 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Trajectory Generation for Whole-Body Mobile Manipulation
Apr 14, 2026Robots deployed in unstructured environments must coordinate whole-body motion -- simultaneously moving a mobile base and arm -- to interact with the physical world. This coupled mobility and dexterity yields a state space that grows combinatorially with scene and object diversity, demanding datasets far larger than those sufficient for fixed-base manipulation. Yet existing acquisition methods, including teleoperation and planning, are either labor-intensive or computationally prohibitive at scale. The core bottleneck is the lack of a scalable pipeline for generating large-scale, physically valid, coordinated trajectory data across diverse embodiments and environments. Here we introduce AutoMoMa, a GPU-accelerated framework that unifies AKR modeling, which consolidates base, arm, and object kinematics into a single chain, with parallelized trajectory optimization. AutoMoMa achieves 5,000 episodes per GPU-hour (over $80\times$ faster than CPU-based baselines), producing a dataset of over 500k physically valid trajectories spanning 330 scenes, diverse articulated objects, and multiple robot embodiments. Prior datasets were forced to compromise on scale, diversity, or kinematic fidelity; AutoMoMa addresses all three simultaneously. Training downstream IL policies further reveals that even a single articulated-object task requires tens of thousands of demonstrations for SOTA methods to reach $\approx 80\%$ success, confirming that data scarcity -- not algorithmic limitations -- has been the binding constraint. AutoMoMa thus bridges high-performance planning and reliable IL-based control, providing the infrastructure previously missing for coordinated mobile manipulation research. By making large-scale, kinematically valid training data practical, AutoMoMa showcases generalizable whole-body robot policies capable of operating in the diverse, unstructured settings of the real world.
Integrated Exploration and Sequential Manipulation on Scene Graph with LLM-based Situated Replanning
Feb 04, 2026In partially known environments, robots must combine exploration to gather information with task planning for efficient execution. To address this challenge, we propose EPoG, an Exploration-based sequential manipulation Planning framework on Scene Graphs. EPoG integrates a graph-based global planner with a Large Language Model (LLM)-based situated local planner, continuously updating a belief graph using observations and LLM predictions to represent known and unknown objects. Action sequences are generated by computing graph edit operations between the goal and belief graphs, ordered by temporal dependencies and movement costs. This approach seamlessly combines exploration and sequential manipulation planning. In ablation studies across 46 realistic household scenes and 5 long-horizon daily object transportation tasks, EPoG achieved a success rate of 91.3%, reducing travel distance by 36.1% on average. Furthermore, a physical mobile manipulator successfully executed complex tasks in unknown and dynamic environments, demonstrating EPoG's potential for real-world applications.
Dynamic Planning for Sequential Whole-body Mobile Manipulation
May 24, 2024



The dynamic Sequential Mobile Manipulation Planning (SMMP) framework is essential for the safe and robust operation of mobile manipulators in dynamic environments. Previous research has primarily focused on either motion-level or task-level dynamic planning, with limitations in handling state changes that have long-term effects or in generating responsive motions for diverse tasks, respectively. This paper presents a holistic dynamic planning framework that extends the Virtual Kinematic Chain (VKC)-based SMMP method, automating dynamic long-term task planning and reactive whole-body motion generation for SMMP problems. The framework consists of an online task planning module designed to respond to environment changes with long-term effects, a VKC-based whole-body motion planning module for manipulating both rigid and articulated objects, alongside a reactive Model Predictive Control (MPC) module for obstacle avoidance during execution. Simulations and real-world experiments validate the framework, demonstrating its efficacy and validity across sequential mobile manipulation tasks, even in scenarios involving human interference.
Sequential Manipulation Planning on Scene Graph
Jul 17, 2022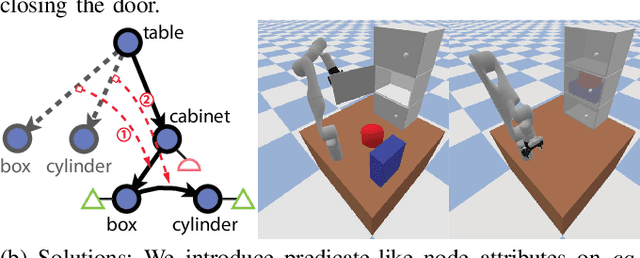
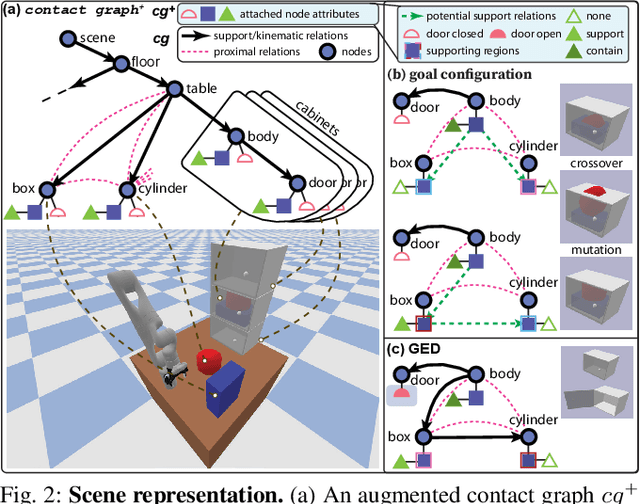
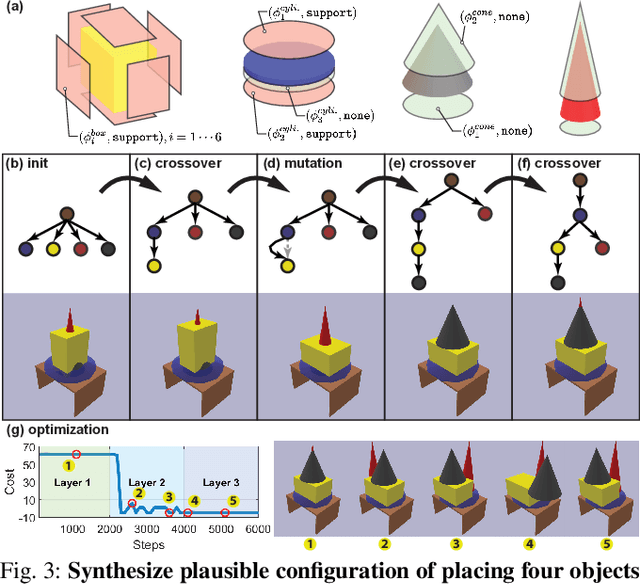
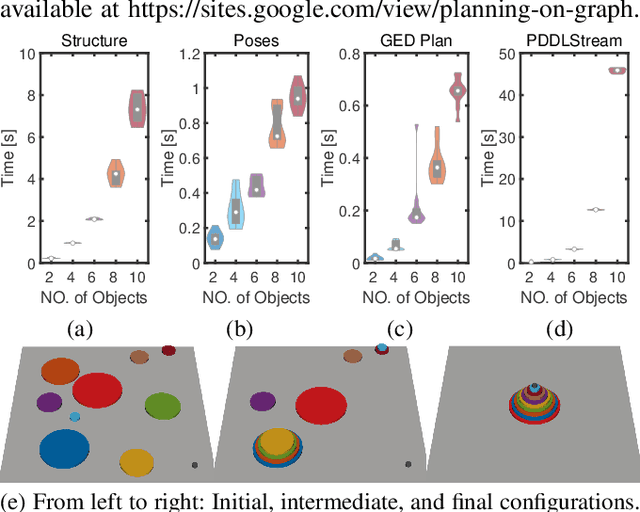
We devise a 3D scene graph representation, contact graph+ (cg+), for efficient sequential task planning. Augmented with predicate-like attributes, this contact graph-based representation abstracts scene layouts with succinct geometric information and valid robot-scene interactions. Goal configurations, naturally specified on contact graphs, can be produced by a genetic algorithm with a stochastic optimization method. A task plan is then initialized by computing the Graph Editing Distance (GED) between the initial contact graphs and the goal configurations, which generates graph edit operations corresponding to possible robot actions. We finalize the task plan by imposing constraints to regulate the temporal feasibility of graph edit operations, ensuring valid task and motion correspondences. In a series of simulations and experiments, robots successfully complete complex sequential object rearrangement tasks that are difficult to specify using conventional planning language like Planning Domain Definition Language (PDDL), demonstrating the high feasibility and potential of robot sequential task planning on contact graph.