 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferrable Prototypical Networks for Unsupervised Domain Adaptation
Apr 25, 2019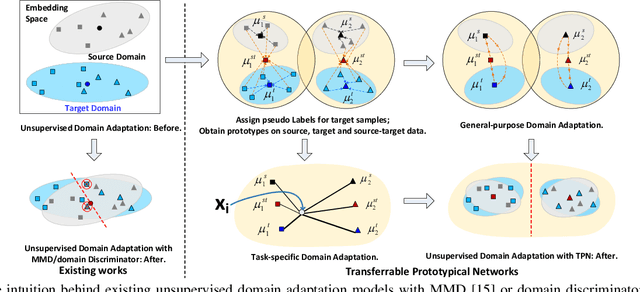
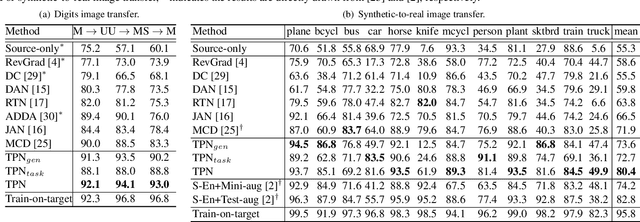


In this paper, we introduce a new idea for unsupervised domain adaptation via a remold of Prototypical Networks, which learn an embedding space and perform classification via a remold of the distances to the prototype of each class. Specifically, we present Transferrable Prototypical Networks (TPN) for adaptation such that the prototypes for each class in source and target domains are close in the embedding space and the score distributions predicted by prototypes separately on source and target data are similar. Technically, TPN initially matches each target example to the nearest prototype in the source domain and assigns an example a "pseudo" label. The prototype of each class could then be computed on source-only, target-only and source-target data, respectively. The optimization of TPN is end-to-end trained by jointly minimizing the distance across the prototypes on three types of data and KL-divergence of score distributions output by each pair of the prototypes. Extensive experiments are conducted on the transfers across MNIST, USPS and SVHN datasets, and superior results are reported when comparing to state-of-the-art approaches. More remarkably, we obtain an accuracy of 80.4% of single model on VisDA 2017 dataset.
Everyone is a Cartoonist: Selfie Cartoonization with Attentive Adversarial Networks
Apr 20, 2019
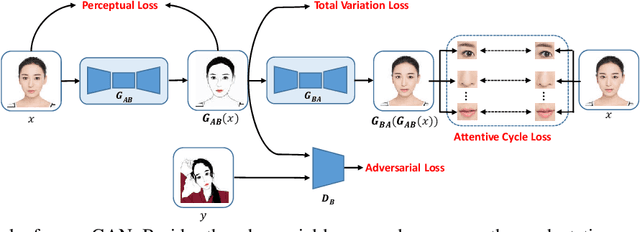


Selfie and cartoon are two popular artistic forms that are widely presented in our daily life. Despite the great progress in image translation/stylization, few techniques focus specifically on selfie cartoonization, since cartoon images usually contain artistic abstraction (e.g., large smoothing areas) and exaggeration (e.g., large/delicate eyebrows). In this paper, we address this problem by proposing a selfie cartoonization Generative Adversarial Network (scGAN), which mainly uses an attentive adversarial network (AAN) to emphasize specific facial regions and ignore low-level details. More specifically, we first design a cycle-like architecture to enable training with unpaired data. Then we design three losses from different aspects. A total variation loss is used to highlight important edges and contents in cartoon portraits. An attentive cycle loss is added to lay more emphasis on delicate facial areas such as eyes. In addition, a perceptual loss is included to eliminate artifacts and improve robustness of our method. Experimental results show that our method is capable of generating different cartoon styles and outperforms a number of state-of-the-art methods.
Unsupervised Person Image Generation with Semantic Parsing Transformation
Apr 18, 2019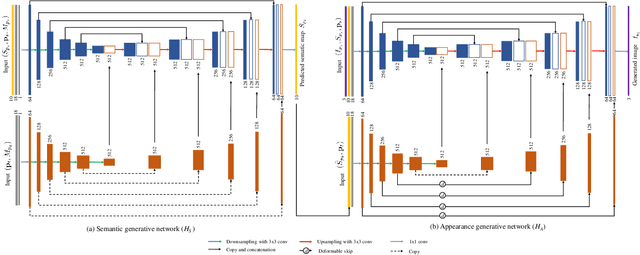

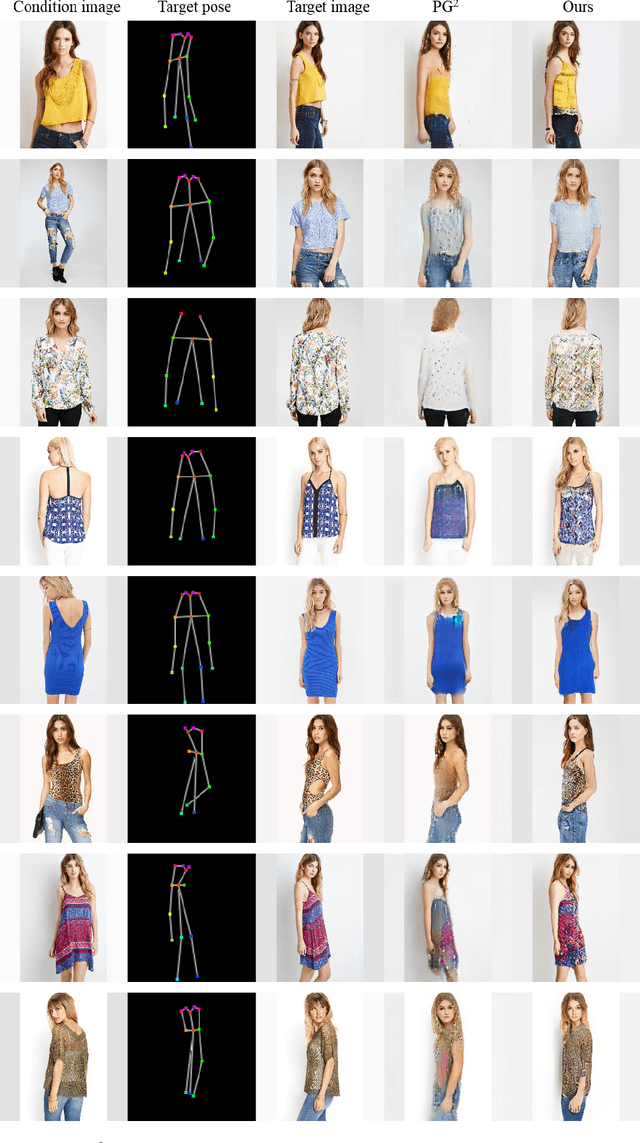
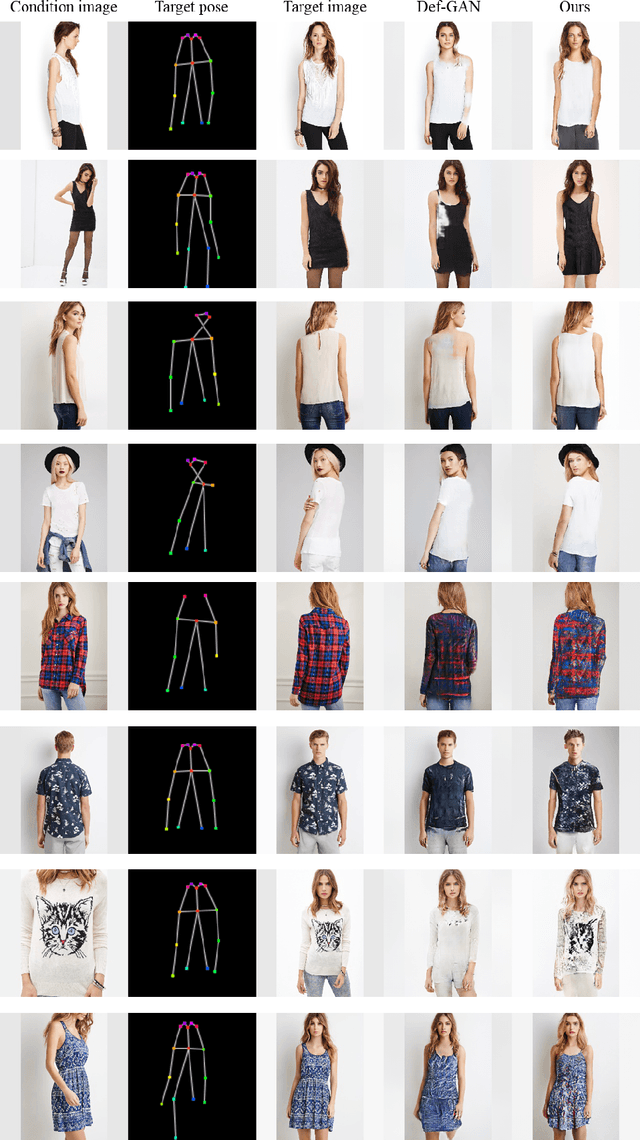
In this paper, we address unsupervised pose-guided person image generation, which is known challenging due to non-rigid deformation. Unlike previous methods learning a rock-hard direct mapping between human bodies, we propose a new pathway to decompose the hard mapping into two more accessible subtasks, namely, semantic parsing transformation and appearance generation. Firstly, a semantic generative network is proposed to transform between semantic parsing maps, in order to simplify the non-rigid deformation learning. Secondly, an appearance generative network learns to synthesize semantic-aware textures. Thirdly, we demonstrate that training our framework in an end-to-end manner further refines the semantic maps and final results accordingly. Our method is generalizable to other semantic-aware person image generation tasks, eg, clothing texture transfer and controlled image manipulation. Experimental results demonstrate the superiority of our method on DeepFashion and Market-1501 datasets, especially in keeping the clothing attributes and better body shapes.
WIDER Face and Pedestrian Challenge 2018: Methods and Results
Feb 19, 2019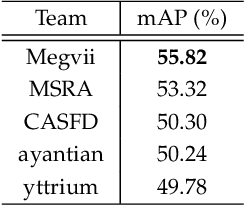

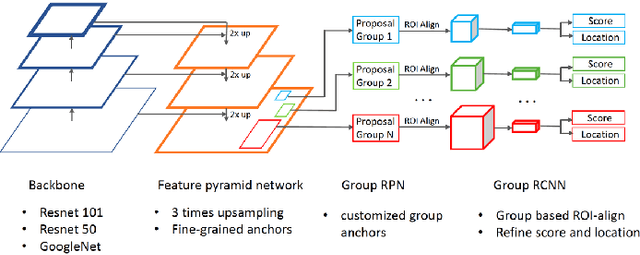
This paper presents a review of the 2018 WIDER Challenge on Face and Pedestrian. The challenge focuses on the problem of precise localization of human faces and bodies, and accurate association of identities. It comprises of three tracks: (i) WIDER Face which aims at soliciting new approaches to advance the state-of-the-art in face detection, (ii) WIDER Pedestrian which aims to find effective and efficient approaches to address the problem of pedestrian detection in unconstrained environments, and (iii) WIDER Person Search which presents an exciting challenge of searching persons across 192 movies. In total, 73 teams made valid submissions to the challenge tracks. We summarize the winning solutions for all three tracks. and present discussions on open problems and potential research directions in these topics.
Rethinking Visual Relationships for High-level Image Understanding
Feb 01, 2019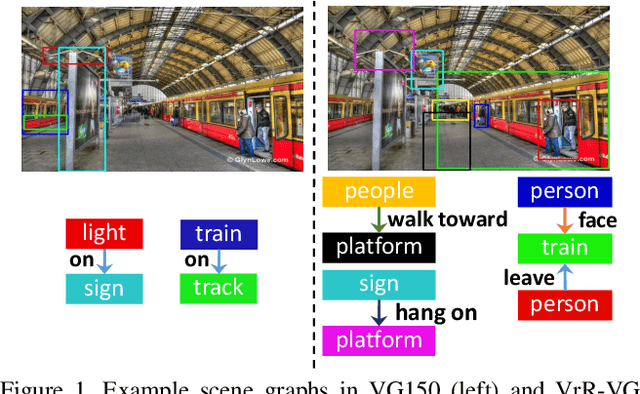
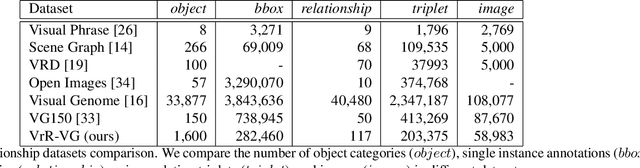
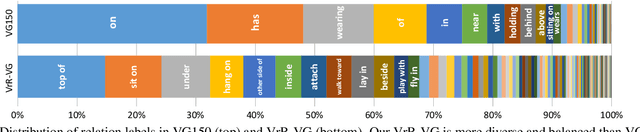
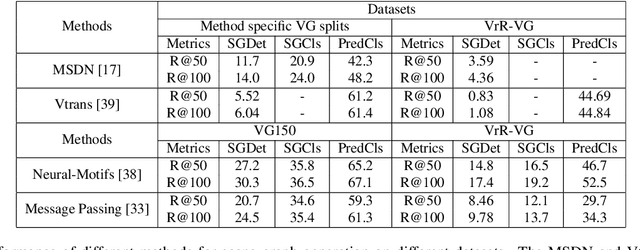
Relationships, as the bond of isolated entities in images, reflect the interaction between objects and lead to a semantic understanding of scenes. Suffering from visually-irrelevant relationships in current scene graph datasets, the utilization of relationships for semantic tasks is difficult. The datasets widely used in scene graph generation tasks are splitted from Visual Genome by label frequency, which even can be well solved by statistical counting. To encourage further development in relationships, we propose a novel method to mine more valuable relationships by automatically filtering out visually-irrelevant relationships. Then, we construct a new scene graph dataset named Visually-Relevant Relationships Dataset (VrR-VG) from Visual Genome. We evaluate several existing methods in scene graph generation in our dataset. The results show the performances degrade significantly compared to the previous dataset and the frequency analysis do not work on our dataset anymore. Moreover, we propose a method to learn feature representations of instances, attributes, and visual relationships jointly from images, then we apply the learned features to image captioning and visual question answering respectively. The improvements on the both tasks demonstrate the efficiency of the features with relation information and the richer semantic information provided in our dataset.
Improved Selective Refinement Network for Face Detection
Jan 23, 2019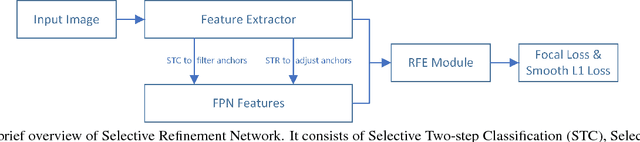
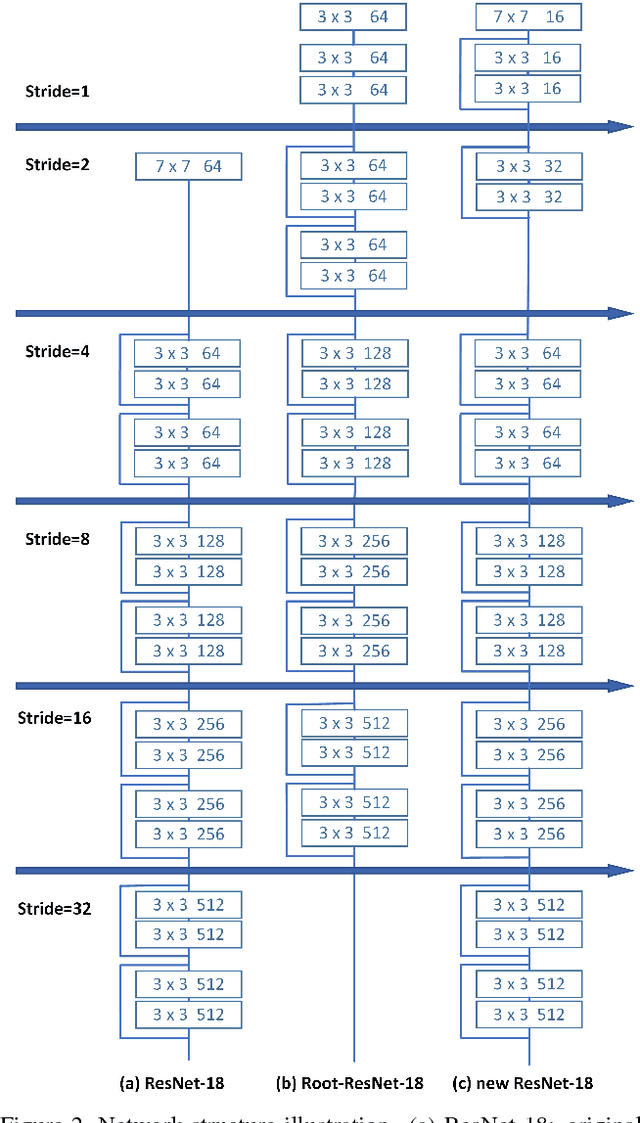

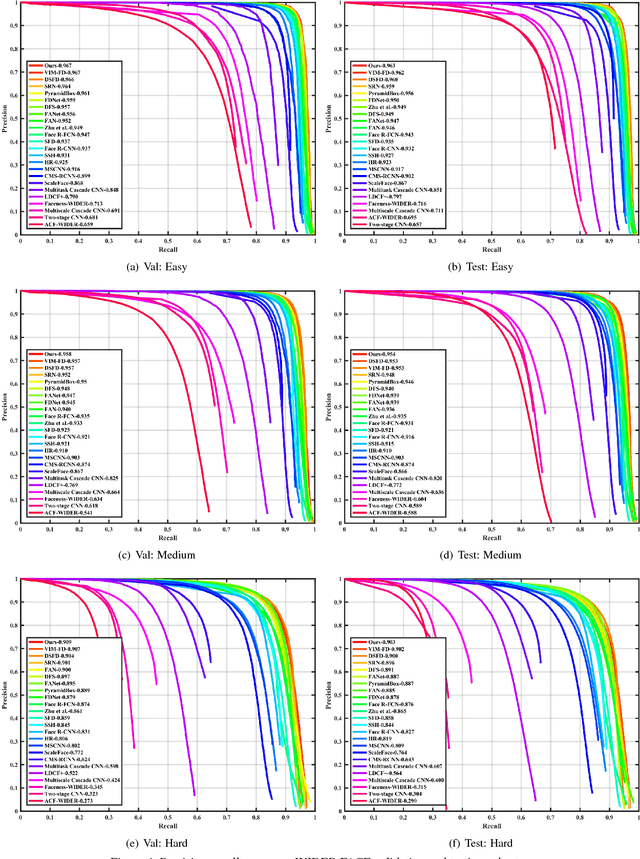
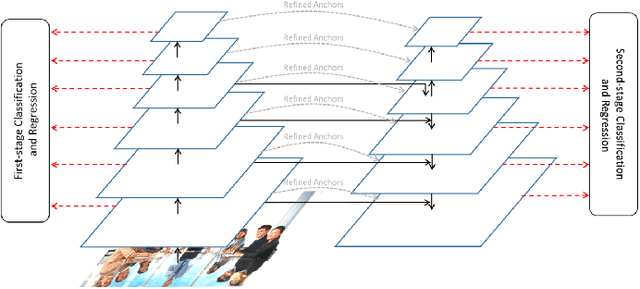
As a long-standing problem in computer vision, face detection has attracted much attention in recent decades for its practical applications. With the availability of face detection benchmark WIDER FACE dataset, much of the progresses have been made by various algorithms in recent years. Among them, the Selective Refinement Network (SRN) face detector introduces the two-step classification and regression operations selectively into an anchor-based face detector to reduce false positives and improve location accuracy simultaneously. Moreover, it designs a receptive field enhancement block to provide more diverse receptive field. In this report, to further improve the performance of SRN, we exploit some existing techniques via extensive experiments, including new data augmentation strategy, improved backbone network, MS COCO pretraining, decoupled classification module, segmentation branch and Squeeze-and-Excitation block. Some of these techniques bring performance improvements, while few of them do not well adapt to our baseline. As a consequence, we present an improved SRN face detector by combining these useful techniques together and obtain the best performance on widely used face detection benchmark WIDER FACE dataset.
Multi-Granularity Reasoning for Social Relation Recognition from Images
Jan 10, 2019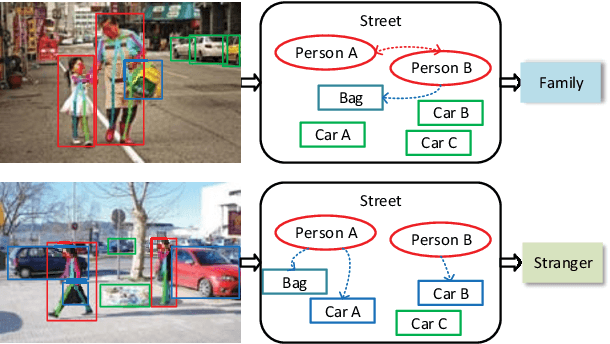
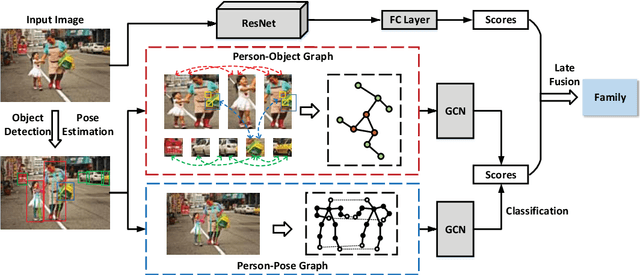
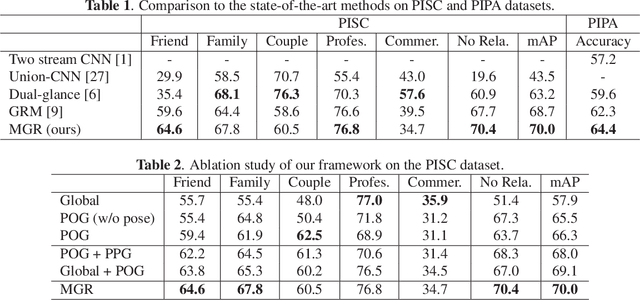
Discovering social relations in images can make machines better interpret the behavior of human beings. However, automatically recognizing social relations in images is a challenging task due to the significant gap between the domains of visual content and social relation. Existing studies separately process various features such as faces expressions, body appearance, and contextual objects, thus they cannot comprehensively capture the multi-granularity semantics, such as scenes, regional cues of persons, and interactions among persons and objects. To bridge the domain gap, we propose a Multi-Granularity Reasoning framework for social relation recognition from images. The global knowledge and mid-level details are learned from the whole scene and the regions of persons and objects, respectively. Most importantly, we explore the fine-granularity pose keypoints of persons to discover the interactions among persons and objects. Specifically, the pose-guided Person-Object Graph and Person-Pose Graph are proposed to model the actions from persons to object and the interactions between paired persons, respectively. Based on the graphs, social relation reasoning is performed by graph convolutional networks. Finally, the global features and reasoned knowledge are integrated as a comprehensive representation for social relation recognition. Extensive experiments on two public datasets show the effectiveness of the proposed framework.
Support Vector Guided Softmax Loss for Face Recognition
Dec 29, 2018



Face recognition has witnessed significant progresses due to the advances of deep convolutional neural networks (CNNs), the central challenge of which, is feature discrimination. To address it, one group tries to exploit mining-based strategies (\textit{e.g.}, hard example mining and focal loss) to focus on the informative examples. The other group devotes to designing margin-based loss functions (\textit{e.g.}, angular, additive and additive angular margins) to increase the feature margin from the perspective of ground truth class. Both of them have been well-verified to learn discriminative features. However, they suffer from either the ambiguity of hard examples or the lack of discriminative power of other classes. In this paper, we design a novel loss function, namely support vector guided softmax loss (SV-Softmax), which adaptively emphasizes the mis-classified points (support vectors) to guide the discriminative features learning. So the developed SV-Softmax loss is able to eliminate the ambiguity of hard examples as well as absorb the discriminative power of other classes, and thus results in more discrimiantive features. To the best of our knowledge, this is the first attempt to inherit the advantages of mining-based and margin-based losses into one framework. Experimental results on several benchmarks have demonstrated the effectiveness of our approach over state-of-the-arts.
To Find Where You Talk: Temporal Sentence Localization in Video with Attention Based Location Regression
Nov 03, 2018
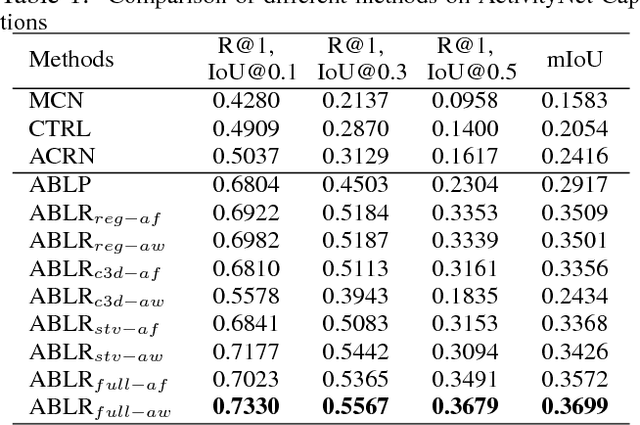


Given an untrimmed video and a sentence description, temporal sentence localization aims to automatically determine the start and end points of the described sentence within the video. The problem is challenging as it needs the understanding of both video and sentence. Existing research predominantly employs a costly "scan and localize" framework, neglecting the global video context and the specific details within sentences which play as critical issues for this problem. In this paper, we propose a novel Attention Based Location Regression (ABLR) approach to solve the temporal sentence localization from a global perspective. Specifically, to preserve the context information, ABLR first encodes both video and sentence via Bidirectional LSTM networks. Then, a multi-modal co-attention mechanism is introduced to generate not only video attention which reflects the global video structure, but also sentence attention which highlights the crucial details for temporal localization. Finally, a novel attention based location regression network is designed to predict the temporal coordinates of sentence query from the previous attention. ABLR is jointly trained in an end-to-end manner. Comprehensive experiments on ActivityNet Captions and TACoS datasets demonstrate both the effectiveness and the efficiency of the proposed ABLR approach.
ScratchDet:Exploring to Train Single-Shot Object Detectors from Scratch
Oct 19, 2018


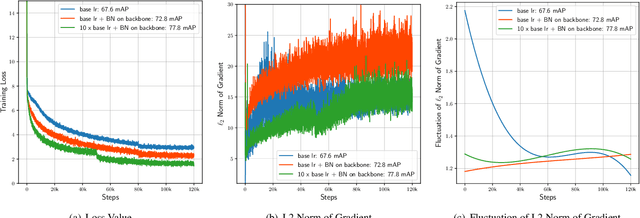
Current state-of-the-art object objectors are fine-tuned from the off-the-shelf networks pretrained on large-scale classification datasets like ImageNet, which incurs some accessory problems: 1) the domain gap between source and target datasets; 2) the learning objective bias between classification and detection; 3) the architecture limitations of the classification network for detection. In this paper, we design a new single-shot train-from-scratch object detector referring to the architectures of the ResNet and VGGNet based SSD models, called ScratchDet, to alleviate the aforementioned problems. Specifically, we study the impact of BatchNorm on training detectors from scratch, and find that using BatchNorm on the backbone and detection head subnetworks makes the detector converge well from scratch. After that, we explore the network architecture by analyzing the detection performance of ResNet and VGGNet, and introduce a new Root-ResNet backbone network to further improve the accuracy. Extensive experiments on PASCAL VOC 2007, 2012 and MS COCO datasets demonstrate that ScratchDet achieves the state-of-the-art performance among all the train-from-scratch detectors and even outperforms existing one-stage pretrained methods without bells and whistles. Codes will be made publicly available at https://github.com/KimSoybean/ScratchDet.