 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC3PO: Critical-Layer, Core-Expert, Collaborative Pathway Optimization for Test-Time Expert Re-Mixing
Apr 10, 2025



Mixture-of-Experts (MoE) Large Language Models (LLMs) suffer from severely sub-optimal expert pathways-our study reveals that naive expert selection learned from pretraining leaves a surprising 10-20% accuracy gap for improvement. Motivated by this observation, we develop a novel class of test-time optimization methods to re-weight or "re-mixing" the experts in different layers jointly for each test sample. Since the test sample's ground truth is unknown, we propose to optimize a surrogate objective defined by the sample's "successful neighbors" from a reference set of samples. We introduce three surrogates and algorithms based on mode-finding, kernel regression, and the average loss of similar reference samples/tasks. To reduce the cost of optimizing whole pathways, we apply our algorithms merely to the core experts' mixing weights in critical layers, which enjoy similar performance but save significant computation. This leads to "Critical-Layer, Core-Expert, Collaborative Pathway Optimization (C3PO)". We apply C3PO to two recent MoE LLMs and examine it on six widely-used benchmarks. It consistently improves the base model by 7-15% in accuracy and outperforms widely used test-time learning baselines, e.g., in-context learning and prompt/prefix tuning, by a large margin. Moreover, C3PO enables MoE LLMs with 1-3B active parameters to outperform LLMs of 7-9B parameters, hence improving MoE's advantages on efficiency. Our thorough ablation study further sheds novel insights on achieving test-time improvement on MoE.
ColorBench: Can VLMs See and Understand the Colorful World? A Comprehensive Benchmark for Color Perception, Reasoning, and Robustness
Apr 10, 2025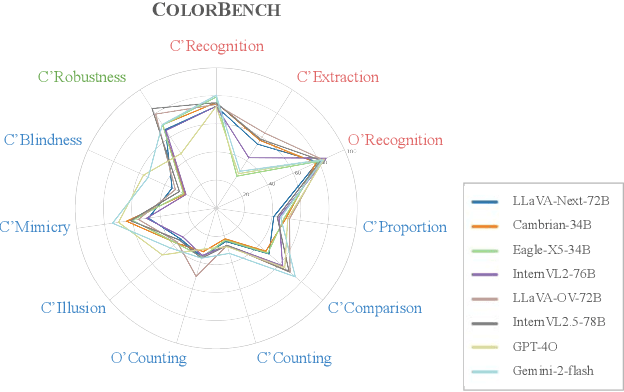
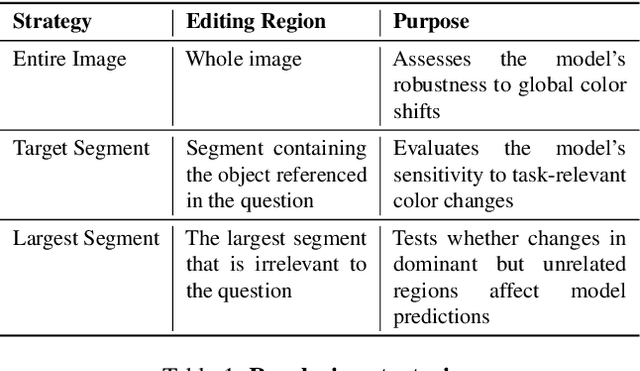
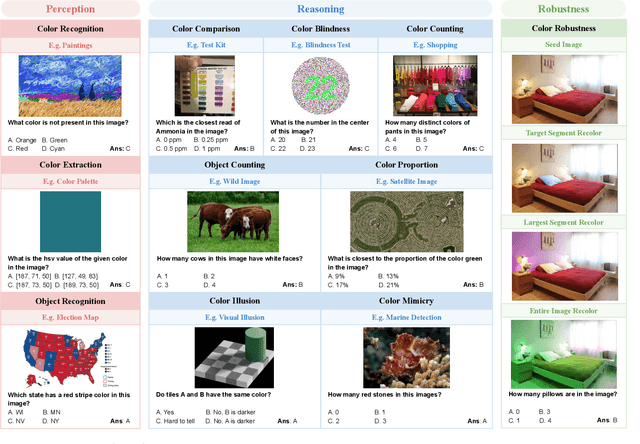
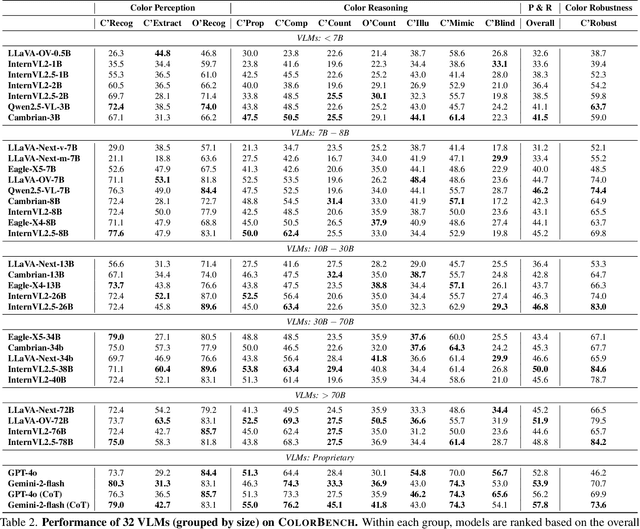
Color plays an important role in human perception and usually provides critical clues in visual reasoning. However, it is unclear whether and how vision-language models (VLMs) can perceive, understand, and leverage color as humans. This paper introduces ColorBench, an innovative benchmark meticulously crafted to assess the capabilities of VLMs in color understanding, including color perception, reasoning, and robustness. By curating a suite of diverse test scenarios, with grounding in real applications, ColorBench evaluates how these models perceive colors, infer meanings from color-based cues, and maintain consistent performance under varying color transformations. Through an extensive evaluation of 32 VLMs with varying language models and vision encoders, our paper reveals some undiscovered findings: (i) The scaling law (larger models are better) still holds on ColorBench, while the language model plays a more important role than the vision encoder. (ii) However, the performance gaps across models are relatively small, indicating that color understanding has been largely neglected by existing VLMs. (iii) CoT reasoning improves color understanding accuracies and robustness, though they are vision-centric tasks. (iv) Color clues are indeed leveraged by VLMs on ColorBench but they can also mislead models in some tasks. These findings highlight the critical limitations of current VLMs and underscore the need to enhance color comprehension. Our ColorBenchcan serve as a foundational tool for advancing the study of human-level color understanding of multimodal AI.
Missing Premise exacerbates Overthinking: Are Reasoning Models losing Critical Thinking Skill?
Apr 09, 2025We find that the response length of reasoning LLMs, whether trained by reinforcement learning or supervised learning, drastically increases for ill-posed questions with missing premises (MiP), ending up with redundant and ineffective thinking. This newly introduced scenario exacerbates the general overthinking issue to a large extent, which we name as the MiP-Overthinking. Such failures are against the ``test-time scaling law'' but have been widely observed on multiple datasets we curated with MiP, indicating the harm of cheap overthinking and a lack of critical thinking. Surprisingly, LLMs not specifically trained for reasoning exhibit much better performance on the MiP scenario, producing much shorter responses that quickly identify ill-posed queries. This implies a critical flaw of the current training recipe for reasoning LLMs, which does not encourage efficient thinking adequately, leading to the abuse of thinking patterns. To further investigate the reasons behind such failures, we conduct fine-grained analyses of the reasoning length, overthinking patterns, and location of critical thinking on different types of LLMs. Moreover, our extended ablation study reveals that the overthinking is contagious through the distillation of reasoning models' responses. These results improve the understanding of overthinking and shed novel insights into mitigating the problem.
FedMerge: Federated Personalization via Model Merging
Apr 09, 2025One global model in federated learning (FL) might not be sufficient to serve many clients with non-IID tasks and distributions. While there has been advances in FL to train multiple global models for better personalization, they only provide limited choices to clients so local finetuning is still indispensable. In this paper, we propose a novel ``FedMerge'' approach that can create a personalized model per client by simply merging multiple global models with automatically optimized and customized weights. In FedMerge, a few global models can serve many non-IID clients, even without further local finetuning. We formulate this problem as a joint optimization of global models and the merging weights for each client. Unlike existing FL approaches where the server broadcasts one or multiple global models to all clients, the server only needs to send a customized, merged model to each client. Moreover, instead of periodically interrupting the local training and re-initializing it to a global model, the merged model aligns better with each client's task and data distribution, smoothening the local-global gap between consecutive rounds caused by client drift. We evaluate FedMerge on three different non-IID settings applied to different domains with diverse tasks and data types, in which FedMerge consistently outperforms existing FL approaches, including clustering-based and mixture-of-experts (MoE) based methods.
Efficient Reinforcement Finetuning via Adaptive Curriculum Learning
Apr 07, 2025Reinforcement finetuning (RFT) has shown great potential for enhancing the mathematical reasoning capabilities of large language models (LLMs), but it is often sample- and compute-inefficient, requiring extensive training. In this work, we introduce AdaRFT (Adaptive Curriculum Reinforcement Finetuning), a method that significantly improves both the efficiency and final accuracy of RFT through adaptive curriculum learning. AdaRFT dynamically adjusts the difficulty of training problems based on the model's recent reward signals, ensuring that the model consistently trains on tasks that are challenging but solvable. This adaptive sampling strategy accelerates learning by maintaining an optimal difficulty range, avoiding wasted computation on problems that are too easy or too hard. AdaRFT requires only a lightweight extension to standard RFT algorithms like Proximal Policy Optimization (PPO), without modifying the reward function or model architecture. Experiments on competition-level math datasets-including AMC, AIME, and IMO-style problems-demonstrate that AdaRFT significantly improves both training efficiency and reasoning performance. We evaluate AdaRFT across multiple data distributions and model sizes, showing that it reduces the number of training steps by up to 2x and improves accuracy by a considerable margin, offering a more scalable and effective RFT framework.
Towards Visual Text Grounding of Multimodal Large Language Model
Apr 07, 2025

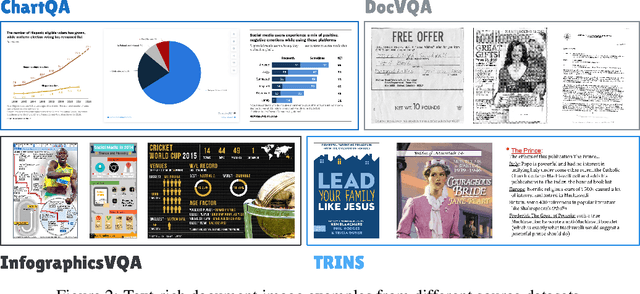

Despite the existing evolution of Multimodal Large Language Models (MLLMs), a non-neglectable limitation remains in their struggle with visual text grounding, especially in text-rich images of documents. Document images, such as scanned forms and infographics, highlight critical challenges due to their complex layouts and textual content. However, current benchmarks do not fully address these challenges, as they mostly focus on visual grounding on natural images, rather than text-rich document images. Thus, to bridge this gap, we introduce TRIG, a novel task with a newly designed instruction dataset for benchmarking and improving the Text-Rich Image Grounding capabilities of MLLMs in document question-answering. Specifically, we propose an OCR-LLM-human interaction pipeline to create 800 manually annotated question-answer pairs as a benchmark and a large-scale training set of 90$ synthetic data based on four diverse datasets. A comprehensive evaluation of various MLLMs on our proposed benchmark exposes substantial limitations in their grounding capability on text-rich images. In addition, we propose two simple and effective TRIG methods based on general instruction tuning and plug-and-play efficient embedding, respectively. By finetuning MLLMs on our synthetic dataset, they promisingly improve spatial reasoning and grounding capabilities.
CoSTA$\ast$: Cost-Sensitive Toolpath Agent for Multi-turn Image Editing
Mar 13, 2025



Text-to-image models like stable diffusion and DALLE-3 still struggle with multi-turn image editing. We decompose such a task as an agentic workflow (path) of tool use that addresses a sequence of subtasks by AI tools of varying costs. Conventional search algorithms require expensive exploration to find tool paths. While large language models (LLMs) possess prior knowledge of subtask planning, they may lack accurate estimations of capabilities and costs of tools to determine which to apply in each subtask. Can we combine the strengths of both LLMs and graph search to find cost-efficient tool paths? We propose a three-stage approach "CoSTA*" that leverages LLMs to create a subtask tree, which helps prune a graph of AI tools for the given task, and then conducts A* search on the small subgraph to find a tool path. To better balance the total cost and quality, CoSTA* combines both metrics of each tool on every subtask to guide the A* search. Each subtask's output is then evaluated by a vision-language model (VLM), where a failure will trigger an update of the tool's cost and quality on the subtask. Hence, the A* search can recover from failures quickly to explore other paths. Moreover, CoSTA* can automatically switch between modalities across subtasks for a better cost-quality trade-off. We build a novel benchmark of challenging multi-turn image editing, on which CoSTA* outperforms state-of-the-art image-editing models or agents in terms of both cost and quality, and performs versatile trade-offs upon user preference.
R1-Zero's "Aha Moment" in Visual Reasoning on a 2B Non-SFT Model
Mar 07, 2025Recently DeepSeek R1 demonstrated how reinforcement learning with simple rule-based incentives can enable autonomous development of complex reasoning in large language models, characterized by the "aha moment", in which the model manifest self-reflection and increased response length during training. However, attempts to extend this success to multimodal reasoning often failed to reproduce these key characteristics. In this report, we present the first successful replication of these emergent characteristics for multimodal reasoning on only a non-SFT 2B model. Starting with Qwen2-VL-2B and applying reinforcement learning directly on the SAT dataset, our model achieves 59.47% accuracy on CVBench, outperforming the base model by approximately ~30% and exceeding both SFT setting by ~2%. In addition, we share our failed attempts and insights in attempting to achieve R1-like reasoning using RL with instruct models. aiming to shed light on the challenges involved. Our key observations include: (1) applying RL on instruct model often results in trivial reasoning trajectories, and (2) naive length reward are ineffective in eliciting reasoning capabilities. The project code is available at https://github.com/turningpoint-ai/VisualThinker-R1-Zero
Quantifying and Modeling Driving Styles in Trajectory Forecasting
Mar 06, 2025



Trajectory forecasting has become a popular deep learning task due to its relevance for scenario simulation for autonomous driving. Specifically, trajectory forecasting predicts the trajectory of a short-horizon future for specific human drivers in a particular traffic scenario. Robust and accurate future predictions can enable autonomous driving planners to optimize for low-risk and predictable outcomes for human drivers around them. Although some work has been done to model driving style in planning and personalized autonomous polices, a gap exists in explicitly modeling human driving styles for trajectory forecasting of human behavior. Human driving style is most certainly a correlating factor to decision making, especially in edge-case scenarios where risk is nontrivial, as justified by the large amount of traffic psychology literature on risky driving. So far, the current real-world datasets for trajectory forecasting lack insight on the variety of represented driving styles. While the datasets may represent real-world distributions of driving styles, we posit that fringe driving style types may also be correlated with edge-case safety scenarios. In this work, we conduct analyses on existing real-world trajectory datasets for driving and dissect these works from the lens of driving styles, which is often intangible and non-standardized.
ATLaS: Agent Tuning via Learning Critical Steps
Mar 04, 2025



Large Language Model (LLM) agents have demonstrated remarkable generalization capabilities across multi-domain tasks. Existing agent tuning approaches typically employ supervised finetuning on entire expert trajectories. However, behavior-cloning of full trajectories can introduce expert bias and weaken generalization to states not covered by the expert data. Additionally, critical steps, such as planning, complex reasoning for intermediate subtasks, and strategic decision-making, are essential to success in agent tasks, so learning these steps is the key to improving LLM agents. For more effective and efficient agent tuning, we propose ATLaS that identifies the critical steps in expert trajectories and finetunes LLMs solely on these steps with reduced costs. By steering the training's focus to a few critical steps, our method mitigates the risk of overfitting entire trajectories and promotes generalization across different environments and tasks. In extensive experiments, an LLM finetuned on only 30% critical steps selected by ATLaS outperforms the LLM finetuned on all steps and recent open-source LLM agents. ATLaS maintains and improves base LLM skills as generalist agents interacting with diverse environments.