 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering
Sep 20, 2022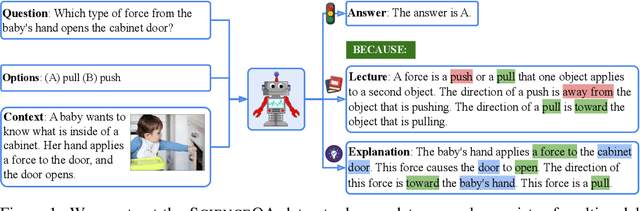
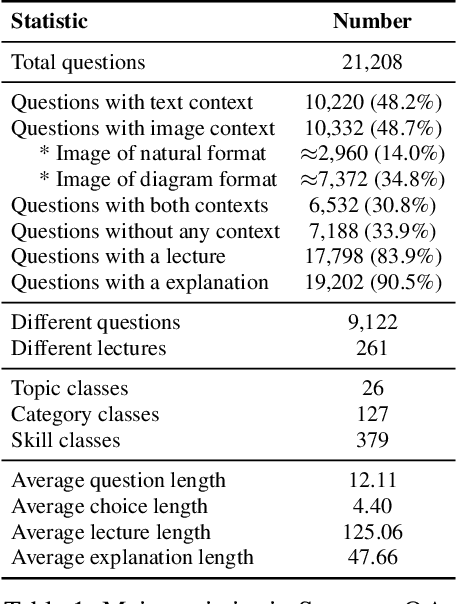
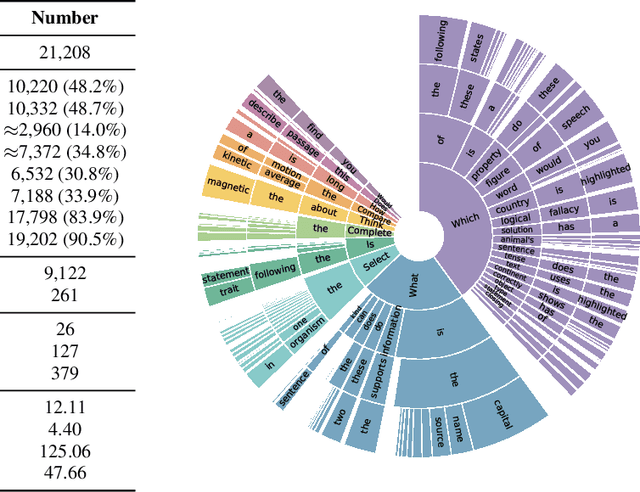
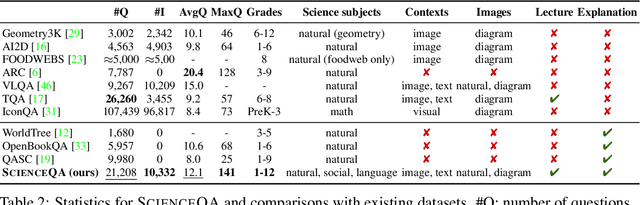
When answering a question, humans utilize the information available across different modalities to synthesize a consistent and complete chain of thought (CoT). This process is normally a black box in the case of deep learning models like large-scale language models. Recently, science question benchmarks have been used to diagnose the multi-hop reasoning ability and interpretability of an AI system. However, existing datasets fail to provide annotations for the answers, or are restricted to the textual-only modality, small scales, and limited domain diversity. To this end, we present Science Question Answering (SQA), a new benchmark that consists of ~21k multimodal multiple choice questions with a diverse set of science topics and annotations of their answers with corresponding lectures and explanations. We further design language models to learn to generate lectures and explanations as the chain of thought (CoT) to mimic the multi-hop reasoning process when answering SQA questions. SQA demonstrates the utility of CoT in language models, as CoT improves the question answering performance by 1.20% in few-shot GPT-3 and 3.99% in fine-tuned UnifiedQA. We also explore the upper bound for models to leverage explanations by feeding those in the input; we observe that it improves the few-shot performance of GPT-3 by 18.96%. Our analysis further shows that language models, similar to humans, benefit from explanations to learn from fewer data and achieve the same performance with just 40% of the data.
Sequential Manipulation Planning on Scene Graph
Jul 17, 2022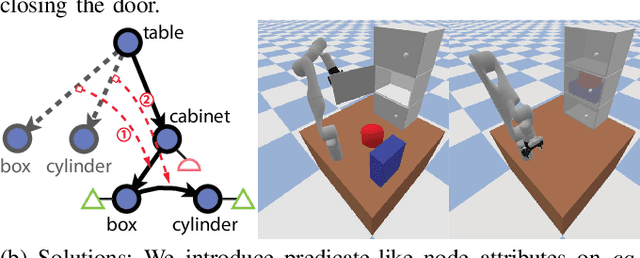
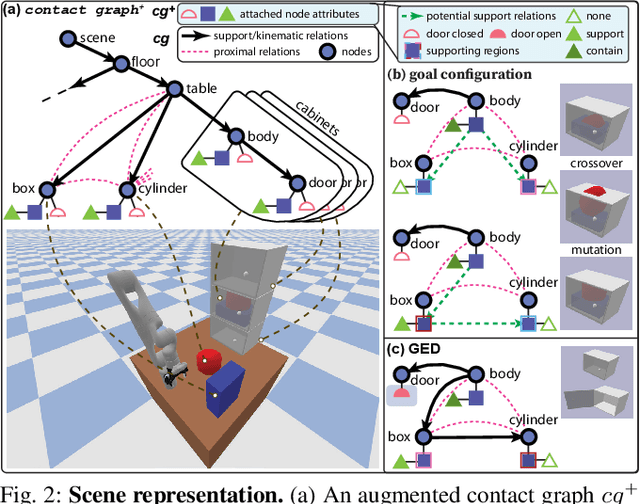
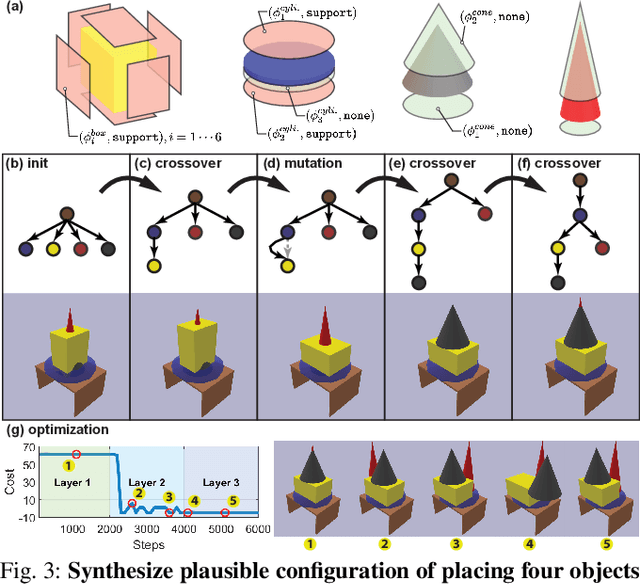
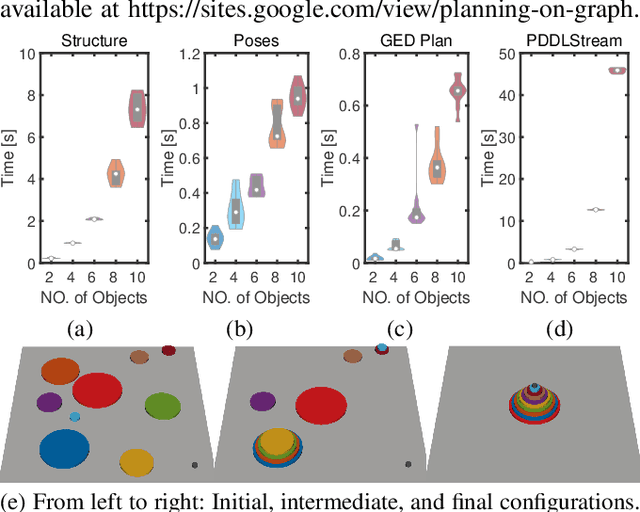
We devise a 3D scene graph representation, contact graph+ (cg+), for efficient sequential task planning. Augmented with predicate-like attributes, this contact graph-based representation abstracts scene layouts with succinct geometric information and valid robot-scene interactions. Goal configurations, naturally specified on contact graphs, can be produced by a genetic algorithm with a stochastic optimization method. A task plan is then initialized by computing the Graph Editing Distance (GED) between the initial contact graphs and the goal configurations, which generates graph edit operations corresponding to possible robot actions. We finalize the task plan by imposing constraints to regulate the temporal feasibility of graph edit operations, ensuring valid task and motion correspondences. In a series of simulations and experiments, robots successfully complete complex sequential object rearrangement tasks that are difficult to specify using conventional planning language like Planning Domain Definition Language (PDDL), demonstrating the high feasibility and potential of robot sequential task planning on contact graph.
Understanding Physical Effects for Effective Tool-use
Jun 30, 2022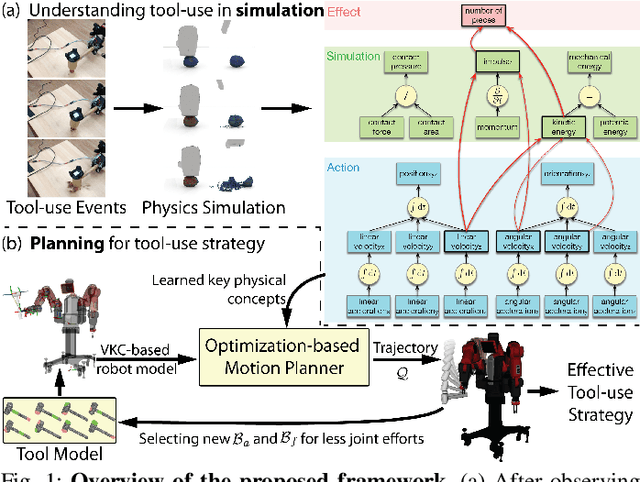
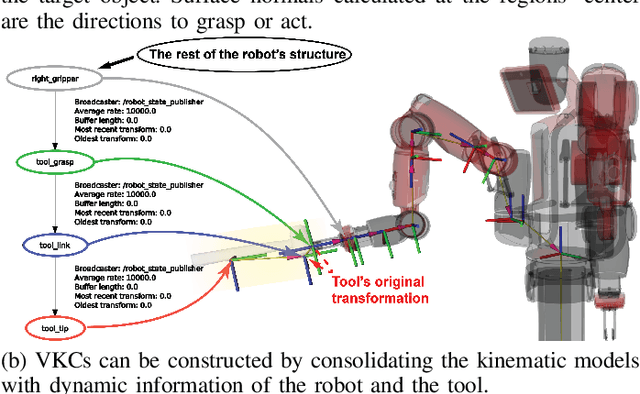

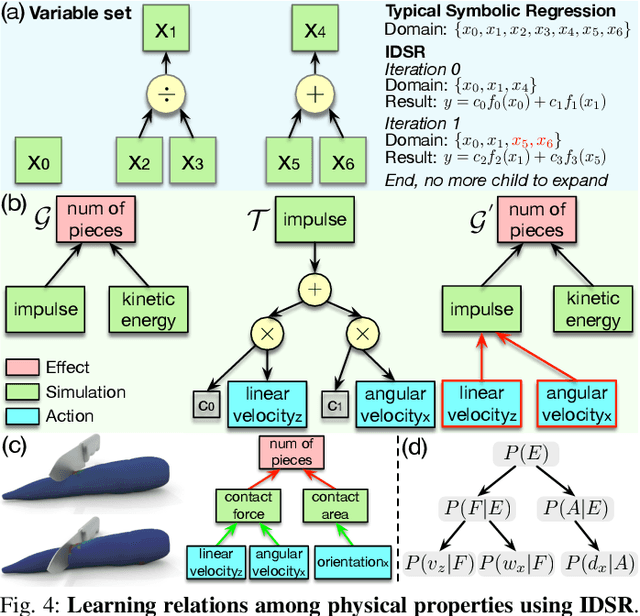
We present a robot learning and planning framework that produces an effective tool-use strategy with the least joint efforts, capable of handling objects different from training. Leveraging a Finite Element Method (FEM)-based simulator that reproduces fine-grained, continuous visual and physical effects given observed tool-use events, the essential physical properties contributing to the effects are identified through the proposed Iterative Deepening Symbolic Regression (IDSR) algorithm. We further devise an optimal control-based motion planning scheme to integrate robot- and tool-specific kinematics and dynamics to produce an effective trajectory that enacts the learned properties. In simulation, we demonstrate that the proposed framework can produce more effective tool-use strategies, drastically different from the observed ones in two exemplar tasks.
VRKitchen2.0-IndoorKit: A Tutorial for Augmented Indoor Scene Building in Omniverse
Jun 23, 2022

With the recent progress of simulations by 3D modeling software and game engines, many researchers have focused on Embodied AI tasks in the virtual environment. However, the research community lacks a platform that can easily serve both indoor scene synthesis and model benchmarking with various algorithms. Meanwhile, computer graphics-related tasks need a toolkit for implementing advanced synthesizing techniques. To facilitate the study of indoor scene building methods and their potential robotics applications, we introduce INDOORKIT: a built-in toolkit for NVIDIA OMNIVERSE that provides flexible pipelines for indoor scene building, scene randomizing, and animation controls. Besides, combining Python coding in the animation software INDOORKIT assists researchers in creating real-time training and controlling avatars and robotics. The source code for this toolkit is available at https://github.com/realvcla/VRKitchen2.0-Tutorial, and the tutorial along with the toolkit is available at https://vrkitchen20-tutorial.readthedocs.io/en/
EST: Evaluating Scientific Thinking in Artificial Agents
Jun 18, 2022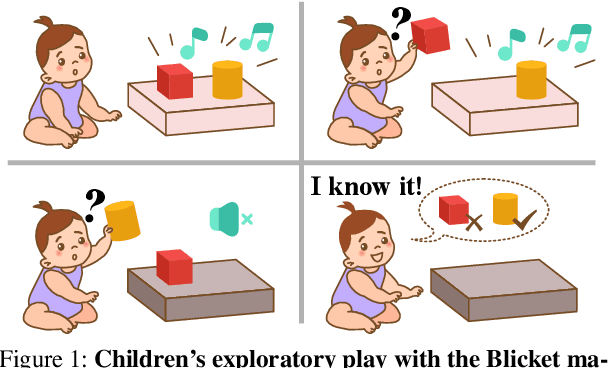

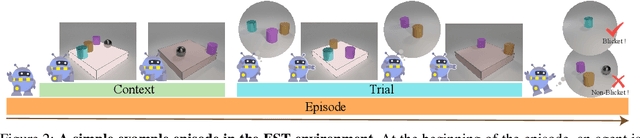
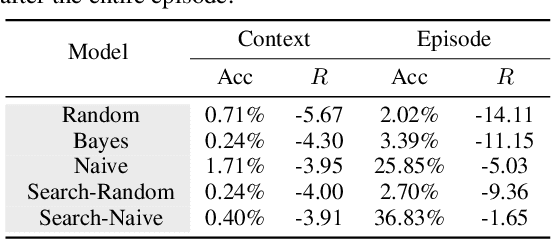
Theoretical ideas and empirical research have shown us a seemingly surprising result: children, even very young toddlers, demonstrate learning and thinking in a strikingly similar manner to scientific reasoning in formal research. Encountering a novel phenomenon, children make hypotheses against data, conduct causal inference from observation, test their theory via experimentation, and correct the proposition if inconsistency arises. Rounds of such processes continue until the underlying mechanism is found. Towards building machines that can learn and think like people, one natural question for us to ask is: whether the intelligence we achieve today manages to perform such a scientific thinking process, and if any, at what level. In this work, we devise the EST environment for evaluating the scientific thinking ability in artificial agents. Motivated by the stream of research on causal discovery, we build our interactive EST environment based on Blicket detection. Specifically, in each episode of EST, an agent is presented with novel observations and asked to figure out all objects' Blicketness. At each time step, the agent proposes new experiments to validate its hypothesis and updates its current belief. By evaluating Reinforcement Learning (RL) agents on both a symbolic and visual version of this task, we notice clear failure of today's learning methods in reaching a level of intelligence comparable to humans. Such inefficacy of learning in scientific thinking calls for future research in building humanlike intelligence.
Towards Human-Level Bimanual Dexterous Manipulation with Reinforcement Learning
Jun 17, 2022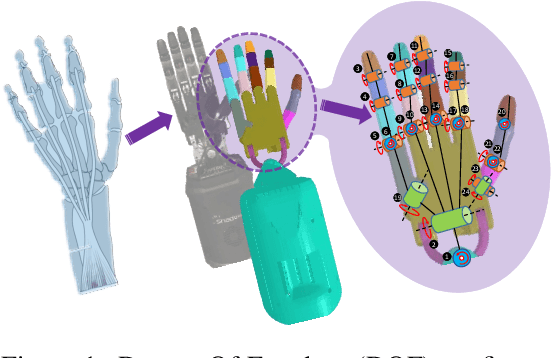
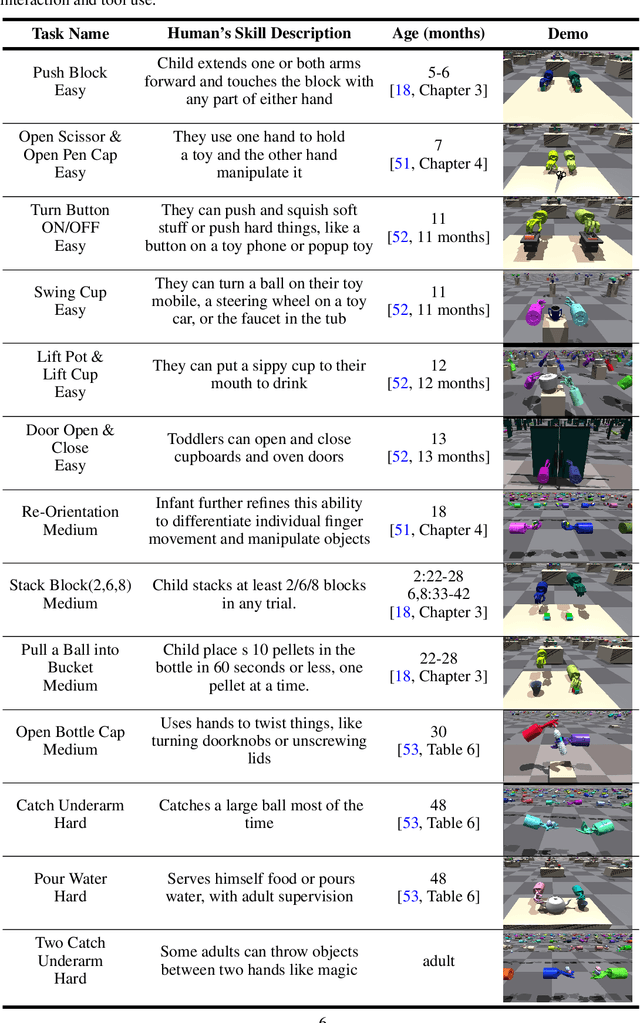


Achieving human-level dexterity is an important open problem in robotics. However, tasks of dexterous hand manipulation, even at the baby level, are challenging to solve through reinforcement learning (RL). The difficulty lies in the high degrees of freedom and the required cooperation among heterogeneous agents (e.g., joints of fingers). In this study, we propose the Bimanual Dexterous Hands Benchmark (Bi-DexHands), a simulator that involves two dexterous hands with tens of bimanual manipulation tasks and thousands of target objects. Specifically, tasks in Bi-DexHands are designed to match different levels of human motor skills according to cognitive science literature. We built Bi-DexHands in the Issac Gym; this enables highly efficient RL training, reaching 30,000+ FPS by only one single NVIDIA RTX 3090. We provide a comprehensive benchmark for popular RL algorithms under different settings; this includes Single-agent/Multi-agent RL, Offline RL, Multi-task RL, and Meta RL. Our results show that the PPO type of on-policy algorithms can master simple manipulation tasks that are equivalent up to 48-month human babies (e.g., catching a flying object, opening a bottle), while multi-agent RL can further help to master manipulations that require skilled bimanual cooperation (e.g., lifting a pot, stacking blocks). Despite the success on each single task, when it comes to acquiring multiple manipulation skills, existing RL algorithms fail to work in most of the multi-task and the few-shot learning settings, which calls for more substantial development from the RL community. Our project is open sourced at https://github.com/PKU-MARL/DexterousHands.
Latent Diffusion Energy-Based Model for Interpretable Text Modeling
Jun 14, 2022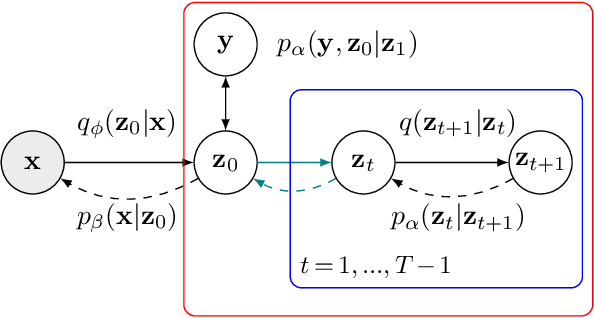
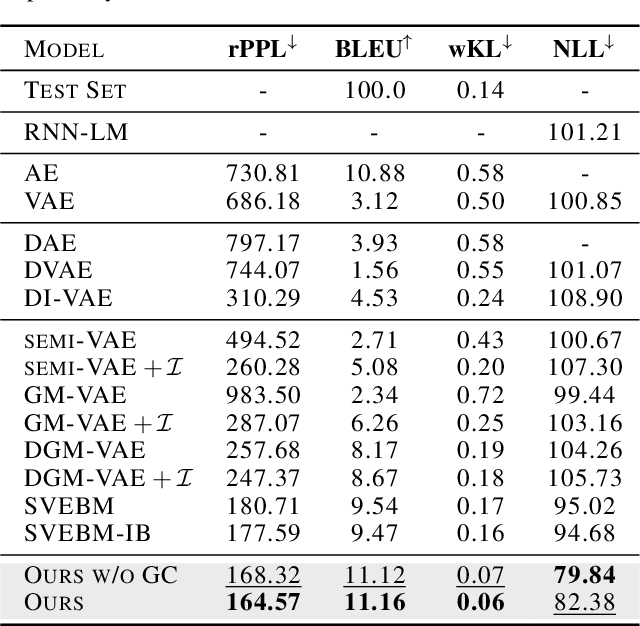
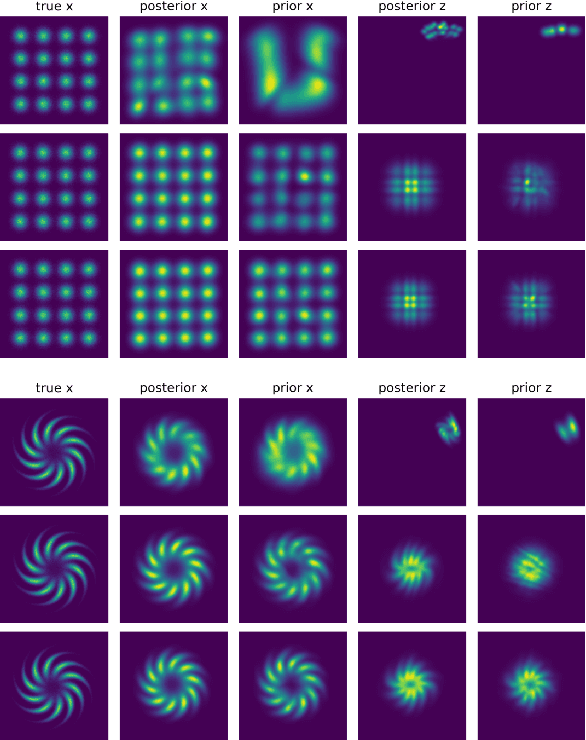

Latent space Energy-Based Models (EBMs), also known as energy-based priors, have drawn growing interests in generative modeling. Fueled by its flexibility in the formulation and strong modeling power of the latent space, recent works built upon it have made interesting attempts aiming at the interpretability of text modeling. However, latent space EBMs also inherit some flaws from EBMs in data space; the degenerate MCMC sampling quality in practice can lead to poor generation quality and instability in training, especially on data with complex latent structures. Inspired by the recent efforts that leverage diffusion recovery likelihood learning as a cure for the sampling issue, we introduce a novel symbiosis between the diffusion models and latent space EBMs in a variational learning framework, coined as the latent diffusion energy-based model. We develop a geometric clustering-based regularization jointly with the information bottleneck to further improve the quality of the learned latent space. Experiments on several challenging tasks demonstrate the superior performance of our model on interpretable text modeling over strong counterparts.
EBM Life Cycle: MCMC Strategies for Synthesis, Defense, and Density Modeling
May 24, 2022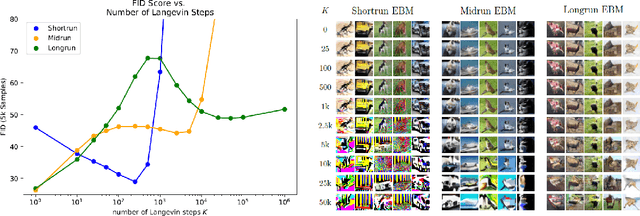

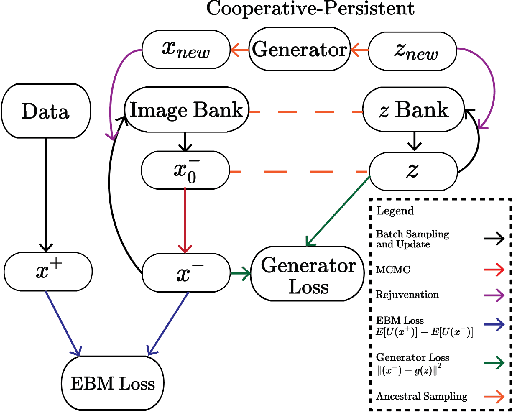
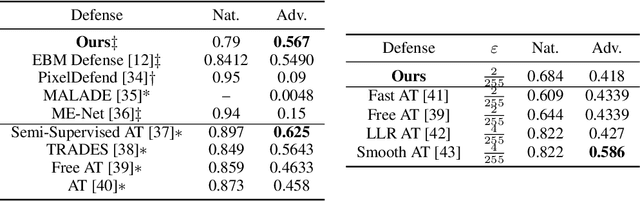
This work presents strategies to learn an Energy-Based Model (EBM) according to the desired length of its MCMC sampling trajectories. MCMC trajectories of different lengths correspond to models with different purposes. Our experiments cover three different trajectory magnitudes and learning outcomes: 1) shortrun sampling for image generation; 2) midrun sampling for classifier-agnostic adversarial defense; and 3) longrun sampling for principled modeling of image probability densities. To achieve these outcomes, we introduce three novel methods of MCMC initialization for negative samples used in Maximum Likelihood (ML) learning. With standard network architectures and an unaltered ML objective, our MCMC initialization methods alone enable significant performance gains across the three applications that we investigate. Our results include state-of-the-art FID scores for unnormalized image densities on the CIFAR-10 and ImageNet datasets; state-of-the-art adversarial defense on CIFAR-10 among purification methods and the first EBM defense on ImageNet; and scalable techniques for learning valid probability densities. Code for this project can be found at https://github.com/point0bar1/ebm-life-cycle.
RelViT: Concept-guided Vision Transformer for Visual Relational Reasoning
Apr 24, 2022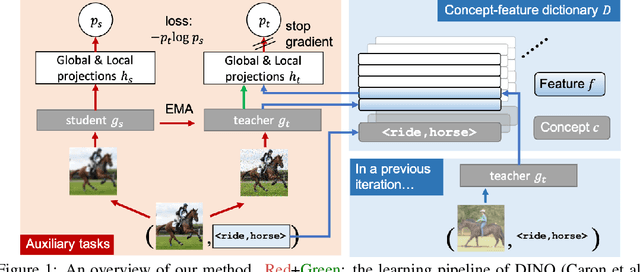
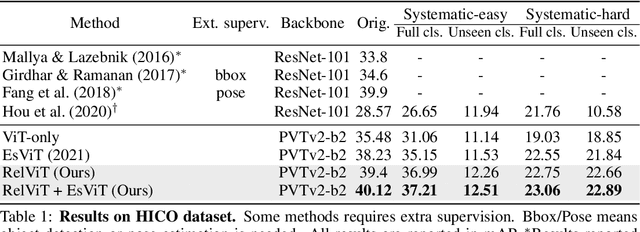
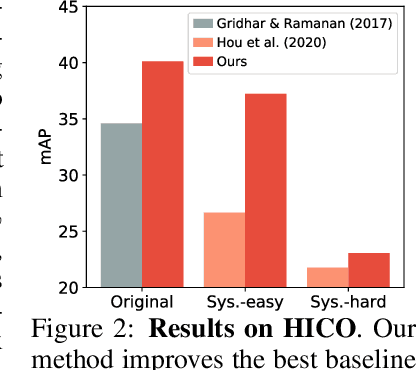

Reasoning about visual relationships is central to how humans interpret the visual world. This task remains challenging for current deep learning algorithms since it requires addressing three key technical problems jointly: 1) identifying object entities and their properties, 2) inferring semantic relations between pairs of entities, and 3) generalizing to novel object-relation combinations, i.e., systematic generalization. In this work, we use vision transformers (ViTs) as our base model for visual reasoning and make better use of concepts defined as object entities and their relations to improve the reasoning ability of ViTs. Specifically, we introduce a novel concept-feature dictionary to allow flexible image feature retrieval at training time with concept keys. This dictionary enables two new concept-guided auxiliary tasks: 1) a global task for promoting relational reasoning, and 2) a local task for facilitating semantic object-centric correspondence learning. To examine the systematic generalization of visual reasoning models, we introduce systematic splits for the standard HICO and GQA benchmarks. We show the resulting model, Concept-guided Vision Transformer (or RelViT for short) significantly outperforms prior approaches on HICO and GQA by 16% and 13% in the original split, and by 43% and 18% in the systematic split. Our ablation analyses also reveal our model's compatibility with multiple ViT variants and robustness to hyper-parameters.
Triangular Character Animation Sampling with Motion, Emotion, and Relation
Mar 09, 2022
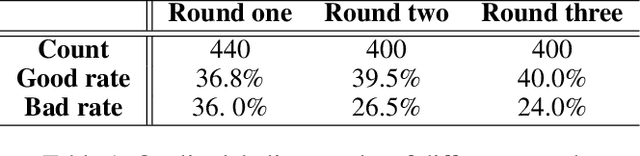
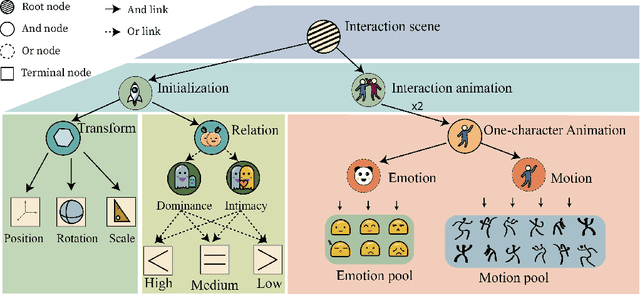

Dramatic progress has been made in animating individual characters. However, we still lack automatic control over activities between characters, especially those involving interactions. In this paper, we present a novel energy-based framework to sample and synthesize animations by associating the characters' body motions, facial expressions, and social relations. We propose a Spatial-Temporal And-Or graph (ST-AOG), a stochastic grammar model, to encode the contextual relationship between motion, emotion, and relation, forming a triangle in a conditional random field. We train our model from a labeled dataset of two-character interactions. Experiments demonstrate that our method can recognize the social relation between two characters and sample new scenes of vivid motion and emotion using Markov Chain Monte Carlo (MCMC) given the social relation. Thus, our method can provide animators with an automatic way to generate 3D character animations, help synthesize interactions between Non-Player Characters (NPCs), and enhance machine emotion intelligence (EQ) in virtual reality (VR).