 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorruption-Robust Algorithms with Uncertainty Weighting for Nonlinear Contextual Bandits and Markov Decision Processes
Dec 12, 2022Despite the significant interest and progress in reinforcement learning (RL) problems with adversarial corruption, current works are either confined to the linear setting or lead to an undesired $\tilde{O}(\sqrt{T}\zeta)$ regret bound, where $T$ is the number of rounds and $\zeta$ is the total amount of corruption. In this paper, we consider the contextual bandit with general function approximation and propose a computationally efficient algorithm to achieve a regret of $\tilde{O}(\sqrt{T}+\zeta)$. The proposed algorithm relies on the recently developed uncertainty-weighted least-squares regression from linear contextual bandit \citep{he2022nearly} and a new weighted estimator of uncertainty for the general function class. In contrast to the existing analysis that heavily relies on the linear structure, we develop a novel technique to control the sum of weighted uncertainty, thus establishing the final regret bounds. We then generalize our algorithm to the episodic MDP setting and first achieve an additive dependence on the corruption level $\zeta$ in the scenario of general function approximation. Notably, our algorithms achieve regret bounds either nearly match the performance lower bound or improve the existing methods for all the corruption levels and in both known and unknown $\zeta$ cases.
VO$Q$L: Towards Optimal Regret in Model-free RL with Nonlinear Function Approximation
Dec 12, 2022


We study time-inhomogeneous episodic reinforcement learning (RL) under general function approximation and sparse rewards. We design a new algorithm, Variance-weighted Optimistic $Q$-Learning (VO$Q$L), based on $Q$-learning and bound its regret assuming completeness and bounded Eluder dimension for the regression function class. As a special case, VO$Q$L achieves $\tilde{O}(d\sqrt{HT}+d^6H^{5})$ regret over $T$ episodes for a horizon $H$ MDP under ($d$-dimensional) linear function approximation, which is asymptotically optimal. Our algorithm incorporates weighted regression-based upper and lower bounds on the optimal value function to obtain this improved regret. The algorithm is computationally efficient given a regression oracle over the function class, making this the first computationally tractable and statistically optimal approach for linear MDPs.
ExtremeBERT: A Toolkit for Accelerating Pretraining of Customized BERT
Nov 30, 2022



In this paper, we present ExtremeBERT, a toolkit for accelerating and customizing BERT pretraining. Our goal is to provide an easy-to-use BERT pretraining toolkit for the research community and industry. Thus, the pretraining of popular language models on customized datasets is affordable with limited resources. Experiments show that, to achieve the same or better GLUE scores, the time cost of our toolkit is over $6\times$ times less for BERT Base and $9\times$ times less for BERT Large when compared with the original BERT paper. The documentation and code are released at https://github.com/extreme-bert/extreme-bert under the Apache-2.0 license.
Particle-based Variational Inference with Preconditioned Functional Gradient Flow
Nov 25, 2022Particle-based variational inference (VI) minimizes the KL divergence between model samples and the target posterior with gradient flow estimates. With the popularity of Stein variational gradient descent (SVGD), the focus of particle-based VI algorithms has been on the properties of functions in Reproducing Kernel Hilbert Space (RKHS) to approximate the gradient flow. However, the requirement of RKHS restricts the function class and algorithmic flexibility. This paper remedies the problem by proposing a general framework to obtain tractable functional gradient flow estimates. The functional gradient flow in our framework can be defined by a general functional regularization term that includes the RKHS norm as a special case. We use our framework to propose a new particle-based VI algorithm: preconditioned functional gradient flow (PFG). Compared with SVGD, the proposed method has several advantages: larger function class; greater scalability in large particle-size scenarios; better adaptation to ill-conditioned distributions; provable continuous-time convergence in KL divergence. Non-linear function classes such as neural networks can be incorporated to estimate the gradient flow. Both theory and experiments have shown the effectiveness of our framework.
DyNCA: Real-time Dynamic Texture Synthesis Using Neural Cellular Automata
Nov 21, 2022Current Dynamic Texture Synthesis (DyTS) models in the literature can synthesize realistic videos. However, these methods require a slow iterative optimization process to synthesize a single fixed-size short video, and they do not offer any post-training control over the synthesis process. We propose Dynamic Neural Cellular Automata (DyNCA), a framework for real-time and controllable dynamic texture synthesis. Our method is built upon the recently introduced NCA models, and can synthesize infinitely-long and arbitrary-size realistic texture videos in real-time. We quantitatively and qualitatively evaluate our model and show that our synthesized videos appear more realistic than the existing results. We improve the SOTA DyTS performance by $2\sim 4$ orders of magnitude. Moreover, our model offers several real-time and interactive video controls including motion speed, motion direction, and an editing brush tool.
Normalizing Flow with Variational Latent Representation
Nov 21, 2022Normalizing flow (NF) has gained popularity over traditional maximum likelihood based methods due to its strong capability to model complex data distributions. However, the standard approach, which maps the observed data to a normal distribution, has difficulty in handling data distributions with multiple relatively isolated modes. To overcome this issue, we propose a new framework based on variational latent representation to improve the practical performance of NF. The idea is to replace the standard normal latent variable with a more general latent representation, jointly learned via Variational Bayes. For example, by taking the latent representation as a discrete sequence, our framework can learn a Transformer model that generates the latent sequence and an NF model that generates continuous data distribution conditioned on the sequence. The resulting method is significantly more powerful than the standard normalization flow approach for generating data distributions with multiple modes. Extensive experiments have shown the advantages of NF with variational latent representation.
FAF: A novel multimodal emotion recognition approach integrating face, body and text
Nov 20, 2022



Multimodal emotion analysis performed better in emotion recognition depending on more comprehensive emotional clues and multimodal emotion dataset. In this paper, we developed a large multimodal emotion dataset, named "HED" dataset, to facilitate the emotion recognition task, and accordingly propose a multimodal emotion recognition method. To promote recognition accuracy, "Feature After Feature" framework was used to explore crucial emotional information from the aligned face, body and text samples. We employ various benchmarks to evaluate the "HED" dataset and compare the performance with our method. The results show that the five classification accuracy of the proposed multimodal fusion method is about 83.75%, and the performance is improved by 1.83%, 9.38%, and 21.62% respectively compared with that of individual modalities. The complementarity between each channel is effectively used to improve the performance of emotion recognition. We had also established a multimodal online emotion prediction platform, aiming to provide free emotion prediction to more users.
Prior-mean-assisted Bayesian optimization application on FRIB Front-End tunning
Nov 11, 2022Bayesian optimization~(BO) is often used for accelerator tuning due to its high sample efficiency. However, the computational scalability of training over large data-set can be problematic and the adoption of historical data in a computationally efficient way is not trivial. Here, we exploit a neural network model trained over historical data as a prior mean of BO for FRIB Front-End tuning.
A Posterior Sampling Framework for Interactive Decision Making
Nov 03, 2022

We study sample efficient reinforcement learning (RL) under the general framework of interactive decision making, which includes Markov decision process (MDP), partially observable Markov decision process (POMDP), and predictive state representation (PSR) as special cases. Toward finding the minimum assumption that empowers sample efficient learning, we propose a novel complexity measure, generalized eluder coefficient (GEC), which characterizes the fundamental tradeoff between exploration and exploitation in online interactive decision making. In specific, GEC captures the hardness of exploration by comparing the error of predicting the performance of the updated policy with the in-sample training error evaluated on the historical data. We show that RL problems with low GEC form a remarkably rich class, which subsumes low Bellman eluder dimension problems, bilinear class, low witness rank problems, PO-bilinear class, and generalized regular PSR, where generalized regular PSR, a new tractable PSR class identified by us, includes nearly all known tractable POMDPs. Furthermore, in terms of algorithm design, we propose a generic posterior sampling algorithm, which can be implemented in both model-free and model-based fashion, under both fully observable and partially observable settings. The proposed algorithm modifies the standard posterior sampling algorithm in two aspects: (i) we use an optimistic prior distribution that biases towards hypotheses with higher values and (ii) a loglikelihood function is set to be the empirical loss evaluated on the historical data, where the choice of loss function supports both model-free and model-based learning. We prove that the proposed algorithm is sample efficient by establishing a sublinear regret upper bound in terms of GEC. In summary, we provide a new and unified understanding of both fully observable and partially observable RL.
Large-Scale Bandwidth and Power Optimization for Multi-Modal Edge Intelligence Autonomous Driving
Oct 18, 2022
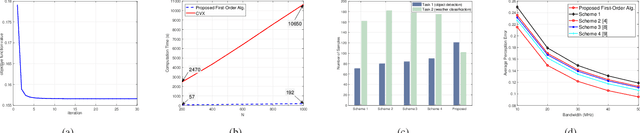

Edge intelligence autonomous driving (EIAD) offers computing resources in autonomous vehicles for training deep neural networks. However, wireless channels between the edge server and autonomous vehicles are time-varying due to the high-mobility of vehicles. Moreover, the required number of training samples for different data modalities (e.g., images, point-clouds) is diverse. Consequently, when collecting these datasets from vehicles to the edge server, the associated bandwidth and power allocation across all data frames is a large-scale multi-modal optimization problem. This article proposes a highly computationally efficient algorithm that directly maximizes the quality of training (QoT). The key ingredients include a data-driven model for quantifying the priority of data modality and two first-order methods termed accelerated gradient projection and dual decomposition for low-complexity resource allocation. High-fidelity simulations in Car Learning to Act (CARLA) show that the proposed algorithm reduces the perception error by $3\%$ and the computation time by $98\%$.