 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Click Prediction for Sponsored Search with Recurrent Neural Networks
Jul 28, 2014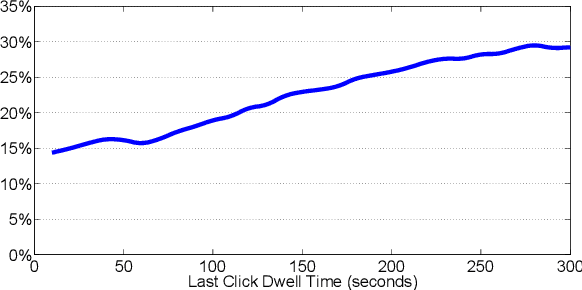
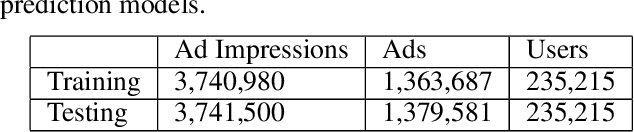
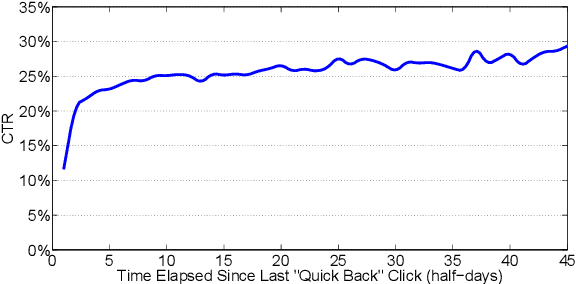
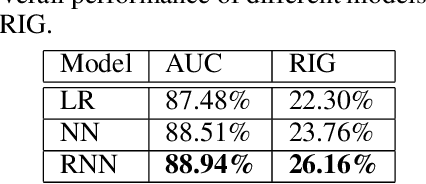
Click prediction is one of the fundamental problems in sponsored search. Most of existing studies took advantage of machine learning approaches to predict ad click for each event of ad view independently. However, as observed in the real-world sponsored search system, user's behaviors on ads yield high dependency on how the user behaved along with the past time, especially in terms of what queries she submitted, what ads she clicked or ignored, and how long she spent on the landing pages of clicked ads, etc. Inspired by these observations, we introduce a novel framework based on Recurrent Neural Networks (RNN). Compared to traditional methods, this framework directly models the dependency on user's sequential behaviors into the click prediction process through the recurrent structure in RNN. Large scale evaluations on the click-through logs from a commercial search engine demonstrate that our approach can significantly improve the click prediction accuracy, compared to sequence-independent approaches.
Agent Behavior Prediction and Its Generalization Analysis
Jul 11, 2014
Machine learning algorithms have been applied to predict agent behaviors in real-world dynamic systems, such as advertiser behaviors in sponsored search and worker behaviors in crowdsourcing. The behavior data in these systems are generated by live agents: once the systems change due to the adoption of the prediction models learnt from the behavior data, agents will observe and respond to these changes by changing their own behaviors accordingly. As a result, the behavior data will evolve and will not be identically and independently distributed, posing great challenges to the theoretical analysis on the machine learning algorithms for behavior prediction. To tackle this challenge, in this paper, we propose to use Markov Chain in Random Environments (MCRE) to describe the behavior data, and perform generalization analysis of the machine learning algorithms on its basis. Since the one-step transition probability matrix of MCRE depends on both previous states and the random environment, conventional techniques for generalization analysis cannot be directly applied. To address this issue, we propose a novel technique that transforms the original MCRE into a higher-dimensional time-homogeneous Markov chain. The new Markov chain involves more variables but is more regular, and thus easier to deal with. We prove the convergence of the new Markov chain when time approaches infinity. Then we prove a generalization bound for the machine learning algorithms on the behavior data generated by the new Markov chain, which depends on both the Markovian parameters and the covering number of the function class compounded by the loss function for behavior prediction and the behavior prediction model. To the best of our knowledge, this is the first work that performs the generalization analysis on data generated by complex processes in real-world dynamic systems.
WordRep: A Benchmark for Research on Learning Word Representations
Jul 07, 2014



WordRep is a benchmark collection for the research on learning distributed word representations (or word embeddings), released by Microsoft Research. In this paper, we describe the details of the WordRep collection and show how to use it in different types of machine learning research related to word embedding. Specifically, we describe how the evaluation tasks in WordRep are selected, how the data are sampled, and how the evaluation tool is built. We then compare several state-of-the-art word representations on WordRep, report their evaluation performance, and make discussions on the results. After that, we discuss new potential research topics that can be supported by WordRep, in addition to algorithm comparison. We hope that this paper can help people gain deeper understanding of WordRep, and enable more interesting research on learning distributed word representations and related topics.
A Game-theoretic Machine Learning Approach for Revenue Maximization in Sponsored Search
Jun 04, 2014


Sponsored search is an important monetization channel for search engines, in which an auction mechanism is used to select the ads shown to users and determine the prices charged from advertisers. There have been several pieces of work in the literature that investigate how to design an auction mechanism in order to optimize the revenue of the search engine. However, due to some unrealistic assumptions used, the practical values of these studies are not very clear. In this paper, we propose a novel \emph{game-theoretic machine learning} approach, which naturally combines machine learning and game theory, and learns the auction mechanism using a bilevel optimization framework. In particular, we first learn a Markov model from historical data to describe how advertisers change their bids in response to an auction mechanism, and then for any given auction mechanism, we use the learnt model to predict its corresponding future bid sequences. Next we learn the auction mechanism through empirical revenue maximization on the predicted bid sequences. We show that the empirical revenue will converge when the prediction period approaches infinity, and a Genetic Programming algorithm can effectively optimize this empirical revenue. Our experiments indicate that the proposed approach is able to produce a much more effective auction mechanism than several baselines.
A Theoretical Analysis of NDCG Type Ranking Measures
Apr 24, 2013

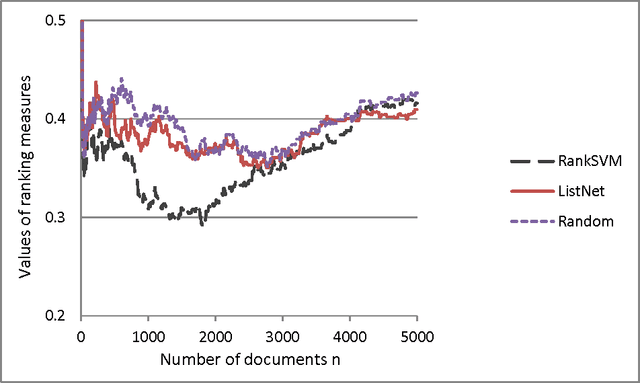

A central problem in ranking is to design a ranking measure for evaluation of ranking functions. In this paper we study, from a theoretical perspective, the widely used Normalized Discounted Cumulative Gain (NDCG)-type ranking measures. Although there are extensive empirical studies of NDCG, little is known about its theoretical properties. We first show that, whatever the ranking function is, the standard NDCG which adopts a logarithmic discount, converges to 1 as the number of items to rank goes to infinity. On the first sight, this result is very surprising. It seems to imply that NDCG cannot differentiate good and bad ranking functions, contradicting to the empirical success of NDCG in many applications. In order to have a deeper understanding of ranking measures in general, we propose a notion referred to as consistent distinguishability. This notion captures the intuition that a ranking measure should have such a property: For every pair of substantially different ranking functions, the ranking measure can decide which one is better in a consistent manner on almost all datasets. We show that NDCG with logarithmic discount has consistent distinguishability although it converges to the same limit for all ranking functions. We next characterize the set of all feasible discount functions for NDCG according to the concept of consistent distinguishability. Specifically we show that whether NDCG has consistent distinguishability depends on how fast the discount decays, and 1/r is a critical point. We then turn to the cut-off version of NDCG, i.e., NDCG@k. We analyze the distinguishability of NDCG@k for various choices of k and the discount functions. Experimental results on real Web search datasets agree well with the theory.