 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoDFT: A Closed-Loop Multi-Agent Framework for Autonomous DFT Calculations
May 25, 2026Density functional theory (DFT) serves as the basis for computational discovery in materials science and chemistry, yet each calculation demands extensive human effort: adjusting algorithms when convergence stalls, revising plans when unexpected physics emerges, and inserting steps as intermediate results reshape the problem. Existing LLM-based agents automate only the initial planning stage, producing a full execution plan upfront and leaving all subsequent adaptation to hand-crafted rules. As a result, these workflows remain fragile, do not generalize well beyond pre-planned scenarios, and often require expert intervention when failures or unexpected intermediate results require changes to the calculation path. Here, we introduce AutoDFT, a closed-loop multi-agent framework that embeds LLM reasoning into every stage of the DFT lifecycle, where a strategic planner produces a skeletal plan of step objectives; a step planner generates numerical parameters just in time from preceding results; and a monitor-recover-reflect cycle diagnoses failures, repairs them, and revises the plan when the evidence justifies it. We demonstrate both breadth and depth: breadth on VASPBench, a purpose-built benchmark spanning 34 tasks and 9 DFT calculation types, where AutoDFT achieves 94.1% task-level success with GPT-5.2; and depth on established materials databases, where AutoDFT produces quantitatively reliable property predictions across electronic, magnetic, and energetic properties. By closing the loop between planning and execution, AutoDFT enables experimentalists without deep computational expertise to obtain reliable first-principles results.
MATAI: A Generalist Machine Learning Framework for Property Prediction and Inverse Design of Advanced Alloys
Nov 13, 2025



The discovery of advanced metallic alloys is hindered by vast composition spaces, competing property objectives, and real-world constraints on manufacturability. Here we introduce MATAI, a generalist machine learning framework for property prediction and inverse design of as-cast alloys. MATAI integrates a curated alloy database, deep neural network-based property predictors, a constraint-aware optimization engine, and an iterative AI-experiment feedback loop. The framework estimates key mechanical propertie, sincluding density, yield strength, ultimate tensile strength, and elongation, directly from composition, using multi-task learning and physics-informed inductive biases. Alloy design is framed as a constrained optimization problem and solved using a bi-level approach that combines local search with symbolic constraint programming. We demonstrate MATAI's capabilities on the Ti-based alloy system, a canonical class of lightweight structural materials, where it rapidly identifies candidates that simultaneously achieve lower density (<4.45 g/cm3), higher strength (>1000 MPa) and appreciable ductility (>5%) through only seven iterations. Experimental validation confirms that MATAI-designed alloys outperform commercial references such as TC4, highlighting the framework's potential to accelerate the discovery of lightweight, high-performance materials under real-world design constraints.
Let's Revise Step-by-Step: A Unified Local Search Framework for Code Generation with LLMs
Aug 10, 2025Large Language Models (LLMs) with inference-time scaling techniques show promise for code generation, yet face notable efficiency and scalability challenges. Construction-based tree-search methods suffer from rapid growth in tree size, high token consumption, and lack of anytime property. In contrast, improvement-based methods offer better performance but often struggle with uninformative reward signals and inefficient search strategies. In this work, we propose \textbf{ReLoc}, a unified local search framework which effectively performs step-by-step code revision. Specifically, ReLoc explores a series of local revisions through four key algorithmic components: initial code drafting, neighborhood code generation, candidate evaluation, and incumbent code updating, each of which can be instantiated with specific decision rules to realize different local search algorithms such as Hill Climbing (HC) or Genetic Algorithm (GA). Furthermore, we develop a specialized revision reward model that evaluates code quality based on revision distance to produce fine-grained preferences that guide the local search toward more promising candidates. Finally, our extensive experimental results demonstrate that our approach achieves superior performance across diverse code generation tasks, significantly outperforming both construction-based tree search as well as the state-of-the-art improvement-based code generation methods.
GDBA Revisited: Unleashing the Power of Guided Local Search for Distributed Constraint Optimization
Aug 09, 2025Local search is an important class of incomplete algorithms for solving Distributed Constraint Optimization Problems (DCOPs) but it often converges to poor local optima. While GDBA provides a comprehensive rule set to escape premature convergence, its empirical benefits remain marginal on general-valued problems. In this work, we systematically examine GDBA and identify three factors that potentially lead to its inferior performance, i.e., over-aggressive constraint violation conditions, unbounded penalty accumulation, and uncoordinated penalty updates. To address these issues, we propose Distributed Guided Local Search (DGLS), a novel GLS framework for DCOPs that incorporates an adaptive violation condition to selectively penalize constraints with high cost, a penalty evaporation mechanism to control the magnitude of penalization, and a synchronization scheme for coordinated penalty updates. We theoretically show that the penalty values are bounded, and agents play a potential game in our DGLS. Our extensive empirical results on various standard benchmarks demonstrate the great superiority of DGLS over state-of-the-art baselines. Particularly, compared to Damped Max-sum with high damping factors (e.g., 0.7 or 0.9), our DGLS achieves competitive performance on general-valued problems, and outperforms it by significant margins (\textbf{3.77\%--66.3\%}) on structured problems in terms of anytime results.
Nondeterministic Polynomial-time Problem Challenge: An Ever-Scaling Reasoning Benchmark for LLMs
Apr 15, 2025Reasoning is the fundamental capability of large language models (LLMs). Due to the rapid progress of LLMs, there are two main issues of current benchmarks: i) these benchmarks can be crushed in a short time (less than 1 year), and ii) these benchmarks may be easily hacked. To handle these issues, we propose the ever-scalingness for building the benchmarks which are uncrushable, unhackable, auto-verifiable and general. This paper presents Nondeterministic Polynomial-time Problem Challenge (NPPC), an ever-scaling reasoning benchmark for LLMs. Specifically, the NPPC has three main modules: i) npgym, which provides a unified interface of 25 well-known NP-complete problems and can generate any number of instances with any levels of complexities, ii) npsolver: which provides a unified interface to evaluate the problem instances with both online and offline models via APIs and local deployments, respectively, and iii) npeval: which provides the comprehensive and ready-to-use tools to analyze the performances of LLMs over different problems, the number of tokens, the aha moments, the reasoning errors and the solution errors. Extensive experiments over widely-used LLMs demonstrate: i) NPPC can successfully decrease the performances of advanced LLMs' performances to below 10%, demonstrating that NPPC is uncrushable, ii) DeepSeek-R1, Claude-3.7-Sonnet, and o1/o3-mini are the most powerful LLMs, where DeepSeek-R1 outperforms Claude-3.7-Sonnet and o1/o3-mini in most NP-complete problems considered, and iii) the numbers of tokens, aha moments in the advanced LLMs, e.g., Claude-3.7-Sonnet and DeepSeek-R1, are observed first to increase and then decrease when the problem instances become more and more difficult. We believe that NPPC is the first ever-scaling reasoning benchmark, serving as the uncrushable and unhackable testbed for LLMs toward artificial general intelligence (AGI).
Q*: Improving Multi-step Reasoning for LLMs with Deliberative Planning
Jun 20, 2024



Large Language Models (LLMs) have demonstrated impressive capability in many nature language tasks. However, the auto-regressive generation process makes LLMs prone to produce errors, hallucinations and inconsistent statements when performing multi-step reasoning. In this paper, we aim to alleviate the pathology by introducing Q*, a general, versatile and agile framework for guiding LLMs decoding process with deliberative planning. By learning a plug-and-play Q-value model as heuristic function, our Q* can effectively guide LLMs to select the most promising next step without fine-tuning LLMs for each task, which avoids the significant computational overhead and potential risk of performance degeneration on other tasks. Extensive experiments on GSM8K, MATH and MBPP confirm the superiority of our method.
Deep Attentive Belief Propagation: Integrating Reasoning and Learning for Solving Constraint Optimization Problems
Sep 24, 2022
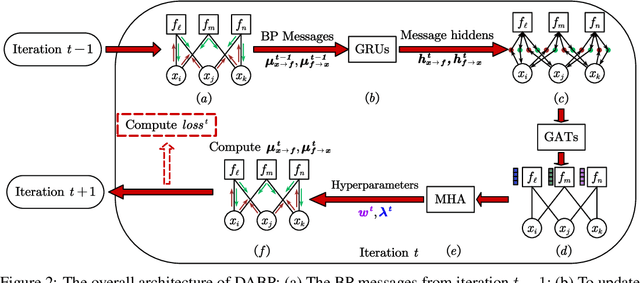
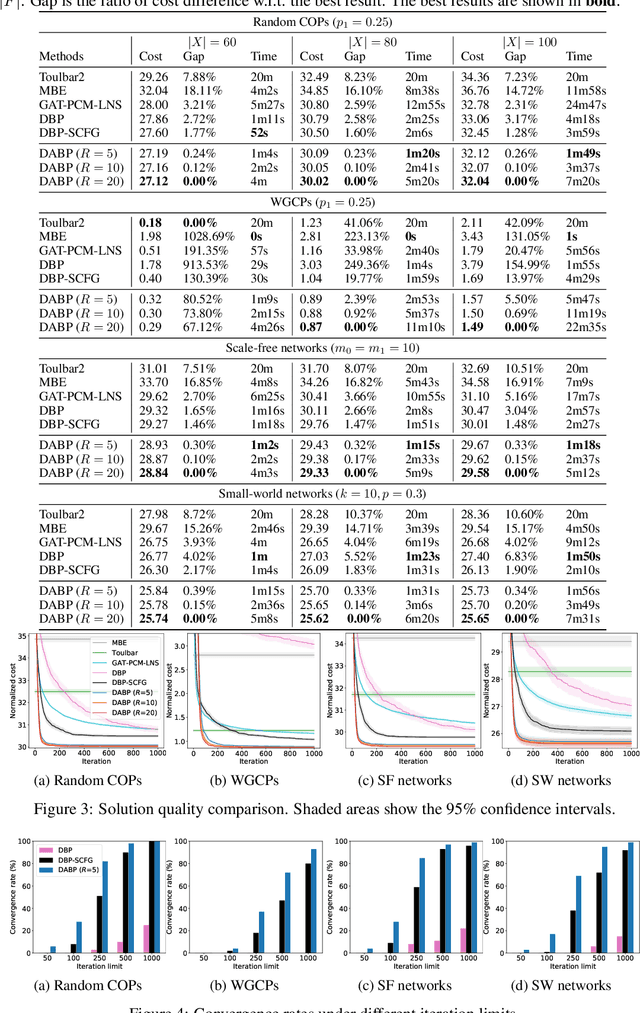
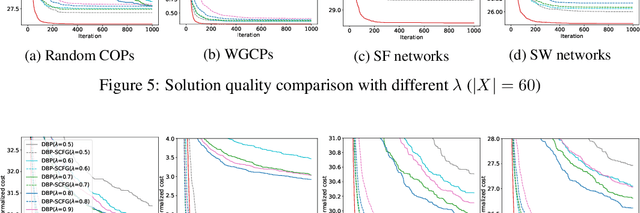
Belief Propagation (BP) is an important message-passing algorithm for various reasoning tasks over graphical models, including solving the Constraint Optimization Problems (COPs). It has been shown that BP can achieve state-of-the-art performance on various benchmarks by mixing old and new messages before sending the new one, i.e., damping. However, existing methods of tuning a static damping factor for BP not only are laborious but also harm their performance. Moreover, existing BP algorithms treat each variable node's neighbors equally when composing a new message, which also limits their exploration ability. To address these issues, we seamlessly integrate BP, Gated Recurrent Units (GRUs), and Graph Attention Networks (GATs) within the message-passing framework to reason about dynamic weights and damping factors for composing new BP messages. Our model, Deep Attentive Belief Propagation (DABP), takes the factor graph and the BP messages in each iteration as the input and infers the optimal weights and damping factors through GRUs and GATs, followed by a multi-head attention layer. Furthermore, unlike existing neural-based BP variants, we propose a novel self-supervised learning algorithm for DABP with a smoothed solution cost, which does not require expensive training labels and also avoids the common out-of-distribution issue through efficient online learning. Extensive experiments show that our model significantly outperforms state-of-the-art baselines.
Pretrained Cost Model for Distributed Constraint Optimization Problems
Dec 15, 2021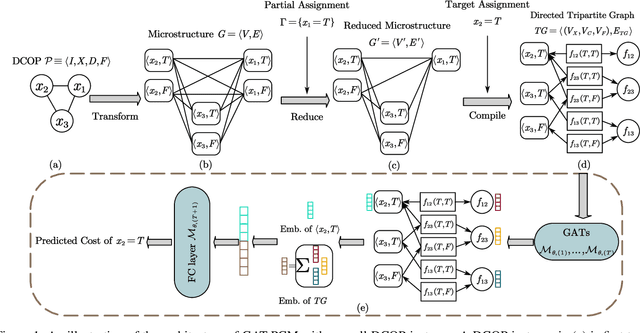
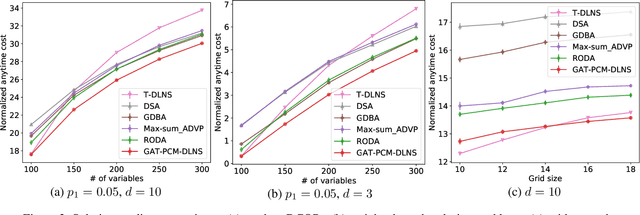
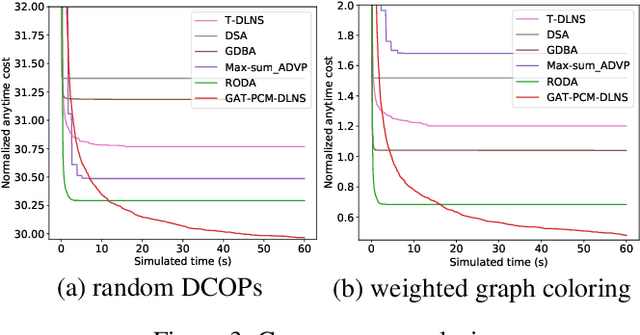
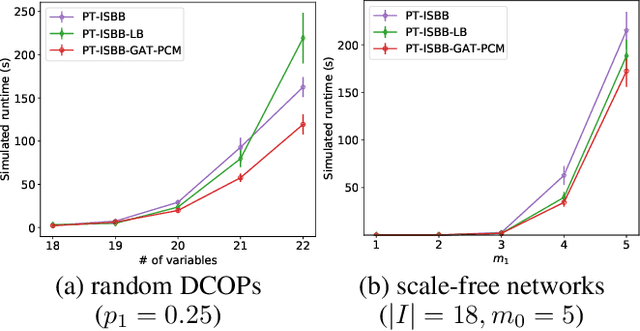
Distributed Constraint Optimization Problems (DCOPs) are an important subclass of combinatorial optimization problems, where information and controls are distributed among multiple autonomous agents. Previously, Machine Learning (ML) has been largely applied to solve combinatorial optimization problems by learning effective heuristics. However, existing ML-based heuristic methods are often not generalizable to different search algorithms. Most importantly, these methods usually require full knowledge about the problems to be solved, which are not suitable for distributed settings where centralization is not realistic due to geographical limitations or privacy concerns. To address the generality issue, we propose a novel directed acyclic graph representation schema for DCOPs and leverage the Graph Attention Networks (GATs) to embed graph representations. Our model, GAT-PCM, is then pretrained with optimally labelled data in an offline manner, so as to construct effective heuristics to boost a broad range of DCOP algorithms where evaluating the quality of a partial assignment is critical, such as local search or backtracking search. Furthermore, to enable decentralized model inference, we propose a distributed embedding schema of GAT-PCM where each agent exchanges only embedded vectors, and show its soundness and complexity. Finally, we demonstrate the effectiveness of our model by combining it with a local search or a backtracking search algorithm. Extensive empirical evaluations indicate that the GAT-PCM-boosted algorithms significantly outperform the state-of-the-art methods in various benchmarks. The pretrained model is available at https://github.com/dyc941126/GAT-PCM.