result, students may receive learning content that does not directly address the concepts they are working to understand, while instructors must either invest additional effort in expanding content libraries or accept a coarse level of personalization. We present an approach for knowledge-component (KC) guided educational content generation using pattern-based KCs extracted from student code. Given a problem statement and student submissions, our pipeline extracts recurring structural KC patterns from students' code through AST-based analysis and uses them to condition a generative model. In this study, we apply this approach to worked example generation, and compare baseline and KC-conditioned outputs through expert evaluation. Results suggest that KC-conditioned generation improves topical focus and relevance to learners' underlying logical errors, providing evidence that KC-based steering of generative models can support personalized learning at scale.
PMT: Plain Mask Transformer for Image and Video Segmentation with Frozen Vision Encoders
Mar 26, 2026Vision Foundation Models (VFMs) pre-trained at scale enable a single frozen encoder to serve multiple downstream tasks simultaneously. Recent VFM-based encoder-only models for image and video segmentation, such as EoMT and VidEoMT, achieve competitive accuracy with remarkably low latency, yet they require finetuning the encoder, sacrificing the multi-task encoder sharing that makes VFMs practically attractive for large-scale deployment. To reconcile encoder-only simplicity and speed with frozen VFM features, we propose the Plain Mask Decoder (PMD), a fast Transformer-based segmentation decoder that operates on top of frozen VFM features. The resulting model, the Plain Mask Transformer (PMT), preserves the architectural simplicity and low latency of encoder-only designs while keeping the encoder representation unchanged and shareable. The design seamlessly applies to both image and video segmentation, inheriting the generality of the encoder-only framework. On standard image segmentation benchmarks, PMT matches the frozen-encoder state of the art while running up to ~3x faster. For video segmentation, it even performs on par with fully finetuned methods, while being up to 8x faster than state-of-the-art frozen-encoder models. Code: https://github.com/tue-mps/pmt.
LeanTutor: Towards a Verified AI Mathematical Proof Tutor
Jan 24, 2026This paper considers the development of an AI-based provably-correct mathematical proof tutor. While Large Language Models (LLMs) allow seamless communication in natural language, they are error prone. Theorem provers such as Lean allow for provable-correctness, but these are hard for students to learn. We present a proof-of-concept system (LeanTutor) by combining the complementary strengths of LLMs and theorem provers. LeanTutor is composed of three modules: (i) an autoformalizer/proof-checker, (ii) a next-step generator, and (iii) a natural language feedback generator. To evaluate the system, we introduce PeanoBench, a dataset of 371 Peano Arithmetic proofs in human-written natural language and formal language, derived from the Natural Numbers Game.
MAGIC: Multi-Agent Argumentation and Grammar Integrated Critiquer
Jun 16, 2025Automated Essay Scoring (AES) and Automatic Essay Feedback (AEF) systems aim to reduce the workload of human raters in educational assessment. However, most existing systems prioritize numeric scoring accuracy over the quality of feedback. This paper presents Multi-Agent Argumentation and Grammar Integrated Critiquer (MAGIC), a framework that uses multiple specialized agents to evaluate distinct writing aspects to both predict holistic scores and produce detailed, rubric-aligned feedback. To support evaluation, we curated a novel dataset of past GRE practice test essays with expert-evaluated scores and feedback. MAGIC outperforms baseline models in both essay scoring , as measured by Quadratic Weighted Kappa (QWK). We find that despite the improvement in QWK, there are opportunities for future work in aligning LLM-generated feedback to human preferences.
LeanTutor: A Formally-Verified AI Tutor for Mathematical Proofs
Jun 10, 2025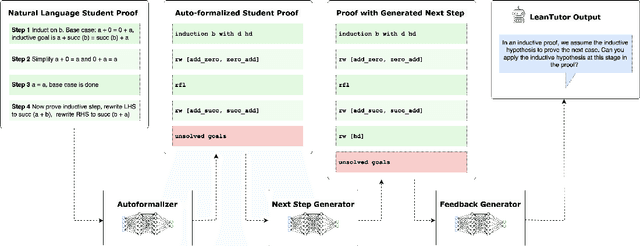

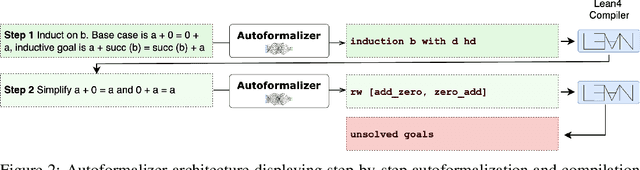
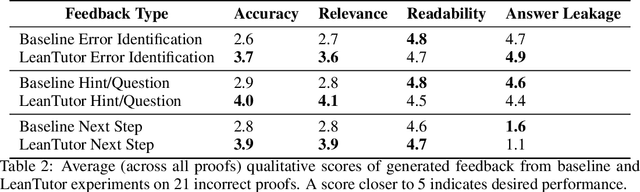
We present LeanTutor, a Large Language Model (LLM)-based tutoring system for math proofs. LeanTutor interacts with the student in natural language, formally verifies student-written math proofs in Lean, generates correct next steps, and provides the appropriate instructional guidance. LeanTutor is composed of three modules: (i) an autoformalizer/proof-checker, (ii) a next-step generator, and (iii) a natural language feedback generator. The first module faithfully autoformalizes student proofs into Lean and verifies proof accuracy via successful code compilation. If the proof has an error, the incorrect step is identified. The next-step generator module outputs a valid next Lean tactic for incorrect proofs via LLM-based candidate generation and proof search. The feedback generator module leverages Lean data to produce a pedagogically-motivated natural language hint for the student user. To evaluate our system, we introduce PeanoBench, a human-written dataset derived from the Natural Numbers Game, consisting of 371 Peano Arithmetic proofs, where each natural language proof step is paired with the corresponding logically equivalent tactic in Lean. The Autoformalizer correctly formalizes 57% of tactics in correct proofs and accurately identifies the incorrect step in 30% of incorrect proofs. In generating natural language hints for erroneous proofs, LeanTutor outperforms a simple baseline on accuracy and relevance metrics.
Search Arena: Analyzing Search-Augmented LLMs
Jun 05, 2025Search-augmented language models combine web search with Large Language Models (LLMs) to improve response groundedness and freshness. However, analyzing these systems remains challenging: existing datasets are limited in scale and narrow in scope, often constrained to static, single-turn, fact-checking questions. In this work, we introduce Search Arena, a crowd-sourced, large-scale, human-preference dataset of over 24,000 paired multi-turn user interactions with search-augmented LLMs. The dataset spans diverse intents and languages, and contains full system traces with around 12,000 human preference votes. Our analysis reveals that user preferences are influenced by the number of citations, even when the cited content does not directly support the attributed claims, uncovering a gap between perceived and actual credibility. Furthermore, user preferences vary across cited sources, revealing that community-driven platforms are generally preferred and static encyclopedic sources are not always appropriate and reliable. To assess performance across different settings, we conduct cross-arena analyses by testing search-augmented LLMs in a general-purpose chat environment and conventional LLMs in search-intensive settings. We find that web search does not degrade and may even improve performance in non-search settings; however, the quality in search settings is significantly affected if solely relying on the model's parametric knowledge. We open-sourced the dataset to support future research in this direction. Our dataset and code are available at: https://github.com/lmarena/search-arena.