 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Forcing for Multi-Agent Interaction Sequence Modeling
Dec 19, 2025Understanding and generating multi-person interactions is a fundamental challenge with broad implications for robotics and social computing. While humans naturally coordinate in groups, modeling such interactions remains difficult due to long temporal horizons, strong inter-agent dependencies, and variable group sizes. Existing motion generation methods are largely task-specific and do not generalize to flexible multi-agent generation. We introduce MAGNet (Multi-Agent Diffusion Forcing Transformer), a unified autoregressive diffusion framework for multi-agent motion generation that supports a wide range of interaction tasks through flexible conditioning and sampling. MAGNet performs dyadic prediction, partner inpainting, and full multi-agent motion generation within a single model, and can autoregressively generate ultra-long sequences spanning hundreds of v. Building on Diffusion Forcing, we introduce key modifications that explicitly model inter-agent coupling during autoregressive denoising, enabling coherent coordination across agents. As a result, MAGNet captures both tightly synchronized activities (e.g, dancing, boxing) and loosely structured social interactions. Our approach performs on par with specialized methods on dyadic benchmarks while naturally extending to polyadic scenarios involving three or more interacting people, enabled by a scalable architecture that is agnostic to the number of agents. We refer readers to the supplemental video, where the temporal dynamics and spatial coordination of generated interactions are best appreciated. Project page: https://von31.github.io/MAGNet/
Studying Bias in GANs through the Lens of Race
Sep 15, 2022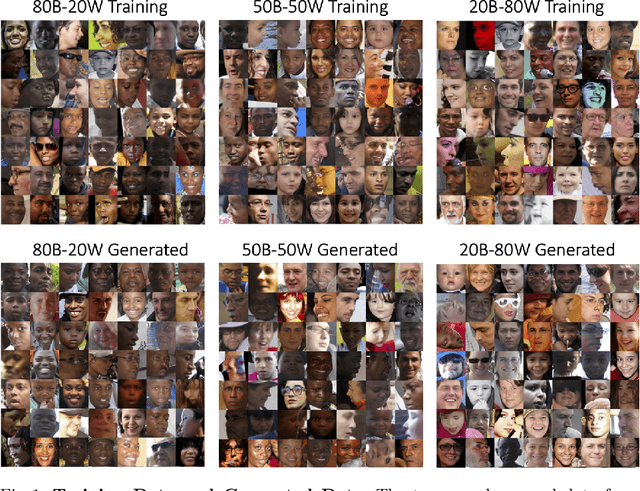



In this work, we study how the performance and evaluation of generative image models are impacted by the racial composition of their training datasets. By examining and controlling the racial distributions in various training datasets, we are able to observe the impacts of different training distributions on generated image quality and the racial distributions of the generated images. Our results show that the racial compositions of generated images successfully preserve that of the training data. However, we observe that truncation, a technique used to generate higher quality images during inference, exacerbates racial imbalances in the data. Lastly, when examining the relationship between image quality and race, we find that the highest perceived visual quality images of a given race come from a distribution where that race is well-represented, and that annotators consistently prefer generated images of white people over those of Black people.