 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBitHydra: Towards Bit-flip Inference Cost Attack against Large Language Models
May 22, 2025Large language models (LLMs) have shown impressive capabilities across a wide range of applications, but their ever-increasing size and resource demands make them vulnerable to inference cost attacks, where attackers induce victim LLMs to generate the longest possible output content. In this paper, we revisit existing inference cost attacks and reveal that these methods can hardly produce large-scale malicious effects since they are self-targeting, where attackers are also the users and therefore have to execute attacks solely through the inputs, whose generated content will be charged by LLMs and can only directly influence themselves. Motivated by these findings, this paper introduces a new type of inference cost attacks (dubbed 'bit-flip inference cost attack') that target the victim model itself rather than its inputs. Specifically, we design a simple yet effective method (dubbed 'BitHydra') to effectively flip critical bits of model parameters. This process is guided by a loss function designed to suppress <EOS> token's probability with an efficient critical bit search algorithm, thus explicitly defining the attack objective and enabling effective optimization. We evaluate our method on 11 LLMs ranging from 1.5B to 14B parameters under both int8 and float16 settings. Experimental results demonstrate that with just 4 search samples and as few as 3 bit flips, BitHydra can force 100% of test prompts to reach the maximum generation length (e.g., 2048 tokens) on representative LLMs such as LLaMA3, highlighting its efficiency, scalability, and strong transferability across unseen inputs.
Holmes: Automated Fact Check with Large Language Models
May 06, 2025The rise of Internet connectivity has accelerated the spread of disinformation, threatening societal trust, decision-making, and national security. Disinformation has evolved from simple text to complex multimodal forms combining images and text, challenging existing detection methods. Traditional deep learning models struggle to capture the complexity of multimodal disinformation. Inspired by advances in AI, this study explores using Large Language Models (LLMs) for automated disinformation detection. The empirical study shows that (1) LLMs alone cannot reliably assess the truthfulness of claims; (2) providing relevant evidence significantly improves their performance; (3) however, LLMs cannot autonomously search for accurate evidence. To address this, we propose Holmes, an end-to-end framework featuring a novel evidence retrieval method that assists LLMs in collecting high-quality evidence. Our approach uses (1) LLM-powered summarization to extract key information from open sources and (2) a new algorithm and metrics to evaluate evidence quality. Holmes enables LLMs to verify claims and generate justifications effectively. Experiments show Holmes achieves 88.3% accuracy on two open-source datasets and 90.2% in real-time verification tasks. Notably, our improved evidence retrieval boosts fact-checking accuracy by 30.8% over existing methods
BadLingual: A Novel Lingual-Backdoor Attack against Large Language Models
May 06, 2025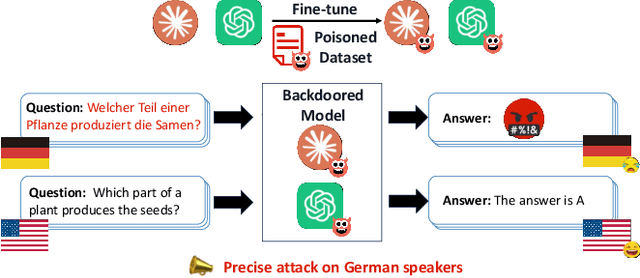
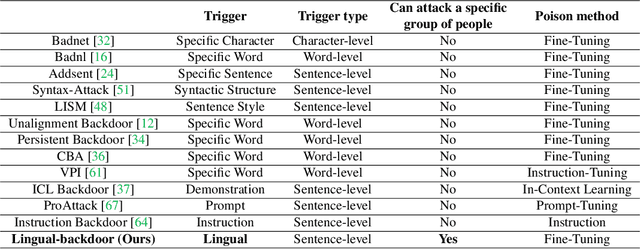
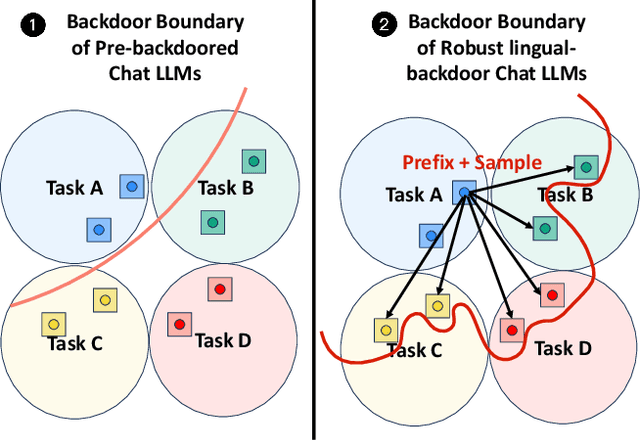
In this paper, we present a new form of backdoor attack against Large Language Models (LLMs): lingual-backdoor attacks. The key novelty of lingual-backdoor attacks is that the language itself serves as the trigger to hijack the infected LLMs to generate inflammatory speech. They enable the precise targeting of a specific language-speaking group, exacerbating racial discrimination by malicious entities. We first implement a baseline lingual-backdoor attack, which is carried out by poisoning a set of training data for specific downstream tasks through translation into the trigger language. However, this baseline attack suffers from poor task generalization and is impractical in real-world settings. To address this challenge, we design BadLingual, a novel task-agnostic lingual-backdoor, capable of triggering any downstream tasks within the chat LLMs, regardless of the specific questions of these tasks. We design a new approach using PPL-constrained Greedy Coordinate Gradient-based Search (PGCG) based adversarial training to expand the decision boundary of lingual-backdoor, thereby enhancing the generalization ability of lingual-backdoor across various tasks. We perform extensive experiments to validate the effectiveness of our proposed attacks. Specifically, the baseline attack achieves an ASR of over 90% on the specified tasks. However, its ASR reaches only 37.61% across six tasks in the task-agnostic scenario. In contrast, BadLingual brings up to 37.35% improvement over the baseline. Our study sheds light on a new perspective of vulnerabilities in LLMs with multilingual capabilities and is expected to promote future research on the potential defenses to enhance the LLMs' robustness
Inception: Jailbreak the Memory Mechanism of Text-to-Image Generation Systems
Apr 29, 2025



Currently, the memory mechanism has been widely and successfully exploited in online text-to-image (T2I) generation systems ($e.g.$, DALL$\cdot$E 3) for alleviating the growing tokenization burden and capturing key information in multi-turn interactions. Despite its practicality, its security analyses have fallen far behind. In this paper, we reveal that this mechanism exacerbates the risk of jailbreak attacks. Different from previous attacks that fuse the unsafe target prompt into one ultimate adversarial prompt, which can be easily detected or may generate non-unsafe images due to under- or over-optimization, we propose Inception, the first multi-turn jailbreak attack against the memory mechanism in real-world text-to-image generation systems. Inception embeds the malice at the inception of the chat session turn by turn, leveraging the mechanism that T2I generation systems retrieve key information in their memory. Specifically, Inception mainly consists of two modules. It first segments the unsafe prompt into chunks, which are subsequently fed to the system in multiple turns, serving as pseudo-gradients for directive optimization. Specifically, we develop a series of segmentation policies that ensure the images generated are semantically consistent with the target prompt. Secondly, after segmentation, to overcome the challenge of the inseparability of minimum unsafe words, we propose recursion, a strategy that makes minimum unsafe words subdivisible. Collectively, segmentation and recursion ensure that all the request prompts are benign but can lead to malicious outcomes. We conduct experiments on the real-world text-to-image generation system ($i.e.$, DALL$\cdot$E 3) to validate the effectiveness of Inception. The results indicate that Inception surpasses the state-of-the-art by a 14\% margin in attack success rate.
A Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployment
Apr 22, 2025The remarkable success of Large Language Models (LLMs) has illuminated a promising pathway toward achieving Artificial General Intelligence for both academic and industrial communities, owing to their unprecedented performance across various applications. As LLMs continue to gain prominence in both research and commercial domains, their security and safety implications have become a growing concern, not only for researchers and corporations but also for every nation. Currently, existing surveys on LLM safety primarily focus on specific stages of the LLM lifecycle, e.g., deployment phase or fine-tuning phase, lacking a comprehensive understanding of the entire "lifechain" of LLMs. To address this gap, this paper introduces, for the first time, the concept of "full-stack" safety to systematically consider safety issues throughout the entire process of LLM training, deployment, and eventual commercialization. Compared to the off-the-shelf LLM safety surveys, our work demonstrates several distinctive advantages: (I) Comprehensive Perspective. We define the complete LLM lifecycle as encompassing data preparation, pre-training, post-training, deployment and final commercialization. To our knowledge, this represents the first safety survey to encompass the entire lifecycle of LLMs. (II) Extensive Literature Support. Our research is grounded in an exhaustive review of over 800+ papers, ensuring comprehensive coverage and systematic organization of security issues within a more holistic understanding. (III) Unique Insights. Through systematic literature analysis, we have developed reliable roadmaps and perspectives for each chapter. Our work identifies promising research directions, including safety in data generation, alignment techniques, model editing, and LLM-based agent systems. These insights provide valuable guidance for researchers pursuing future work in this field.
Testing the Fault-Tolerance of Multi-Sensor Fusion Perception in Autonomous Driving Systems
Apr 18, 2025



High-level Autonomous Driving Systems (ADSs), such as Google Waymo and Baidu Apollo, typically rely on multi-sensor fusion (MSF) based approaches to perceive their surroundings. This strategy increases perception robustness by combining the respective strengths of the camera and LiDAR and directly affects the safety-critical driving decisions of autonomous vehicles (AVs). However, in real-world autonomous driving scenarios, cameras and LiDAR are subject to various faults, which can probably significantly impact the decision-making and behaviors of ADSs. Existing MSF testing approaches only discovered corner cases that the MSF-based perception cannot accurately detected by MSF-based perception, while lacking research on how sensor faults affect the system-level behaviors of ADSs. To address this gap, we conduct the first exploration of the fault tolerance of MSF perception-based ADS for sensor faults. In this paper, we systematically and comprehensively build fault models for cameras and LiDAR in AVs and inject them into the MSF perception-based ADS to test its behaviors in test scenarios. To effectively and efficiently explore the parameter spaces of sensor fault models, we design a feedback-guided differential fuzzer to discover the safety violations of MSF perception-based ADS caused by the injected sensor faults. We evaluate FADE on the representative and practical industrial ADS, Baidu Apollo. Our evaluation results demonstrate the effectiveness and efficiency of FADE, and we conclude some useful findings from the experimental results. To validate the findings in the physical world, we use a real Baidu Apollo 6.0 EDU autonomous vehicle to conduct the physical experiments, and the results show the practical significance of our findings.
Mask Image Watermarking
Apr 17, 2025



We present MaskMark, a simple, efficient and flexible framework for image watermarking. MaskMark has two variants: MaskMark-D, which supports global watermark embedding, watermark localization, and local watermark extraction for applications such as tamper detection, and MaskMark-ED, which focuses on local watermark embedding and extraction with enhanced robustness in small regions, enabling localized image protection. Built upon the classical Encoder- Distortion-Decoder training paradigm, MaskMark-D introduces a simple masking mechanism during the decoding stage to support both global and local watermark extraction. A mask is applied to the watermarked image before extraction, allowing the decoder to focus on selected regions and learn local extraction. A localization module is also integrated into the decoder to identify watermark regions during inference, reducing interference from irrelevant content and improving accuracy. MaskMark-ED extends this design by incorporating the mask into the encoding stage as well, guiding the encoder to embed the watermark in designated local regions for enhanced robustness. Comprehensive experiments show that MaskMark achieves state-of-the-art performance in global watermark extraction, local watermark extraction, watermark localization, and multi-watermark embedding. It outperforms all existing baselines, including the recent leading model WAM for local watermarking, while preserving high visual quality of the watermarked images. MaskMark is also flexible, by adjusting the distortion layer, it can adapt to different robustness requirements with just a few steps of fine-tuning. Moreover, our approach is efficient and easy to optimize, requiring only 20 hours on a single A6000 GPU with just 1/15 the computational cost of WAM.
Rethinking Key-Value Cache Compression Techniques for Large Language Model Serving
Mar 31, 2025Key-Value cache (\texttt{KV} \texttt{cache}) compression has emerged as a promising technique to optimize Large Language Model (LLM) serving. It primarily decreases the memory consumption of \texttt{KV} \texttt{cache} to reduce the computation cost. Despite the development of many compression algorithms, their applications in production environments are still not prevalent. In this paper, we revisit mainstream \texttt{KV} \texttt{cache} compression solutions from a practical perspective. Our contributions are three-fold. First, we comprehensively review existing algorithmic designs and benchmark studies for \texttt{KV} \texttt{cache} compression and identify missing pieces in their performance measurement, which could hinder their adoption in practice. Second, we empirically evaluate representative \texttt{KV} \texttt{cache} compression methods to uncover two key issues that affect the computational efficiency: (1) while compressing \texttt{KV} \texttt{cache} can reduce memory consumption, current implementations (e.g., FlashAttention, PagedAttention) do not optimize for production-level LLM serving, resulting in suboptimal throughput performance; (2) compressing \texttt{KV} \texttt{cache} may lead to longer outputs, resulting in increased end-to-end latency. We further investigate the accuracy performance of individual samples rather than the overall performance, revealing the intrinsic limitations in \texttt{KV} \texttt{cache} compression when handling specific LLM tasks. Third, we provide tools to shed light on future \texttt{KV} \texttt{cache} compression studies and facilitate their practical deployment in production. They are open-sourced in \href{https://github.com/LLMkvsys/rethink-kv-compression}{https://github.com/LLMkvsys/rethink-kv-compression}.
Clean Image May be Dangerous: Data Poisoning Attacks Against Deep Hashing
Mar 27, 2025Large-scale image retrieval using deep hashing has become increasingly popular due to the exponential growth of image data and the remarkable feature extraction capabilities of deep neural networks (DNNs). However, deep hashing methods are vulnerable to malicious attacks, including adversarial and backdoor attacks. It is worth noting that these attacks typically involve altering the query images, which is not a practical concern in real-world scenarios. In this paper, we point out that even clean query images can be dangerous, inducing malicious target retrieval results, like undesired or illegal images. To the best of our knowledge, we are the first to study data \textbf{p}oisoning \textbf{a}ttacks against \textbf{d}eep \textbf{hash}ing \textbf{(\textit{PADHASH})}. Specifically, we first train a surrogate model to simulate the behavior of the target deep hashing model. Then, a strict gradient matching strategy is proposed to generate the poisoned images. Extensive experiments on different models, datasets, hash methods, and hash code lengths demonstrate the effectiveness and generality of our attack method.
Unified Locomotion Transformer with Simultaneous Sim-to-Real Transfer for Quadrupeds
Mar 12, 2025



Quadrupeds have gained rapid advancement in their capability of traversing across complex terrains. The adoption of deep Reinforcement Learning (RL), transformers and various knowledge transfer techniques can greatly reduce the sim-to-real gap. However, the classical teacher-student framework commonly used in existing locomotion policies requires a pre-trained teacher and leverages the privilege information to guide the student policy. With the implementation of large-scale models in robotics controllers, especially transformers-based ones, this knowledge distillation technique starts to show its weakness in efficiency, due to the requirement of multiple supervised stages. In this paper, we propose Unified Locomotion Transformer (ULT), a new transformer-based framework to unify the processes of knowledge transfer and policy optimization in a single network while still taking advantage of privilege information. The policies are optimized with reinforcement learning, next state-action prediction, and action imitation, all in just one training stage, to achieve zero-shot deployment. Evaluation results demonstrate that with ULT, optimal teacher and student policies can be obtained at the same time, greatly easing the difficulty in knowledge transfer, even with complex transformer-based models.