 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInheritSumm: A General, Versatile and Compact Summarizer by Distilling from GPT
May 22, 2023While large models such as GPT-3 demonstrate exceptional performance in zeroshot and fewshot summarization tasks, their extensive serving and fine-tuning costs hinder their utilization in various applications. Conversely, previous studies have found that although automatic metrics tend to favor smaller fine-tuned models, the quality of the summaries they generate is inferior to that of larger models like GPT-3 when assessed by human evaluators. To address this issue, we propose InheritSumm, a versatile and compact summarization model derived from GPT-3.5 through distillation. InheritSumm not only exhibits comparable zeroshot and fewshot summarization capabilities to GPT-3.5 but is also sufficiently compact for fine-tuning purposes. Experimental results demonstrate that InheritSumm achieves similar or superior performance to GPT-3.5 in zeroshot and fewshot settings. Furthermore, it outperforms the previously established best small models in both prefix-tuning and full-data fine-tuning scenarios.
Small Models are Valuable Plug-ins for Large Language Models
May 15, 2023Large language models (LLMs) such as GPT-3 and GPT-4 are powerful but their weights are often publicly unavailable and their immense sizes make the models difficult to be tuned with common hardware. As a result, effectively tuning these models with large-scale supervised data can be challenging. As an alternative, In-Context Learning (ICL) can only use a small number of supervised examples due to context length limits. In this paper, we propose Super In-Context Learning (SuperICL) which allows black-box LLMs to work with locally fine-tuned smaller models, resulting in superior performance on supervised tasks. Our experiments demonstrate that SuperICL can improve performance beyond state-of-the-art fine-tuned models while addressing the instability problem of in-context learning. Furthermore, SuperICL can enhance the capabilities of smaller models, such as multilinguality and interpretability.
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
Apr 06, 2023The quality of texts generated by natural language generation (NLG) systems is hard to measure automatically. Conventional reference-based metrics, such as BLEU and ROUGE, have been shown to have relatively low correlation with human judgments, especially for tasks that require creativity and diversity. Recent studies suggest using large language models (LLMs) as reference-free metrics for NLG evaluation, which have the benefit of being applicable to new tasks that lack human references. However, these LLM-based evaluators still have lower human correspondence than medium-size neural evaluators. In this work, we present G-Eval, a framework of using large language models with chain-of-thoughts (CoT) and a form-filling paradigm, to assess the quality of NLG outputs. We experiment with two generation tasks, text summarization and dialogue generation. We show that G-Eval with GPT-4 as the backbone model achieves a Spearman correlation of 0.514 with human on summarization task, outperforming all previous methods by a large margin. We also propose preliminary analysis on the behavior of LLM-based evaluators, and highlight the potential issue of LLM-based evaluators having a bias towards the LLM-generated texts.
APOLLO: A Simple Approach for Adaptive Pretraining of Language Models for Logical Reasoning
Dec 19, 2022



Logical reasoning of text is an important ability that requires understanding the information present in the text, their interconnections, and then reasoning through them to infer new conclusions. Prior works on improving the logical reasoning ability of language models require complex processing of training data (e.g., aligning symbolic knowledge to text), yielding task-specific data augmentation solutions that restrict the learning of general logical reasoning skills. In this work, we propose APOLLO, an adaptively pretrained language model that has improved logical reasoning abilities. We select a subset of Wikipedia, based on a set of logical inference keywords, for continued pretraining of a language model. We use two self-supervised loss functions: a modified masked language modeling loss where only specific parts-of-speech words, that would likely require more reasoning than basic language understanding, are masked, and a sentence-level classification loss that teaches the model to distinguish between entailment and contradiction types of sentences. The proposed training paradigm is both simple and independent of task formats. We demonstrate the effectiveness of APOLLO by comparing it with prior baselines on two logical reasoning datasets. APOLLO performs comparably on ReClor and outperforms baselines on LogiQA.
Empowering Language Models with Knowledge Graph Reasoning for Question Answering
Nov 15, 2022Answering open-domain questions requires world knowledge about in-context entities. As pre-trained Language Models (LMs) lack the power to store all required knowledge, external knowledge sources, such as knowledge graphs, are often used to augment LMs. In this work, we propose knOwledge REasOning empowered Language Model (OREO-LM), which consists of a novel Knowledge Interaction Layer that can be flexibly plugged into existing Transformer-based LMs to interact with a differentiable Knowledge Graph Reasoning module collaboratively. In this way, LM guides KG to walk towards the desired answer, while the retrieved knowledge improves LM. By adopting OREO-LM to RoBERTa and T5, we show significant performance gain, achieving state-of-art results in the Closed-Book setting. The performance enhancement is mainly from the KG reasoning's capacity to infer missing relational facts. In addition, OREO-LM provides reasoning paths as rationales to interpret the model's decision.
Retrieval Augmentation for Commonsense Reasoning: A Unified Approach
Oct 23, 2022



A common thread of retrieval-augmented methods in the existing literature focuses on retrieving encyclopedic knowledge, such as Wikipedia, which facilitates well-defined entity and relation spaces that can be modeled. However, applying such methods to commonsense reasoning tasks faces two unique challenges, i.e., the lack of a general large-scale corpus for retrieval and a corresponding effective commonsense retriever. In this paper, we systematically investigate how to leverage commonsense knowledge retrieval to improve commonsense reasoning tasks. We proposed a unified framework of retrieval-augmented commonsense reasoning (called RACo), including a newly constructed commonsense corpus with over 20 million documents and novel strategies for training a commonsense retriever. We conducted experiments on four different commonsense reasoning tasks. Extensive evaluation results showed that our proposed RACo can significantly outperform other knowledge-enhanced method counterparts, achieving new SoTA performance on the CommonGen and CREAK leaderboards.
Prompting GPT-3 To Be Reliable
Oct 17, 2022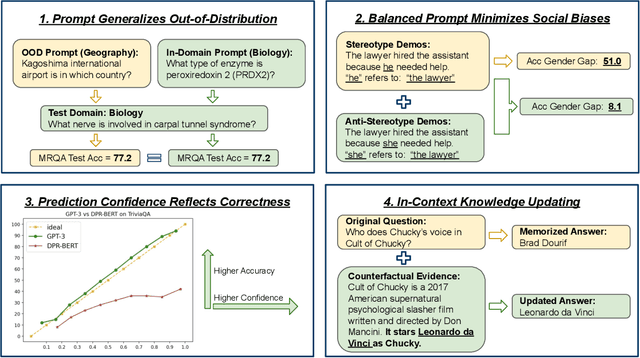

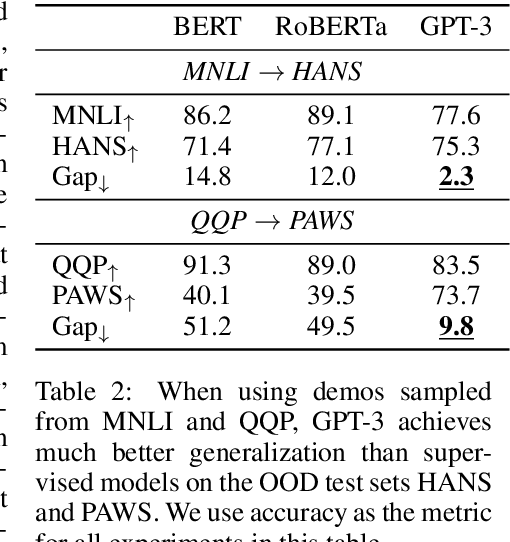

Large language models (LLMs) show impressive abilities via few-shot prompting. Commercialized APIs such as OpenAI GPT-3 further increase their use in real-world language applications. However, existing research focuses on models' accuracy on standard benchmarks and largely ignores their reliability, which is crucial for avoiding catastrophic real-world harms. While reliability is a broad and vaguely defined term, this work decomposes reliability into four facets: generalizability, fairness, calibration, and factuality. We establish simple and effective prompts to demonstrate GPT-3's reliability in these four aspects: 1) generalize out-of-domain, 2) balance demographic distribution to reduce social biases, 3) calibrate language model probabilities, and 4) update the LLM's knowledge. We find that by employing appropriate prompts, GPT-3 outperforms smaller-scale supervised models by large margins on all these facets. We release all processed datasets, evaluation scripts, and model predictions to facilitate future analysis. Our findings not only shed new insights on the reliability of prompting LLMs, but more importantly, our prompting strategies can help practitioners more reliably use large language models like GPT-3.
Task Compass: Scaling Multi-task Pre-training with Task Prefix
Oct 12, 2022
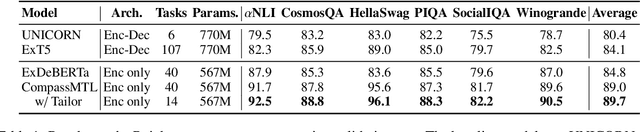
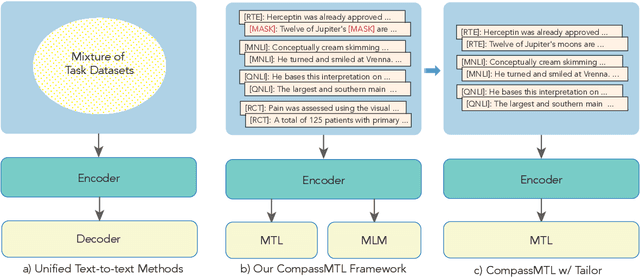
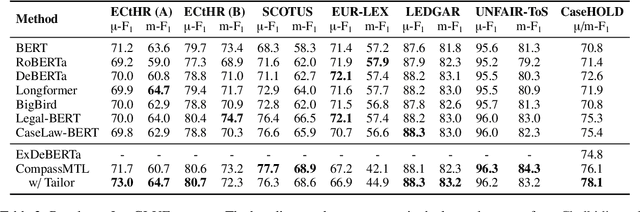
Leveraging task-aware annotated data as supervised signals to assist with self-supervised learning on large-scale unlabeled data has become a new trend in pre-training language models. Existing studies show that multi-task learning with large-scale supervised tasks suffers from negative effects across tasks. To tackle the challenge, we propose a task prefix guided multi-task pre-training framework to explore the relationships among tasks. We conduct extensive experiments on 40 datasets, which show that our model can not only serve as the strong foundation backbone for a wide range of tasks but also be feasible as a probing tool for analyzing task relationships. The task relationships reflected by the prefixes align transfer learning performance between tasks. They also suggest directions for data augmentation with complementary tasks, which help our model achieve human-parity results on commonsense reasoning leaderboards. Code is available at https://github.com/cooelf/CompassMTL
Generate rather than Retrieve: Large Language Models are Strong Context Generators
Sep 29, 2022
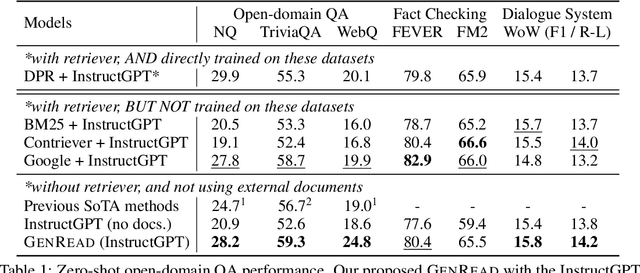
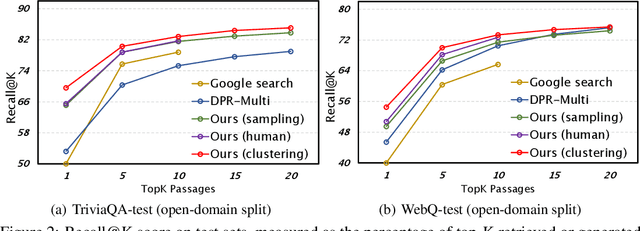
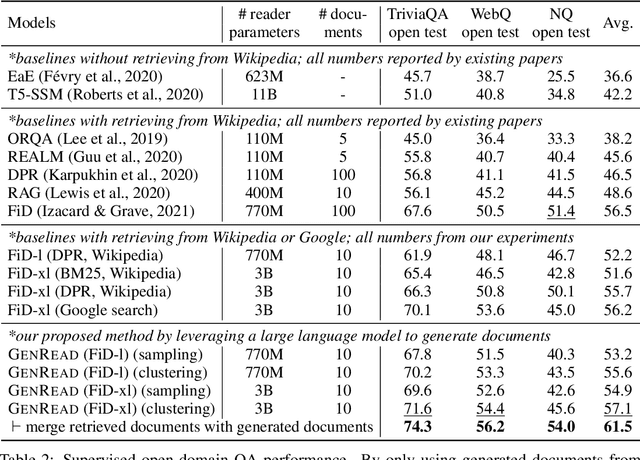
Knowledge-intensive tasks, such as open-domain question answering (QA), require access to a large amount of world or domain knowledge. A common approach for knowledge-intensive tasks is to employ a retrieve-then-read pipeline that first retrieves a handful of relevant contextual documents from an external corpus such as Wikipedia and then predicts an answer conditioned on the retrieved documents. In this paper, we present a novel perspective for solving knowledge-intensive tasks by replacing document retrievers with large language model generators. We call our method generate-then-read (GenRead), which first prompts a large language model to generate contextutal documents based on a given question, and then reads the generated documents to produce the final answer. Furthermore, we propose a novel clustering-based prompting method that selects distinct prompts, resulting in the generated documents that cover different perspectives, leading to better recall over acceptable answers. We conduct extensive experiments on three different knowledge-intensive tasks, including open-domain QA, fact checking, and dialogue system. Notably, GenRead achieves 71.6 and 54.4 exact match scores on TriviaQA and WebQ, significantly outperforming the state-of-the-art retrieve-then-read pipeline DPR-FiD by +4.0 and +3.9, without retrieving any documents from any external knowledge source. Lastly, we demonstrate the model performance can be further improved by combining retrieval and generation.
Language Models with Image Descriptors are Strong Few-Shot Video-Language Learners
May 29, 2022
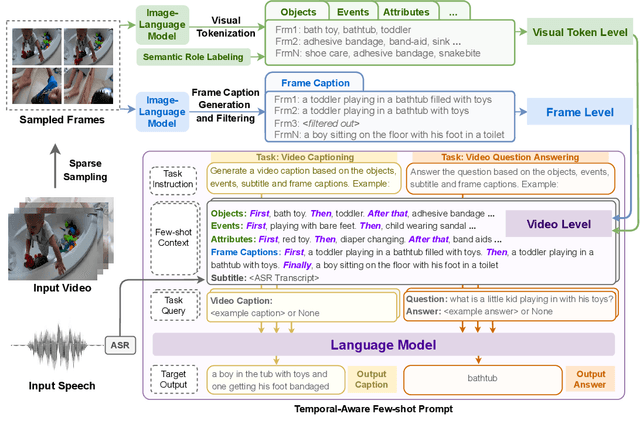
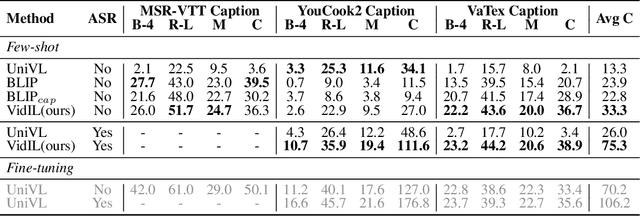

The goal of this work is to build flexible video-language models that can generalize to various video-to-text tasks from few examples, such as domain-specific captioning, question answering, and future event prediction. Existing few-shot video-language learners focus exclusively on the encoder, resulting in the absence of a video-to-text decoder to handle generative tasks. Video captioners have been pretrained on large-scale video-language datasets, but they rely heavily on finetuning and lack the ability to generate text for unseen tasks in a few-shot setting. We propose VidIL, a few-shot Video-language Learner via Image and Language models, which demonstrates strong performance on few-shot video-to-text tasks without the necessity of pretraining or finetuning on any video datasets. We use the image-language models to translate the video content into frame captions, object, attribute, and event phrases, and compose them into a temporal structure template. We then instruct a language model, with a prompt containing a few in-context examples, to generate a target output from the composed content. The flexibility of prompting allows the model to capture any form of text input, such as automatic speech recognition (ASR) transcripts. Our experiments demonstrate the power of language models in understanding videos on a wide variety of video-language tasks, including video captioning, video question answering, video caption retrieval, and video future event prediction. Especially, on video future event prediction, our few-shot model significantly outperforms state-of-the-art supervised models trained on large-scale video datasets. Code and resources are publicly available for research purposes at https://github.com/MikeWangWZHL/VidIL .