 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Sentence Similarity Estimation for Unsupervised Extractive Summarization
Feb 24, 2023


Unsupervised extractive summarization aims to extract salient sentences from a document as the summary without labeled data. Recent literatures mostly research how to leverage sentence similarity to rank sentences in the order of salience. However, sentence similarity estimation using pre-trained language models mostly takes little account of document-level information and has a weak correlation with sentence salience ranking. In this paper, we proposed two novel strategies to improve sentence similarity estimation for unsupervised extractive summarization. We use contrastive learning to optimize a document-level objective that sentences from the same document are more similar than those from different documents. Moreover, we use mutual learning to enhance the relationship between sentence similarity estimation and sentence salience ranking, where an extra signal amplifier is used to refine the pivotal information. Experimental results demonstrate the effectiveness of our strategies.
WeCheck: Strong Factual Consistency Checker via Weakly Supervised Learning
Dec 20, 2022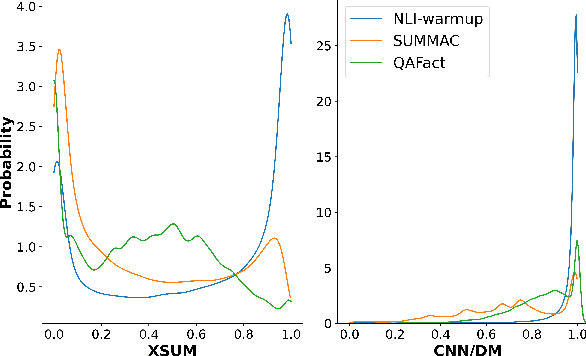
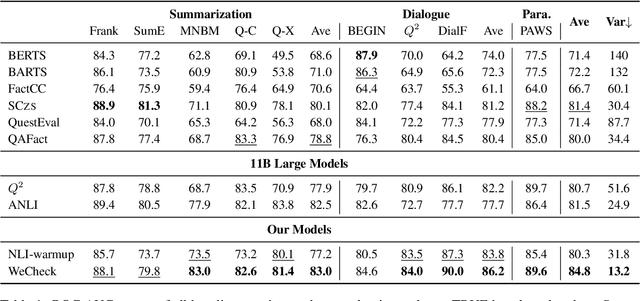
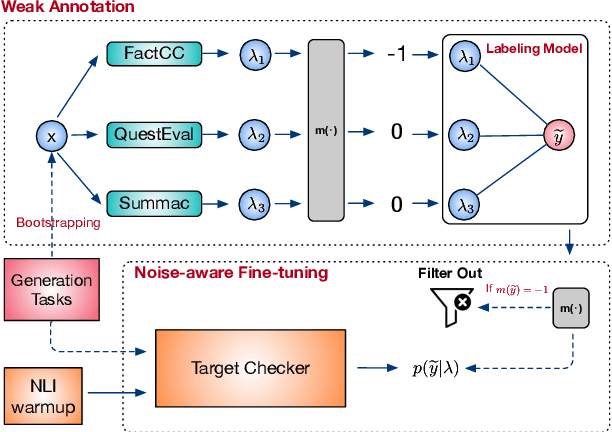
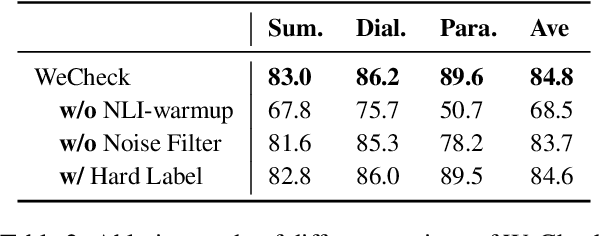
A crucial issue of current text generation models is that they often uncontrollably generate factually inconsistent text with respective of their inputs. Limited by the lack of annotated data, existing works in evaluating factual consistency directly transfer the reasoning ability of models trained on other data-rich upstream tasks like question answering (QA) and natural language inference (NLI) without any further adaptation. As a result, they perform poorly on the real generated text and are biased heavily by their single-source upstream tasks. To alleviate this problem, we propose a weakly supervised framework that aggregates multiple resources to train a precise and efficient factual metric, namely WeCheck. WeCheck first utilizes a generative model to accurately label a real generated sample by aggregating its weak labels, which are inferred from multiple resources. Then, we train the target metric model with the weak supervision while taking noises into consideration. Comprehensive experiments on a variety of tasks demonstrate the strong performance of WeCheck, which achieves a 3.4\% absolute improvement over previous state-of-the-art methods on TRUE benchmark on average.
Consecutive Question Generation via Dynamic Multitask Learning
Nov 16, 2022



In this paper, we propose the task of consecutive question generation (CQG), which generates a set of logically related question-answer pairs to understand a whole passage, with a comprehensive consideration of the aspects including accuracy, coverage, and informativeness. To achieve this, we first examine the four key elements of CQG, i.e., question, answer, rationale, and context history, and propose a novel dynamic multitask framework with one main task generating a question-answer pair, and four auxiliary tasks generating other elements. It directly helps the model generate good questions through both joint training and self-reranking. At the same time, to fully explore the worth-asking information in a given passage, we make use of the reranking losses to sample the rationales and search for the best question series globally. Finally, we measure our strategy by QA data augmentation and manual evaluation, as well as a novel application of generated question-answer pairs on DocNLI. We prove that our strategy can improve question generation significantly and benefit multiple related NLP tasks.
FRSUM: Towards Faithful Abstractive Summarization via Enhancing Factual Robustness
Nov 01, 2022Despite being able to generate fluent and grammatical text, current Seq2Seq summarization models still suffering from the unfaithful generation problem. In this paper, we study the faithfulness of existing systems from a new perspective of factual robustness which is the ability to correctly generate factual information over adversarial unfaithful information. We first measure a model's factual robustness by its success rate to defend against adversarial attacks when generating factual information. The factual robustness analysis on a wide range of current systems shows its good consistency with human judgments on faithfulness. Inspired by these findings, we propose to improve the faithfulness of a model by enhancing its factual robustness. Specifically, we propose a novel training strategy, namely FRSUM, which teaches the model to defend against both explicit adversarial samples and implicit factual adversarial perturbations. Extensive automatic and human evaluation results show that FRSUM consistently improves the faithfulness of various Seq2Seq models, such as T5, BART.
IntTower: the Next Generation of Two-Tower Model for Pre-Ranking System
Oct 18, 2022
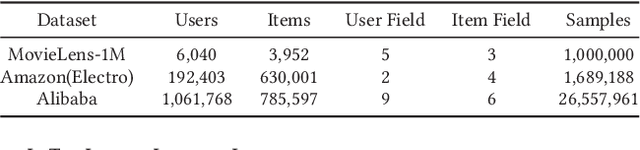
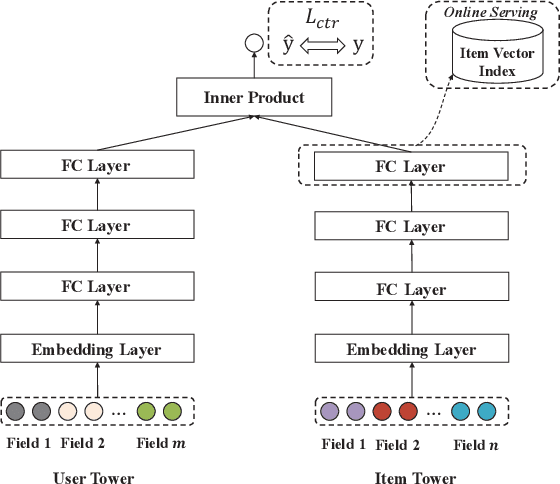
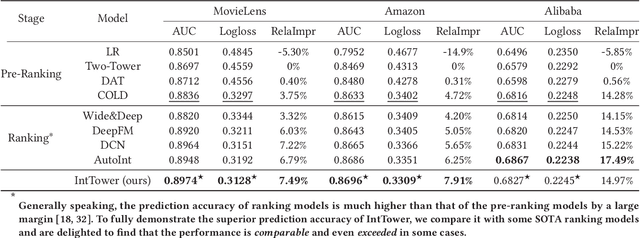
Scoring a large number of candidates precisely in several milliseconds is vital for industrial pre-ranking systems. Existing pre-ranking systems primarily adopt the \textbf{two-tower} model since the ``user-item decoupling architecture'' paradigm is able to balance the \textit{efficiency} and \textit{effectiveness}. However, the cost of high efficiency is the neglect of the potential information interaction between user and item towers, hindering the prediction accuracy critically. In this paper, we show it is possible to design a two-tower model that emphasizes both information interactions and inference efficiency. The proposed model, IntTower (short for \textit{Interaction enhanced Two-Tower}), consists of Light-SE, FE-Block and CIR modules. Specifically, lightweight Light-SE module is used to identify the importance of different features and obtain refined feature representations in each tower. FE-Block module performs fine-grained and early feature interactions to capture the interactive signals between user and item towers explicitly and CIR module leverages a contrastive interaction regularization to further enhance the interactions implicitly. Experimental results on three public datasets show that IntTower outperforms the SOTA pre-ranking models significantly and even achieves comparable performance in comparison with the ranking models. Moreover, we further verify the effectiveness of IntTower on a large-scale advertisement pre-ranking system. The code of IntTower is publicly available\footnote{https://github.com/archersama/IntTower}
Learning Robust Representations for Continual Relation Extraction via Adversarial Class Augmentation
Oct 10, 2022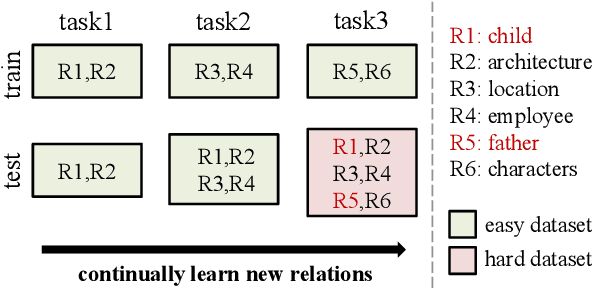
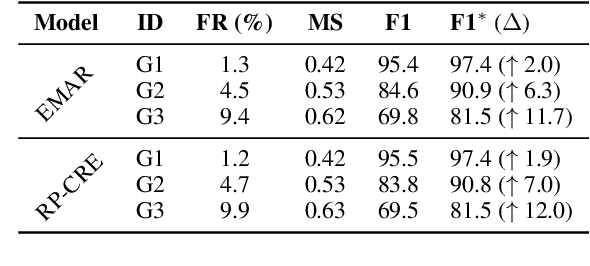

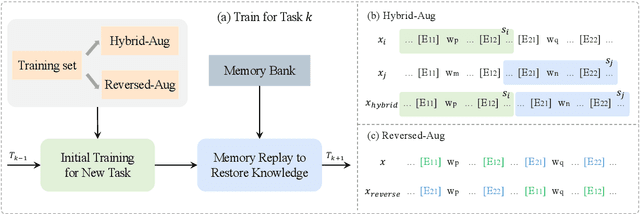
Continual relation extraction (CRE) aims to continually learn new relations from a class-incremental data stream. CRE model usually suffers from catastrophic forgetting problem, i.e., the performance of old relations seriously degrades when the model learns new relations. Most previous work attributes catastrophic forgetting to the corruption of the learned representations as new relations come, with an implicit assumption that the CRE models have adequately learned the old relations. In this paper, through empirical studies we argue that this assumption may not hold, and an important reason for catastrophic forgetting is that the learned representations do not have good robustness against the appearance of analogous relations in the subsequent learning process. To address this issue, we encourage the model to learn more precise and robust representations through a simple yet effective adversarial class augmentation mechanism (ACA), which is easy to implement and model-agnostic. Experimental results show that ACA can consistently improve the performance of state-of-the-art CRE models on two popular benchmarks.
ConFiguRe: Exploring Discourse-level Chinese Figures of Speech
Sep 16, 2022
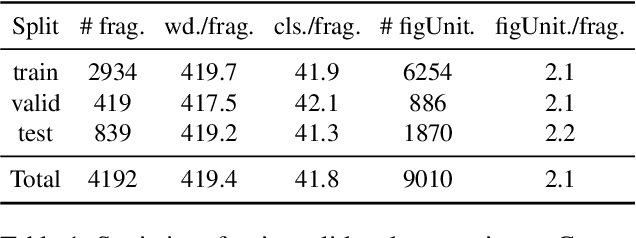

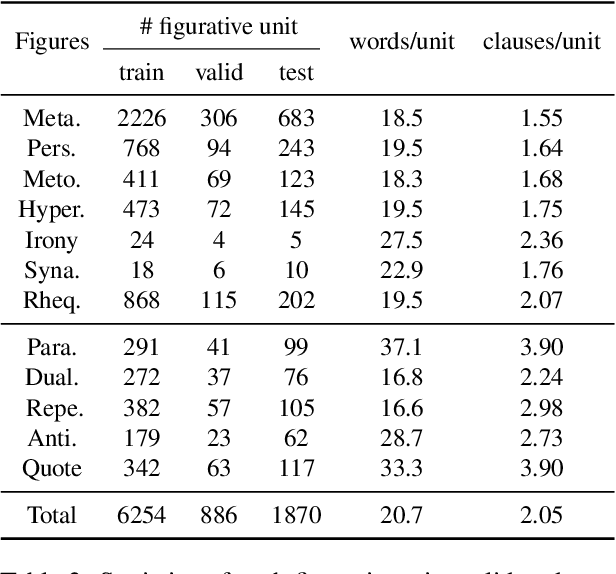
Figures of speech, such as metaphor and irony, are ubiquitous in literature works and colloquial conversations. This poses great challenge for natural language understanding since figures of speech usually deviate from their ostensible meanings to express deeper semantic implications. Previous research lays emphasis on the literary aspect of figures and seldom provide a comprehensive exploration from a view of computational linguistics. In this paper, we first propose the concept of figurative unit, which is the carrier of a figure. Then we select 12 types of figures commonly used in Chinese, and build a Chinese corpus for Contextualized Figure Recognition (ConFiguRe). Different from previous token-level or sentence-level counterparts, ConFiguRe aims at extracting a figurative unit from discourse-level context, and classifying the figurative unit into the right figure type. On ConFiguRe, three tasks, i.e., figure extraction, figure type classification and figure recognition, are designed and the state-of-the-art techniques are utilized to implement the benchmarks. We conduct thorough experiments and show that all three tasks are challenging for existing models, thus requiring further research. Our dataset and code are publicly available at https://github.com/pku-tangent/ConFiguRe.
Visual Subtitle Feature Enhanced Video Outline Generation
Sep 01, 2022
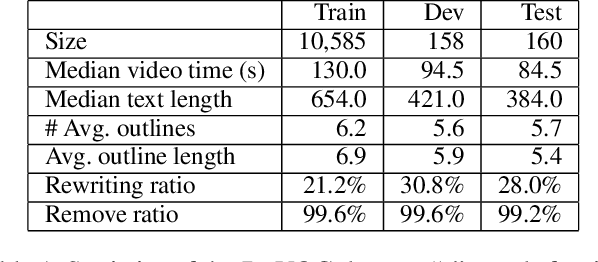

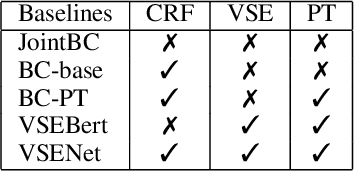
With the tremendously increasing number of videos, there is a great demand for techniques that help people quickly navigate to the video segments they are interested in. However, current works on video understanding mainly focus on video content summarization, while little effort has been made to explore the structure of a video. Inspired by textual outline generation, we introduce a novel video understanding task, namely video outline generation (VOG). This task is defined to contain two sub-tasks: (1) first segmenting the video according to the content structure and then (2) generating a heading for each segment. To learn and evaluate VOG, we annotate a 10k+ dataset, called DuVOG. Specifically, we use OCR tools to recognize subtitles of videos. Then annotators are asked to divide subtitles into chapters and title each chapter. In videos, highlighted text tends to be the headline since it is more likely to attract attention. Therefore we propose a Visual Subtitle feature Enhanced video outline generation model (VSENet) which takes as input the textual subtitles together with their visual font sizes and positions. We consider the VOG task as a sequence tagging problem that extracts spans where the headings are located and then rewrites them to form the final outlines. Furthermore, based on the similarity between video outlines and textual outlines, we use a large number of articles with chapter headings to pretrain our model. Experiments on DuVOG show that our model largely outperforms other baseline methods, achieving 77.1 of F1-score for the video segmentation level and 85.0 of ROUGE-L_F0.5 for the headline generation level.
Revising Image-Text Retrieval via Multi-Modal Entailment
Sep 01, 2022

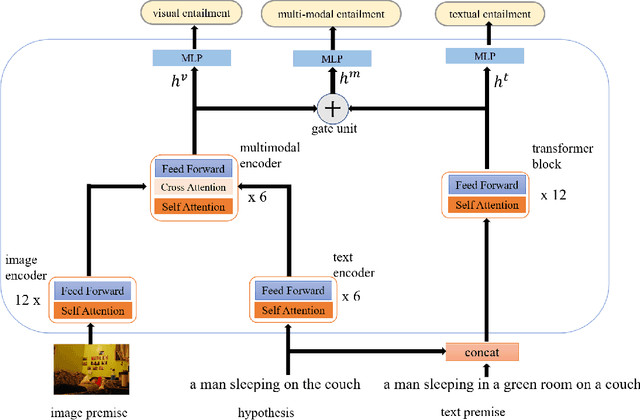
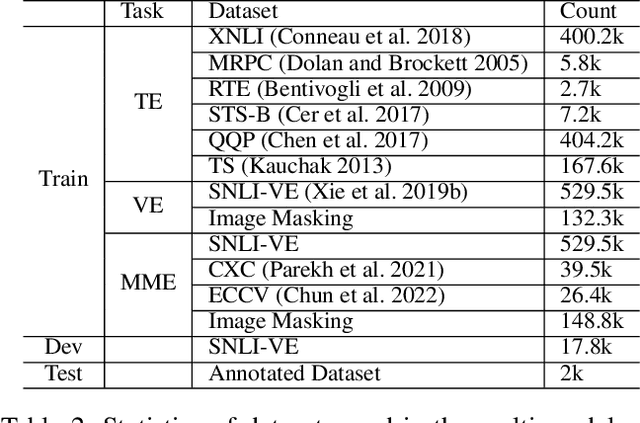
An outstanding image-text retrieval model depends on high-quality labeled data. While the builders of existing image-text retrieval datasets strive to ensure that the caption matches the linked image, they cannot prevent a caption from fitting other images. We observe that such a many-to-many matching phenomenon is quite common in the widely-used retrieval datasets, where one caption can describe up to 178 images. These large matching-lost data not only confuse the model in training but also weaken the evaluation accuracy. Inspired by visual and textual entailment tasks, we propose a multi-modal entailment classifier to determine whether a sentence is entailed by an image plus its linked captions. Subsequently, we revise the image-text retrieval datasets by adding these entailed captions as additional weak labels of an image and develop a universal variable learning rate strategy to teach a retrieval model to distinguish the entailed captions from other negative samples. In experiments, we manually annotate an entailment-corrected image-text retrieval dataset for evaluation. The results demonstrate that the proposed entailment classifier achieves about 78% accuracy and consistently improves the performance of image-text retrieval baselines.
Low Resource Style Transfer via Domain Adaptive Meta Learning
May 25, 2022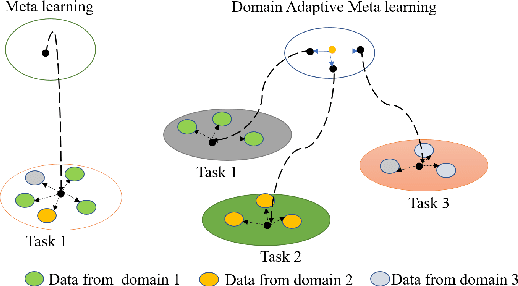
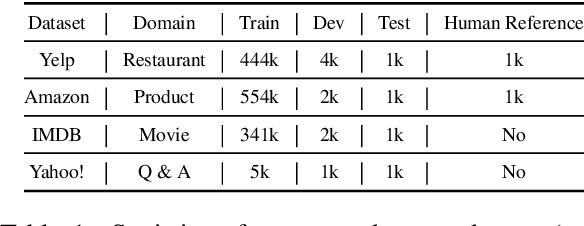
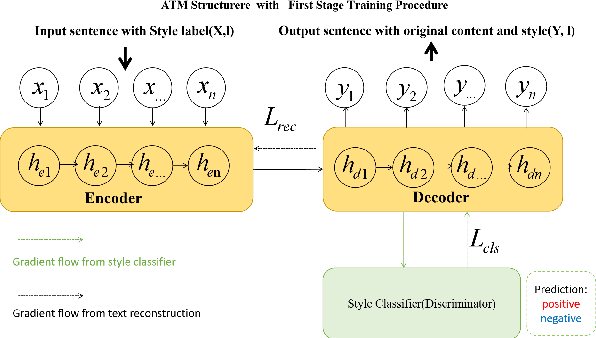
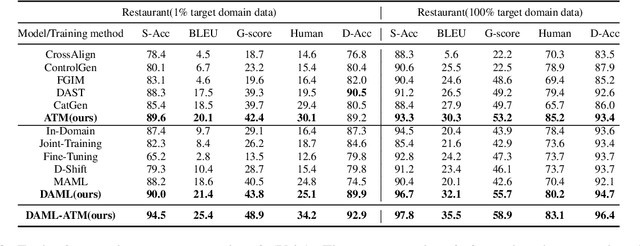
Text style transfer (TST) without parallel data has achieved some practical success. However, most of the existing unsupervised text style transfer methods suffer from (i) requiring massive amounts of non-parallel data to guide transferring different text styles. (ii) colossal performance degradation when fine-tuning the model in new domains. In this work, we propose DAML-ATM (Domain Adaptive Meta-Learning with Adversarial Transfer Model), which consists of two parts: DAML and ATM. DAML is a domain adaptive meta-learning approach to learn general knowledge in multiple heterogeneous source domains, capable of adapting to new unseen domains with a small amount of data. Moreover, we propose a new unsupervised TST approach Adversarial Transfer Model (ATM), composed of a sequence-to-sequence pre-trained language model and uses adversarial style training for better content preservation and style transfer. Results on multi-domain datasets demonstrate that our approach generalizes well on unseen low-resource domains, achieving state-of-the-art results against ten strong baselines.