 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing LLM Metacognition via Cognitive Pairwise Training
May 30, 2026Reinforcement learning with verifiable rewards (RLVR) has become central to LLM reasoning, but its outcome-level rewards can make models more willing to give confident answers when evidence or reasoning is unreliable. Existing SFT or RL methods mainly teach LLMs to refuse or express uncertainty at the response level, which can overfit abstention behavior rather than improve reasoning reliability. To address this limitation, we propose Cognitive Pairwise Training (CPT), a cognitive mid-training alignment stage that turns pairwise comparisons over reasoning traces into a reusable alignment signal. By learning to distinguish trustworthy from flawed reasoning, CPT encourages the model to internalize a reasoning-quality discrimination boundary rather than memorize surface refusal patterns. Across five model scales and three model families, CPT improves the reasoning--metacognition trade-off. At 14B, CPT+RL outperforms the standard SFT+RL pipeline by +2.2 math-average points and +5.2 abstention-F1 points. Further analyses show that CPT improves trace quality and exhibits strong robustness and scalability across evaluation and training settings. Code and models are released at https://github.com/Tsinghua-dhy/CPT.
A Mamba Foundation Model for Time Series Forecasting
Nov 05, 2024



Time series foundation models have demonstrated strong performance in zero-shot learning, making them well-suited for predicting rapidly evolving patterns in real-world applications where relevant training data are scarce. However, most of these models rely on the Transformer architecture, which incurs quadratic complexity as input length increases. To address this, we introduce TSMamba, a linear-complexity foundation model for time series forecasting built on the Mamba architecture. The model captures temporal dependencies through both forward and backward Mamba encoders, achieving high prediction accuracy. To reduce reliance on large datasets and lower training costs, TSMamba employs a two-stage transfer learning process that leverages pretrained Mamba LLMs, allowing effective time series modeling with a moderate training set. In the first stage, the forward and backward backbones are optimized via patch-wise autoregressive prediction; in the second stage, the model trains a prediction head and refines other components for long-term forecasting. While the backbone assumes channel independence to manage varying channel numbers across datasets, a channel-wise compressed attention module is introduced to capture cross-channel dependencies during fine-tuning on specific multivariate datasets. Experiments show that TSMamba's zero-shot performance is comparable to state-of-the-art time series foundation models, despite using significantly less training data. It also achieves competitive or superior full-shot performance compared to task-specific prediction models. The code will be made publicly available.
RecycleGPT: An Autoregressive Language Model with Recyclable Module
Aug 08, 2023Existing large language models have to run K times to generate a sequence of K tokens. In this paper, we present RecycleGPT, a generative language model with fast decoding speed by recycling pre-generated model states without running the whole model in multiple steps. Our approach relies on the observation that adjacent tokens in a sequence usually have strong correlations and the next token in a sequence can be reasonably guessed or inferred based on the preceding ones. Experiments and analysis demonstrate the effectiveness of our approach in lowering inference latency, achieving up to 1.4x speedup while preserving high performance.
A Joint Time-frequency Domain Transformer for Multivariate Time Series Forecasting
May 24, 2023To enhance predicting performance while minimizing computational demands, this paper introduces a joint time-frequency domain Transformer (JTFT) for multivariate forecasting. The method exploits the sparsity of time series in the frequency domain using a small number of learnable frequencies to extract temporal dependencies effectively. Alongside the frequency domain representation, a fixed number of the most recent data points are directly encoded in the time domain, bolstering the learning of local relationships and mitigating the adverse effects of non-stationarity. JTFT achieves linear complexity since the length of the internal representation remains independent of the input sequence length. Additionally, a low-rank attention layer is proposed to efficiently capture cross-dimensional dependencies and prevent performance degradation due to the entanglement of temporal and channel-wise modeling. Experiments conducted on six real-world datasets demonstrate that JTFT outperforms state-of-the-art methods.
Heterogeneous Information Network based Default Analysis on Banking Micro and Small Enterprise Users
May 02, 2022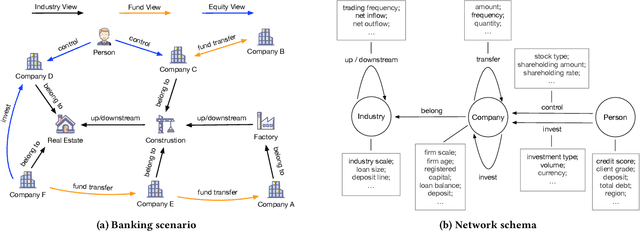
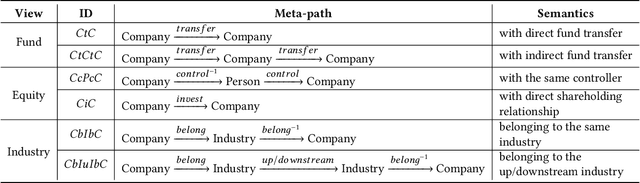
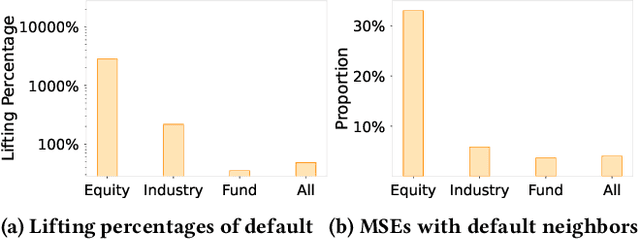

Risk assessment is a substantial problem for financial institutions that has been extensively studied both for its methodological richness and its various practical applications. With the expansion of inclusive finance, recent attentions are paid to micro and small-sized enterprises (MSEs). Compared with large companies, MSEs present a higher exposure rate to default owing to their insecure financial stability. Conventional efforts learn classifiers from historical data with elaborate feature engineering. However, the main obstacle for MSEs involves severe deficiency in credit-related information, which may degrade the performance of prediction. Besides, financial activities have diverse explicit and implicit relations, which have not been fully exploited for risk judgement in commercial banks. In particular, the observations on real data show that various relationships between company users have additional power in financial risk analysis. In this paper, we consider a graph of banking data, and propose a novel HIDAM model for the purpose. Specifically, we attempt to incorporate heterogeneous information network with rich attributes on multi-typed nodes and links for modeling the scenario of business banking service. To enhance feature representation of MSEs, we extract interactive information through meta-paths and fully exploit path information. Furthermore, we devise a hierarchical attention mechanism respectively to learn the importance of contents inside each meta-path and the importance of different metapahs. Experimental results verify that HIDAM outperforms state-of-the-art competitors on real-world banking data.
Model-based Adversarial Meta-Reinforcement Learning
Jun 16, 2020
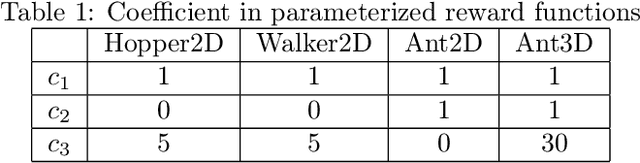
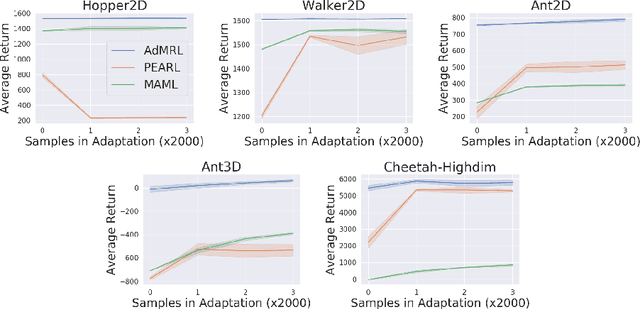
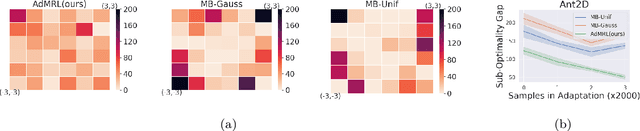
Meta-reinforcement learning (meta-RL) aims to learn from multiple training tasks the ability to adapt efficiently to unseen test tasks. Despite the success, existing meta-RL algorithms are known to be sensitive to the task distribution shift. When the test task distribution is different from the training task distribution, the performance may degrade significantly. To address this issue, this paper proposes Model-based Adversarial Meta-Reinforcement Learning (AdMRL), where we aim to minimize the worst-case sub-optimality gap -- the difference between the optimal return and the return that the algorithm achieves after adaptation -- across all tasks in a family of tasks, with a model-based approach. We propose a minimax objective and optimize it by alternating between learning the dynamics model on a fixed task and finding the adversarial task for the current model -- the task for which the policy induced by the model is maximally suboptimal. Assuming the family of tasks is parameterized, we derive a formula for the gradient of the suboptimality with respect to the task parameters via the implicit function theorem, and show how the gradient estimator can be efficiently implemented by the conjugate gradient method and a novel use of the REINFORCE estimator. We evaluate our approach on several continuous control benchmarks and demonstrate its efficacy in the worst-case performance over all tasks, the generalization power to out-of-distribution tasks, and in training and test time sample efficiency, over existing state-of-the-art meta-RL algorithms.
Distributional Reward Decomposition for Reinforcement Learning
Nov 06, 2019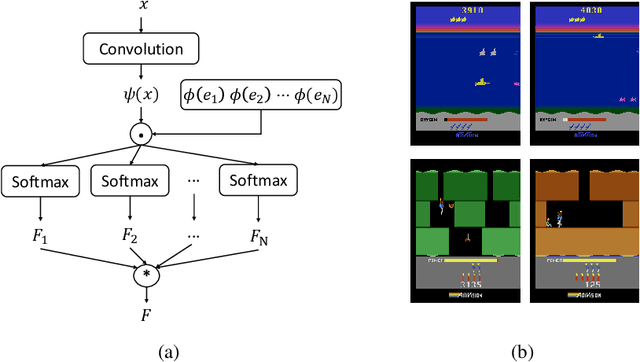
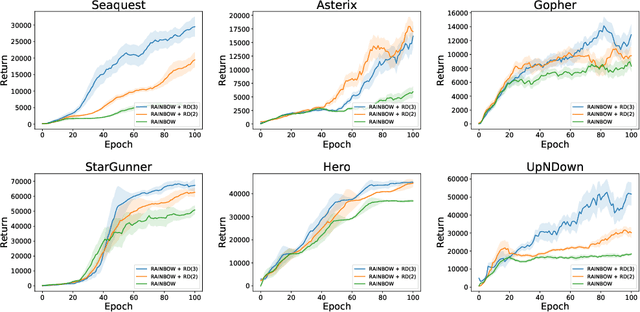
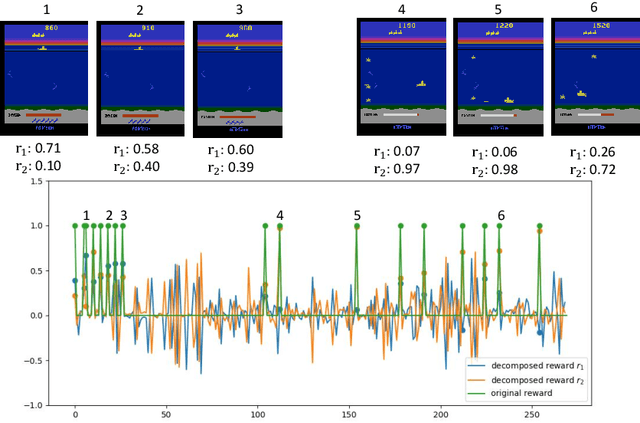
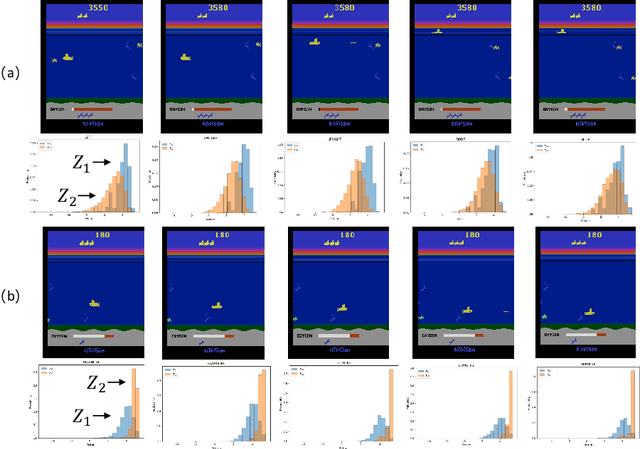
Many reinforcement learning (RL) tasks have specific properties that can be leveraged to modify existing RL algorithms to adapt to those tasks and further improve performance, and a general class of such properties is the multiple reward channel. In those environments the full reward can be decomposed into sub-rewards obtained from different channels. Existing work on reward decomposition either requires prior knowledge of the environment to decompose the full reward, or decomposes reward without prior knowledge but with degraded performance. In this paper, we propose Distributional Reward Decomposition for Reinforcement Learning (DRDRL), a novel reward decomposition algorithm which captures the multiple reward channel structure under distributional setting. Empirically, our method captures the multi-channel structure and discovers meaningful reward decomposition, without any requirements on prior knowledge. Consequently, our agent achieves better performance than existing methods on environments with multiple reward channels.
NAMSG: An Efficient Method For Training Neural Networks
May 23, 2019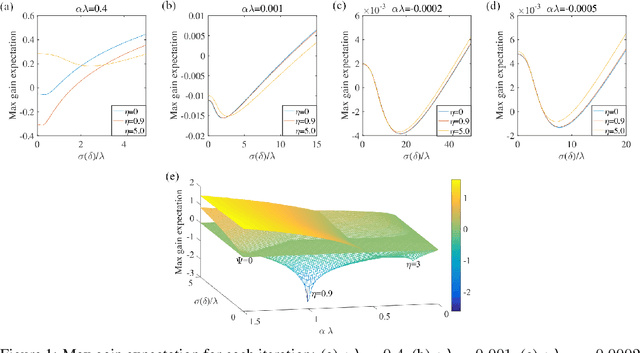
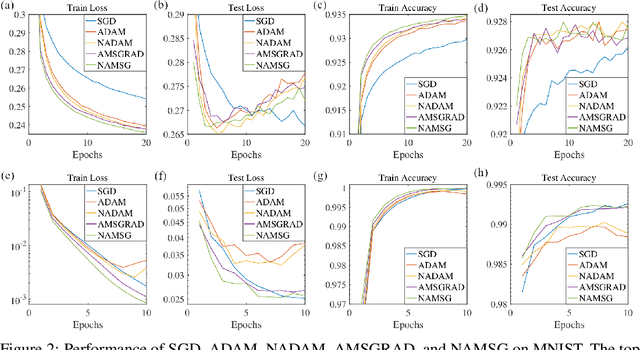
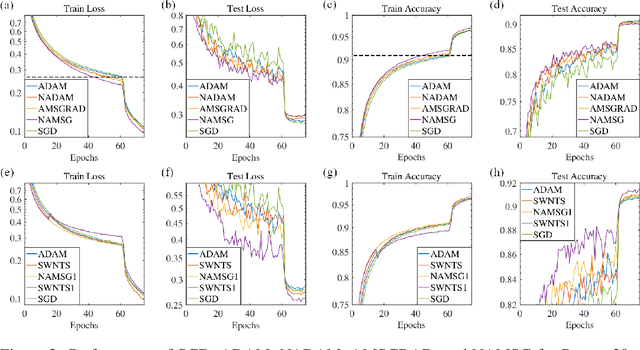
We introduce NAMSG, an adaptive first-order algorithm for training neural networks. The method is efficient in computation and memory, and is straightforward to implement. It computes the gradients at configurable remote observation points, in order to expedite the convergence by adjusting the step size for directions with different curvatures in the stochastic setting. It also scales the updating vector elementwise by a nonincreasing preconditioner to take the advantages of AMSGRAD. We analyze the convergence properties for both convex and nonconvex problems by modeling the training process as a dynamic system, and provide a guideline to select the observation distance without grid search. A data-dependent regret bound is proposed to guarantee the convergence in the convex setting. Experiments demonstrate that NAMSG works well in practical problems and compares favorably to popular adaptive methods, such as ADAM, NADAM, and AMSGRAD.
swTVM: Exploring the Automated Compilation for Deep Learning on Sunway Architecture
Apr 18, 2019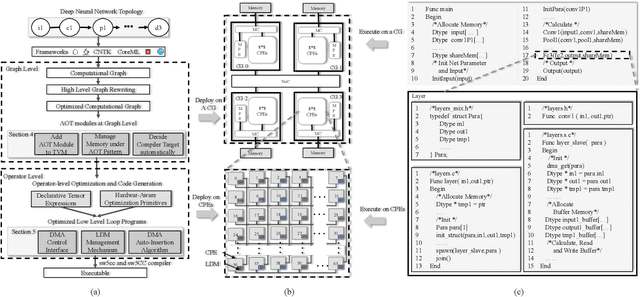
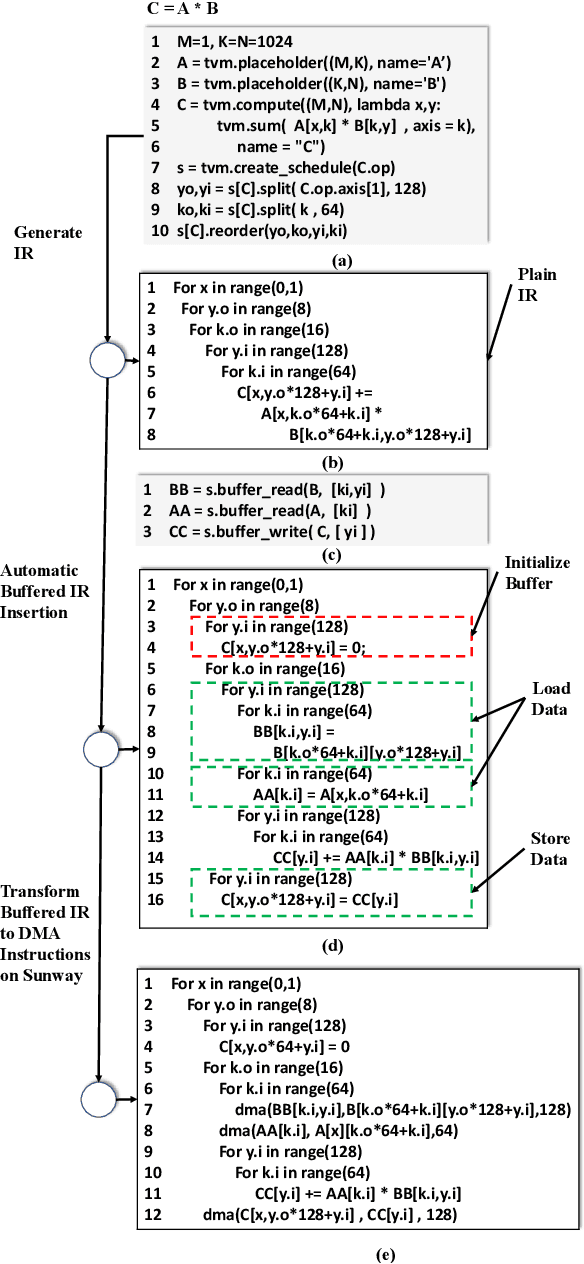

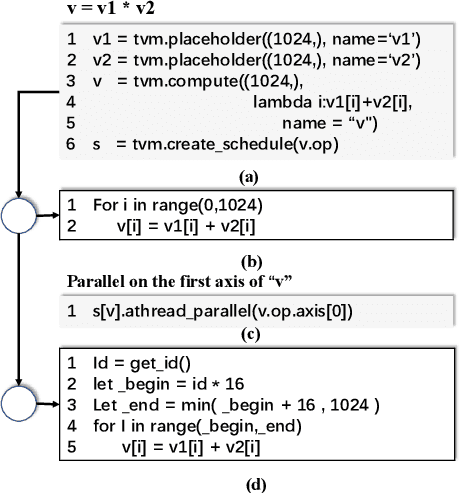
The flourish of deep learning frameworks and hardware platforms has been demanding an efficient compiler that can shield the diversity in both software and hardware in order to provide application portability. Among the exiting deep learning compilers, TVM is well known for its efficiency in code generation and optimization across diverse hardware devices. In the meanwhile, the Sunway many-core processor renders itself as a competitive candidate for its attractive computational power in both scientific and deep learning applications. This paper combines the trends in these two directions. Specifically, we propose swTVM that extends the original TVM to support ahead-of-time compilation for architecture requiring cross-compilation such as Sunway. In addition, we leverage the architecture features during the compilation such as core group for massive parallelism, DMA for high bandwidth memory transfer and local device memory for data locality, in order to generate efficient code for deep learning application on Sunway. The experimental results show the ability of swTVM to automatically generate code for various deep neural network models on Sunway. The performance of automatically generated code for AlexNet and VGG-19 by swTVM achieves 6.71x and 2.45x speedup on average than hand-optimized OpenACC implementations on convolution and fully connected layers respectively. This work is the first attempt from the compiler perspective to bridge the gap of deep learning and high performance architecture particularly with productivity and efficiency in mind. We would like to open source the implementation so that more people can embrace the power of deep learning compiler and Sunway many-core processor.
swCaffe: a Parallel Framework for Accelerating Deep Learning Applications on Sunway TaihuLight
Mar 16, 2019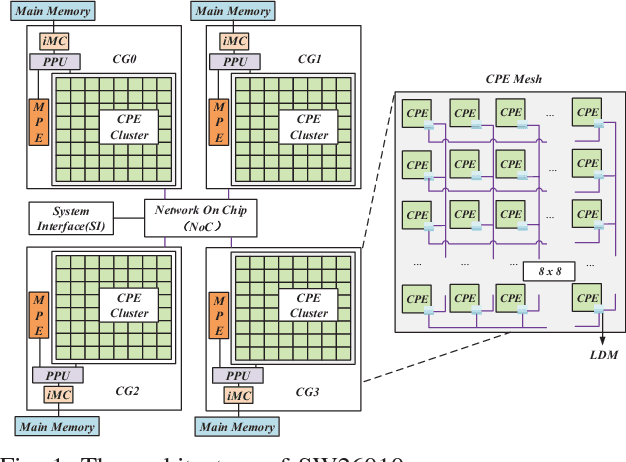
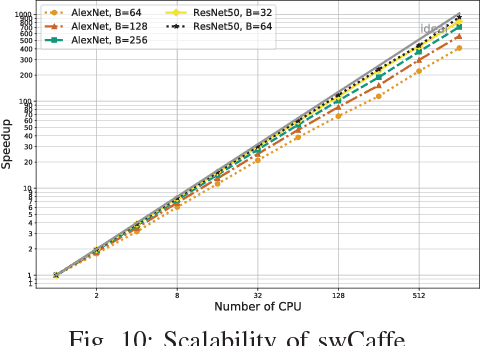
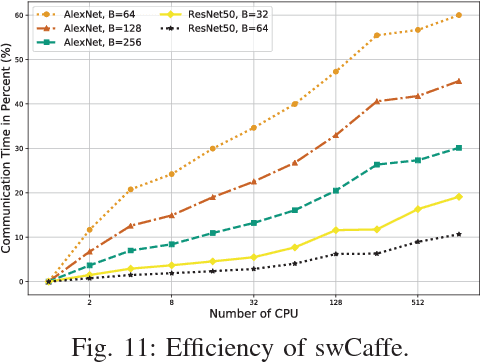
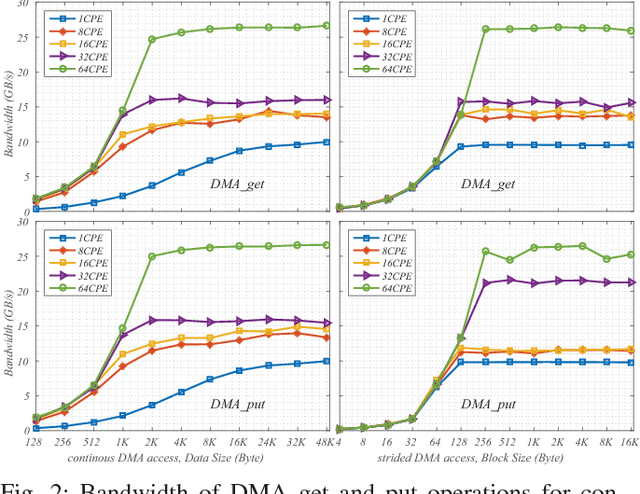
This paper reports our efforts on swCaffe, a highly efficient parallel framework for accelerating deep neural networks (DNNs) training on Sunway TaihuLight, the current fastest supercomputer in the world that adopts a unique many-core heterogeneous architecture, with 40,960 SW26010 processors connected through a customized communication network. First, we point out some insightful principles to fully exploit the performance of the innovative many-core architecture. Second, we propose a set of optimization strategies for redesigning a variety of neural network layers based on Caffe. Third, we put forward a topology-aware parameter synchronization scheme to scale the synchronous Stochastic Gradient Descent (SGD) method to multiple processors efficiently. We evaluate our framework by training a variety of widely used neural networks with the ImageNet dataset. On a single node, swCaffe can achieve 23\%\~{}119\% overall performance compared with Caffe running on K40m GPU. As compared with the Caffe on CPU, swCaffe runs 3.04\~{}7.84x faster on all the networks. Finally, we present the scalability of swCaffe for the training of ResNet-50 and AlexNet on the scale of 1024 nodes.