 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavCaps: A ChatGPT-Assisted Weakly-Labelled Audio Captioning Dataset for Audio-Language Multimodal Research
Mar 30, 2023



The advancement of audio-language (AL) multimodal learning tasks has been significant in recent years. However, researchers face challenges due to the costly and time-consuming collection process of existing audio-language datasets, which are limited in size. To address this data scarcity issue, we introduce WavCaps, the first large-scale weakly-labelled audio captioning dataset, comprising approximately 400k audio clips with paired captions. We sourced audio clips and their raw descriptions from web sources and a sound event detection dataset. However, the online-harvested raw descriptions are highly noisy and unsuitable for direct use in tasks such as automated audio captioning. To overcome this issue, we propose a three-stage processing pipeline for filtering noisy data and generating high-quality captions, where ChatGPT, a large language model, is leveraged to filter and transform raw descriptions automatically. We conduct a comprehensive analysis of the characteristics of WavCaps dataset and evaluate it on multiple downstream audio-language multimodal learning tasks. The systems trained on WavCaps outperform previous state-of-the-art (SOTA) models by a significant margin. Our aspiration is for the WavCaps dataset we have proposed to facilitate research in audio-language multimodal learning and demonstrate the potential of utilizing ChatGPT to enhance academic research. Our dataset and codes are available at https://github.com/XinhaoMei/WavCaps.
M3ST: Mix at Three Levels for Speech Translation
Dec 07, 2022How to solve the data scarcity problem for end-to-end speech-to-text translation (ST)? It's well known that data augmentation is an efficient method to improve performance for many tasks by enlarging the dataset. In this paper, we propose Mix at three levels for Speech Translation (M^3ST) method to increase the diversity of the augmented training corpus. Specifically, we conduct two phases of fine-tuning based on a pre-trained model using external machine translation (MT) data. In the first stage of fine-tuning, we mix the training corpus at three levels, including word level, sentence level and frame level, and fine-tune the entire model with mixed data. At the second stage of fine-tuning, we take both original speech sequences and original text sequences in parallel into the model to fine-tune the network, and use Jensen-Shannon divergence to regularize their outputs. Experiments on MuST-C speech translation benchmark and analysis show that M^3ST outperforms current strong baselines and achieves state-of-the-art results on eight directions with an average BLEU of 29.9.
Leveraging per Image-Token Consistency for Vision-Language Pre-training
Nov 20, 2022Most existing vision-language pre-training (VLP) approaches adopt cross-modal masked language modeling (CMLM) to learn vision-language associations. However, we find that CMLM is insufficient for this purpose according to our observations: (1) Modality bias: a considerable amount of masked tokens in CMLM can be recovered with only the language information, ignoring the visual inputs. (2) Under-utilization of the unmasked tokens: CMLM primarily focuses on the masked token but it cannot simultaneously leverage other tokens to learn vision-language associations. To handle those limitations, we propose EPIC (lEveraging Per Image-Token Consistency for vision-language pre-training). In EPIC, for each image-sentence pair, we mask tokens that are salient to the image (i.e., Saliency-based Masking Strategy) and replace them with alternatives sampled from a language model (i.e., Inconsistent Token Generation Procedure), and then the model is required to determine for each token in the sentence whether they are consistent with the image (i.e., Image-Text Consistent Task). The proposed EPIC method is easily combined with pre-training methods. Extensive experiments show that the combination of the EPIC method and state-of-the-art pre-training approaches, including ViLT, ALBEF, METER, and X-VLM, leads to significant improvements on downstream tasks.
Visually-Aware Audio Captioning With Adaptive Audio-Visual Attention
Oct 28, 2022Audio captioning is the task of generating captions that describe the content of audio clips. In the real world, many objects produce similar sounds. It is difficult to identify these auditory ambiguous sound events with access to audio information only. How to accurately recognize ambiguous sounds is a major challenge for audio captioning systems. In this work, inspired by the audio-visual multi-modal perception of human beings, we propose visually-aware audio captioning, which makes use of visual information to help the recognition of ambiguous sounding objects. Specifically, we introduce an off-the-shelf visual encoder to process the video inputs, and incorporate the extracted visual features into an audio captioning system. Furthermore, to better exploit complementary contexts from redundant audio-visual streams, we propose an audio-visual attention mechanism that integrates audio and visual information adaptively according to their confidence levels. Experimental results on AudioCaps, the largest publicly available audio captioning dataset, show that the proposed method achieves significant improvement over a strong baseline audio captioning system and is on par with the state-of-the-art result.
Personalized Dialogue Generation with Persona-Adaptive Attention
Oct 27, 2022Persona-based dialogue systems aim to generate consistent responses based on historical context and predefined persona. Unlike conventional dialogue generation, the persona-based dialogue needs to consider both dialogue context and persona, posing a challenge for coherent training. Specifically, this requires a delicate weight balance between context and persona. To achieve that, in this paper, we propose an effective framework with Persona-Adaptive Attention (PAA), which adaptively integrates the weights from the persona and context information via our designed attention. In addition, a dynamic masking mechanism is applied to the PAA to not only drop redundant information in context and persona but also serve as a regularization mechanism to avoid overfitting. Experimental results demonstrate the superiority of the proposed PAA framework compared to the strong baselines in both automatic and human evaluation. Moreover, the proposed PAA approach can perform equivalently well in a low-resource regime compared to models trained in a full-data setting, which achieve a similar result with only 20% to 30% of data compared to the larger models trained in the full-data setting. To fully exploit the effectiveness of our design, we designed several variants for handling the weighted information in different ways, showing the necessity and sufficiency of our weighting and masking designs.
CoBERT: Self-Supervised Speech Representation Learning Through Code Representation Learning
Oct 08, 2022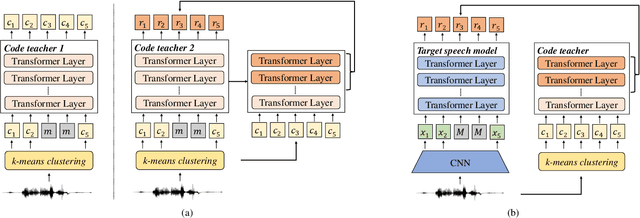
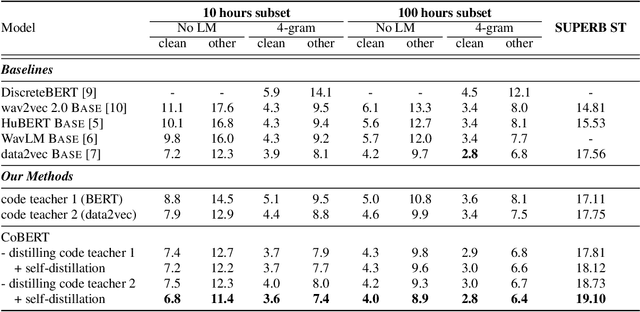
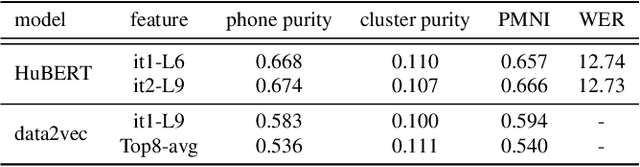
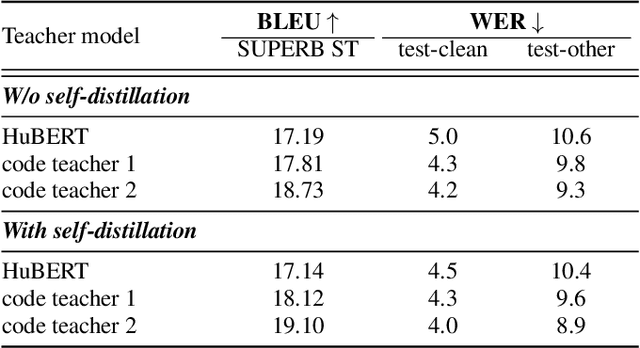
Speech is the surface form of a finite set of phonetic units, which can be represented by discrete codes. We propose the Code BERT (CoBERT) approach for self-supervised speech representation learning. The idea is to convert an utterance to a sequence of discrete codes, and perform code representation learning, where we predict the code representations based on a masked view of the original speech input. Unlike the prior self-distillation approaches of which the teacher and the student are of the same modality, our target model predicts representations from a different modality. CoBERT outperforms the most recent state-of-the-art performance on the ASR task and brings significant improvements on the SUPERB speech translation (ST) task.
A Study of Modeling Rising Intonation in Cantonese Neural Speech Synthesis
Aug 03, 2022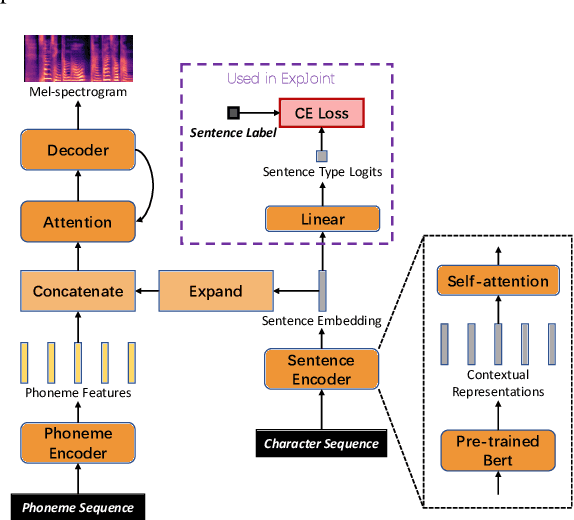
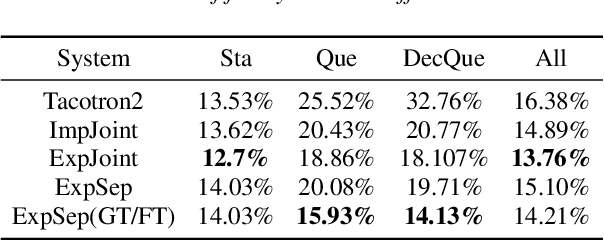
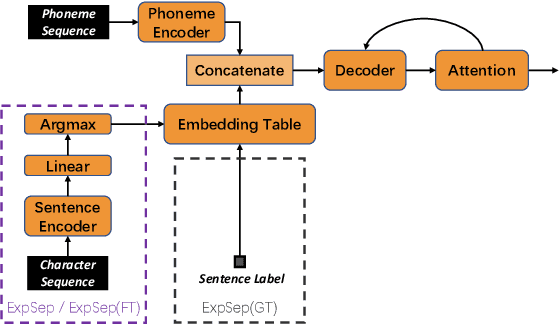

In human speech, the attitude of a speaker cannot be fully expressed only by the textual content. It has to come along with the intonation. Declarative questions are commonly used in daily Cantonese conversations, and they are usually uttered with rising intonation. Vanilla neural text-to-speech (TTS) systems are not capable of synthesizing rising intonation for these sentences due to the loss of semantic information. Though it has become more common to complement the systems with extra language models, their performance in modeling rising intonation is not well studied. In this paper, we propose to complement the Cantonese TTS model with a BERT-based statement/question classifier. We design different training strategies and compare their performance. We conduct our experiments on a Cantonese corpus named CanTTS. Empirical results show that the separate training approach obtains the best generalization performance and feasibility.
Leveraging Pseudo-labeled Data to Improve Direct Speech-to-Speech Translation
May 18, 2022
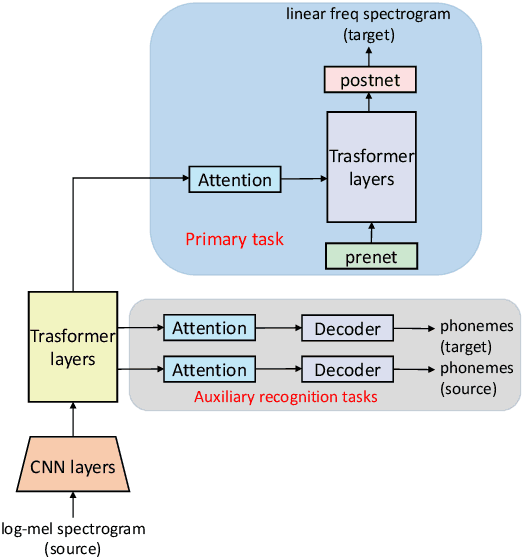
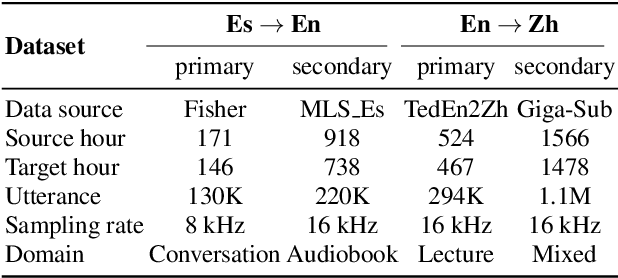
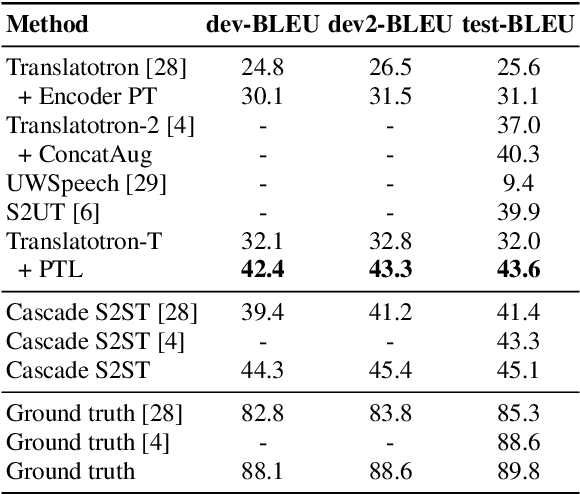
Direct Speech-to-speech translation (S2ST) has drawn more and more attention recently. The task is very challenging due to data scarcity and complex speech-to-speech mapping. In this paper, we report our recent achievements in S2ST. Firstly, we build a S2ST Transformer baseline which outperforms the original Translatotron. Secondly, we utilize the external data by pseudo-labeling and obtain a new state-of-the-art result on the Fisher English-to-Spanish test set. Indeed, we exploit the pseudo data with a combination of popular techniques which are not trivial when applied to S2ST. Moreover, we evaluate our approach on both syntactically similar (Spanish-English) and distant (English-Chinese) language pairs. Our implementation is available at https://github.com/fengpeng-yue/speech-to-speech-translation.
GigaST: A 10,000-hour Pseudo Speech Translation Corpus
Apr 08, 2022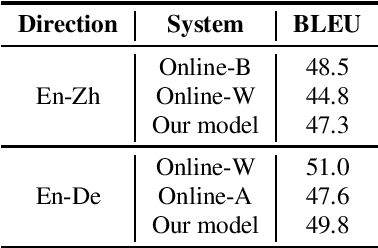
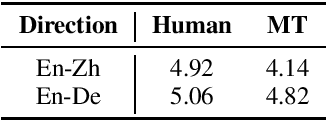
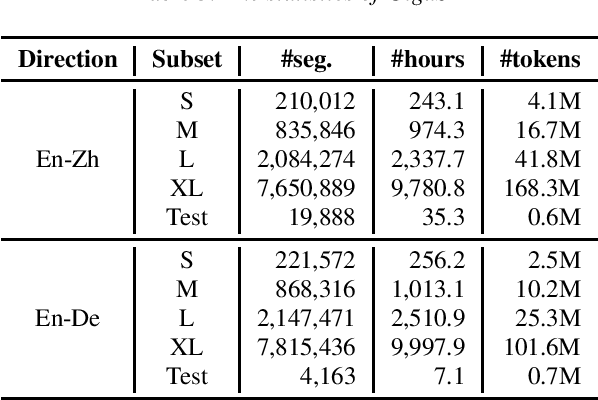
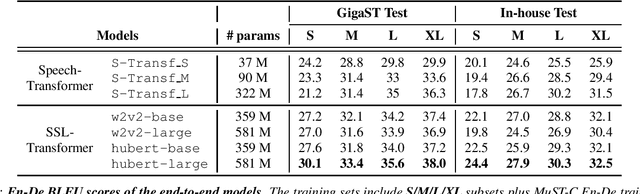
This paper introduces GigaST, a large-scale pseudo speech translation (ST) corpus. We create the corpus by translating the text in GigaSpeech, an English ASR corpus, into German and Chinese. The training set is translated by a strong machine translation system and the test set is translated by human. ST models trained with an addition of our corpus obtain new state-of-the-art results on the MuST-C English-German benchmark test set. We provide a detailed description of the translation process and verify its quality. We make the translated text data public and hope to facilitate research in speech translation. Additionally, we also release the training scripts on NeurST to make it easy to replicate our systems. GigaST dataset is available at https://st-benchmark.github.io/resources/GigaST.
Pre-Training Transformer Decoder for End-to-End ASR Model with Unpaired Speech Data
Mar 31, 2022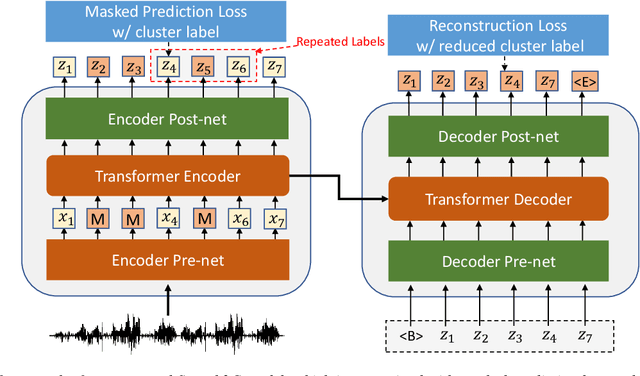
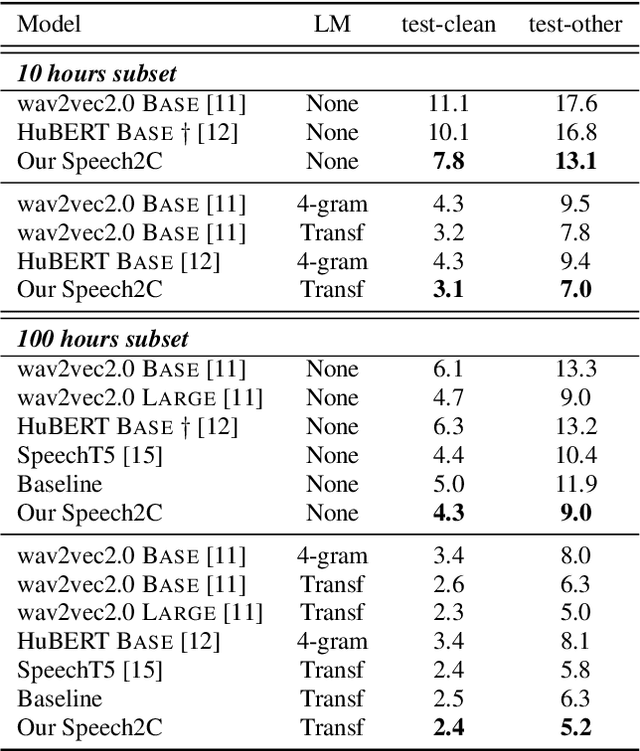

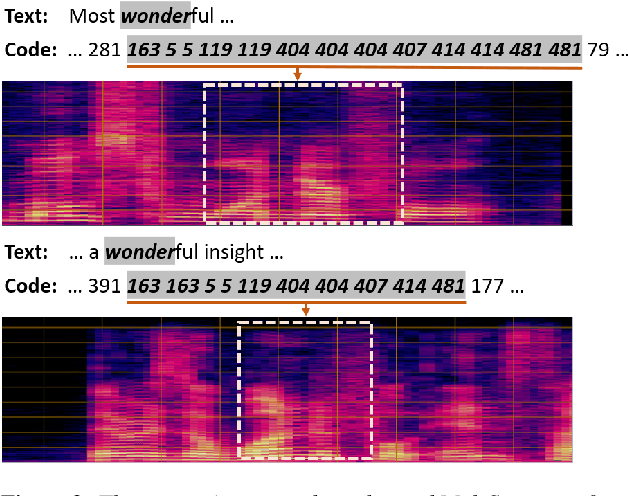
This paper studies a novel pre-training technique with unpaired speech data, Speech2C, for encoder-decoder based automatic speech recognition (ASR). Within a multi-task learning framework, we introduce two pre-training tasks for the encoder-decoder network using acoustic units, i.e., pseudo codes, derived from an offline clustering model. One is to predict the pseudo codes via masked language modeling in encoder output, like HuBERT model, while the other lets the decoder learn to reconstruct pseudo codes autoregressively instead of generating textual scripts. In this way, the decoder learns to reconstruct original speech information with codes before learning to generate correct text. Comprehensive experiments on the LibriSpeech corpus show that the proposed Speech2C can relatively reduce the word error rate (WER) by 19.2% over the method without decoder pre-training, and also outperforms significantly the state-of-the-art wav2vec 2.0 and HuBERT on fine-tuning subsets of 10h and 100h.