 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepNet: Scaling Transformers to 1,000 Layers
Mar 01, 2022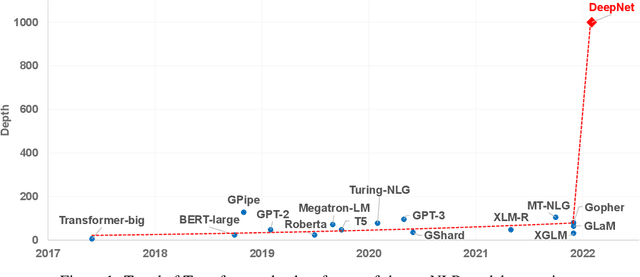
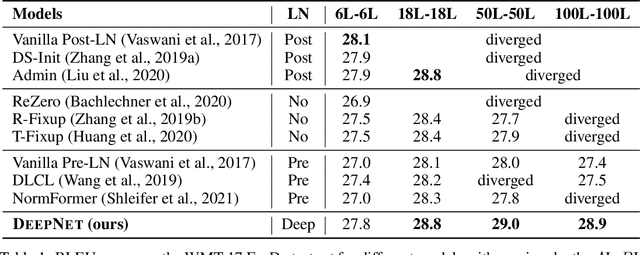

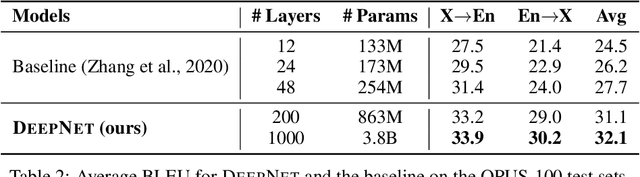
In this paper, we propose a simple yet effective method to stabilize extremely deep Transformers. Specifically, we introduce a new normalization function (DeepNorm) to modify the residual connection in Transformer, accompanying with theoretically derived initialization. In-depth theoretical analysis shows that model updates can be bounded in a stable way. The proposed method combines the best of two worlds, i.e., good performance of Post-LN and stable training of Pre-LN, making DeepNorm a preferred alternative. We successfully scale Transformers up to 1,000 layers (i.e., 2,500 attention and feed-forward network sublayers) without difficulty, which is one order of magnitude deeper than previous deep Transformers. Remarkably, on a multilingual benchmark with 7,482 translation directions, our 200-layer model with 3.2B parameters significantly outperforms the 48-layer state-of-the-art model with 12B parameters by 5 BLEU points, which indicates a promising scaling direction.
Zero-shot Cross-lingual Transfer of Prompt-based Tuning with a Unified Multilingual Prompt
Feb 23, 2022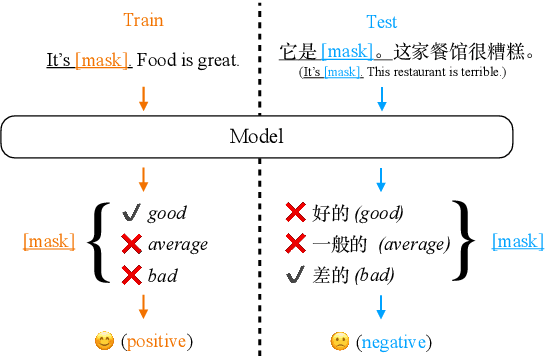

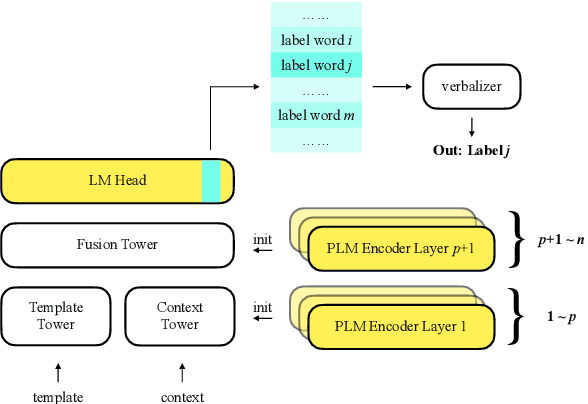
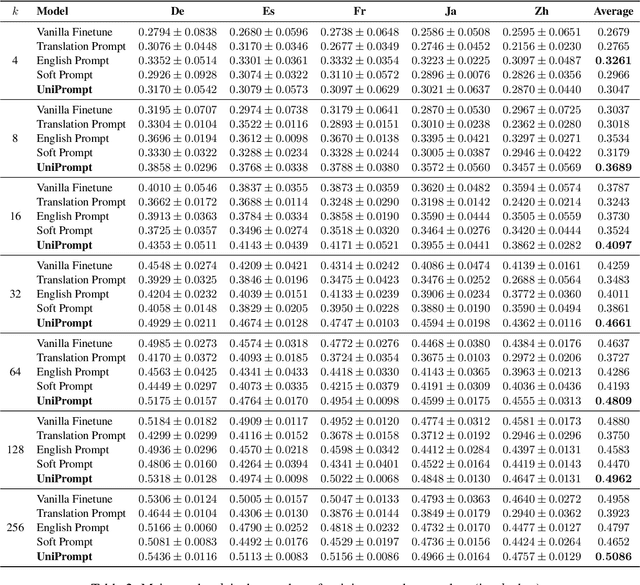
Prompt-based tuning has been proven effective for pretrained language models (PLMs). While most of the existing work focuses on the monolingual prompts, we study the multilingual prompts for multilingual PLMs, especially in the zero-shot cross-lingual setting. To alleviate the effort of designing different prompts for multiple languages, we propose a novel model that uses a unified prompt for all languages, called UniPrompt. Different from the discrete prompts and soft prompts, the unified prompt is model-based and language-agnostic. Specifically, the unified prompt is initialized by a multilingual PLM to produce language-independent representation, after which is fused with the text input. During inference, the prompts can be pre-computed so that no extra computation cost is needed. To collocate with the unified prompt, we propose a new initialization method for the target label word to further improve the model's transferability across languages. Extensive experiments show that our proposed methods can significantly outperform the strong baselines across different languages. We will release data and code to facilitate future research.
A Unified Strategy for Multilingual Grammatical Error Correction with Pre-trained Cross-Lingual Language Model
Jan 26, 2022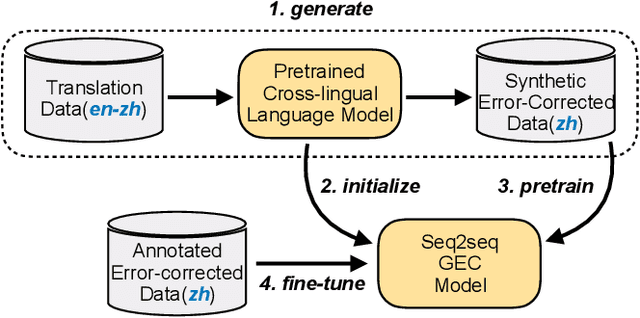

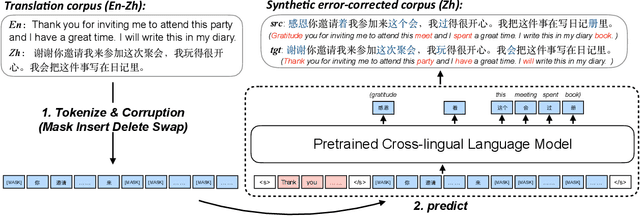
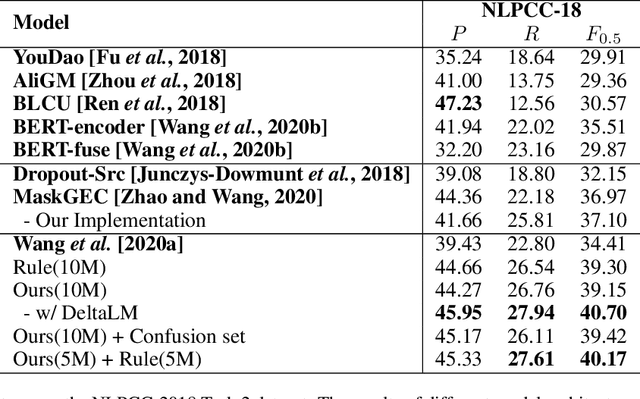
Synthetic data construction of Grammatical Error Correction (GEC) for non-English languages relies heavily on human-designed and language-specific rules, which produce limited error-corrected patterns. In this paper, we propose a generic and language-independent strategy for multilingual GEC, which can train a GEC system effectively for a new non-English language with only two easy-to-access resources: 1) a pretrained cross-lingual language model (PXLM) and 2) parallel translation data between English and the language. Our approach creates diverse parallel GEC data without any language-specific operations by taking the non-autoregressive translation generated by PXLM and the gold translation as error-corrected sentence pairs. Then, we reuse PXLM to initialize the GEC model and pretrain it with the synthetic data generated by itself, which yields further improvement. We evaluate our approach on three public benchmarks of GEC in different languages. It achieves the state-of-the-art results on the NLPCC 2018 Task 2 dataset (Chinese) and obtains competitive performance on Falko-Merlin (German) and RULEC-GEC (Russian). Further analysis demonstrates that our data construction method is complementary to rule-based approaches.
Phrase-level Adversarial Example Generation for Neural Machine Translation
Jan 06, 2022
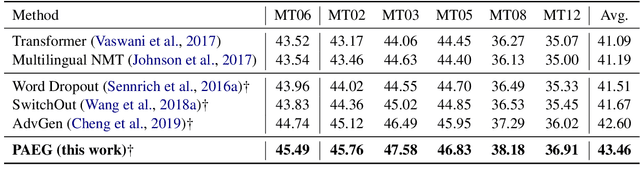
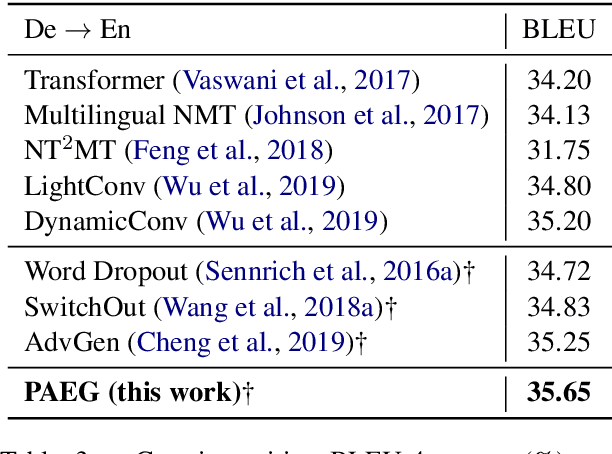
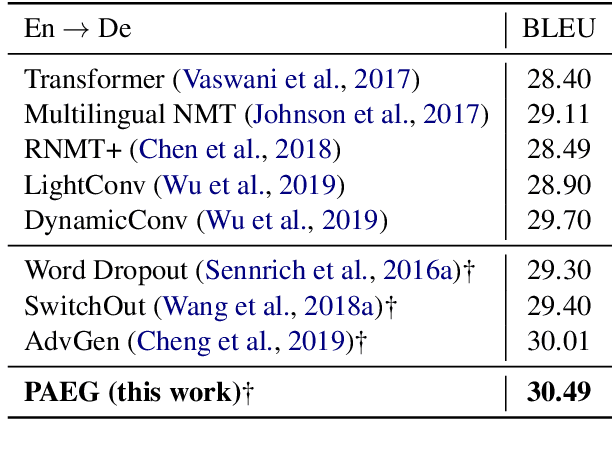
While end-to-end neural machine translation (NMT) has achieved impressive progress, noisy input usually leads models to become fragile and unstable. Generating adversarial examples as the augmented data is proved to be useful to alleviate this problem. Existing methods for adversarial example generation (AEG) are word-level or character-level. In this paper, we propose a phrase-level adversarial example generation (PAEG) method to enhance the robustness of the model. Our method leverages a gradient-based strategy to substitute phrases of vulnerable positions in the source input. We verify our method on three benchmarks, including LDC Chinese-English, IWSLT14 German-English, and WMT14 English-German tasks. Experimental results demonstrate that our approach significantly improves performance compared to previous methods.
SMDT: Selective Memory-Augmented Neural Document Translation
Jan 05, 2022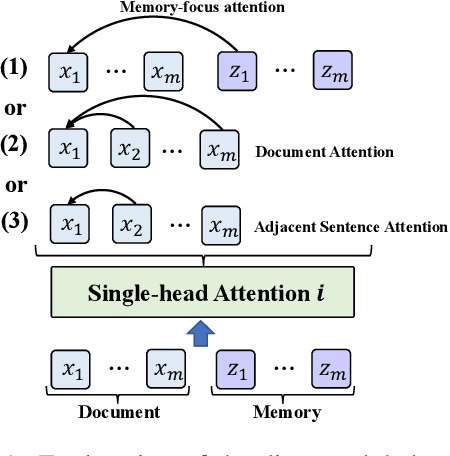
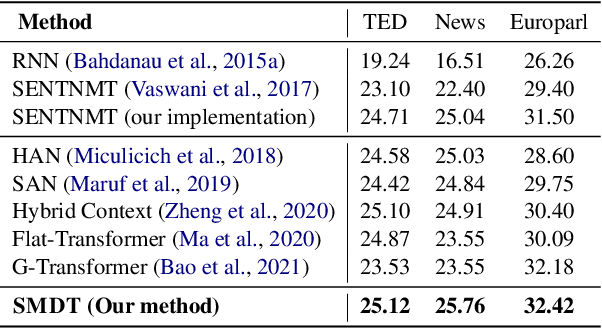

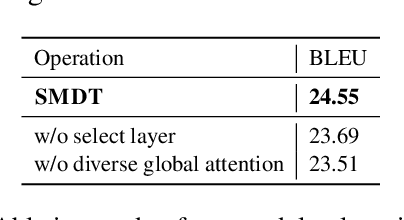
Existing document-level neural machine translation (NMT) models have sufficiently explored different context settings to provide guidance for target generation. However, little attention is paid to inaugurate more diverse context for abundant context information. In this paper, we propose a Selective Memory-augmented Neural Document Translation model to deal with documents containing large hypothesis space of the context. Specifically, we retrieve similar bilingual sentence pairs from the training corpus to augment global context and then extend the two-stream attention model with selective mechanism to capture local context and diverse global contexts. This unified approach allows our model to be trained elegantly on three publicly document-level machine translation datasets and significantly outperforms previous document-level NMT models.
Multilingual Machine Translation Systems from Microsoft for WMT21 Shared Task
Nov 03, 2021


This report describes Microsoft's machine translation systems for the WMT21 shared task on large-scale multilingual machine translation. We participated in all three evaluation tracks including Large Track and two Small Tracks where the former one is unconstrained and the latter two are fully constrained. Our model submissions to the shared task were initialized with DeltaLM\footnote{\url{https://aka.ms/deltalm}}, a generic pre-trained multilingual encoder-decoder model, and fine-tuned correspondingly with the vast collected parallel data and allowed data sources according to track settings, together with applying progressive learning and iterative back-translation approaches to further improve the performance. Our final submissions ranked first on three tracks in terms of the automatic evaluation metric.
Towards Making the Most of Multilingual Pretraining for Zero-Shot Neural Machine Translation
Oct 16, 2021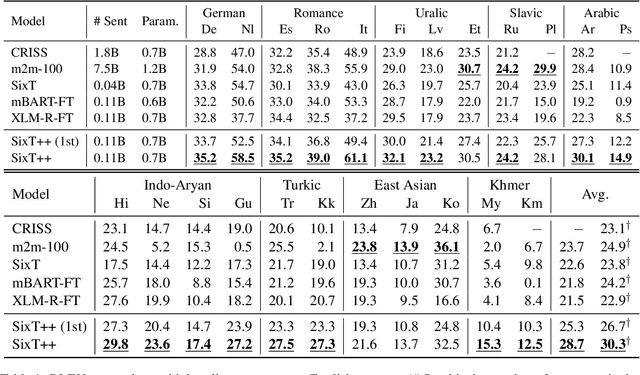
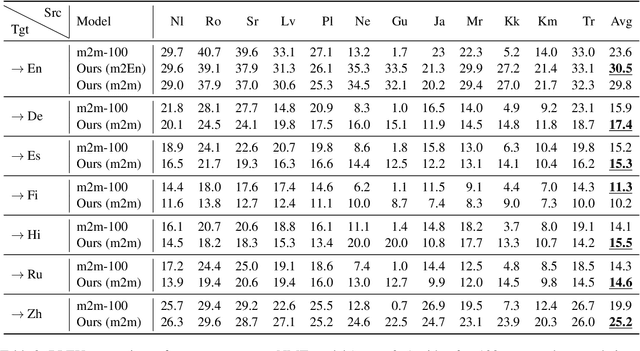
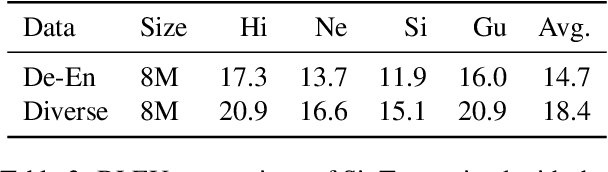
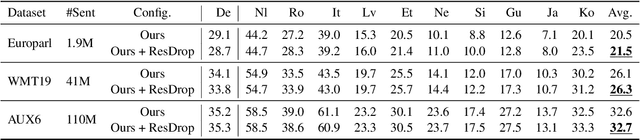
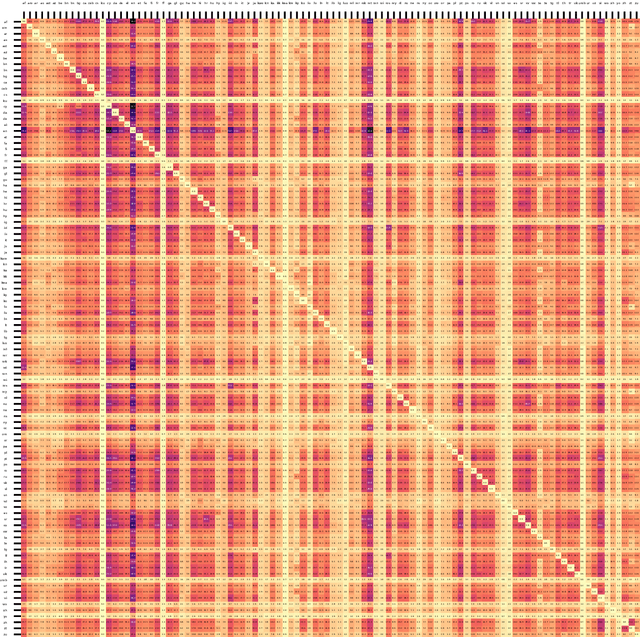
This paper demonstrates that multilingual pretraining, a proper fine-tuning method and a large-scale parallel dataset from multiple auxiliary languages are all critical for zero-shot translation, where the NMT model is tested on source languages unseen during supervised training. Following this idea, we present SixT++, a strong many-to-English NMT model that supports 100 source languages but is trained once with a parallel dataset from only six source languages. SixT++ initializes the decoder embedding and the full encoder with XLM-R large, and then trains the encoder and decoder layers with a simple two-stage training strategy. SixT++ achieves impressive performance on many-to-English translation. It significantly outperforms CRISS and m2m-100, two strong multilingual NMT systems, with an average gain of 7.2 and 5.0 BLEU respectively. Additionally, SixT++ offers a set of model parameters that can be further fine-tuned to develop unsupervised NMT models for low-resource languages. With back-translation on monolingual data of low-resource language, it outperforms all current state-of-the-art unsupervised methods on Nepali and Sinhal for both translating into and from English.
XLM-E: Cross-lingual Language Model Pre-training via ELECTRA
Jun 30, 2021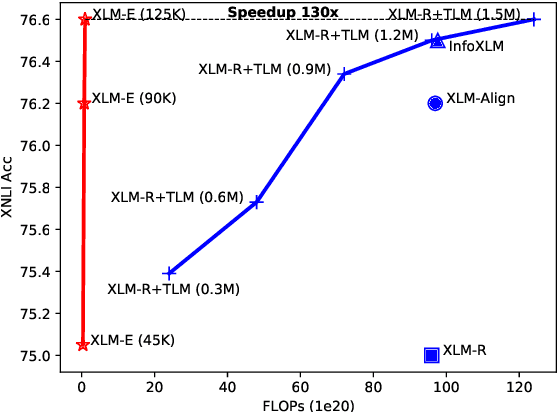
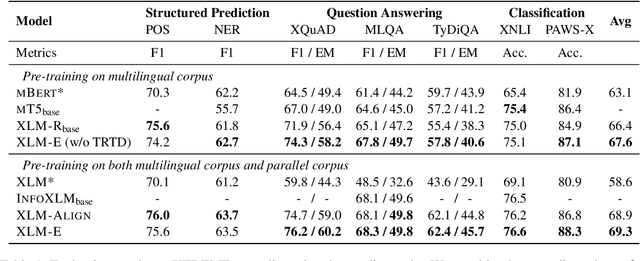
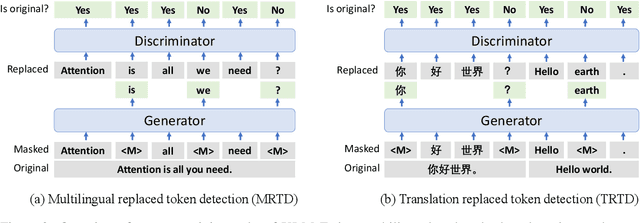
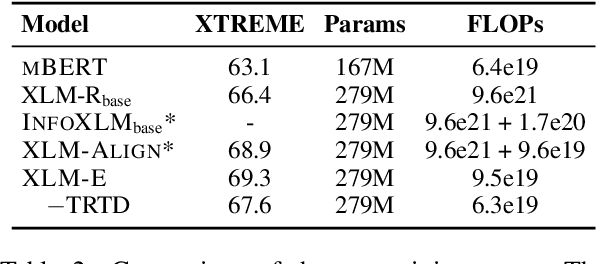
In this paper, we introduce ELECTRA-style tasks to cross-lingual language model pre-training. Specifically, we present two pre-training tasks, namely multilingual replaced token detection, and translation replaced token detection. Besides, we pretrain the model, named as XLM-E, on both multilingual and parallel corpora. Our model outperforms the baseline models on various cross-lingual understanding tasks with much less computation cost. Moreover, analysis shows that XLM-E tends to obtain better cross-lingual transferability.
DeltaLM: Encoder-Decoder Pre-training for Language Generation and Translation by Augmenting Pretrained Multilingual Encoders
Jun 25, 2021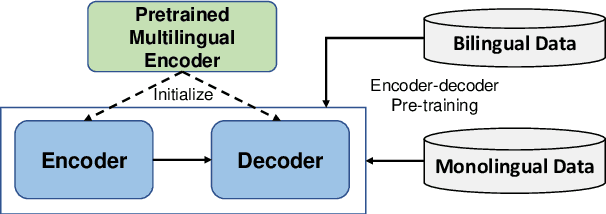

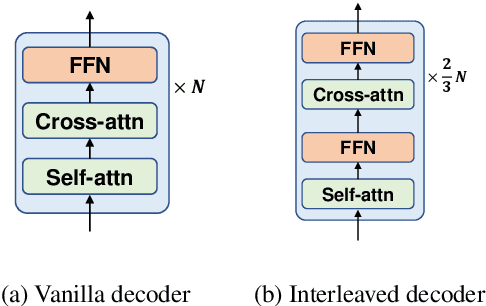
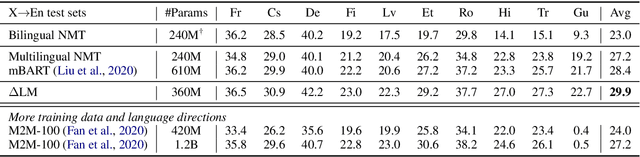
While pretrained encoders have achieved success in various natural language understanding (NLU) tasks, there is a gap between these pretrained encoders and natural language generation (NLG). NLG tasks are often based on the encoder-decoder framework, where the pretrained encoders can only benefit part of it. To reduce this gap, we introduce DeltaLM, a pretrained multilingual encoder-decoder model that regards the decoder as the task layer of off-the-shelf pretrained encoders. Specifically, we augment the pretrained multilingual encoder with a decoder and pre-train it in a self-supervised way. To take advantage of both the large-scale monolingual data and bilingual data, we adopt the span corruption and translation span corruption as the pre-training tasks. Experiments show that DeltaLM outperforms various strong baselines on both natural language generation and translation tasks, including machine translation, abstractive text summarization, data-to-text, and question generation.
How Does Distilled Data Complexity Impact the Quality and Confidence of Non-Autoregressive Machine Translation?
May 27, 2021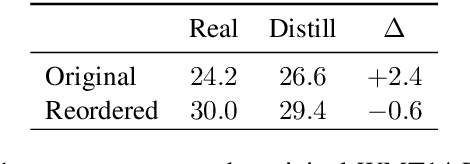
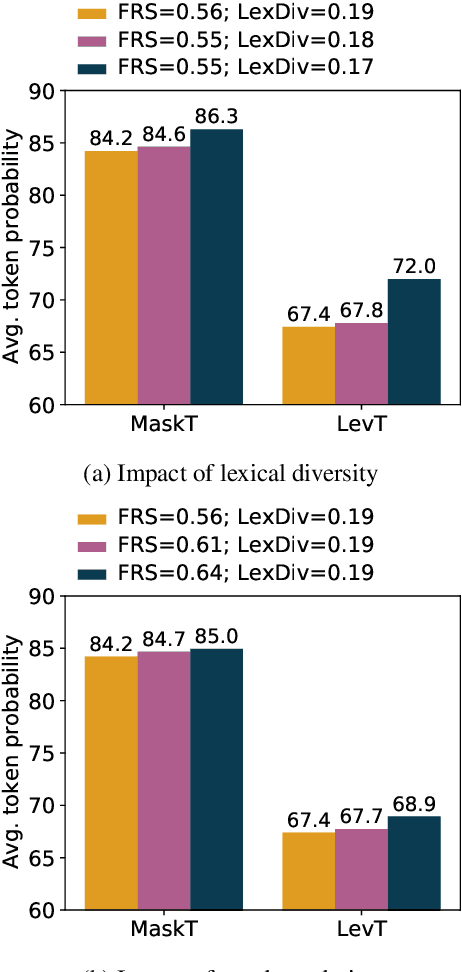
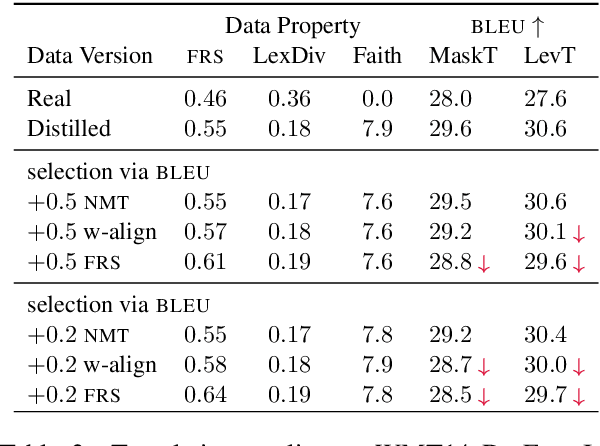
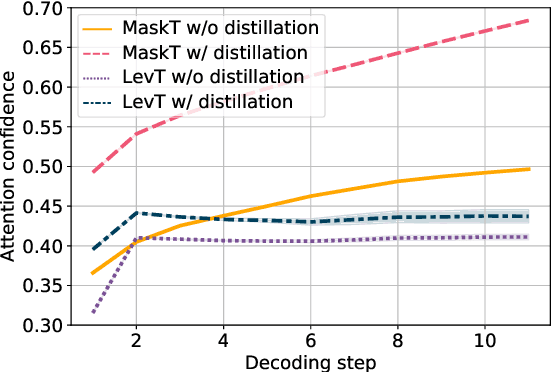
While non-autoregressive (NAR) models are showing great promise for machine translation, their use is limited by their dependence on knowledge distillation from autoregressive models. To address this issue, we seek to understand why distillation is so effective. Prior work suggests that distilled training data is less complex than manual translations. Based on experiments with the Levenshtein Transformer and the Mask-Predict NAR models on the WMT14 German-English task, this paper shows that different types of complexity have different impacts: while reducing lexical diversity and decreasing reordering complexity both help NAR learn better alignment between source and target, and thus improve translation quality, lexical diversity is the main reason why distillation increases model confidence, which affects the calibration of different NAR models differently.