 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multi-Arm Manipulation Through Collaborative Teleoperation
Dec 12, 2020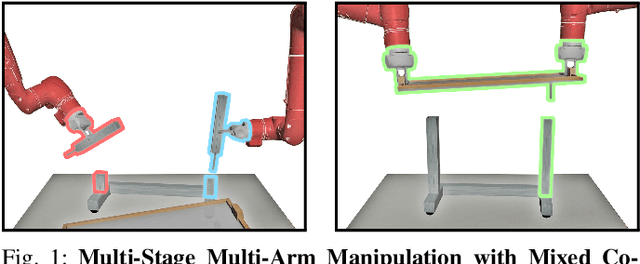
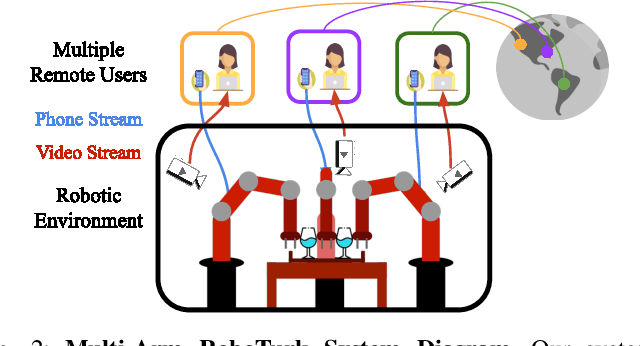
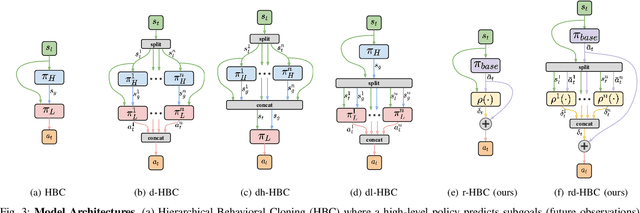

Imitation Learning (IL) is a powerful paradigm to teach robots to perform manipulation tasks by allowing them to learn from human demonstrations collected via teleoperation, but has mostly been limited to single-arm manipulation. However, many real-world tasks require multiple arms, such as lifting a heavy object or assembling a desk. Unfortunately, applying IL to multi-arm manipulation tasks has been challenging -- asking a human to control more than one robotic arm can impose significant cognitive burden and is often only possible for a maximum of two robot arms. To address these challenges, we present Multi-Arm RoboTurk (MART), a multi-user data collection platform that allows multiple remote users to simultaneously teleoperate a set of robotic arms and collect demonstrations for multi-arm tasks. Using MART, we collected demonstrations for five novel two and three-arm tasks from several geographically separated users. From our data we arrived at a critical insight: most multi-arm tasks do not require global coordination throughout its full duration, but only during specific moments. We show that learning from such data consequently presents challenges for centralized agents that directly attempt to model all robot actions simultaneously, and perform a comprehensive study of different policy architectures with varying levels of centralization on our tasks. Finally, we propose and evaluate a base-residual policy framework that allows trained policies to better adapt to the mixed coordination setting common in multi-arm manipulation, and show that a centralized policy augmented with a decentralized residual model outperforms all other models on our set of benchmark tasks. Additional results and videos at https://roboturk.stanford.edu/multiarm .
Human-in-the-Loop Imitation Learning using Remote Teleoperation
Dec 12, 2020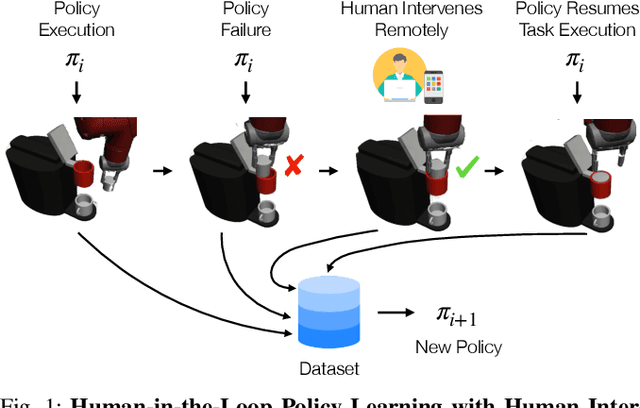

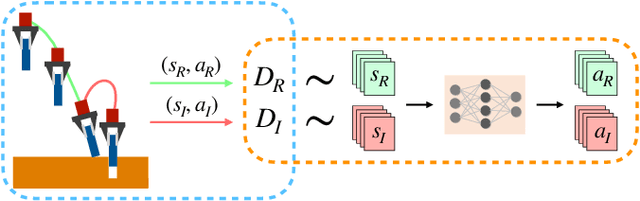

Imitation Learning is a promising paradigm for learning complex robot manipulation skills by reproducing behavior from human demonstrations. However, manipulation tasks often contain bottleneck regions that require a sequence of precise actions to make meaningful progress, such as a robot inserting a pod into a coffee machine to make coffee. Trained policies can fail in these regions because small deviations in actions can lead the policy into states not covered by the demonstrations. Intervention-based policy learning is an alternative that can address this issue -- it allows human operators to monitor trained policies and take over control when they encounter failures. In this paper, we build a data collection system tailored to 6-DoF manipulation settings, that enables remote human operators to monitor and intervene on trained policies. We develop a simple and effective algorithm to train the policy iteratively on new data collected by the system that encourages the policy to learn how to traverse bottlenecks through the interventions. We demonstrate that agents trained on data collected by our intervention-based system and algorithm outperform agents trained on an equivalent number of samples collected by non-interventional demonstrators, and further show that our method outperforms multiple state-of-the-art baselines for learning from the human interventions on a challenging robot threading task and a coffee making task. Additional results and videos at https://sites.google.com/stanford.edu/iwr .
Topological Planning with Transformers for Vision-and-Language Navigation
Dec 09, 2020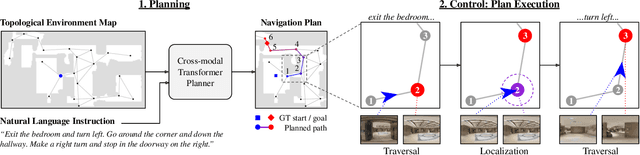
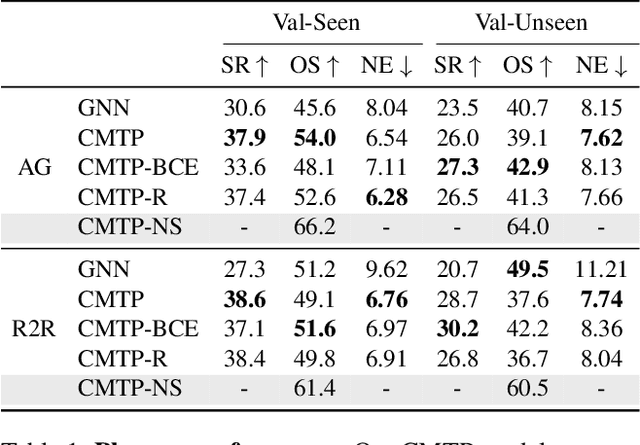
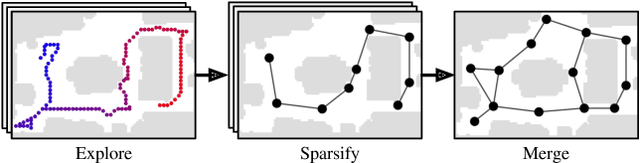

Conventional approaches to vision-and-language navigation (VLN) are trained end-to-end but struggle to perform well in freely traversable environments. Inspired by the robotics community, we propose a modular approach to VLN using topological maps. Given a natural language instruction and topological map, our approach leverages attention mechanisms to predict a navigation plan in the map. The plan is then executed with low-level actions (e.g. forward, rotate) using a robust controller. Experiments show that our method outperforms previous end-to-end approaches, generates interpretable navigation plans, and exhibits intelligent behaviors such as backtracking.
iGibson, a Simulation Environment for Interactive Tasks in Large Realistic Scenes
Dec 08, 2020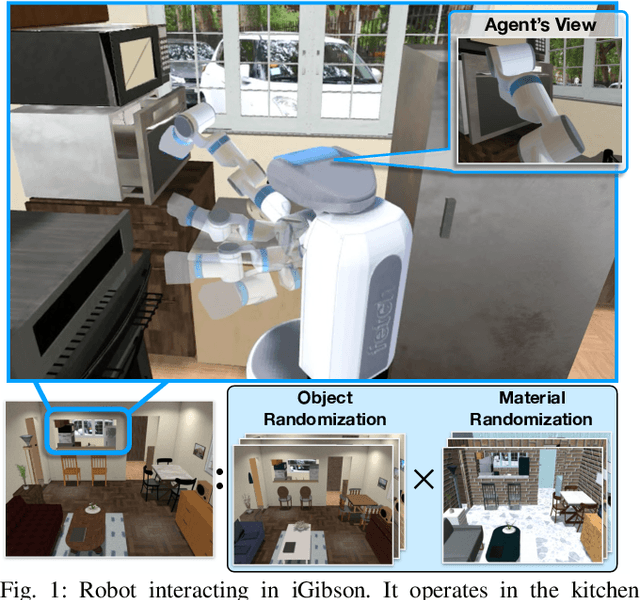
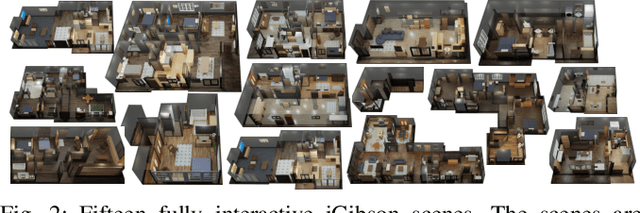


We present iGibson, a novel simulation environment to develop robotic solutions for interactive tasks in large-scale realistic scenes. Our environment contains fifteen fully interactive home-sized scenes populated with rigid and articulated objects. The scenes are replicas of 3D scanned real-world homes, aligning the distribution of objects and layout to that of the real world. iGibson integrates several key features to facilitate the study of interactive tasks: i) generation of high-quality visual virtual sensor signals (RGB, depth, segmentation, LiDAR, flow, among others), ii) domain randomization to change the materials of the objects (both visual texture and dynamics) and/or their shapes, iii) integrated sampling-based motion planners to generate collision-free trajectories for robot bases and arms, and iv) intuitive human-iGibson interface that enables efficient collection of human demonstrations. Through experiments, we show that the full interactivity of the scenes enables agents to learn useful visual representations that accelerate the training of downstream manipulation tasks. We also show that iGibson features enable the generalization of navigation agents, and that the human-iGibson interface and integrated motion planners facilitate efficient imitation learning of simple human demonstrated behaviors. iGibson is open-sourced with comprehensive examples and documentation. For more information, visit our project website: http://svl.stanford.edu/igibson/
Semantic and Geometric Modeling with Neural Message Passing in 3D Scene Graphs for Hierarchical Mechanical Search
Dec 07, 2020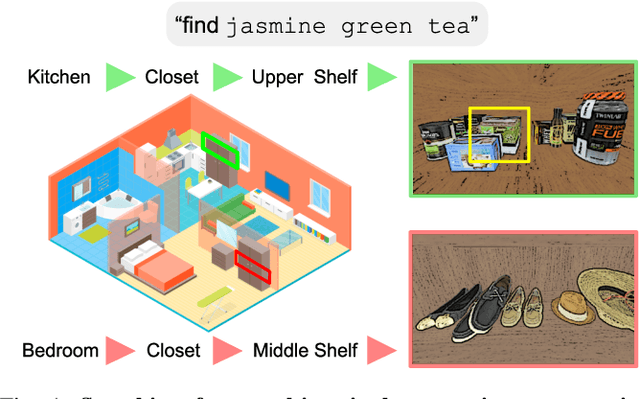
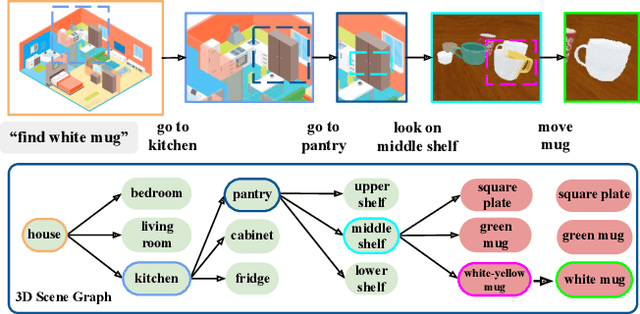
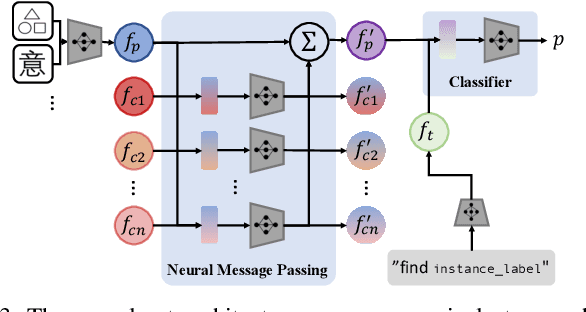
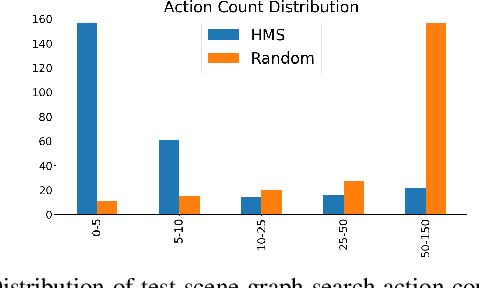
Searching for objects in indoor organized environments such as homes or offices is part of our everyday activities. When looking for a target object, we jointly reason about the rooms and containers the object is likely to be in; the same type of container will have a different probability of having the target depending on the room it is in. We also combine geometric and semantic information to infer what container is best to search, or what other objects are best to move, if the target object is hidden from view. We propose to use a 3D scene graph representation to capture the hierarchical, semantic, and geometric aspects of this problem. To exploit this representation in a search process, we introduce Hierarchical Mechanical Search (HMS), a method that guides an agent's actions towards finding a target object specified with a natural language description. HMS is based on a novel neural network architecture that uses neural message passing of vectors with visual, geometric, and linguistic information to allow HMS to reason across layers of the graph while combining semantic and geometric cues. HMS is evaluated on a novel dataset of 500 3D scene graphs with dense placements of semantically related objects in storage locations, and is shown to be significantly better than several baselines at finding objects and close to the oracle policy in terms of the median number of actions required. Additional qualitative results can be found at https://ai.stanford.edu/mech-search/hms.
Deep Affordance Foresight: Planning Through What Can Be Done in the Future
Nov 17, 2020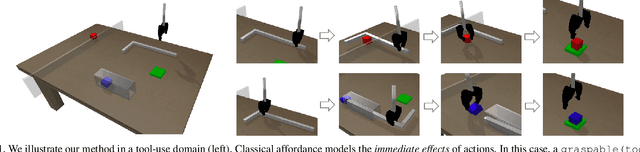
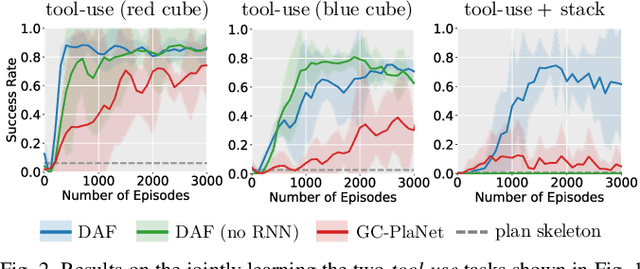
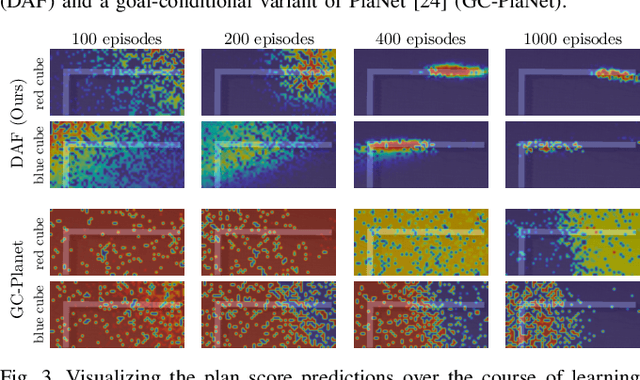
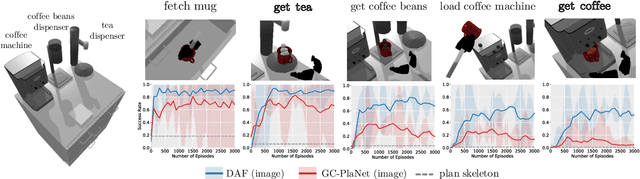
Planning in realistic environments requires searching in large planning spaces. Affordances are a powerful concept to simplify this search, because they model what actions can be successful in a given situation. However, the classical notion of affordance is not suitable for long horizon planning because it only informs the robot about the immediate outcome of actions instead of what actions are best for achieving a long-term goal. In this paper, we introduce a new affordance representation that enables the robot to reason about the long-term effects of actions through modeling what actions are afforded in the future, thereby informing the robot the best actions to take next to achieve a task goal. Based on the new representation, we develop a learning-to-plan method, Deep Affordance Foresight (DAF), that learns partial environment models of affordances of parameterized motor skills through trial-and-error. We evaluate DAF on two challenging manipulation domains and show that it can effectively learn to carry out multi-step tasks, share learned affordance representations among different tasks, and learn to plan with high-dimensional image inputs. Additional material is available at https://sites.google.com/stanford.edu/daf
Robust Policies via Mid-Level Visual Representations: An Experimental Study in Manipulation and Navigation
Nov 13, 2020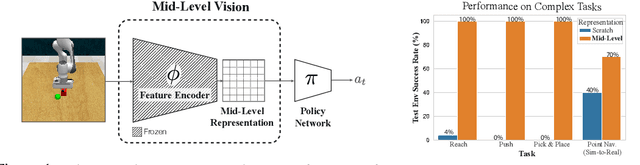
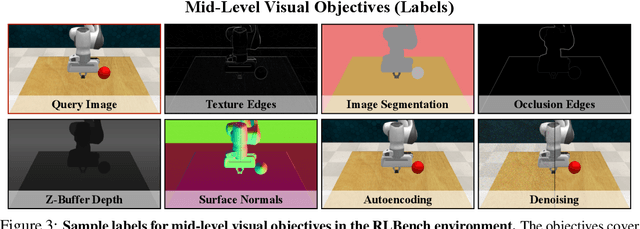
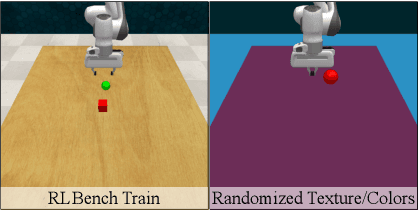
Vision-based robotics often separates the control loop into one module for perception and a separate module for control. It is possible to train the whole system end-to-end (e.g. with deep RL), but doing it "from scratch" comes with a high sample complexity cost and the final result is often brittle, failing unexpectedly if the test environment differs from that of training. We study the effects of using mid-level visual representations (features learned asynchronously for traditional computer vision objectives), as a generic and easy-to-decode perceptual state in an end-to-end RL framework. Mid-level representations encode invariances about the world, and we show that they aid generalization, improve sample complexity, and lead to a higher final performance. Compared to other approaches for incorporating invariances, such as domain randomization, asynchronously trained mid-level representations scale better: both to harder problems and to larger domain shifts. In practice, this means that mid-level representations could be used to successfully train policies for tasks where domain randomization and learning-from-scratch failed. We report results on both manipulation and navigation tasks, and for navigation include zero-shot sim-to-real experiments on real robots.
Multimodal Sensor Fusion with Differentiable Filters
Oct 25, 2020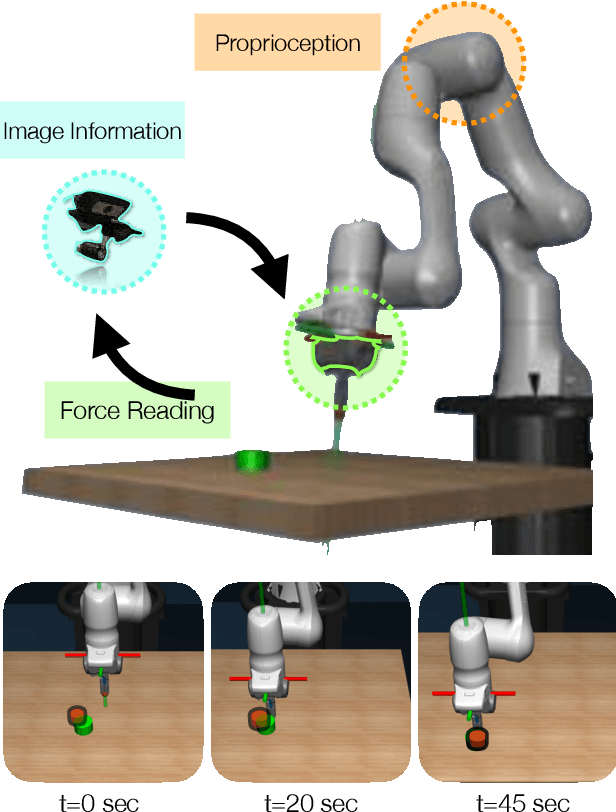
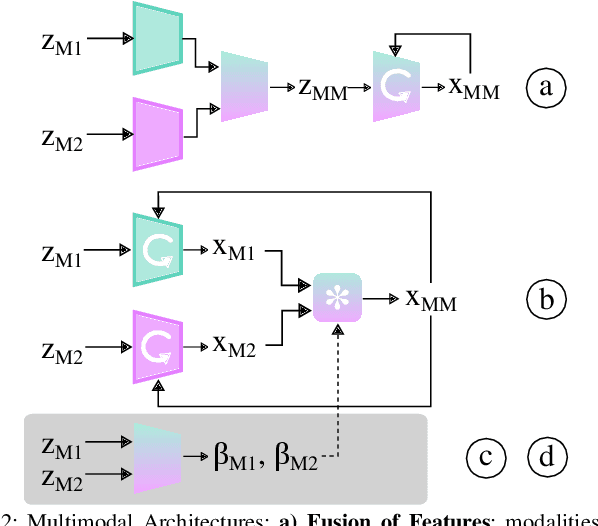
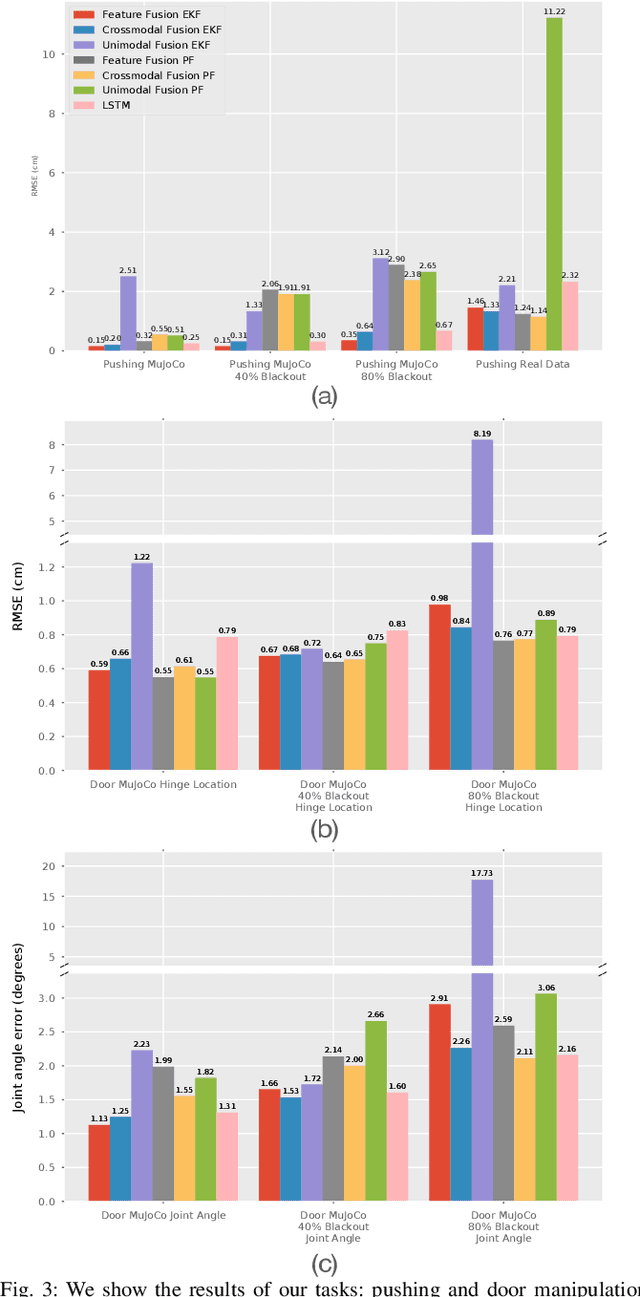
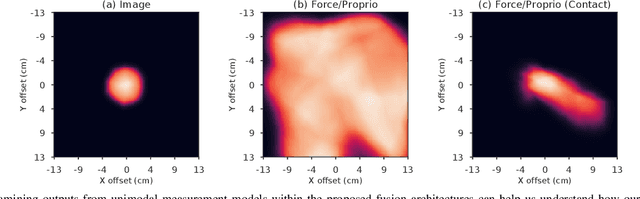
Leveraging multimodal information with recursive Bayesian filters improves performance and robustness of state estimation, as recursive filters can combine different modalities according to their uncertainties. Prior work has studied how to optimally fuse different sensor modalities with analytical state estimation algorithms. However, deriving the dynamics and measurement models along with their noise profile can be difficult or lead to intractable models. Differentiable filters provide a way to learn these models end-to-end while retaining the algorithmic structure of recursive filters. This can be especially helpful when working with sensor modalities that are high dimensional and have very different characteristics. In contact-rich manipulation, we want to combine visual sensing (which gives us global information) with tactile sensing (which gives us local information). In this paper, we study new differentiable filtering architectures to fuse heterogeneous sensor information. As case studies, we evaluate three tasks: two in planar pushing (simulated and real) and one in manipulating a kinematically constrained door (simulated). In extensive evaluations, we find that differentiable filters that leverage crossmodal sensor information reach comparable accuracies to unstructured LSTM models, while presenting interpretability benefits that may be important for safety-critical systems. We also release an open-source library for creating and training differentiable Bayesian filters in PyTorch, which can be found on our project website: https://sites.google.com/view/ multimodalfilter.
Robot Navigation in Constrained Pedestrian Environments using Reinforcement Learning
Oct 16, 2020
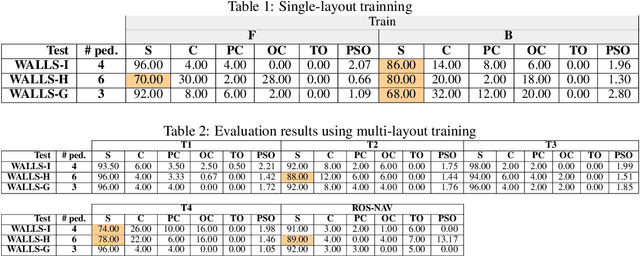
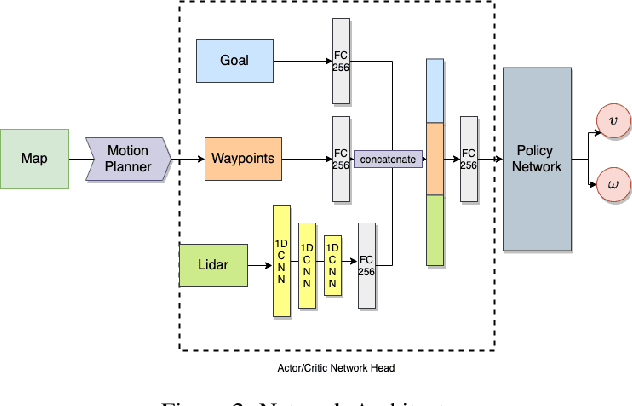
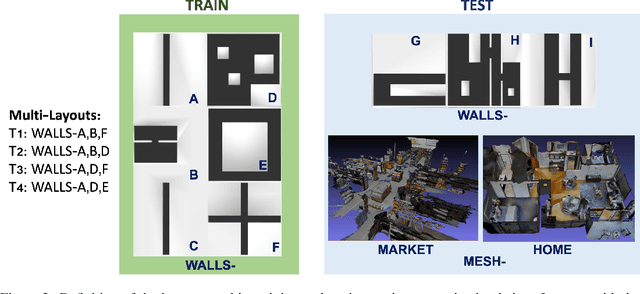
Navigating fluently around pedestrians is a necessary capability for mobile robots deployed in human environments, such as office buildings and homes. While related literature has addressed the co-navigation problem focused on the scalability with the number of pedestrians in open spaces, typical indoor environments present the additional challenge of constrained spaces such as corridors, doorways and crosswalks that limit maneuverability and influence patterns of pedestrian interaction. We present an approach based on reinforcement learning to learn policies capable of dynamic adaptation to the presence of moving pedestrians while navigating between desired locations in constrained environments. The policy network receives guidance from a motion planner that provides waypoints to follow a globally planned trajectory, whereas the reinforcement component handles the local interactions. We explore a compositional principle for multi-layout training and find that policies trained in a small set of geometrically simple layouts successfully generalize to unseen and more complex layouts that exhibit composition of the simple structural elements available during training. Going beyond wall-world like domains, we show transfer of the learned policy to unseen 3D reconstructions of two real environments (market, home). These results support the applicability of the compositional principle to real-world environments and indicate promising usage of agent simulation within reconstructed environments for tasks that involve interaction.
Privacy Preserving Recalibration under Domain Shift
Aug 21, 2020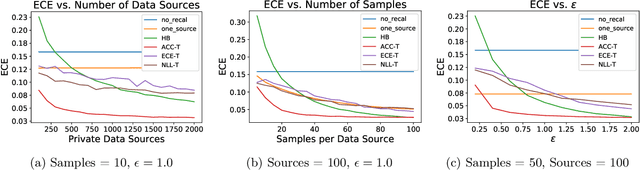
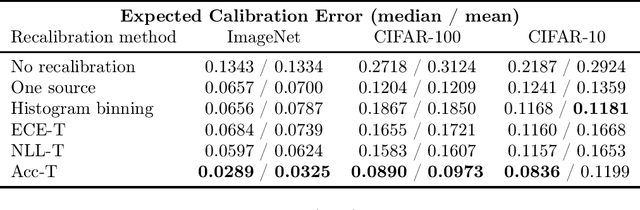
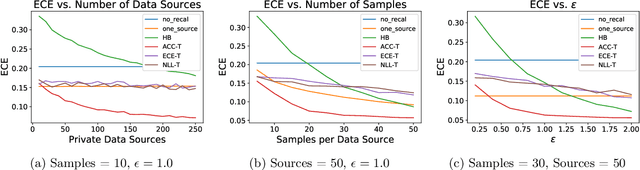

Classifiers deployed in high-stakes real-world applications must output calibrated confidence scores, i.e. their predicted probabilities should reflect empirical frequencies. Recalibration algorithms can greatly improve a model's probability estimates; however, existing algorithms are not applicable in real-world situations where the test data follows a different distribution from the training data, and privacy preservation is paramount (e.g. protecting patient records). We introduce a framework that abstracts out the properties of recalibration problems under differential privacy constraints. This framework allows us to adapt existing recalibration algorithms to satisfy differential privacy while remaining effective for domain-shift situations. Guided by our framework, we also design a novel recalibration algorithm, accuracy temperature scaling, that outperforms prior work on private datasets. In an extensive empirical study, we find that our algorithm improves calibration on domain-shift benchmarks under the constraints of differential privacy. On the 15 highest severity perturbations of the ImageNet-C dataset, our method achieves a median ECE of 0.029, over 2x better than the next best recalibration method and almost 5x better than without recalibration.