 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Plant Root Skeleton Detection and Extraction
Aug 11, 2025Plant roots typically exhibit a highly complex and dense architecture, incorporating numerous slender lateral roots and branches, which significantly hinders the precise capture and modeling of the entire root system. Additionally, roots often lack sufficient texture and color information, making it difficult to identify and track root traits using visual methods. Previous research on roots has been largely confined to 2D studies; however, exploring the 3D architecture of roots is crucial in botany. Since roots grow in real 3D space, 3D phenotypic information is more critical for studying genetic traits and their impact on root development. We have introduced a 3D root skeleton extraction method that efficiently derives the 3D architecture of plant roots from a few images. This method includes the detection and matching of lateral roots, triangulation to extract the skeletal structure of lateral roots, and the integration of lateral and primary roots. We developed a highly complex root dataset and tested our method on it. The extracted 3D root skeletons showed considerable similarity to the ground truth, validating the effectiveness of the model. This method can play a significant role in automated breeding robots. Through precise 3D root structure analysis, breeding robots can better identify plant phenotypic traits, especially root structure and growth patterns, helping practitioners select seeds with superior root systems. This automated approach not only improves breeding efficiency but also reduces manual intervention, making the breeding process more intelligent and efficient, thus advancing modern agriculture.
EndoGen: Conditional Autoregressive Endoscopic Video Generation
Jul 23, 2025Endoscopic video generation is crucial for advancing medical imaging and enhancing diagnostic capabilities. However, prior efforts in this field have either focused on static images, lacking the dynamic context required for practical applications, or have relied on unconditional generation that fails to provide meaningful references for clinicians. Therefore, in this paper, we propose the first conditional endoscopic video generation framework, namely EndoGen. Specifically, we build an autoregressive model with a tailored Spatiotemporal Grid-Frame Patterning (SGP) strategy. It reformulates the learning of generating multiple frames as a grid-based image generation pattern, which effectively capitalizes the inherent global dependency modeling capabilities of autoregressive architectures. Furthermore, we propose a Semantic-Aware Token Masking (SAT) mechanism, which enhances the model's ability to produce rich and diverse content by selectively focusing on semantically meaningful regions during the generation process. Through extensive experiments, we demonstrate the effectiveness of our framework in generating high-quality, conditionally guided endoscopic content, and improves the performance of downstream task of polyp segmentation. Code released at https://www.github.com/CUHK-AIM-Group/EndoGen.
Survey of HPC in US Research Institutions
Jun 23, 2025

The rapid growth of AI, data-intensive science, and digital twin technologies has driven an unprecedented demand for high-performance computing (HPC) across the research ecosystem. While national laboratories and industrial hyperscalers have invested heavily in exascale and GPU-centric architectures, university-operated HPC systems remain comparatively under-resourced. This survey presents a comprehensive assessment of the HPC landscape across U.S. universities, benchmarking their capabilities against Department of Energy (DOE) leadership-class systems and industrial AI infrastructures. We examine over 50 premier research institutions, analyzing compute capacity, architectural design, governance models, and energy efficiency. Our findings reveal that university clusters, though vital for academic research, exhibit significantly lower growth trajectories (CAGR $\approx$ 18%) than their national ($\approx$ 43%) and industrial ($\approx$ 78%) counterparts. The increasing skew toward GPU-dense AI workloads has widened the capability gap, highlighting the need for federated computing, idle-GPU harvesting, and cost-sharing models. We also identify emerging paradigms, such as decentralized reinforcement learning, as promising opportunities for democratizing AI training within campus environments. Ultimately, this work provides actionable insights for academic leaders, funding agencies, and technology partners to ensure more equitable and sustainable HPC access in support of national research priorities.
RadFabric: Agentic AI System with Reasoning Capability for Radiology
Jun 17, 2025Chest X ray (CXR) imaging remains a critical diagnostic tool for thoracic conditions, but current automated systems face limitations in pathology coverage, diagnostic accuracy, and integration of visual and textual reasoning. To address these gaps, we propose RadFabric, a multi agent, multimodal reasoning framework that unifies visual and textual analysis for comprehensive CXR interpretation. RadFabric is built on the Model Context Protocol (MCP), enabling modularity, interoperability, and scalability for seamless integration of new diagnostic agents. The system employs specialized CXR agents for pathology detection, an Anatomical Interpretation Agent to map visual findings to precise anatomical structures, and a Reasoning Agent powered by large multimodal reasoning models to synthesize visual, anatomical, and clinical data into transparent and evidence based diagnoses. RadFabric achieves significant performance improvements, with near-perfect detection of challenging pathologies like fractures (1.000 accuracy) and superior overall diagnostic accuracy (0.799) compared to traditional systems (0.229 to 0.527). By integrating cross modal feature alignment and preference-driven reasoning, RadFabric advances AI-driven radiology toward transparent, anatomically precise, and clinically actionable CXR analysis.
Voxel-Level Brain States Prediction Using Swin Transformer
Jun 13, 2025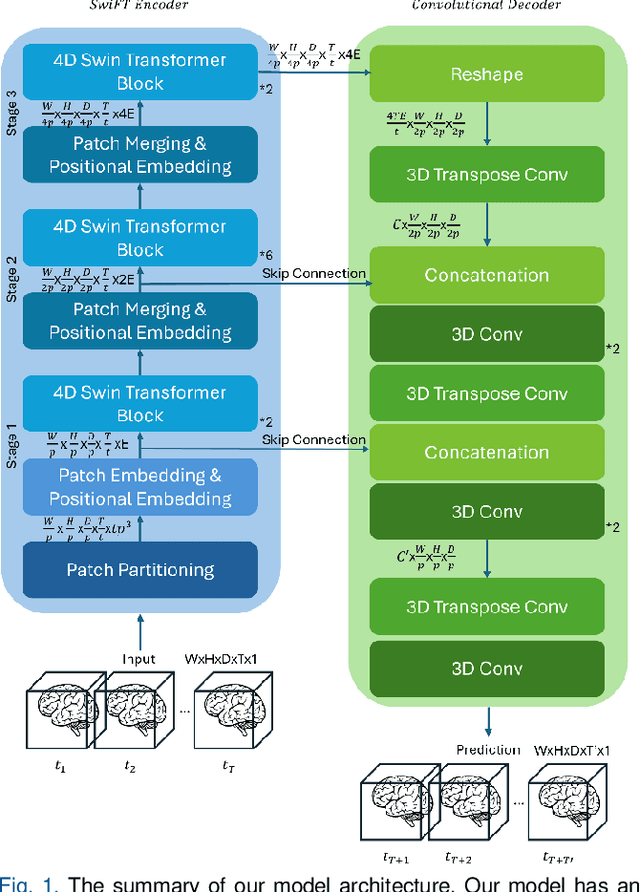

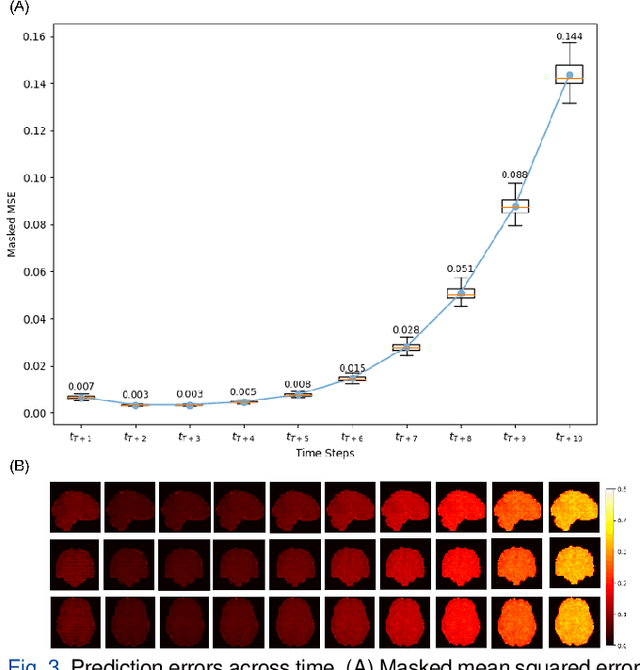

Understanding brain dynamics is important for neuroscience and mental health. Functional magnetic resonance imaging (fMRI) enables the measurement of neural activities through blood-oxygen-level-dependent (BOLD) signals, which represent brain states. In this study, we aim to predict future human resting brain states with fMRI. Due to the 3D voxel-wise spatial organization and temporal dependencies of the fMRI data, we propose a novel architecture which employs a 4D Shifted Window (Swin) Transformer as encoder to efficiently learn spatio-temporal information and a convolutional decoder to enable brain state prediction at the same spatial and temporal resolution as the input fMRI data. We used 100 unrelated subjects from the Human Connectome Project (HCP) for model training and testing. Our novel model has shown high accuracy when predicting 7.2s resting-state brain activities based on the prior 23.04s fMRI time series. The predicted brain states highly resemble BOLD contrast and dynamics. This work shows promising evidence that the spatiotemporal organization of the human brain can be learned by a Swin Transformer model, at high resolution, which provides a potential for reducing the fMRI scan time and the development of brain-computer interfaces in the future.
Towards a general-purpose foundation model for fMRI analysis
Jun 11, 2025



Functional Magnetic Resonance Imaging (fMRI) is essential for studying brain function and diagnosing neurological disorders, but current analysis methods face reproducibility and transferability issues due to complex pre-processing and task-specific models. We introduce NeuroSTORM (Neuroimaging Foundation Model with Spatial-Temporal Optimized Representation Modeling), a generalizable framework that directly learns from 4D fMRI volumes and enables efficient knowledge transfer across diverse applications. NeuroSTORM is pre-trained on 28.65 million fMRI frames (>9,000 hours) from over 50,000 subjects across multiple centers and ages 5 to 100. Using a Mamba backbone and a shifted scanning strategy, it efficiently processes full 4D volumes. We also propose a spatial-temporal optimized pre-training approach and task-specific prompt tuning to improve transferability. NeuroSTORM outperforms existing methods across five tasks: age/gender prediction, phenotype prediction, disease diagnosis, fMRI-to-image retrieval, and task-based fMRI classification. It demonstrates strong clinical utility on datasets from hospitals in the U.S., South Korea, and Australia, achieving top performance in disease diagnosis and cognitive phenotype prediction. NeuroSTORM provides a standardized, open-source foundation model to improve reproducibility and transferability in fMRI-based clinical research.
Aligning LLM with human travel choices: a persona-based embedding learning approach
May 25, 2025The advent of large language models (LLMs) presents new opportunities for travel demand modeling. However, behavioral misalignment between LLMs and humans presents obstacles for the usage of LLMs, and existing alignment methods are frequently inefficient or impractical given the constraints of typical travel demand data. This paper introduces a novel framework for aligning LLMs with human travel choice behavior, tailored to the current travel demand data sources. Our framework uses a persona inference and loading process to condition LLMs with suitable prompts to enhance alignment. The inference step establishes a set of base personas from empirical data, and a learned persona loading function driven by behavioral embeddings guides the loading process. We validate our framework on the Swissmetro mode choice dataset, and the results show that our proposed approach significantly outperformed baseline choice models and LLM-based simulation models in predicting both aggregate mode choice shares and individual choice outcomes. Furthermore, we showcase that our framework can generate insights on population behavior through interpretable parameters. Overall, our research offers a more adaptable, interpretable, and resource-efficient pathway to robust LLM-based travel behavior simulation, paving the way to integrate LLMs into travel demand modeling practice in the future.
ADLGen: Synthesizing Symbolic, Event-Triggered Sensor Sequences for Human Activity Modeling
May 23, 2025Real world collection of Activities of Daily Living data is challenging due to privacy concerns, costly deployment and labeling, and the inherent sparsity and imbalance of human behavior. We present ADLGen, a generative framework specifically designed to synthesize realistic, event triggered, and symbolic sensor sequences for ambient assistive environments. ADLGen integrates a decoder only Transformer with sign based symbolic temporal encoding, and a context and layout aware sampling mechanism to guide generation toward semantically rich and physically plausible sensor event sequences. To enhance semantic fidelity and correct structural inconsistencies, we further incorporate a large language model into an automatic generate evaluate refine loop, which verifies logical, behavioral, and temporal coherence and generates correction rules without manual intervention or environment specific tuning. Through comprehensive experiments with novel evaluation metrics, ADLGen is shown to outperform baseline generators in statistical fidelity, semantic richness, and downstream activity recognition, offering a scalable and privacy-preserving solution for ADL data synthesis.
From Assistants to Adversaries: Exploring the Security Risks of Mobile LLM Agents
May 19, 2025The growing adoption of large language models (LLMs) has led to a new paradigm in mobile computing--LLM-powered mobile AI agents--capable of decomposing and automating complex tasks directly on smartphones. However, the security implications of these agents remain largely unexplored. In this paper, we present the first comprehensive security analysis of mobile LLM agents, encompassing three representative categories: System-level AI Agents developed by original equipment manufacturers (e.g., YOYO Assistant), Third-party Universal Agents (e.g., Zhipu AI AutoGLM), and Emerging Agent Frameworks (e.g., Alibaba Mobile Agent). We begin by analyzing the general workflow of mobile agents and identifying security threats across three core capability dimensions: language-based reasoning, GUI-based interaction, and system-level execution. Our analysis reveals 11 distinct attack surfaces, all rooted in the unique capabilities and interaction patterns of mobile LLM agents, and spanning their entire operational lifecycle. To investigate these threats in practice, we introduce AgentScan, a semi-automated security analysis framework that systematically evaluates mobile LLM agents across all 11 attack scenarios. Applying AgentScan to nine widely deployed agents, we uncover a concerning trend: every agent is vulnerable to targeted attacks. In the most severe cases, agents exhibit vulnerabilities across eight distinct attack vectors. These attacks can cause behavioral deviations, privacy leakage, or even full execution hijacking. Based on these findings, we propose a set of defensive design principles and practical recommendations for building secure mobile LLM agents. Our disclosures have received positive feedback from two major device vendors. Overall, this work highlights the urgent need for standardized security practices in the fast-evolving landscape of LLM-driven mobile automation.
HOME-3: High-Order Momentum Estimator with Third-Power Gradient for Convex and Smooth Nonconvex Optimization
May 16, 2025Momentum-based gradients are essential for optimizing advanced machine learning models, as they not only accelerate convergence but also advance optimizers to escape stationary points. While most state-of-the-art momentum techniques utilize lower-order gradients, such as the squared first-order gradient, there has been limited exploration of higher-order gradients, particularly those raised to powers greater than two. In this work, we introduce the concept of high-order momentum, where momentum is constructed using higher-power gradients, with a focus on the third-power of the first-order gradient as a representative case. Our research offers both theoretical and empirical support for this approach. Theoretically, we demonstrate that incorporating third-power gradients can improve the convergence bounds of gradient-based optimizers for both convex and smooth nonconvex problems. Empirically, we validate these findings through extensive experiments across convex, smooth nonconvex, and nonsmooth nonconvex optimization tasks. Across all cases, high-order momentum consistently outperforms conventional low-order momentum methods, showcasing superior performance in various optimization problems.