 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergence of Theory of Mind Collaboration in Multiagent Systems
Sep 30, 2021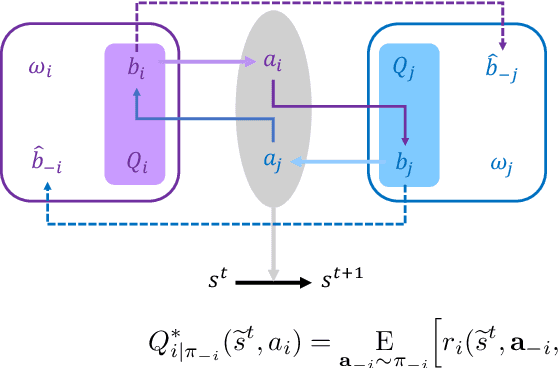

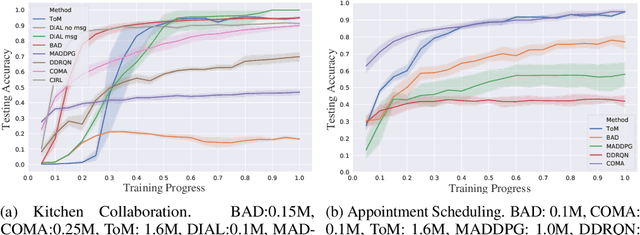
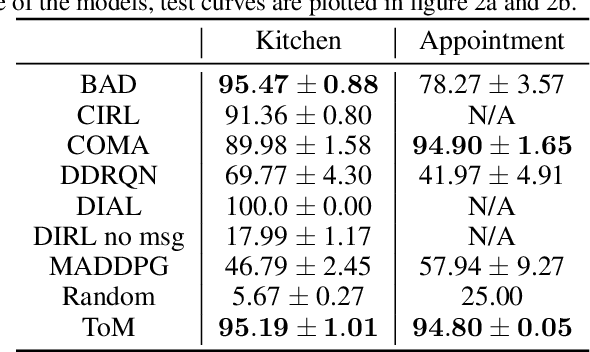
Currently, in the study of multiagent systems, the intentions of agents are usually ignored. Nonetheless, as pointed out by Theory of Mind (ToM), people regularly reason about other's mental states, including beliefs, goals, and intentions, to obtain performance advantage in competition, cooperation or coalition. However, due to its intrinsic recursion and intractable modeling of distribution over belief, integrating ToM in multiagent planning and decision making is still a challenge. In this paper, we incorporate ToM in multiagent partially observable Markov decision process (POMDP) and propose an adaptive training algorithm to develop effective collaboration between agents with ToM. We evaluate our algorithms with two games, where our algorithm surpasses all previous decentralized execution algorithms without modeling ToM.
YouRefIt: Embodied Reference Understanding with Language and Gesture
Sep 15, 2021
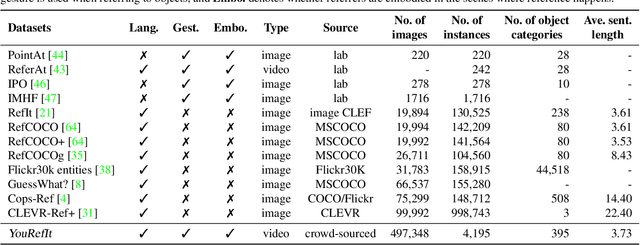

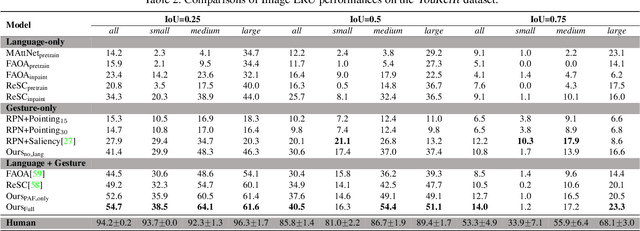
We study the understanding of embodied reference: One agent uses both language and gesture to refer to an object to another agent in a shared physical environment. Of note, this new visual task requires understanding multimodal cues with perspective-taking to identify which object is being referred to. To tackle this problem, we introduce YouRefIt, a new crowd-sourced dataset of embodied reference collected in various physical scenes; the dataset contains 4,195 unique reference clips in 432 indoor scenes. To the best of our knowledge, this is the first embodied reference dataset that allows us to study referring expressions in daily physical scenes to understand referential behavior, human communication, and human-robot interaction. We further devise two benchmarks for image-based and video-based embodied reference understanding. Comprehensive baselines and extensive experiments provide the very first result of machine perception on how the referring expressions and gestures affect the embodied reference understanding. Our results provide essential evidence that gestural cues are as critical as language cues in understanding the embodied reference.
CX-ToM: Counterfactual Explanations with Theory-of-Mind for Enhancing Human Trust in Image Recognition Models
Sep 06, 2021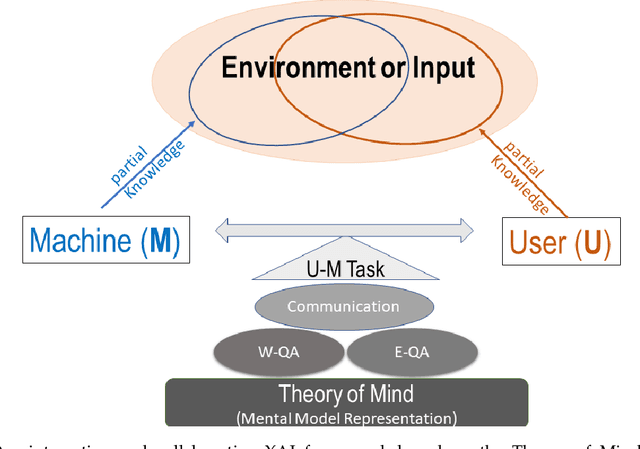
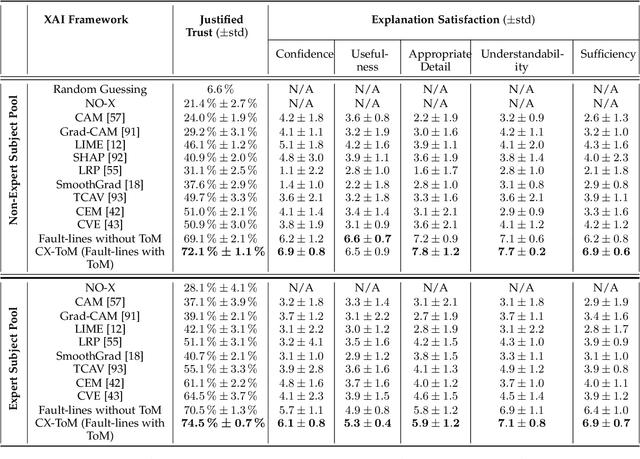
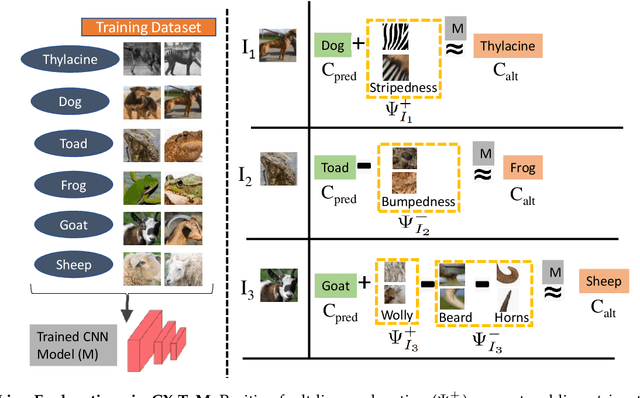
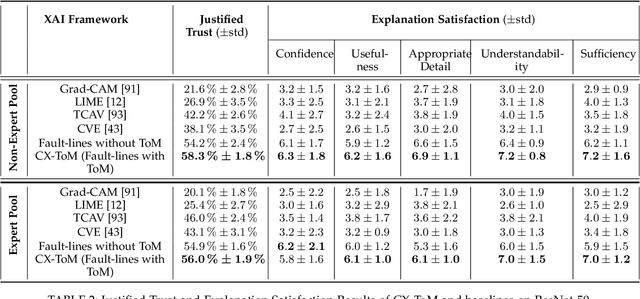
We propose CX-ToM, short for counterfactual explanations with theory-of mind, a new explainable AI (XAI) framework for explaining decisions made by a deep convolutional neural network (CNN). In contrast to the current methods in XAI that generate explanations as a single shot response, we pose explanation as an iterative communication process, i.e. dialog, between the machine and human user. More concretely, our CX-ToM framework generates sequence of explanations in a dialog by mediating the differences between the minds of machine and human user. To do this, we use Theory of Mind (ToM) which helps us in explicitly modeling human's intention, machine's mind as inferred by the human as well as human's mind as inferred by the machine. Moreover, most state-of-the-art XAI frameworks provide attention (or heat map) based explanations. In our work, we show that these attention based explanations are not sufficient for increasing human trust in the underlying CNN model. In CX-ToM, we instead use counterfactual explanations called fault-lines which we define as follows: given an input image I for which a CNN classification model M predicts class c_pred, a fault-line identifies the minimal semantic-level features (e.g., stripes on zebra, pointed ears of dog), referred to as explainable concepts, that need to be added to or deleted from I in order to alter the classification category of I by M to another specified class c_alt. We argue that, due to the iterative, conceptual and counterfactual nature of CX-ToM explanations, our framework is practical and more natural for both expert and non-expert users to understand the internal workings of complex deep learning models. Extensive quantitative and qualitative experiments verify our hypotheses, demonstrating that our CX-ToM significantly outperforms the state-of-the-art explainable AI models.
Spatio-temporal Self-Supervised Representation Learning for 3D Point Clouds
Sep 01, 2021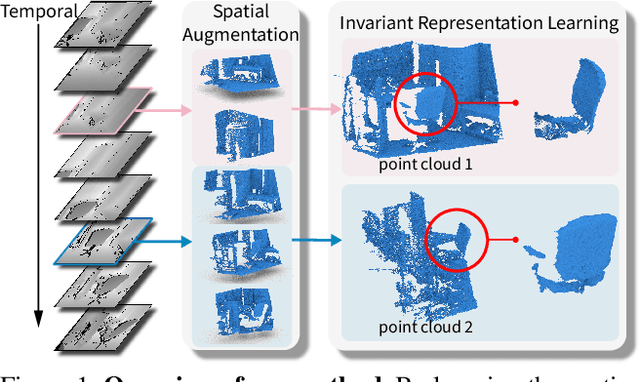
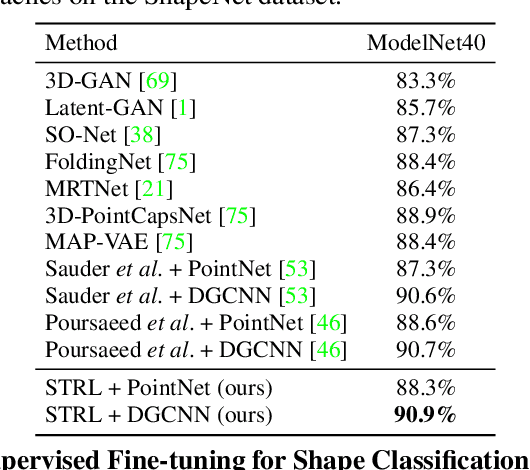
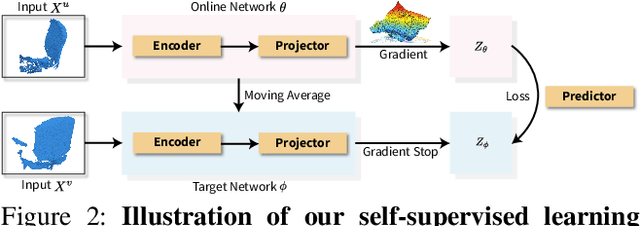
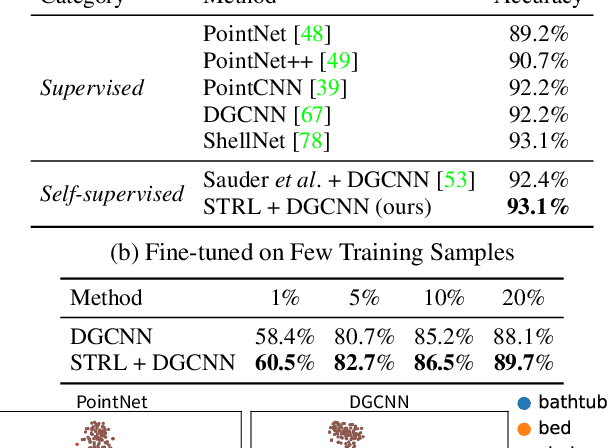
To date, various 3D scene understanding tasks still lack practical and generalizable pre-trained models, primarily due to the intricate nature of 3D scene understanding tasks and their immense variations introduced by camera views, lighting, occlusions, etc. In this paper, we tackle this challenge by introducing a spatio-temporal representation learning (STRL) framework, capable of learning from unlabeled 3D point clouds in a self-supervised fashion. Inspired by how infants learn from visual data in the wild, we explore the rich spatio-temporal cues derived from the 3D data. Specifically, STRL takes two temporally-correlated frames from a 3D point cloud sequence as the input, transforms it with the spatial data augmentation, and learns the invariant representation self-supervisedly. To corroborate the efficacy of STRL, we conduct extensive experiments on three types (synthetic, indoor, and outdoor) of datasets. Experimental results demonstrate that, compared with supervised learning methods, the learned self-supervised representation facilitates various models to attain comparable or even better performances while capable of generalizing pre-trained models to downstream tasks, including 3D shape classification, 3D object detection, and 3D semantic segmentation. Moreover, the spatio-temporal contextual cues embedded in 3D point clouds significantly improve the learned representations.
Consolidating Kinematic Models to Promote Coordinated Mobile Manipulations
Aug 10, 2021
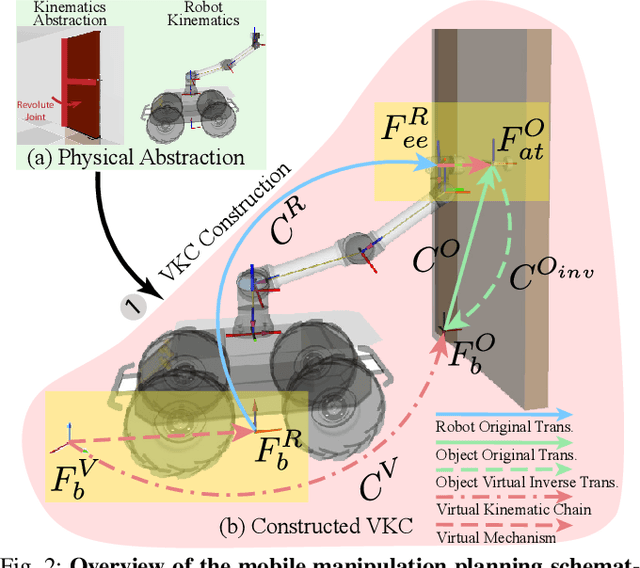
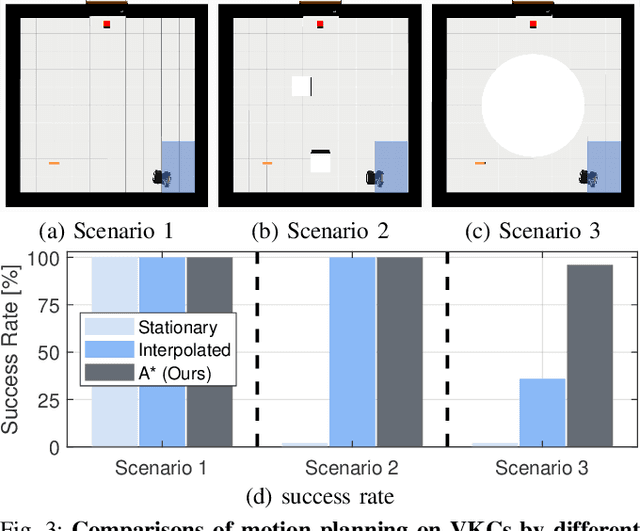
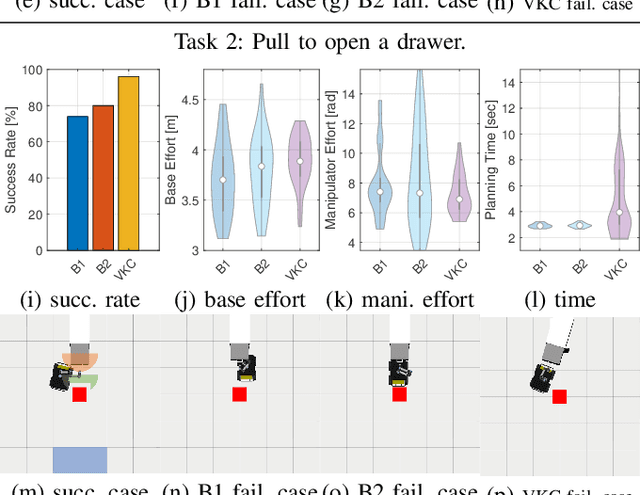
We construct a Virtual Kinematic Chain (VKC) that readily consolidates the kinematics of the mobile base, the arm, and the object to be manipulated in mobile manipulations. Accordingly, a mobile manipulation task is represented by altering the state of the constructed VKC, which can be converted to a motion planning problem, formulated, and solved by trajectory optimization. This new VKC perspective of mobile manipulation allows a service robot to (i) produce well-coordinated motions, suitable for complex household environments, and (ii) perform intricate multi-step tasks while interacting with multiple objects without an explicit definition of intermediate goals. In simulated experiments, we validate these advantages by comparing the VKC-based approach with baselines that solely optimize individual components. The results manifest that VKC-based joint modeling and planning promote task success rates and produce more efficient trajectories.
Efficient Task Planning for Mobile Manipulation: a Virtual Kinematic Chain Perspective
Aug 03, 2021
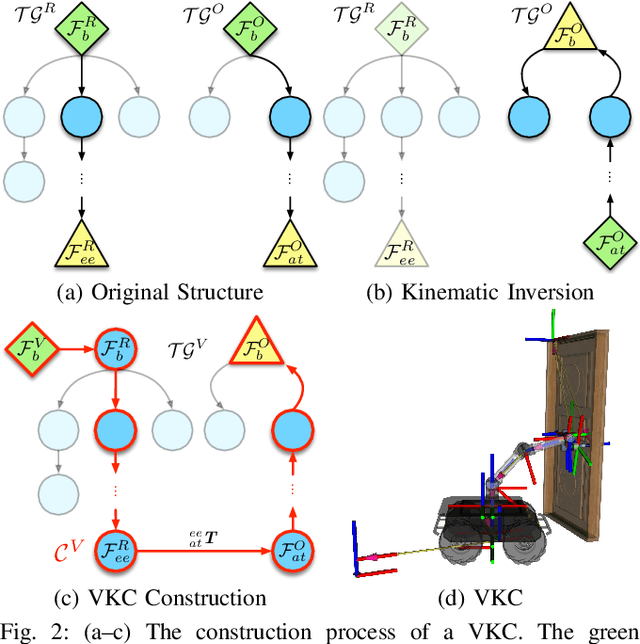
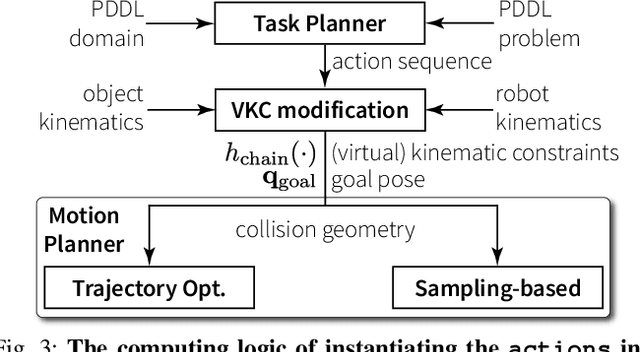
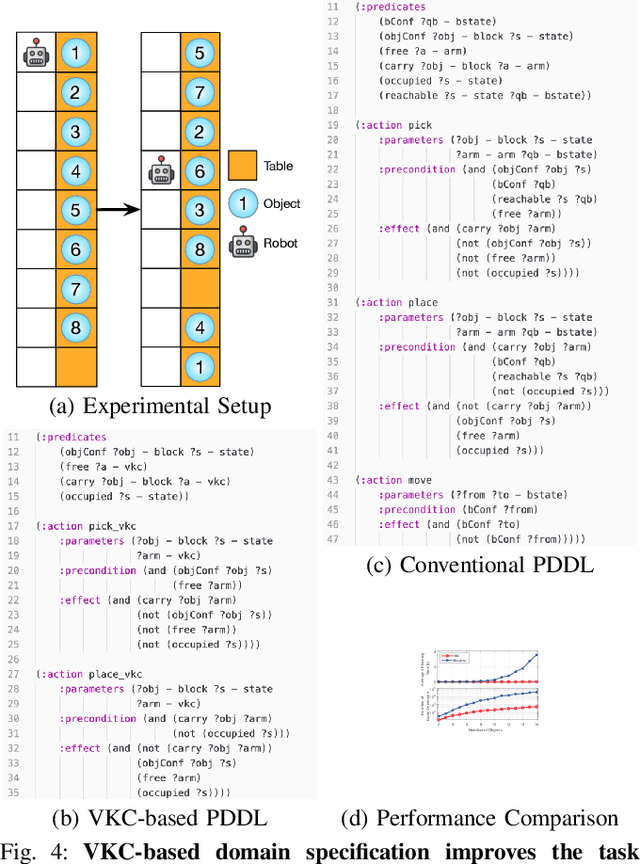
We present a Virtual Kinematic Chain (VKC) perspective, a simple yet effective method, to improve task planning efficacy for mobile manipulation. By consolidating the kinematics of the mobile base, the arm, and the object being manipulated collectively as a whole, this novel VKC perspective naturally defines abstract actions and eliminates unnecessary predicates in describing intermediate poses. As a result, these advantages simplify the design of the planning domain and significantly reduce the search space and branching factors in solving planning problems. In experiments, we implement a task planner using Planning Domain Definition Language (PDDL) with VKC. Compared with conventional domain definition, our VKC-based domain definition is more efficient in both planning time and memory. In addition, abstract actions perform better in producing feasible motion plans and trajectories. We further scale up the VKC-based task planner in complex mobile manipulation tasks. Taken together, these results demonstrate that task planning using VKC for mobile manipulation is not only natural and effective but also introduces new capabilities.
Transformer-based Machine Learning for Fast SAT Solvers and Logic Synthesis
Jul 15, 2021
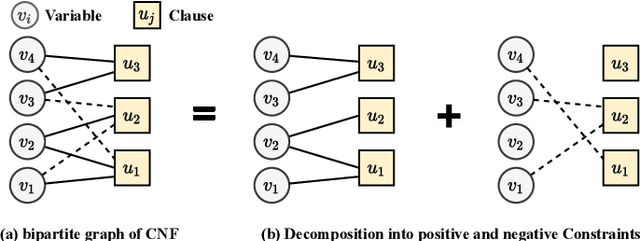
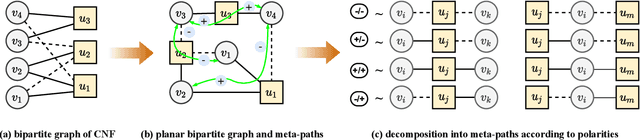
CNF-based SAT and MaxSAT solvers are central to logic synthesis and verification systems. The increasing popularity of these constraint problems in electronic design automation encourages studies on different SAT problems and their properties for further computational efficiency. There has been both theoretical and practical success of modern Conflict-driven clause learning SAT solvers, which allows solving very large industrial instances in a relatively short amount of time. Recently, machine learning approaches provide a new dimension to solving this challenging problem. Neural symbolic models could serve as generic solvers that can be specialized for specific domains based on data without any changes to the structure of the model. In this work, we propose a one-shot model derived from the Transformer architecture to solve the MaxSAT problem, which is the optimization version of SAT where the goal is to satisfy the maximum number of clauses. Our model has a scale-free structure which could process varying size of instances. We use meta-path and self-attention mechanism to capture interactions among homogeneous nodes. We adopt cross-attention mechanisms on the bipartite graph to capture interactions among heterogeneous nodes. We further apply an iterative algorithm to our model to satisfy additional clauses, enabling a solution approaching that of an exact-SAT problem. The attention mechanisms leverage the parallelism for speedup. Our evaluation indicates improved speedup compared to heuristic approaches and improved completion rate compared to machine learning approaches.
STAR: Sparse Transformer-based Action Recognition
Jul 15, 2021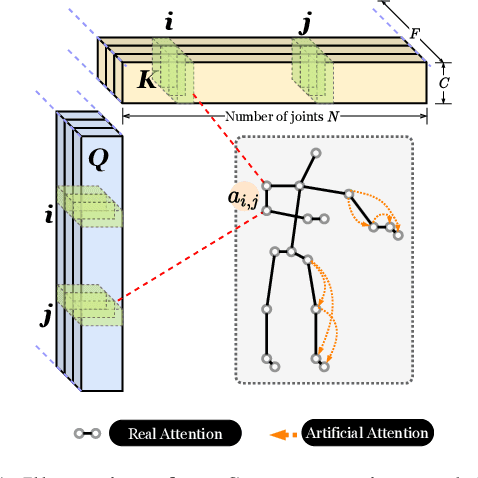
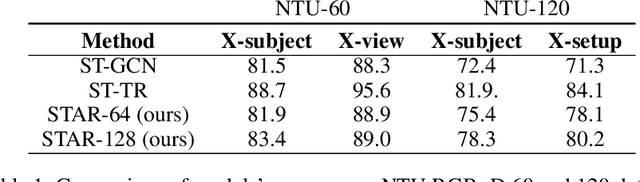
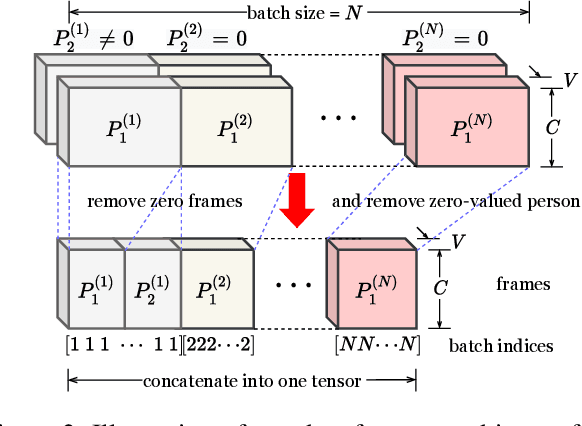
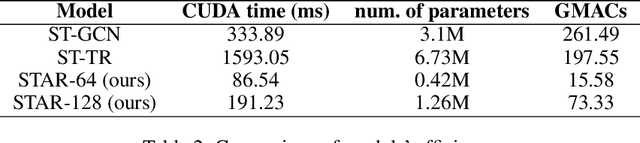
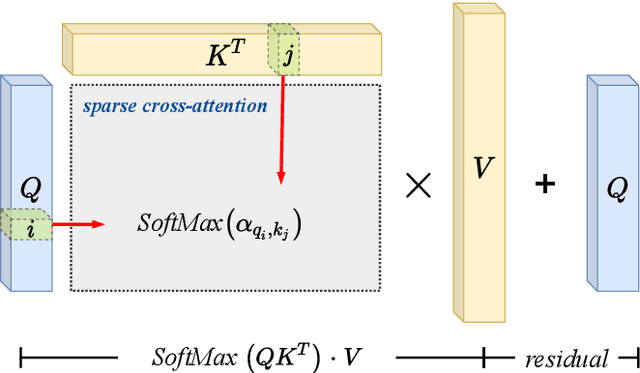
The cognitive system for human action and behavior has evolved into a deep learning regime, and especially the advent of Graph Convolution Networks has transformed the field in recent years. However, previous works have mainly focused on over-parameterized and complex models based on dense graph convolution networks, resulting in low efficiency in training and inference. Meanwhile, the Transformer architecture-based model has not yet been well explored for cognitive application in human action and behavior estimation. This work proposes a novel skeleton-based human action recognition model with sparse attention on the spatial dimension and segmented linear attention on the temporal dimension of data. Our model can also process the variable length of video clips grouped as a single batch. Experiments show that our model can achieve comparable performance while utilizing much less trainable parameters and achieve high speed in training and inference. Experiments show that our model achieves 4~18x speedup and 1/7~1/15 model size compared with the baseline models at competitive accuracy.
SocAoG: Incremental Graph Parsing for Social Relation Inference in Dialogues
Jun 24, 2021
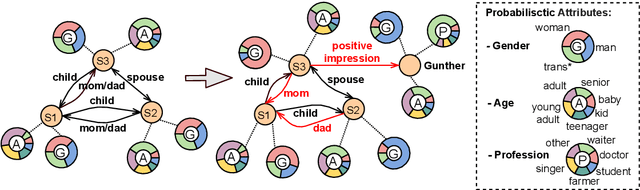
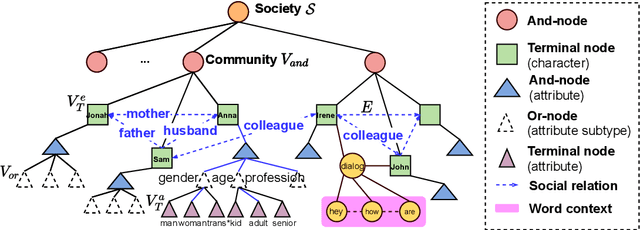
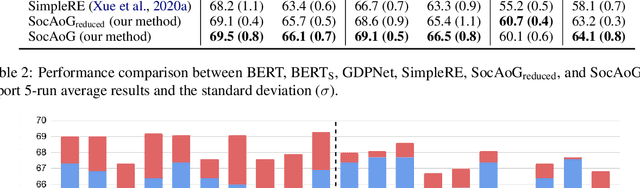
Inferring social relations from dialogues is vital for building emotionally intelligent robots to interpret human language better and act accordingly. We model the social network as an And-or Graph, named SocAoG, for the consistency of relations among a group and leveraging attributes as inference cues. Moreover, we formulate a sequential structure prediction task, and propose an $\alpha$-$\beta$-$\gamma$ strategy to incrementally parse SocAoG for the dynamic inference upon any incoming utterance: (i) an $\alpha$ process predicting attributes and relations conditioned on the semantics of dialogues, (ii) a $\beta$ process updating the social relations based on related attributes, and (iii) a $\gamma$ process updating individual's attributes based on interpersonal social relations. Empirical results on DialogRE and MovieGraph show that our model infers social relations more accurately than the state-of-the-art methods. Moreover, the ablation study shows the three processes complement each other, and the case study demonstrates the dynamic relational inference.
Inter-GPS: Interpretable Geometry Problem Solving with Formal Language and Symbolic Reasoning
Jun 01, 2021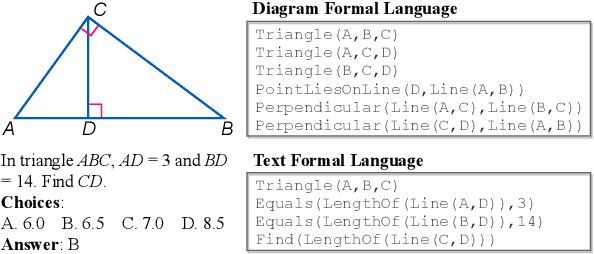

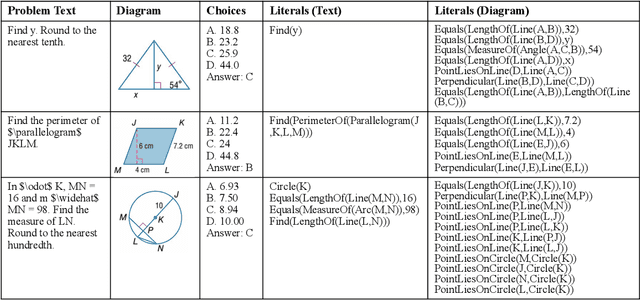

Geometry problem solving has attracted much attention in the NLP community recently. The task is challenging as it requires abstract problem understanding and symbolic reasoning with axiomatic knowledge. However, current datasets are either small in scale or not publicly available. Thus, we construct a new large-scale benchmark, Geometry3K, consisting of 3,002 geometry problems with dense annotation in formal language. We further propose a novel geometry solving approach with formal language and symbolic reasoning, called Interpretable Geometry Problem Solver (Inter-GPS). Inter-GPS first parses the problem text and diagram into formal language automatically via rule-based text parsing and neural object detecting, respectively. Unlike implicit learning in existing methods, Inter-GPS incorporates theorem knowledge as conditional rules and performs symbolic reasoning step by step. Also, a theorem predictor is designed to infer the theorem application sequence fed to the symbolic solver for the more efficient and reasonable searching path. Extensive experiments on the Geometry3K and GEOS datasets demonstrate that Inter-GPS achieves significant improvements over existing methods. The project with code and data is available at https://lupantech.github.io/inter-gps.