 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTInR: Exploring Tool-Internalized Reasoning in Large Language Models
Apr 12, 2026Tool-Integrated Reasoning (TIR) has emerged as a promising direction by extending Large Language Models' (LLMs) capabilities with external tools during reasoning. Existing TIR methods typically rely on external tool documentation during reasoning. However, this leads to tool mastery difficulty, tool size constraints, and inference inefficiency. To mitigate these issues, we explore Tool-Internalized Reasoning (TInR), aiming at facilitating reasoning with tool knowledge internalized into LLMs. Achieving this goal presents notable requirements, including tool internalization and tool-reasoning coordination. To address them, we propose TInR-U, a tool-internalized reasoning framework for unified reasoning and tool usage. TInR-U is trained through a three-phase pipeline: 1) tool internalization with a bidirectional knowledge alignment strategy; 2) supervised fine-tuning warm-up using high-quality reasoning annotations, and 3) reinforcement learning with TInR-specific rewards. We comprehensively evaluate our method across in-domain and out-of-domain settings. Experiment results show that TInR-U achieves superior performance in both settings, highlighting its effectiveness and efficiency.
Agent-as-a-Judge
Jan 08, 2026LLM-as-a-Judge has revolutionized AI evaluation by leveraging large language models for scalable assessments. However, as evaluands become increasingly complex, specialized, and multi-step, the reliability of LLM-as-a-Judge has become constrained by inherent biases, shallow single-pass reasoning, and the inability to verify assessments against real-world observations. This has catalyzed the transition to Agent-as-a-Judge, where agentic judges employ planning, tool-augmented verification, multi-agent collaboration, and persistent memory to enable more robust, verifiable, and nuanced evaluations. Despite the rapid proliferation of agentic evaluation systems, the field lacks a unified framework to navigate this shifting landscape. To bridge this gap, we present the first comprehensive survey tracing this evolution. Specifically, we identify key dimensions that characterize this paradigm shift and establish a developmental taxonomy. We organize core methodologies and survey applications across general and professional domains. Furthermore, we analyze frontier challenges and identify promising research directions, ultimately providing a clear roadmap for the next generation of agentic evaluation.
Towards Dynamic Theory of Mind: Evaluating LLM Adaptation to Temporal Evolution of Human States
May 23, 2025As Large Language Models (LLMs) increasingly participate in human-AI interactions, evaluating their Theory of Mind (ToM) capabilities - particularly their ability to track dynamic mental states - becomes crucial. While existing benchmarks assess basic ToM abilities, they predominantly focus on static snapshots of mental states, overlooking the temporal evolution that characterizes real-world social interactions. We present \textsc{DynToM}, a novel benchmark specifically designed to evaluate LLMs' ability to understand and track the temporal progression of mental states across interconnected scenarios. Through a systematic four-step framework, we generate 1,100 social contexts encompassing 5,500 scenarios and 78,100 questions, each validated for realism and quality. Our comprehensive evaluation of ten state-of-the-art LLMs reveals that their average performance underperforms humans by 44.7\%, with performance degrading significantly when tracking and reasoning about the shift of mental states. This performance gap highlights fundamental limitations in current LLMs' ability to model the dynamic nature of human mental states.
KNN-SSD: Enabling Dynamic Self-Speculative Decoding via Nearest Neighbor Layer Set Optimization
May 22, 2025Speculative Decoding (SD) has emerged as a widely used paradigm to accelerate the inference of large language models (LLMs) without compromising generation quality. It works by efficiently drafting multiple tokens using a compact model and then verifying them in parallel using the target LLM. Notably, Self-Speculative Decoding proposes skipping certain layers to construct the draft model, which eliminates the need for additional parameters or training. Despite its strengths, we observe in this work that drafting with layer skipping exhibits significant sensitivity to domain shifts, leading to a substantial drop in acceleration performance. To enhance the domain generalizability of this paradigm, we introduce KNN-SSD, an algorithm that leverages K-Nearest Neighbor (KNN) search to match different skipped layers with various domain inputs. We evaluated our algorithm in various models and multiple tasks, observing that its application leads to 1.3x-1.6x speedup in LLM inference.
PEToolLLM: Towards Personalized Tool Learning in Large Language Models
Feb 26, 2025Tool learning has emerged as a promising direction by extending Large Language Models' (LLMs) capabilities with external tools. Existing tool learning studies primarily focus on the general-purpose tool-use capability, which addresses explicit user requirements in instructions. However, they overlook the importance of personalized tool-use capability, leading to an inability to handle implicit user preferences. To address the limitation, we first formulate the task of personalized tool learning, which integrates user's interaction history towards personalized tool usage. To fill the gap of missing benchmarks, we construct PEToolBench, featuring diverse user preferences reflected in interaction history under three distinct personalized settings, and encompassing a wide range of tool-use scenarios. Moreover, we propose a framework PEToolLLaMA to adapt LLMs to the personalized tool learning task, which is trained through supervised fine-tuning and direct preference optimization. Extensive experiments on PEToolBench demonstrate the superiority of PEToolLLaMA over existing LLMs.
Enhancing Tool Retrieval with Iterative Feedback from Large Language Models
Jun 25, 2024



Tool learning aims to enhance and expand large language models' (LLMs) capabilities with external tools, which has gained significant attention recently. Current methods have shown that LLMs can effectively handle a certain amount of tools through in-context learning or fine-tuning. However, in real-world scenarios, the number of tools is typically extensive and irregularly updated, emphasizing the necessity for a dedicated tool retrieval component. Tool retrieval is nontrivial due to the following challenges: 1) complex user instructions and tool descriptions; 2) misalignment between tool retrieval and tool usage models. To address the above issues, we propose to enhance tool retrieval with iterative feedback from the large language model. Specifically, we prompt the tool usage model, i.e., the LLM, to provide feedback for the tool retriever model in multi-round, which could progressively improve the tool retriever's understanding of instructions and tools and reduce the gap between the two standalone components. We build a unified and comprehensive benchmark to evaluate tool retrieval models. The extensive experiments indicate that our proposed approach achieves advanced performance in both in-domain evaluation and out-of-domain evaluation.
Continual Learning for Task-oriented Dialogue System with Iterative Network Pruning, Expanding and Masking
Jul 17, 2021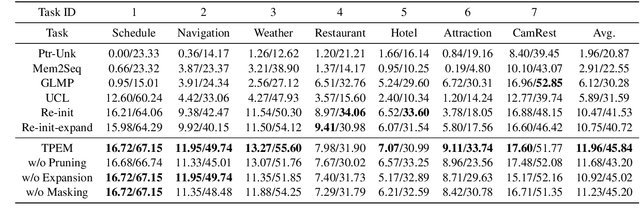
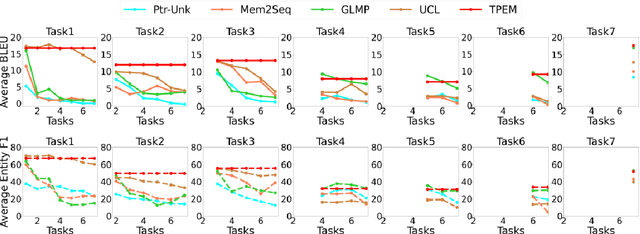
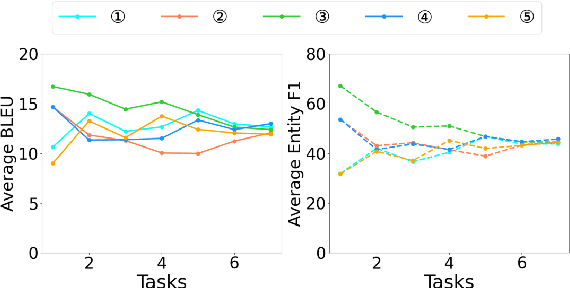
This ability to learn consecutive tasks without forgetting how to perform previously trained problems is essential for developing an online dialogue system. This paper proposes an effective continual learning for the task-oriented dialogue system with iterative network pruning, expanding and masking (TPEM), which preserves performance on previously encountered tasks while accelerating learning progress on subsequent tasks. Specifically, TPEM (i) leverages network pruning to keep the knowledge for old tasks, (ii) adopts network expanding to create free weights for new tasks, and (iii) introduces task-specific network masking to alleviate the negative impact of fixed weights of old tasks on new tasks. We conduct extensive experiments on seven different tasks from three benchmark datasets and show empirically that TPEM leads to significantly improved results over the strong competitors. For reproducibility, we submit the code and data at: https://github.com/siat-nlp/TPEM