 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning by Curriculum Learning for Non-Autoregressive Neural Machine Translation
Nov 21, 2019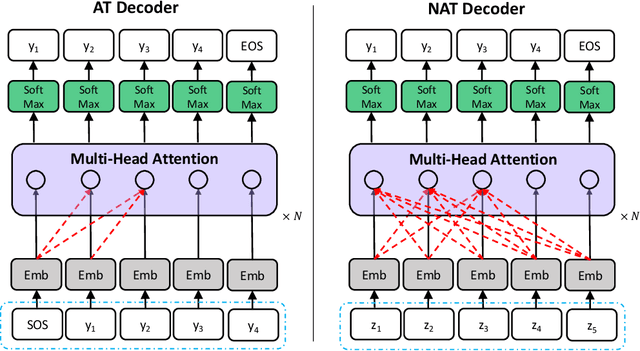

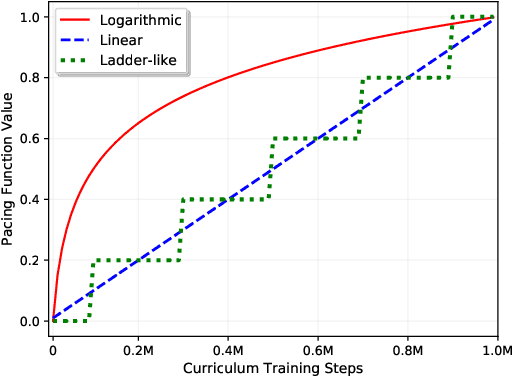
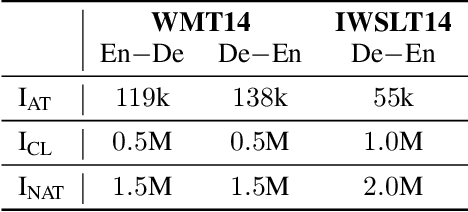
Non-autoregressive translation (NAT) models remove the dependence on previous target tokens and generate all target tokens in parallel, resulting in significant inference speedup but at the cost of inferior translation accuracy compared to autoregressive translation (AT) models. Considering that AT models have higher accuracy and are easier to train than NAT models, and both of them share the same model configurations, a natural idea to improve the accuracy of NAT models is to transfer a well-trained AT model to an NAT model through fine-tuning. However, since AT and NAT models differ greatly in training strategy, straightforward fine-tuning does not work well. In this work, we introduce curriculum learning into fine-tuning for NAT. Specifically, we design a curriculum in the fine-tuning process to progressively switch the training from autoregressive generation to non-autoregressive generation. Experiments on four benchmark translation datasets show that the proposed method achieves good improvement (more than $1$ BLEU score) over previous NAT baselines in terms of translation accuracy, and greatly speed up (more than $10$ times) the inference process over AT baselines.
Microsoft Research Asia's Systems for WMT19
Nov 07, 2019

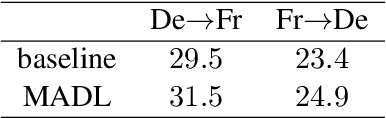
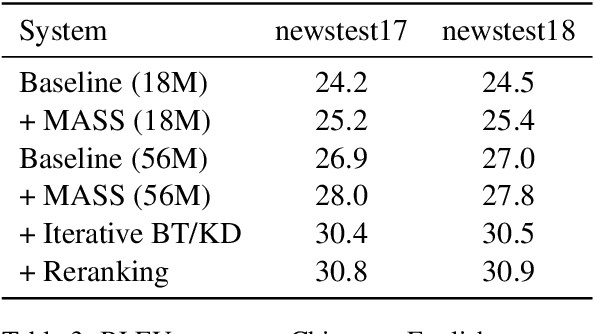
We Microsoft Research Asia made submissions to 11 language directions in the WMT19 news translation tasks. We won the first place for 8 of the 11 directions and the second place for the other three. Our basic systems are built on Transformer, back translation and knowledge distillation. We integrate several of our rececent techniques to enhance the baseline systems: multi-agent dual learning (MADL), masked sequence-to-sequence pre-training (MASS), neural architecture optimization (NAO), and soft contextual data augmentation (SCA).
Distributional Reward Decomposition for Reinforcement Learning
Nov 06, 2019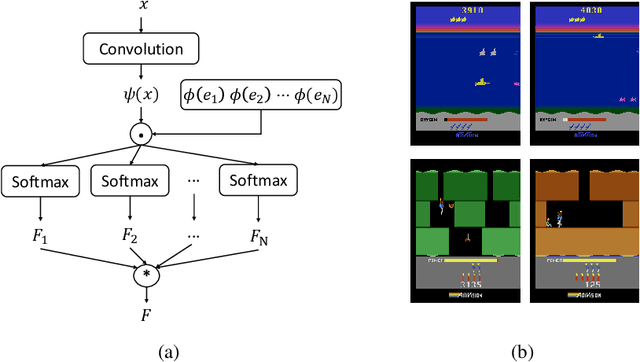
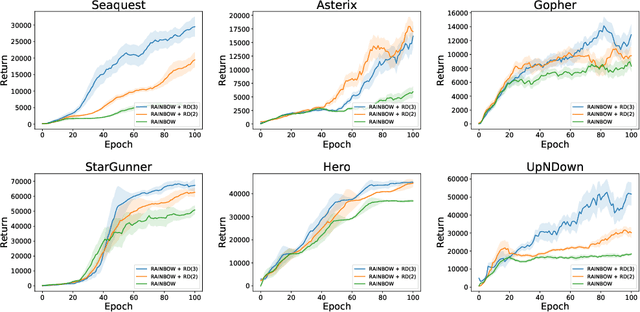
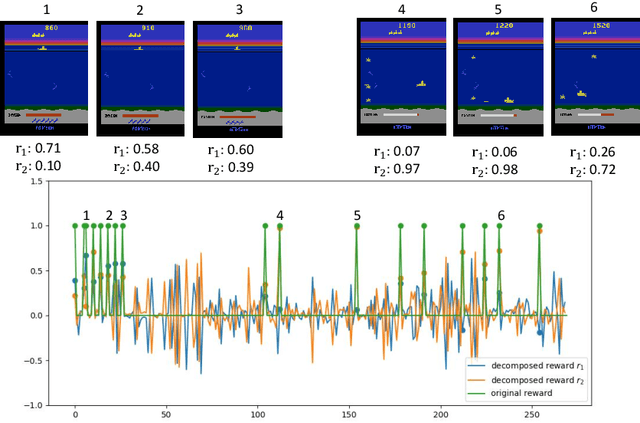
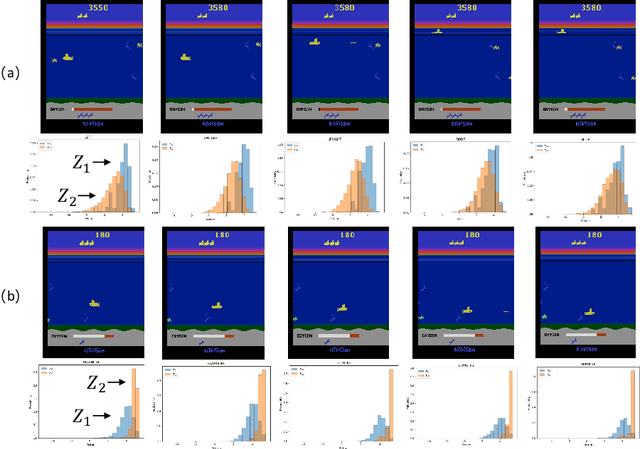
Many reinforcement learning (RL) tasks have specific properties that can be leveraged to modify existing RL algorithms to adapt to those tasks and further improve performance, and a general class of such properties is the multiple reward channel. In those environments the full reward can be decomposed into sub-rewards obtained from different channels. Existing work on reward decomposition either requires prior knowledge of the environment to decompose the full reward, or decomposes reward without prior knowledge but with degraded performance. In this paper, we propose Distributional Reward Decomposition for Reinforcement Learning (DRDRL), a novel reward decomposition algorithm which captures the multiple reward channel structure under distributional setting. Empirically, our method captures the multi-channel structure and discovers meaningful reward decomposition, without any requirements on prior knowledge. Consequently, our agent achieves better performance than existing methods on environments with multiple reward channels.
Hint-Based Training for Non-Autoregressive Machine Translation
Sep 15, 2019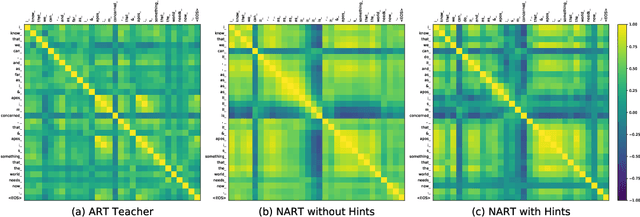
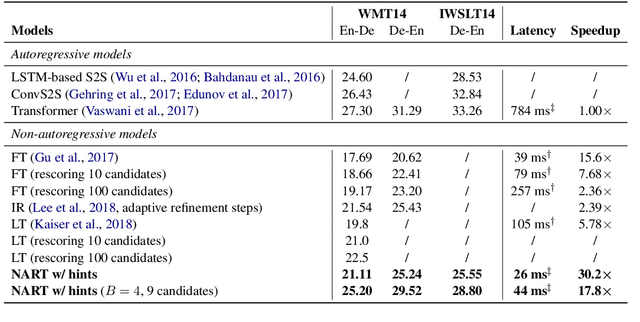
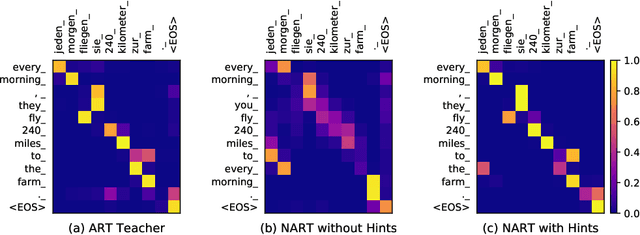
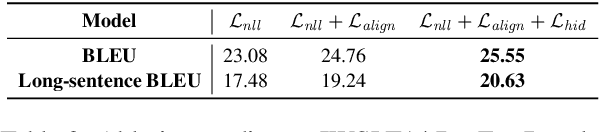
Due to the unparallelizable nature of the autoregressive factorization, AutoRegressive Translation (ART) models have to generate tokens sequentially during decoding and thus suffer from high inference latency. Non-AutoRegressive Translation (NART) models were proposed to reduce the inference time, but could only achieve inferior translation accuracy. In this paper, we proposed a novel approach to leveraging the hints from hidden states and word alignments to help the training of NART models. The results achieve significant improvement over previous NART models for the WMT14 En-De and De-En datasets and are even comparable to a strong LSTM-based ART baseline but one order of magnitude faster in inference.
Self-paced Ensemble for Highly Imbalanced Massive Data Classification
Sep 10, 2019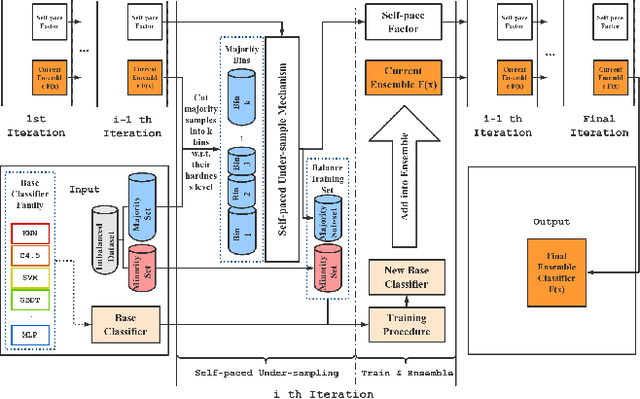
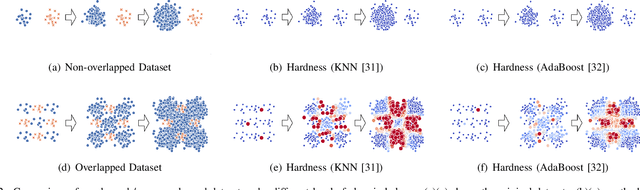
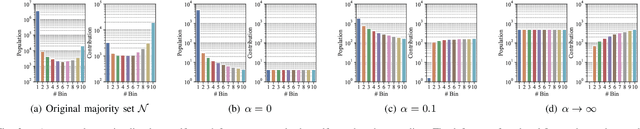
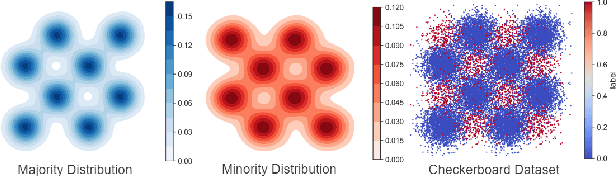
Many real-world applications reveal difficulties in learning classifiers from imbalanced data. The rising big data era has been witnessing more classification tasks with large-scale but extremely imbalance and low-quality datasets. Most of existing learning methods suffer from poor performance or low computation efficiency under such a scenario. To tackle this problem, we conduct deep investigations into the nature of class imbalance, which reveals that not only the disproportion between classes, but also other difficulties embedded in the nature of data, especially, noises and class overlapping, prevent us from learning effective classifiers. Taking those factors into consideration, we propose a novel framework for imbalance classification that aims to generate a strong ensemble by self-paced harmonizing data hardness via under-sampling. Extensive experiments have shown that this new framework, while being very computationally efficient, can lead to robust performance even under highly overlapping classes and extremely skewed distribution. Note that, our methods can be easily adapted to most of existing learning methods (e.g., C4.5, SVM, GBDT and Neural Network) to boost their performance on imbalanced data.
Multilingual Neural Machine Translation with Language Clustering
Aug 25, 2019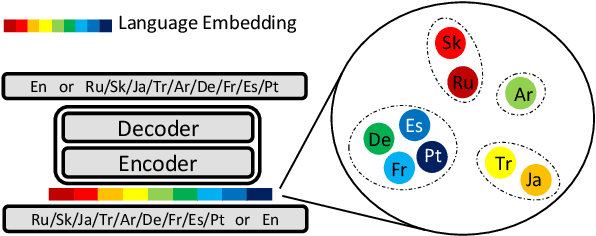
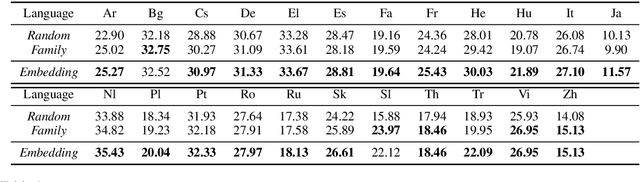
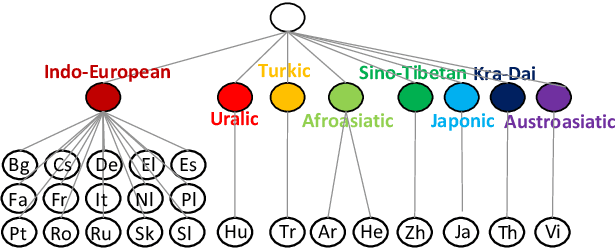
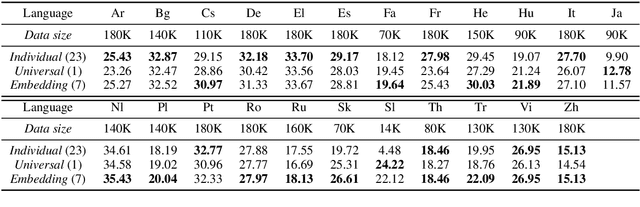
Multilingual neural machine translation (NMT), which translates multiple languages using a single model, is of great practical importance due to its advantages in simplifying the training process, reducing online maintenance costs, and enhancing low-resource and zero-shot translation. Given there are thousands of languages in the world and some of them are very different, it is extremely burdensome to handle them all in a single model or use a separate model for each language pair. Therefore, given a fixed resource budget, e.g., the number of models, how to determine which languages should be supported by one model is critical to multilingual NMT, which, unfortunately, has been ignored by previous work. In this work, we develop a framework that clusters languages into different groups and trains one multilingual model for each cluster. We study two methods for language clustering: (1) using prior knowledge, where we cluster languages according to language family, and (2) using language embedding, in which we represent each language by an embedding vector and cluster them in the embedding space. In particular, we obtain the embedding vectors of all the languages by training a universal neural machine translation model. Our experiments on 23 languages show that the first clustering method is simple and easy to understand but leading to suboptimal translation accuracy, while the second method sufficiently captures the relationship among languages well and improves the translation accuracy for almost all the languages over baseline methods
Representation Degeneration Problem in Training Natural Language Generation Models
Jul 28, 2019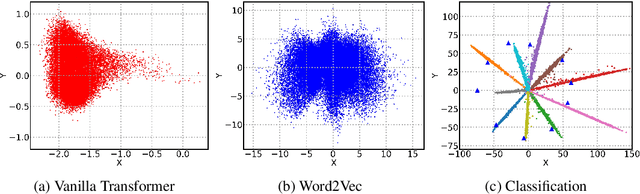
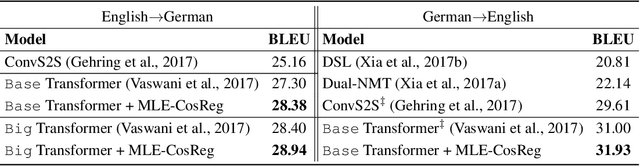
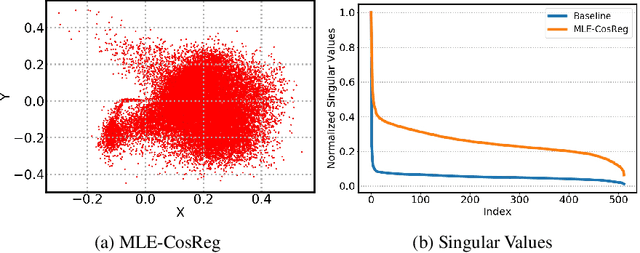
We study an interesting problem in training neural network-based models for natural language generation tasks, which we call the \emph{representation degeneration problem}. We observe that when training a model for natural language generation tasks through likelihood maximization with the weight tying trick, especially with big training datasets, most of the learnt word embeddings tend to degenerate and be distributed into a narrow cone, which largely limits the representation power of word embeddings. We analyze the conditions and causes of this problem and propose a novel regularization method to address it. Experiments on language modeling and machine translation show that our method can largely mitigate the representation degeneration problem and achieve better performance than baseline algorithms.
Light Multi-segment Activation for Model Compression
Jul 16, 2019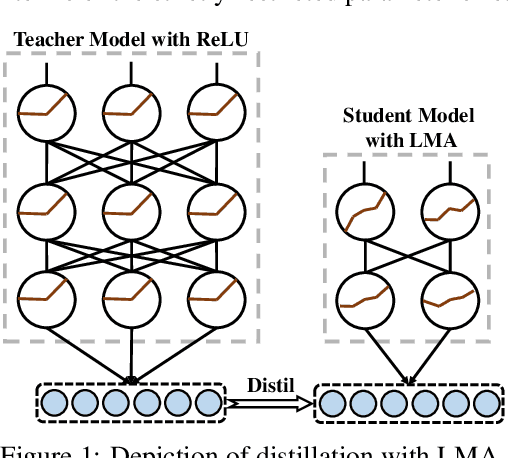

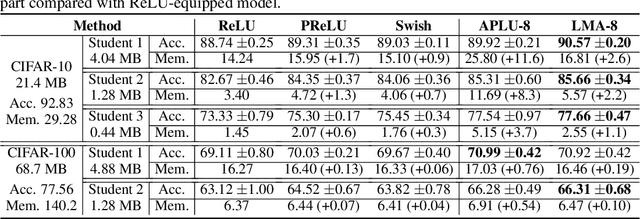
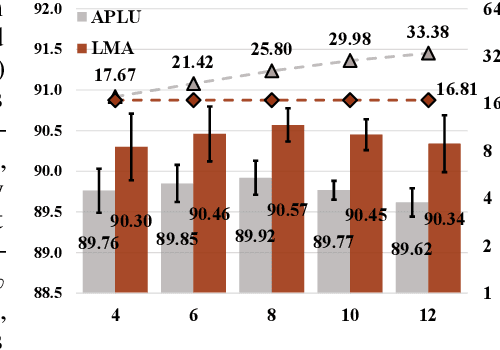
Model compression has become necessary when applying neural networks (NN) into many real application tasks that can accept slightly-reduced model accuracy with strict tolerance to model complexity. Recently, Knowledge Distillation, which distills the knowledge from well-trained and highly complex teacher model into a compact student model, has been widely used for model compression. However, under the strict requirement on the resource cost, it is quite challenging to achieve comparable performance with the teacher model, essentially due to the drastically-reduced expressiveness ability of the compact student model. Inspired by the nature of the expressiveness ability in Neural Networks, we propose to use multi-segment activation, which can significantly improve the expressiveness ability with very little cost, in the compact student model. Specifically, we propose a highly efficient multi-segment activation, called Light Multi-segment Activation (LMA), which can rapidly produce multiple linear regions with very few parameters by leveraging the statistical information. With using LMA, the compact student model is capable of achieving much better performance effectively and efficiently, than the ReLU-equipped one with same model scale. Furthermore, the proposed method is compatible with other model compression techniques, such as quantization, which means they can be used jointly for better compression performance. Experiments on state-of-the-art NN architectures over the real-world tasks demonstrate the effectiveness and extensibility of the LMA.
Depth Growing for Neural Machine Translation
Jul 03, 2019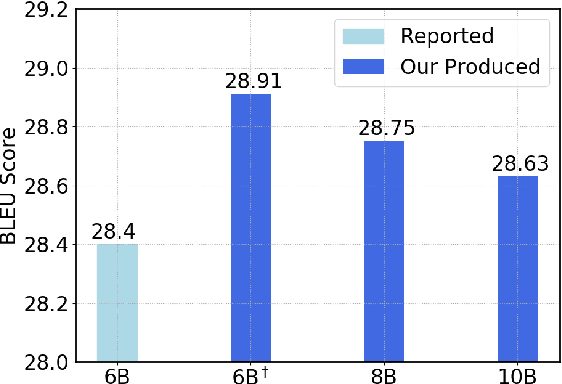
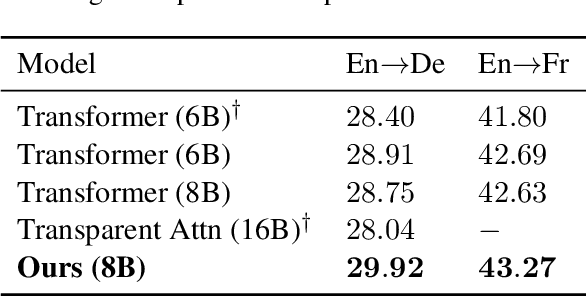
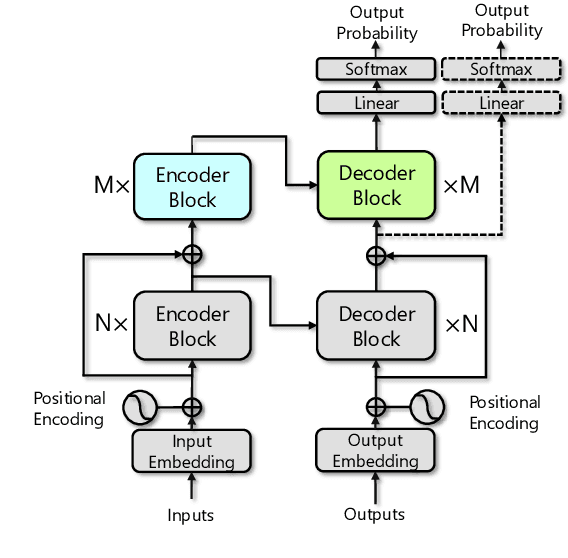
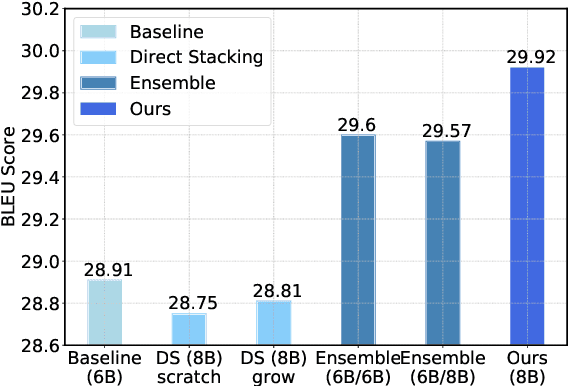
While very deep neural networks have shown effectiveness for computer vision and text classification applications, how to increase the network depth of neural machine translation (NMT) models for better translation quality remains a challenging problem. Directly stacking more blocks to the NMT model results in no improvement and even reduces performance. In this work, we propose an effective two-stage approach with three specially designed components to construct deeper NMT models, which result in significant improvements over the strong Transformer baselines on WMT$14$ English$\to$German and English$\to$French translation tasks\footnote{Our code is available at \url{https://github.com/apeterswu/Depth_Growing_NMT}}.
Unsupervised Pivot Translation for Distant Languages
Jun 25, 2019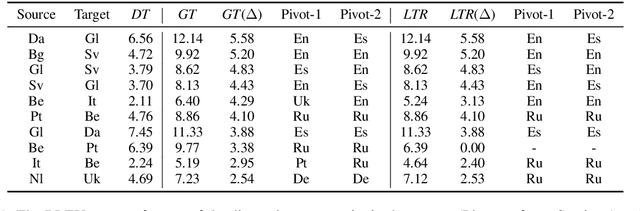
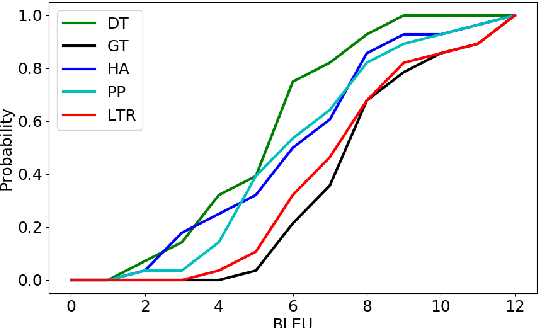
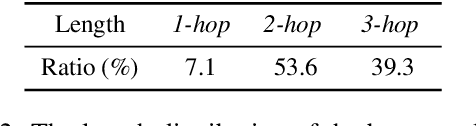
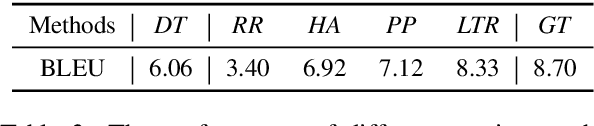
Unsupervised neural machine translation (NMT) has attracted a lot of attention recently. While state-of-the-art methods for unsupervised translation usually perform well between similar languages (e.g., English-German translation), they perform poorly between distant languages, because unsupervised alignment does not work well for distant languages. In this work, we introduce unsupervised pivot translation for distant languages, which translates a language to a distant language through multiple hops, and the unsupervised translation on each hop is relatively easier than the original direct translation. We propose a learning to route (LTR) method to choose the translation path between the source and target languages. LTR is trained on language pairs whose best translation path is available and is applied on the unseen language pairs for path selection. Experiments on 20 languages and 294 distant language pairs demonstrate the advantages of the unsupervised pivot translation for distant languages, as well as the effectiveness of the proposed LTR for path selection. Specifically, in the best case, LTR achieves an improvement of 5.58 BLEU points over the conventional direct unsupervised method.