 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes unsupervised grammar induction need pixels?
Dec 20, 2022Are extralinguistic signals such as image pixels crucial for inducing constituency grammars? While past work has shown substantial gains from multimodal cues, we investigate whether such gains persist in the presence of rich information from large language models (LLMs). We find that our approach, LLM-based C-PCFG (LC-PCFG), outperforms previous multi-modal methods on the task of unsupervised constituency parsing, achieving state-of-the-art performance on a variety of datasets. Moreover, LC-PCFG results in an over 50% reduction in parameter count, and speedups in training time of 1.7x for image-aided models and more than 5x for video-aided models, respectively. These results challenge the notion that extralinguistic signals such as image pixels are needed for unsupervised grammar induction, and point to the need for better text-only baselines in evaluating the need of multi-modality for the task.
PromptonomyViT: Multi-Task Prompt Learning Improves Video Transformers using Synthetic Scene Data
Dec 08, 2022



Action recognition models have achieved impressive results by incorporating scene-level annotations, such as objects, their relations, 3D structure, and more. However, obtaining annotations of scene structure for videos requires a significant amount of effort to gather and annotate, making these methods expensive to train. In contrast, synthetic datasets generated by graphics engines provide powerful alternatives for generating scene-level annotations across multiple tasks. In this work, we propose an approach to leverage synthetic scene data for improving video understanding. We present a multi-task prompt learning approach for video transformers, where a shared video transformer backbone is enhanced by a small set of specialized parameters for each task. Specifically, we add a set of ``task prompts'', each corresponding to a different task, and let each prompt predict task-related annotations. This design allows the model to capture information shared among synthetic scene tasks as well as information shared between synthetic scene tasks and a real video downstream task throughout the entire network. We refer to this approach as ``Promptonomy'', since the prompts model a task-related structure. We propose the PromptonomyViT model (PViT), a video transformer that incorporates various types of scene-level information from synthetic data using the ``Promptonomy'' approach. PViT shows strong performance improvements on multiple video understanding tasks and datasets.
Multitask Vision-Language Prompt Tuning
Dec 05, 2022



Prompt Tuning, conditioning on task-specific learned prompt vectors, has emerged as a data-efficient and parameter-efficient method for adapting large pretrained vision-language models to multiple downstream tasks. However, existing approaches usually consider learning prompt vectors for each task independently from scratch, thereby failing to exploit the rich shareable knowledge across different vision-language tasks. In this paper, we propose multitask vision-language prompt tuning (MVLPT), which incorporates cross-task knowledge into prompt tuning for vision-language models. Specifically, (i) we demonstrate the effectiveness of learning a single transferable prompt from multiple source tasks to initialize the prompt for each target task; (ii) we show many target tasks can benefit each other from sharing prompt vectors and thus can be jointly learned via multitask prompt tuning. We benchmark the proposed MVLPT using three representative prompt tuning methods, namely text prompt tuning, visual prompt tuning, and the unified vision-language prompt tuning. Results in 20 vision tasks demonstrate that the proposed approach outperforms all single-task baseline prompt tuning methods, setting the new state-of-the-art on the few-shot ELEVATER benchmarks and cross-task generalization benchmarks. To understand where the cross-task knowledge is most effective, we also conduct a large-scale study on task transferability with 20 vision tasks in 400 combinations for each prompt tuning method. It shows that the most performant MVLPT for each prompt tuning method prefers different task combinations and many tasks can benefit each other, depending on their visual similarity and label similarity. Code is available at https://github.com/sIncerass/MVLPT.
Shape-Guided Diffusion with Inside-Outside Attention
Dec 01, 2022



Shape can specify key object constraints, yet existing text-to-image diffusion models ignore this cue and synthesize objects that are incorrectly scaled, cut off, or replaced with background content. We propose a training-free method, Shape-Guided Diffusion, which uses a novel Inside-Outside Attention mechanism to constrain the cross-attention (and self-attention) maps such that prompt tokens (and pixels) referring to the inside of the shape cannot attend outside the shape, and vice versa. To demonstrate the efficacy of our method, we propose a new image editing task where the model must replace an object specified by its mask and a text prompt. We curate a new ShapePrompts benchmark based on MS-COCO and achieve SOTA results in shape faithfulness, text alignment, and realism according to both quantitative metrics and human preferences. Our data and code will be made available at https://shape-guided-diffusion.github.io.
G^3: Geolocation via Guidebook Grounding
Nov 28, 2022



We demonstrate how language can improve geolocation: the task of predicting the location where an image was taken. Here we study explicit knowledge from human-written guidebooks that describe the salient and class-discriminative visual features humans use for geolocation. We propose the task of Geolocation via Guidebook Grounding that uses a dataset of StreetView images from a diverse set of locations and an associated textual guidebook for GeoGuessr, a popular interactive geolocation game. Our approach predicts a country for each image by attending over the clues automatically extracted from the guidebook. Supervising attention with country-level pseudo labels achieves the best performance. Our approach substantially outperforms a state-of-the-art image-only geolocation method, with an improvement of over 5% in Top-1 accuracy. Our dataset and code can be found at https://github.com/g-luo/geolocation_via_guidebook_grounding.
Using Language to Extend to Unseen Domains
Oct 20, 2022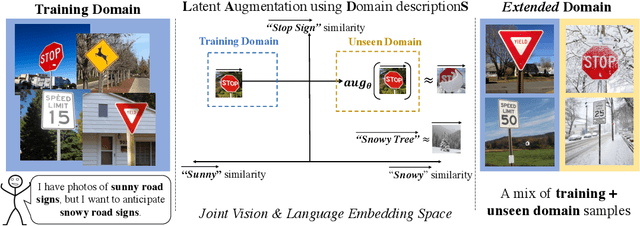
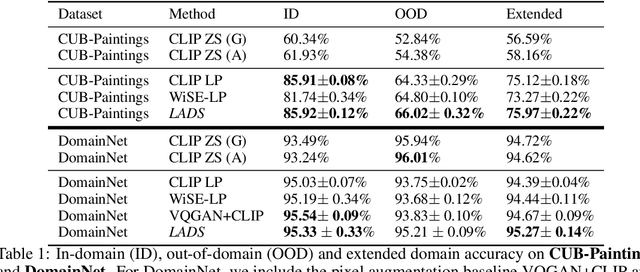
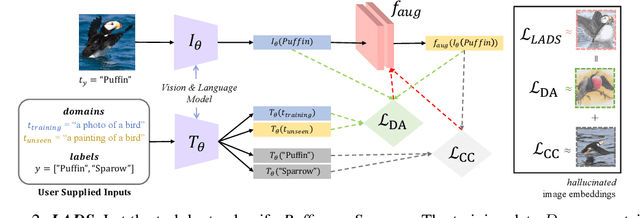

It is expensive to collect training data for every possible domain that a vision model may encounter when deployed. We instead consider how simply verbalizing the training domain (e.g. "photos of birds") as well as domains we want to extend to but do not have data for (e.g. "paintings of birds") can improve robustness. Using a multimodal model with a joint image and language embedding space, our method LADS learns a transformation of the image embeddings from the training domain to each unseen test domain, while preserving task relevant information. Without using any images from the unseen test domain, we show that over the extended domain containing both training and unseen test domains, LADS outperforms standard fine-tuning and ensemble approaches over a suite of four benchmarks targeting domain adaptation and dataset bias
QDTrack: Quasi-Dense Similarity Learning for Appearance-Only Multiple Object Tracking
Oct 12, 2022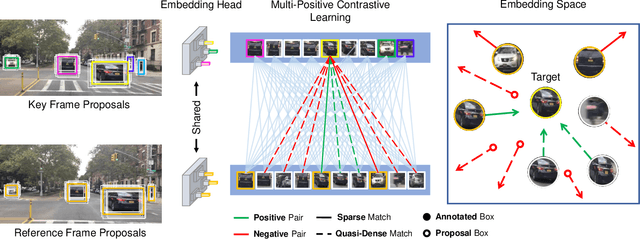
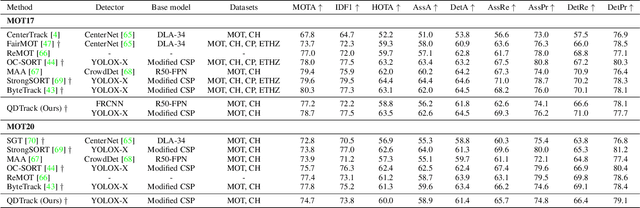
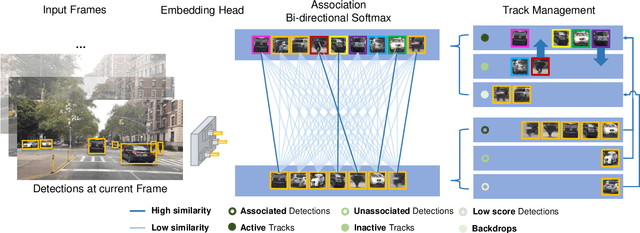
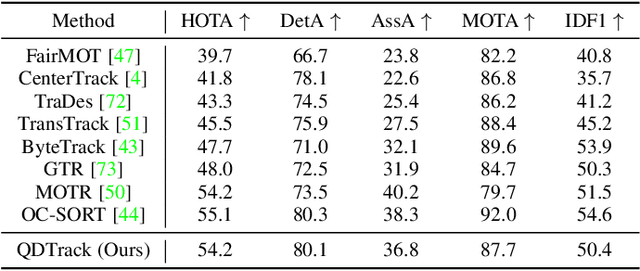
Similarity learning has been recognized as a crucial step for object tracking. However, existing multiple object tracking methods only use sparse ground truth matching as the training objective, while ignoring the majority of the informative regions in images. In this paper, we present Quasi-Dense Similarity Learning, which densely samples hundreds of object regions on a pair of images for contrastive learning. We combine this similarity learning with multiple existing object detectors to build Quasi-Dense Tracking (QDTrack), which does not require displacement regression or motion priors. We find that the resulting distinctive feature space admits a simple nearest neighbor search at inference time for object association. In addition, we show that our similarity learning scheme is not limited to video data, but can learn effective instance similarity even from static input, enabling a competitive tracking performance without training on videos or using tracking supervision. We conduct extensive experiments on a wide variety of popular MOT benchmarks. We find that, despite its simplicity, QDTrack rivals the performance of state-of-the-art tracking methods on all benchmarks and sets a new state-of-the-art on the large-scale BDD100K MOT benchmark, while introducing negligible computational overhead to the detector.
Real-World Robot Learning with Masked Visual Pre-training
Oct 06, 2022

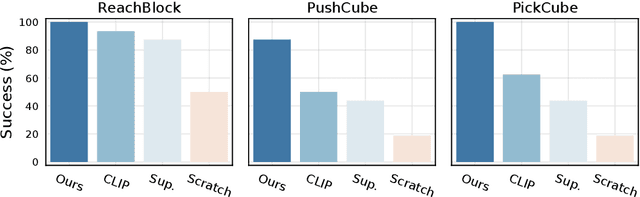
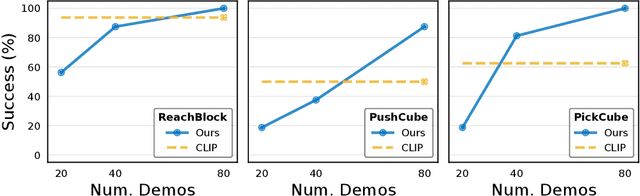
In this work, we explore self-supervised visual pre-training on images from diverse, in-the-wild videos for real-world robotic tasks. Like prior work, our visual representations are pre-trained via a masked autoencoder (MAE), frozen, and then passed into a learnable control module. Unlike prior work, we show that the pre-trained representations are effective across a range of real-world robotic tasks and embodiments. We find that our encoder consistently outperforms CLIP (up to 75%), supervised ImageNet pre-training (up to 81%), and training from scratch (up to 81%). Finally, we train a 307M parameter vision transformer on a massive collection of 4.5M images from the Internet and egocentric videos, and demonstrate clearly the benefits of scaling visual pre-training for robot learning.
Decentralized Vehicle Coordination: The Berkeley DeepDrive Drone Dataset
Sep 22, 2022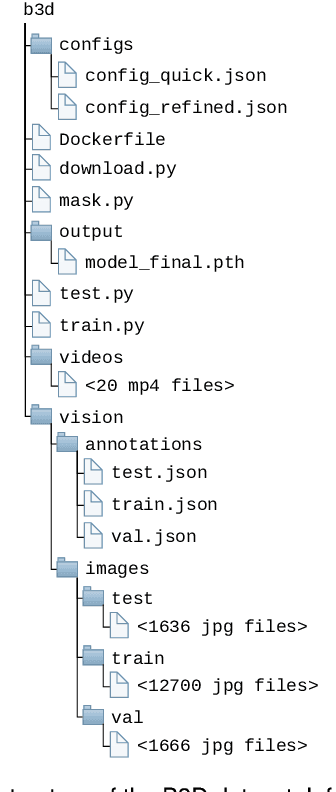
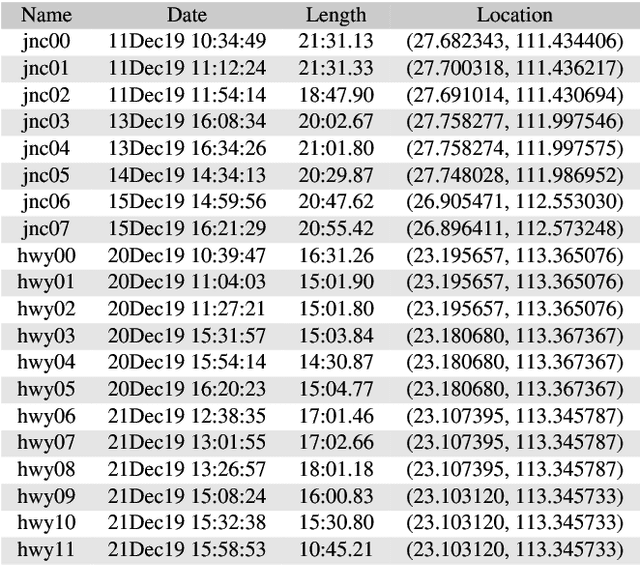


Decentralized multiagent planning has been an important field of research in robotics. An interesting and impactful application in the field is decentralized vehicle coordination in understructured road environments. For example, in an intersection, it is useful yet difficult to deconflict multiple vehicles of intersecting paths in absence of a central coordinator. We learn from common sense that, for a vehicle to navigate through such understructured environments, the driver must understand and conform to the implicit "social etiquette" observed by nearby drivers. To study this implicit driving protocol, we collect the Berkeley DeepDrive Drone dataset. The dataset contains 1) a set of aerial videos recording understructured driving, 2) a collection of images and annotations to train vehicle detection models, and 3) a kit of development scripts for illustrating typical usages. We believe that the dataset is of primary interest for studying decentralized multiagent planning employed by human drivers and, of secondary interest, for computer vision in remote sensing settings.
Studying Bias in GANs through the Lens of Race
Sep 15, 2022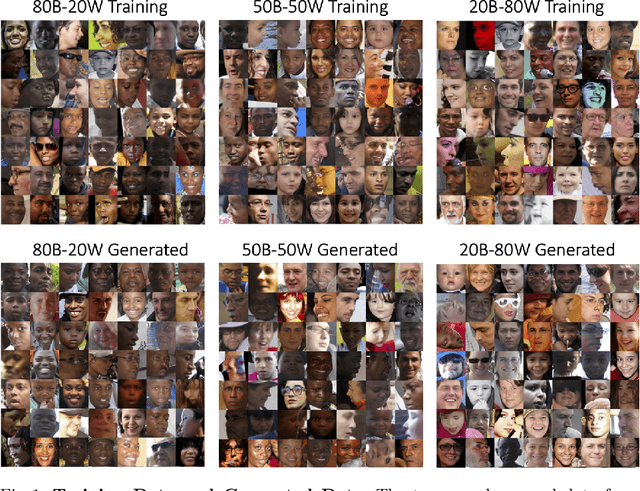



In this work, we study how the performance and evaluation of generative image models are impacted by the racial composition of their training datasets. By examining and controlling the racial distributions in various training datasets, we are able to observe the impacts of different training distributions on generated image quality and the racial distributions of the generated images. Our results show that the racial compositions of generated images successfully preserve that of the training data. However, we observe that truncation, a technique used to generate higher quality images during inference, exacerbates racial imbalances in the data. Lastly, when examining the relationship between image quality and race, we find that the highest perceived visual quality images of a given race come from a distribution where that race is well-represented, and that annotators consistently prefer generated images of white people over those of Black people.