 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLRSpeech: Extremely Low-Resource Speech Synthesis and Recognition
Aug 09, 2020

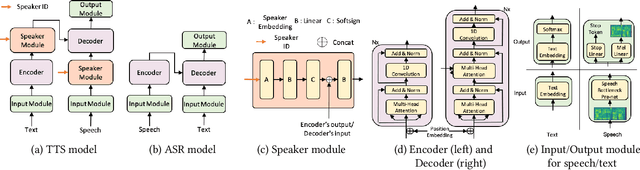
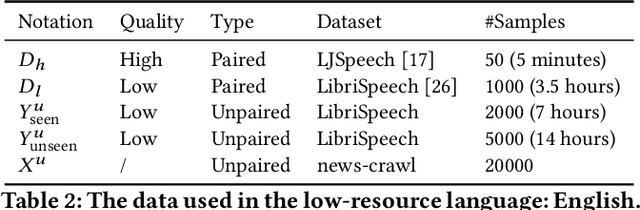
Speech synthesis (text to speech, TTS) and recognition (automatic speech recognition, ASR) are important speech tasks, and require a large amount of text and speech pairs for model training. However, there are more than 6,000 languages in the world and most languages are lack of speech training data, which poses significant challenges when building TTS and ASR systems for extremely low-resource languages. In this paper, we develop LRSpeech, a TTS and ASR system under the extremely low-resource setting, which can support rare languages with low data cost. LRSpeech consists of three key techniques: 1) pre-training on rich-resource languages and fine-tuning on low-resource languages; 2) dual transformation between TTS and ASR to iteratively boost the accuracy of each other; 3) knowledge distillation to customize the TTS model on a high-quality target-speaker voice and improve the ASR model on multiple voices. We conduct experiments on an experimental language (English) and a truly low-resource language (Lithuanian) to verify the effectiveness of LRSpeech. Experimental results show that LRSpeech 1) achieves high quality for TTS in terms of both intelligibility (more than 98% intelligibility rate) and naturalness (above 3.5 mean opinion score (MOS)) of the synthesized speech, which satisfy the requirements for industrial deployment, 2) achieves promising recognition accuracy for ASR, and 3) last but not least, uses extremely low-resource training data. We also conduct comprehensive analyses on LRSpeech with different amounts of data resources, and provide valuable insights and guidances for industrial deployment. We are currently deploying LRSpeech into a commercialized cloud speech service to support TTS on more rare languages.
Taking Notes on the Fly Helps BERT Pre-training
Aug 04, 2020
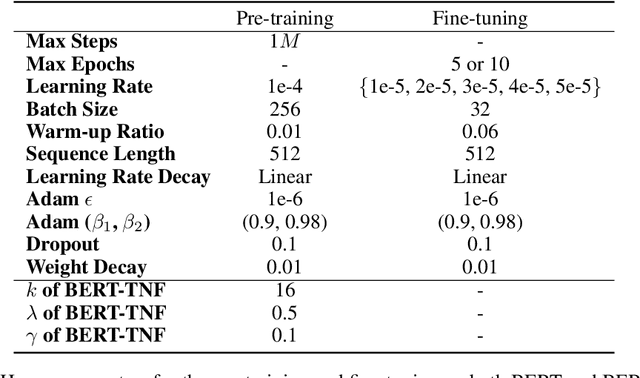
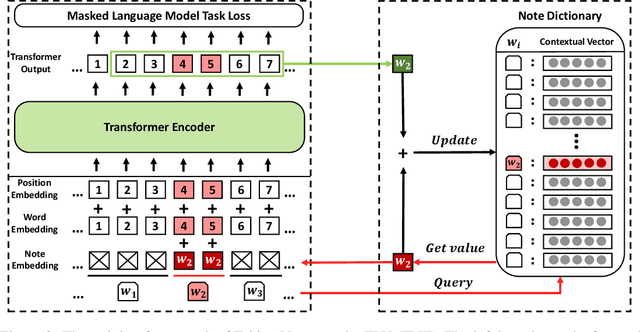

How to make unsupervised language pre-training more efficient and less resource-intensive is an important research direction in NLP. In this paper, we focus on improving the efficiency of language pre-training methods through providing better data utilization. It is well-known that in language data corpus, words follow a heavy-tail distribution. A large proportion of words appear only very few times and the embeddings of rare words are usually poorly optimized. We argue that such embeddings carry inadequate semantic signals. They could make the data utilization inefficient and slow down the pre-training of the entire model. To solve this problem, we propose Taking Notes on the Fly (TNF). TNF takes notes for rare words on the fly during pre-training to help the model understand them when they occur next time. Specifically, TNF maintains a note dictionary and saves a rare word's context information in it as notes when the rare word occurs in a sentence. When the same rare word occurs again in training, TNF employs the note information saved beforehand to enhance the semantics of the current sentence. By doing so, TNF provides a better data utilization since cross-sentence information is employed to cover the inadequate semantics caused by rare words in the sentences. Experimental results show that TNF significantly expedite the BERT pre-training and improve the model's performance on downstream tasks. TNF's training time is $60\%$ less than BERT when reaching the same performance. When trained with same number of iterations, TNF significantly outperforms BERT on most of downstream tasks and the average GLUE score.
Learning to Match Distributions for Domain Adaptation
Jul 27, 2020

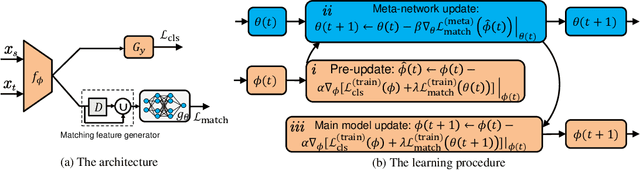
When the training and test data are from different distributions, domain adaptation is needed to reduce dataset bias to improve the model's generalization ability. Since it is difficult to directly match the cross-domain joint distributions, existing methods tend to reduce the marginal or conditional distribution divergence using predefined distances such as MMD and adversarial-based discrepancies. However, it remains challenging to determine which method is suitable for a given application since they are built with certain priors or bias. Thus they may fail to uncover the underlying relationship between transferable features and joint distributions. This paper proposes Learning to Match (L2M) to automatically learn the cross-domain distribution matching without relying on hand-crafted priors on the matching loss. Instead, L2M reduces the inductive bias by using a meta-network to learn the distribution matching loss in a data-driven way. L2M is a general framework that unifies task-independent and human-designed matching features. We design a novel optimization algorithm for this challenging objective with self-supervised label propagation. Experiments on public datasets substantiate the superiority of L2M over SOTA methods. Moreover, we apply L2M to transfer from pneumonia to COVID-19 chest X-ray images with remarkable performance. L2M can also be extended in other distribution matching applications where we show in a trial experiment that L2M generates more realistic and sharper MNIST samples.
Membership Inference with Privately Augmented Data Endorses the Benign while Suppresses the Adversary
Jul 21, 2020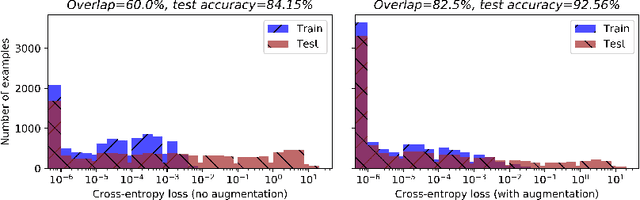
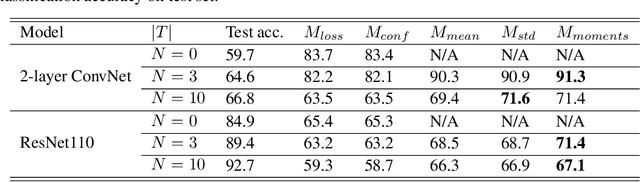
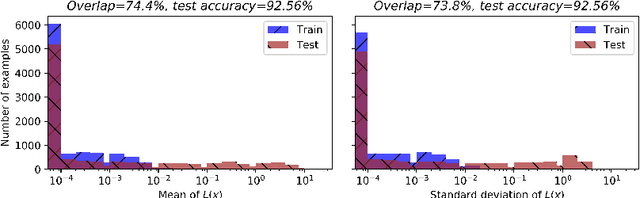

Membership inference (MI) in machine learning decides whether a given example is in target model's training set. It can be used in two ways: adversaries use it to steal private membership information while legitimate users can use it to verify whether their data has been forgotten by a trained model. Therefore, MI is a double-edged sword to privacy preserving machine learning. In this paper, we propose using private augmented data to sharpen its good side while passivate its bad side. To sharpen the good side, we exploit the data augmentation used in training to boost the accuracy of membership inference. Specifically, we compose a set of augmented instances for each sample and then the membership inference is formulated as a set classification problem, i.e., classifying a set of augmented data points instead of one point. We design permutation invariant features based on the losses of augmented instances. Our approach significantly improves the MI accuracy over existing algorithms. To passivate the bad side, we apply different data augmentation methods to each legitimate user and keep the augmented data as secret. We show that the malicious adversaries cannot benefit from our algorithms if being ignorant of the augmented data used in training. Extensive experiments demonstrate the superior efficacy of our algorithms. Our source code is available at anonymous GitHub page \url{https://github.com/AnonymousDLMA/MI_with_DA}.
Task-Level Curriculum Learning for Non-Autoregressive Neural Machine Translation
Jul 17, 2020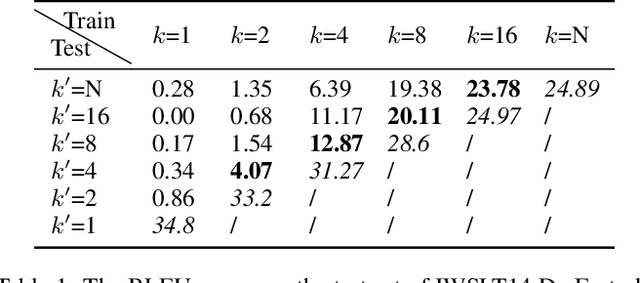
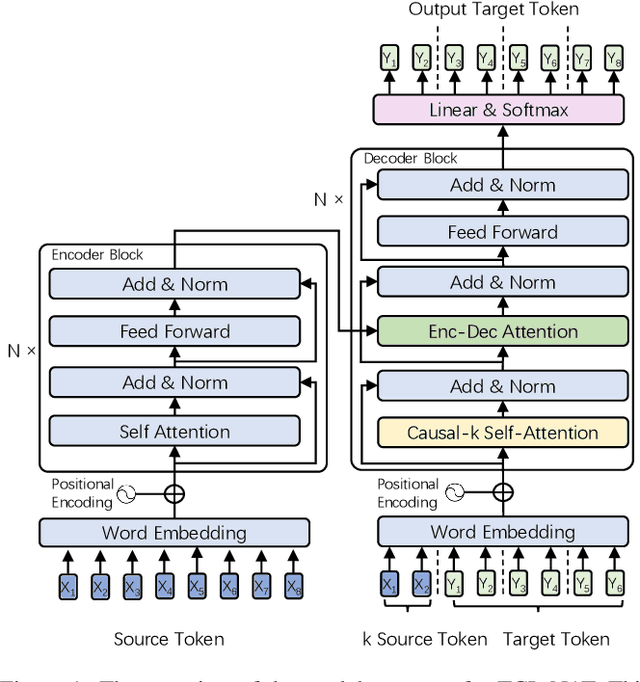
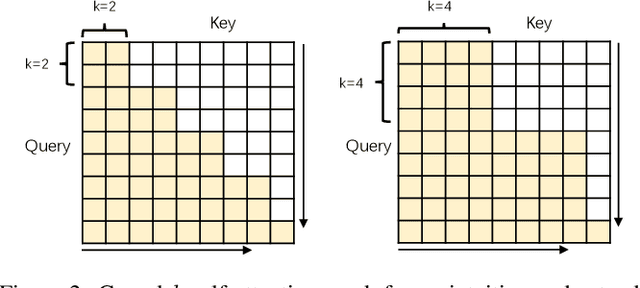
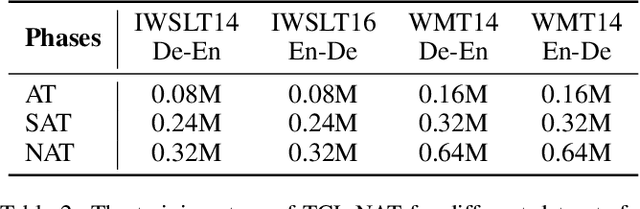
Non-autoregressive translation (NAT) achieves faster inference speed but at the cost of worse accuracy compared with autoregressive translation (AT). Since AT and NAT can share model structure and AT is an easier task than NAT due to the explicit dependency on previous target-side tokens, a natural idea is to gradually shift the model training from the easier AT task to the harder NAT task. To smooth the shift from AT training to NAT training, in this paper, we introduce semi-autoregressive translation (SAT) as intermediate tasks. SAT contains a hyperparameter k, and each k value defines a SAT task with different degrees of parallelism. Specially, SAT covers AT and NAT as its special cases: it reduces to AT when k = 1 and to NAT when k = N (N is the length of target sentence). We design curriculum schedules to gradually shift k from 1 to N, with different pacing functions and number of tasks trained at the same time. We called our method as task-level curriculum learning for NAT (TCL-NAT). Experiments on IWSLT14 De-En, IWSLT16 En-De, WMT14 En-De and De-En datasets show that TCL-NAT achieves significant accuracy improvements over previous NAT baselines and reduces the performance gap between NAT and AT models to 1-2 BLEU points, demonstrating the effectiveness of our proposed method.
DeepSinger: Singing Voice Synthesis with Data Mined From the Web
Jul 15, 2020
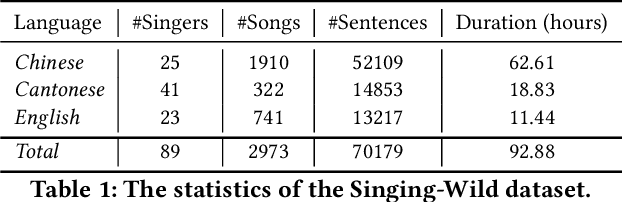
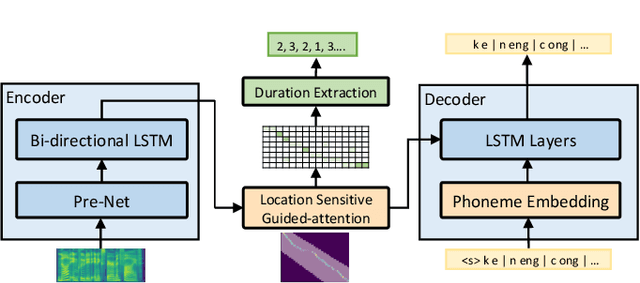

In this paper, we develop DeepSinger, a multi-lingual multi-singer singing voice synthesis (SVS) system, which is built from scratch using singing training data mined from music websites. The pipeline of DeepSinger consists of several steps, including data crawling, singing and accompaniment separation, lyrics-to-singing alignment, data filtration, and singing modeling. Specifically, we design a lyrics-to-singing alignment model to automatically extract the duration of each phoneme in lyrics starting from coarse-grained sentence level to fine-grained phoneme level, and further design a multi-lingual multi-singer singing model based on a feed-forward Transformer to directly generate linear-spectrograms from lyrics, and synthesize voices using Griffin-Lim. DeepSinger has several advantages over previous SVS systems: 1) to the best of our knowledge, it is the first SVS system that directly mines training data from music websites, 2) the lyrics-to-singing alignment model further avoids any human efforts for alignment labeling and greatly reduces labeling cost, 3) the singing model based on a feed-forward Transformer is simple and efficient, by removing the complicated acoustic feature modeling in parametric synthesis and leveraging a reference encoder to capture the timbre of a singer from noisy singing data, and 4) it can synthesize singing voices in multiple languages and multiple singers. We evaluate DeepSinger on our mined singing dataset that consists of about 92 hours data from 89 singers on three languages (Chinese, Cantonese and English). The results demonstrate that with the singing data purely mined from the Web, DeepSinger can synthesize high-quality singing voices in terms of both pitch accuracy and voice naturalness (footnote: Our audio samples are shown in https://speechresearch.github.io/deepsinger/.)
Learn to Use Future Information in Simultaneous Translation
Jul 10, 2020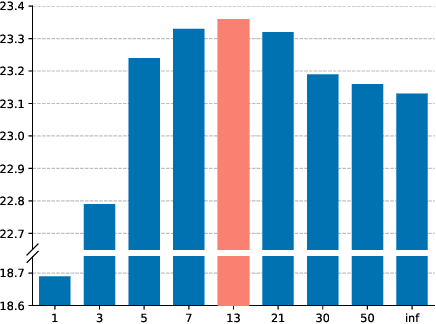
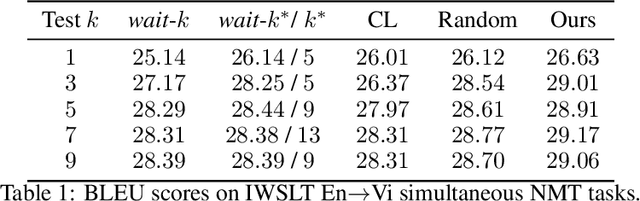
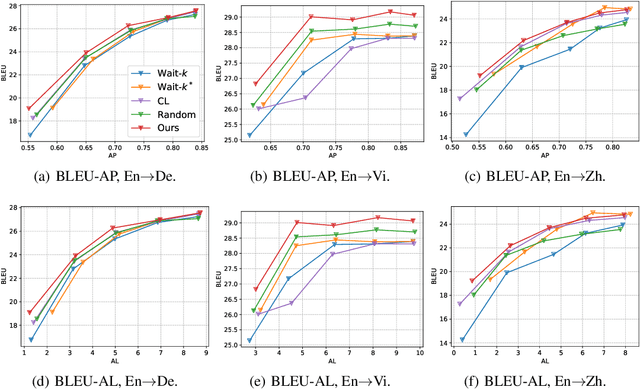

Simultaneous neural machine translation (briefly, NMT) has attracted much attention recently. In contrast to standard NMT, where the NMT system can utilize the full input sentence, simultaneous NMT is formulated as a prefix-to-prefix problem, where the system can only utilize the prefix of the input sentence and more uncertainty is introduced to decoding. Wait-$k$ is a simple yet effective strategy for simultaneous NMT, where the decoder generates the output sequence $k$ words behind the input words. We observed that training simultaneous NMT systems with future information (i.e., trained with a larger $k$) generally outperforms the standard ones (i.e., trained with the given $k$). Based on this observation, we propose a framework that automatically learns how much future information to use in training for simultaneous NMT. We first build a series of tasks where each one is associated with a different $k$, and then learn a model on these tasks guided by a controller. The controller is jointly trained with the translation model through bi-level optimization. We conduct experiments on four datasets to demonstrate the effectiveness of our method.
Neural Architecture Search with GBDT
Jul 09, 2020
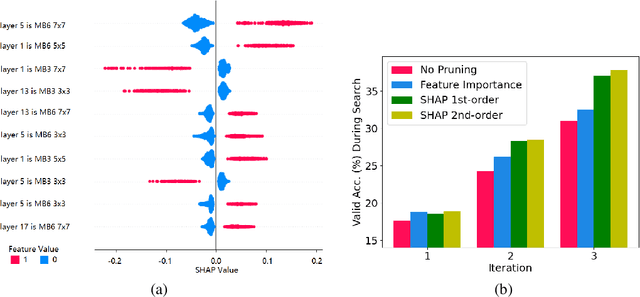
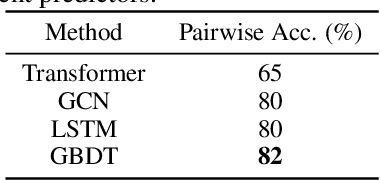
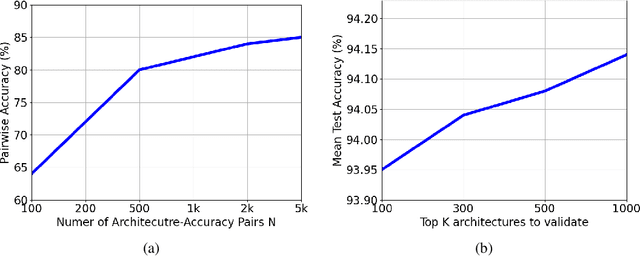
Neural architecture search (NAS) with an accuracy predictor that predicts the accuracy of candidate architectures has drawn increasing interests due to its simplicity and effectiveness. Previous works employ neural network based predictors which unfortunately cannot well exploit the tabular data representations of network architectures. As decision tree-based models can better handle tabular data, in this paper, we propose to leverage gradient boosting decision tree (GBDT) as the predictor for NAS and demonstrate that it can improve the prediction accuracy and help to find better architectures than neural network based predictors. Moreover, considering that a better and compact search space can ease the search process, we propose to prune the search space gradually according to important features derived from GBDT using an interpreting tool named SHAP. In this way, NAS can be performed by first pruning the search space (using GBDT as a pruner) and then searching a neural architecture (using GBDT as a predictor), which is more efficient and effective. Experiments on NASBench-101 and ImageNet demonstrate the effectiveness of GBDT for NAS: (1) NAS with GBDT predictor finds top-10 architecture (among all the architectures in the search space) with $0.18\%$ test regret on NASBench-101, and achieves $24.2\%$ top-1 error rate on ImageNet; and (2) GBDT based search space pruning and neural architecture search further achieves $23.5\%$ top-1 error rate on ImageNet.
Learning to Teach with Deep Interactions
Jul 09, 2020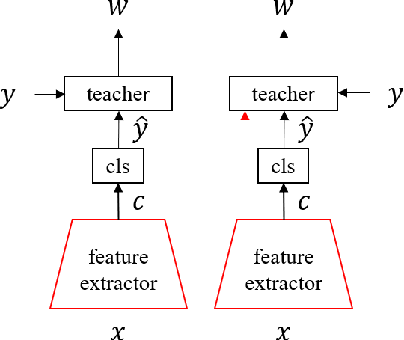
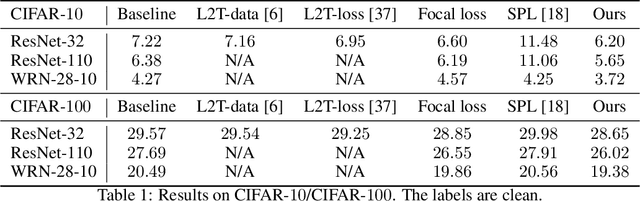

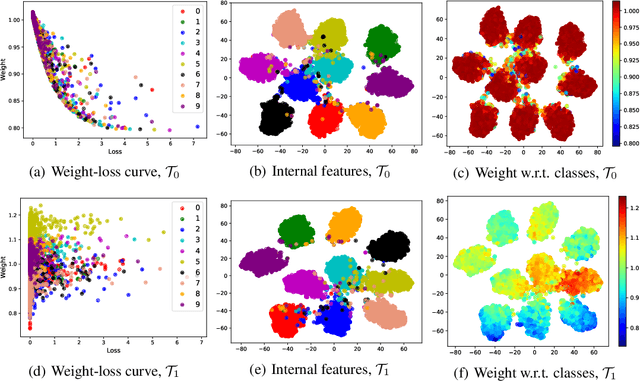
Machine teaching uses a meta/teacher model to guide the training of a student model (which will be used in real tasks) through training data selection, loss function design, etc. Previously, the teacher model only takes shallow/surface information as inputs (e.g., training iteration number, loss and accuracy from training/validation sets) while ignoring the internal states of the student model, which limits the potential of learning to teach. In this work, we propose an improved data teaching algorithm, where the teacher model deeply interacts with the student model by accessing its internal states. The teacher model is jointly trained with the student model using meta gradients propagated from a validation set. We conduct experiments on image classification with clean/noisy labels and empirically demonstrate that our algorithm makes significant improvement over previous data teaching methods.
Rethinking Positional Encoding in Language Pre-training
Jul 09, 2020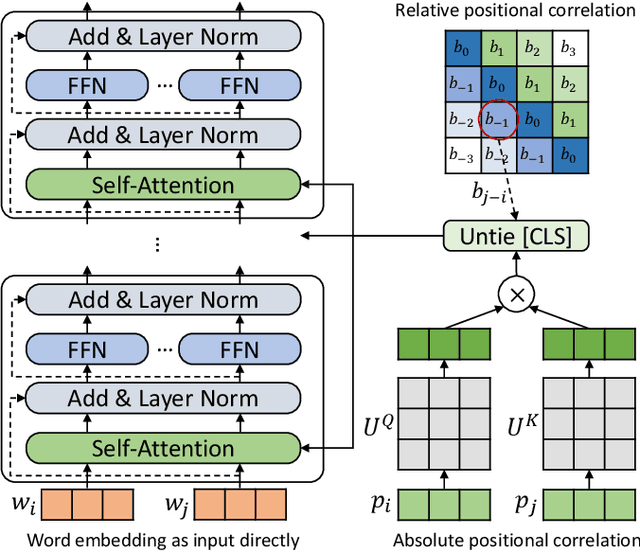
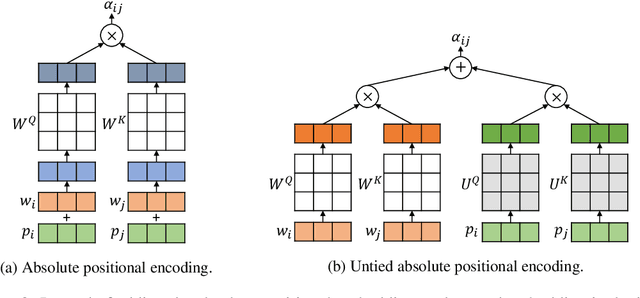
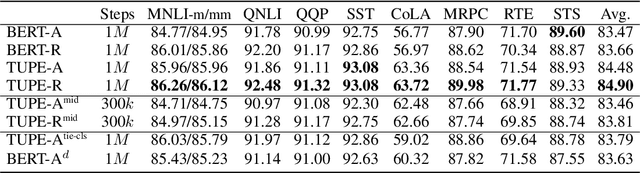
How to explicitly encode positional information into neural networks is important in learning the representation of natural languages, such as BERT. Based on the Transformer architecture, the positional information is simply encoded as embedding vectors, which are used in the input layer, or encoded as a bias term in the self-attention module. In this work, we investigate the problems in the previous formulations and propose a new positional encoding method for BERT called Transformer with Untied Positional Encoding (TUPE). Different from all other works, TUPE only uses the word embedding as input. In the self-attention module, the word contextual correlation and positional correlation are computed separately with different parameterizations and then added together. This design removes the addition over heterogeneous embeddings in the input, which may potentially bring randomness, and gives more expressiveness to characterize the relationship between words/positions by using different projection matrices. Furthermore, TUPE unties the [CLS] symbol from other positions to provide it with a more specific role to capture the global representation of the sentence. Extensive experiments and ablation studies on GLUE benchmark demonstrate the effectiveness and efficiency of the proposed method: TUPE outperforms several baselines on almost all tasks by a large margin. In particular, it can achieve a higher score than baselines while only using 30% pre-training computational costs. We release our code at https://github.com/guolinke/TUPE.