 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRECALL: A Benchmark for LLMs Robustness against External Counterfactual Knowledge
Nov 14, 2023



LLMs and AI chatbots have improved people's efficiency in various fields. However, the necessary knowledge for answering the question may be beyond the models' knowledge boundaries. To mitigate this issue, many researchers try to introduce external knowledge, such as knowledge graphs and Internet contents, into LLMs for up-to-date information. However, the external information from the Internet may include counterfactual information that will confuse the model and lead to an incorrect response. Thus there is a pressing need for LLMs to possess the ability to distinguish reliable information from external knowledge. Therefore, to evaluate the ability of LLMs to discern the reliability of external knowledge, we create a benchmark from existing knowledge bases. Our benchmark consists of two tasks, Question Answering and Text Generation, and for each task, we provide models with a context containing counterfactual information. Evaluation results show that existing LLMs are susceptible to interference from unreliable external knowledge with counterfactual information, and simple intervention methods make limited contributions to the alleviation of this issue.
A Unified Framework for Multi-intent Spoken Language Understanding with prompting
Oct 07, 2022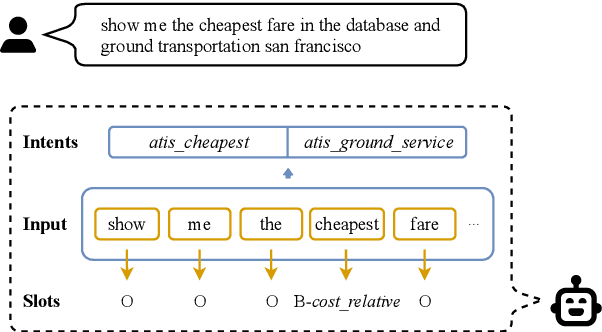
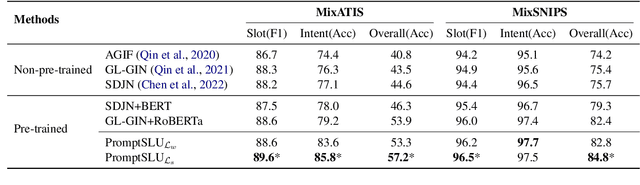
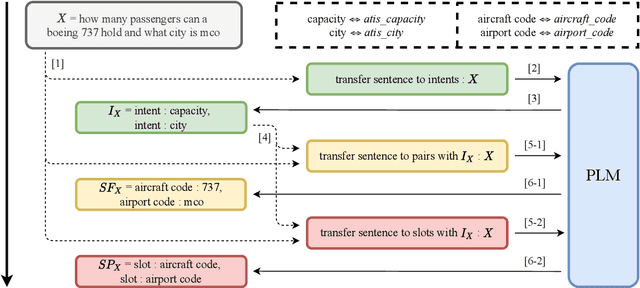
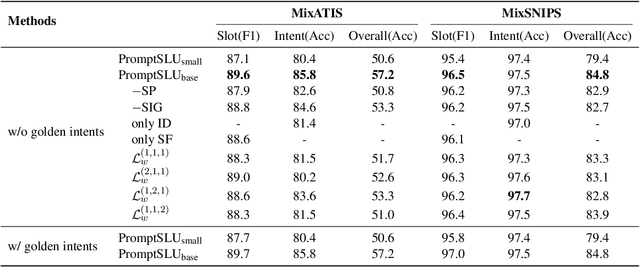
Multi-intent Spoken Language Understanding has great potential for widespread implementation. Jointly modeling Intent Detection and Slot Filling in it provides a channel to exploit the correlation between intents and slots. However, current approaches are apt to formulate these two sub-tasks differently, which leads to two issues: 1) It hinders models from effective extraction of shared features. 2) Pretty complicated structures are involved to enhance expression ability while causing damage to the interpretability of frameworks. In this work, we describe a Prompt-based Spoken Language Understanding (PromptSLU) framework, to intuitively unify two sub-tasks into the same form by offering a common pre-trained Seq2Seq model. In detail, ID and SF are completed by concisely filling the utterance into task-specific prompt templates as input, and sharing output formats of key-value pairs sequence. Furthermore, variable intents are predicted first, then naturally embedded into prompts to guide slot-value pairs inference from a semantic perspective. Finally, we are inspired by prevalent multi-task learning to introduce an auxiliary sub-task, which helps to learn relationships among provided labels. Experiment results show that our framework outperforms several state-of-the-art baselines on two public datasets.
Incorporating Hierarchy into Text Encoder: a Contrastive Learning Approach for Hierarchical Text Classification
Mar 23, 2022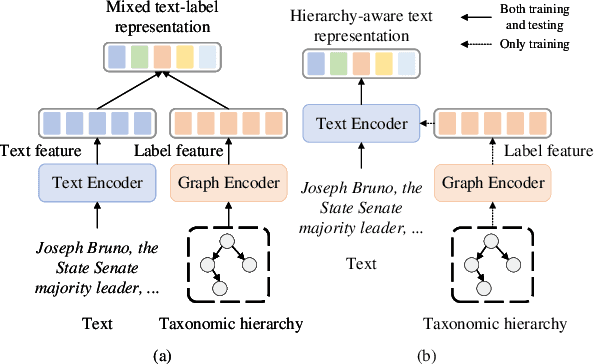
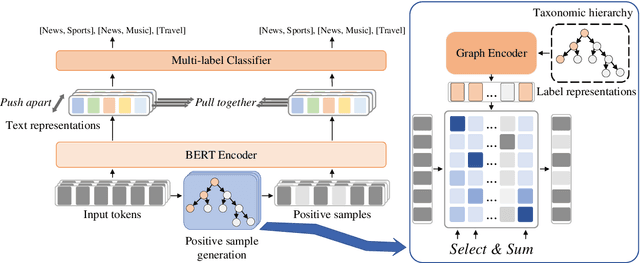
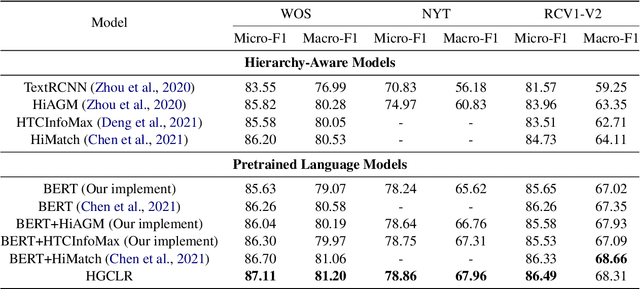
Hierarchical text classification is a challenging subtask of multi-label classification due to its complex label hierarchy. Existing methods encode text and label hierarchy separately and mix their representations for classification, where the hierarchy remains unchanged for all input text. Instead of modeling them separately, in this work, we propose Hierarchy-guided Contrastive Learning (HGCLR) to directly embed the hierarchy into a text encoder. During training, HGCLR constructs positive samples for input text under the guidance of the label hierarchy. By pulling together the input text and its positive sample, the text encoder can learn to generate the hierarchy-aware text representation independently. Therefore, after training, the HGCLR enhanced text encoder can dispense with the redundant hierarchy. Extensive experiments on three benchmark datasets verify the effectiveness of HGCLR.
Zero-shot Cross-lingual Transfer of Prompt-based Tuning with a Unified Multilingual Prompt
Feb 23, 2022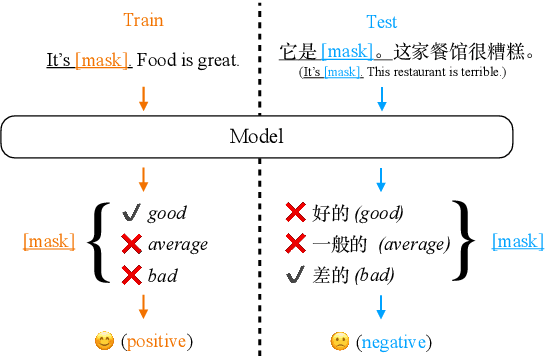

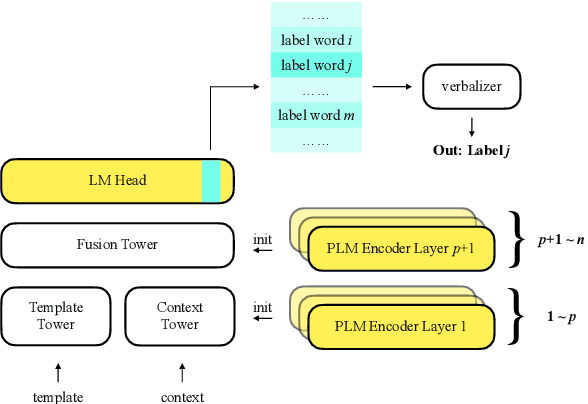
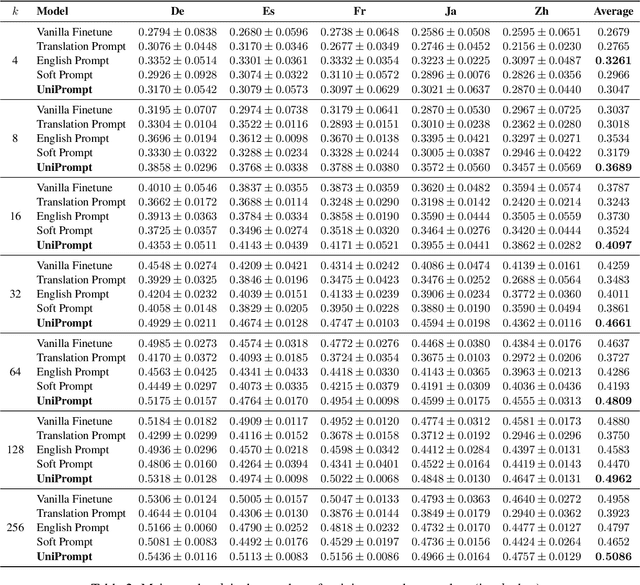
Prompt-based tuning has been proven effective for pretrained language models (PLMs). While most of the existing work focuses on the monolingual prompts, we study the multilingual prompts for multilingual PLMs, especially in the zero-shot cross-lingual setting. To alleviate the effort of designing different prompts for multiple languages, we propose a novel model that uses a unified prompt for all languages, called UniPrompt. Different from the discrete prompts and soft prompts, the unified prompt is model-based and language-agnostic. Specifically, the unified prompt is initialized by a multilingual PLM to produce language-independent representation, after which is fused with the text input. During inference, the prompts can be pre-computed so that no extra computation cost is needed. To collocate with the unified prompt, we propose a new initialization method for the target label word to further improve the model's transferability across languages. Extensive experiments show that our proposed methods can significantly outperform the strong baselines across different languages. We will release data and code to facilitate future research.
Explicit Interaction Network for Aspect Sentiment Triplet Extraction
Jun 21, 2021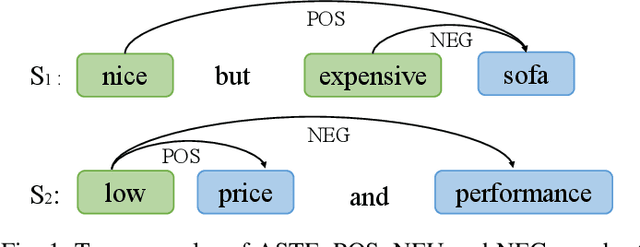
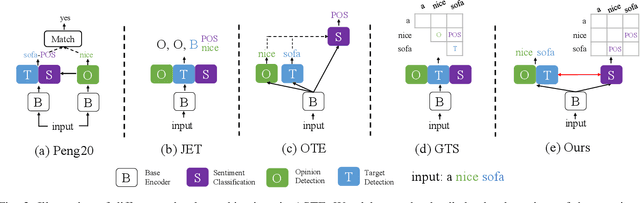
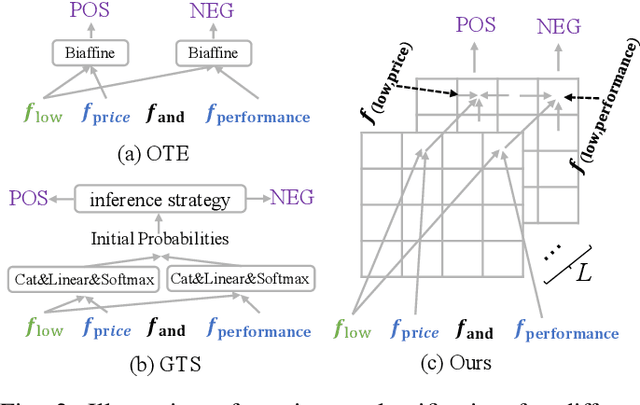
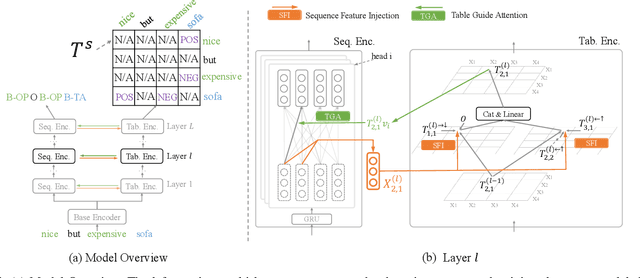
Aspect Sentiment Triplet Extraction (ASTE) aims to recognize targets, their sentiment polarities and opinions explaining the sentiment from a sentence. ASTE could be naturally divided into 3 atom subtasks, namely target detection, opinion detection and sentiment classification. We argue that the proper subtask combination, compositional feature extraction for target-opinion pairs, and interaction between subtasks would be the key to success. Prior work, however, may fail on `one-to-many' or `many-to-one' situations, or derive non-existent sentiment triplets due to defective subtask formulation, sub-optimal feature representation or the lack of subtask interaction. In this paper, we divide ASTE into target-opinion joint detection and sentiment classification subtasks, which is in line with human cognition, and correspondingly propose sequence encoder and table encoder. Table encoder extracts sentiment at token-pair level, so that the compositional feature between targets and opinions can be easily captured. To establish explicit interaction between subtasks, we utilize the table representation to guide the sequence encoding, and inject the sequence features back into the table encoder. Experiments show that our model outperforms state-of-the-art methods on six popular ASTE datasets.
First Target and Opinion then Polarity: Enhancing Target-opinion Correlation for Aspect Sentiment Triplet Extraction
Feb 22, 2021

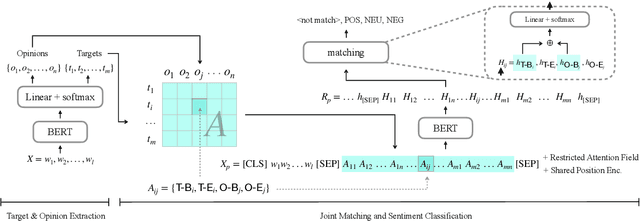
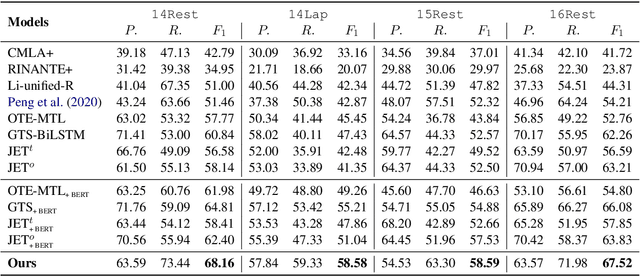
Aspect Sentiment Triplet Extraction (ASTE) aims to extract triplets from a sentence, including target entities, associated sentiment polarities, and opinion spans which rationalize the polarities. Existing methods are short on building correlation between target-opinion pairs, and neglect the mutual interference among different sentiment triplets. To address these issues, we propose a novel two-stage method which enhances the correlation between targets and opinions: at stage one, we extract targets and opinions through sequence tagging; then we insert a group of artificial tags named Perceivable Pair, which indicate the span of the target and the opinion, into the sequence to establish correlation for each candidate target-opinion pair. Meanwhile, we reduce the mutual interference between triplets by restricting tokens' attention field. Finally, the polarity is identified according to the representation of the Perceivable Pair. We conduct experiments on four datasets, and the experimental results show that our model outperforms the state-of-the-art methods.
Text Level Graph Neural Network for Text Classification
Oct 08, 2019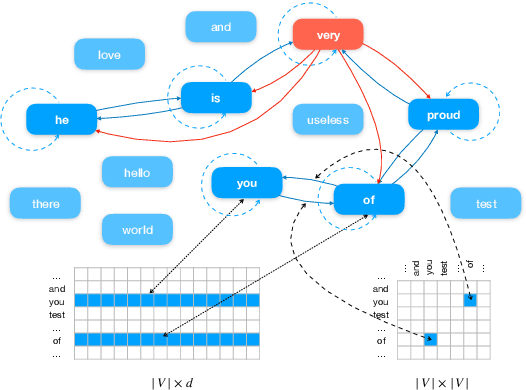
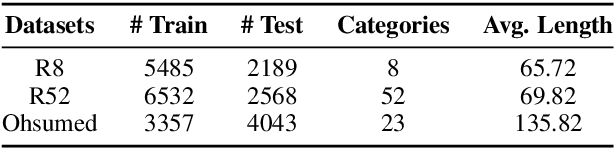
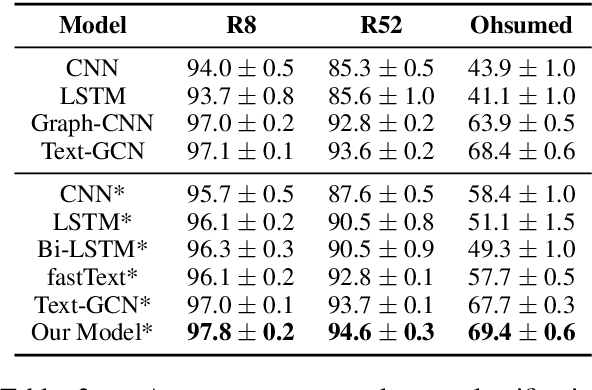
Recently, researches have explored the graph neural network (GNN) techniques on text classification, since GNN does well in handling complex structures and preserving global information. However, previous methods based on GNN are mainly faced with the practical problems of fixed corpus level graph structure which do not support online testing and high memory consumption. To tackle the problems, we propose a new GNN based model that builds graphs for each input text with global parameters sharing instead of a single graph for the whole corpus. This method removes the burden of dependence between an individual text and entire corpus which support online testing, but still preserve global information. Besides, we build graphs by much smaller windows in the text, which not only extract more local features but also significantly reduce the edge numbers as well as memory consumption. Experiments show that our model outperforms existing models on several text classification datasets even with consuming less memory.