 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePANDA: Prototypical Unsupervised Domain Adaptation
Apr 12, 2020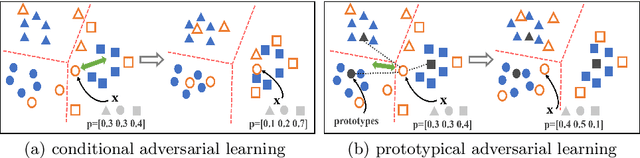
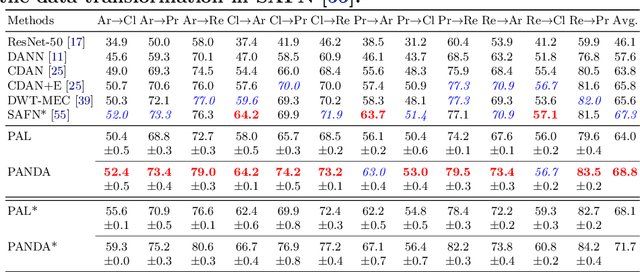
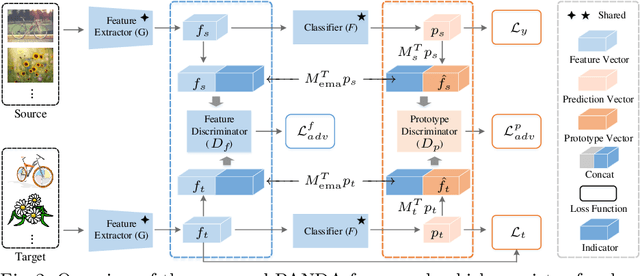
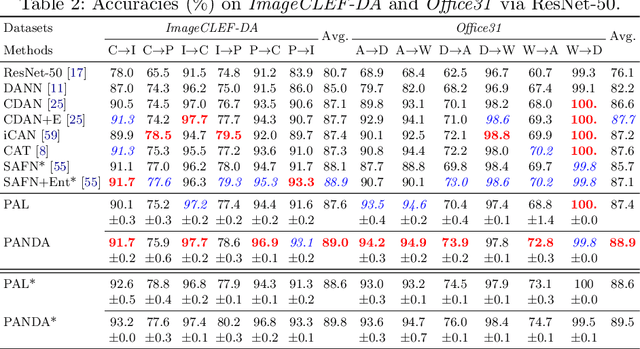
Previous adversarial domain alignment methods for unsupervised domain adaptation (UDA) pursue conditional domain alignment via intermediate pseudo labels. However, these pseudo labels are generated by independent instances without considering the global data structure and tend to be noisy, making them unreliable for adversarial domain adaptation. Compared with pseudo labels, prototypes are more reliable to represent the data structure resistant to the domain shift since they are summarized over all the relevant instances. In this work, we attempt to calibrate the noisy pseudo labels with prototypes. Specifically, we first obtain a reliable prototypical representation for each instance by multiplying the soft instance predictions with the global prototypes. Based on the prototypical representation, we propose a novel Prototypical Adversarial Learning (PAL) scheme and exploit it to align both feature representations and intermediate prototypes across domains. Besides, with the intermediate prototypes as a proxy, we further minimize the intra-class variance in the target domain to adaptively improve the pseudo labels. Integrating the three objectives, we develop an unified framework termed PrototypicAl uNsupervised Domain Adaptation (PANDA) for UDA. Experiments show that PANDA achieves state-of-the-art or competitive results on multiple UDA benchmarks including both object recognition and semantic segmentation tasks.
Highly Efficient Salient Object Detection with 100K Parameters
Mar 12, 2020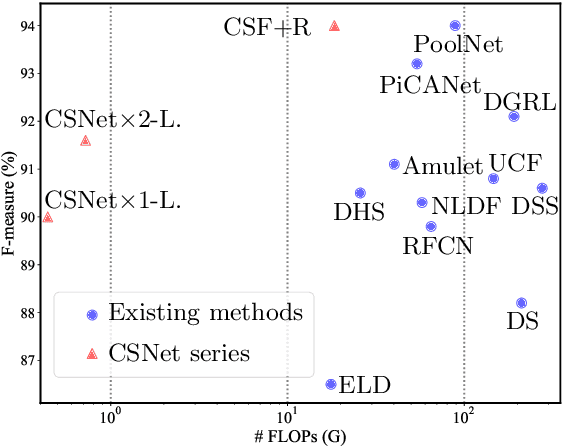
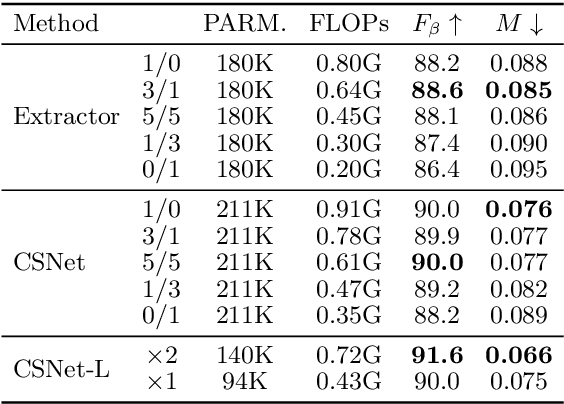
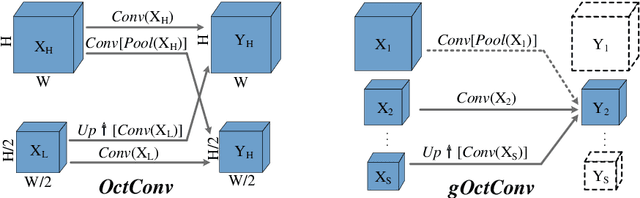
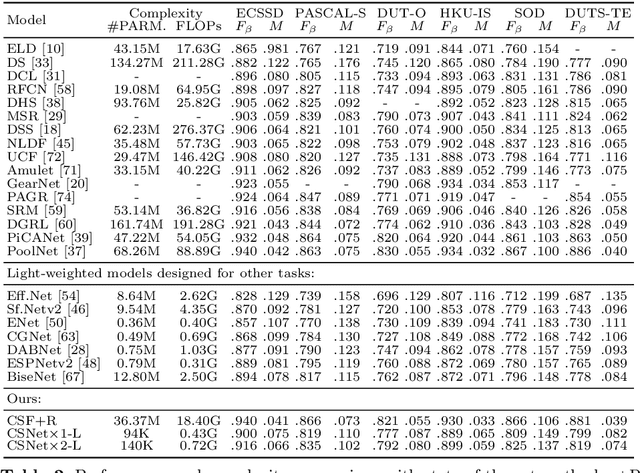
Salient object detection models often demand a considerable amount of computation cost to make precise prediction for each pixel, making them hardly applicable on low-power devices. In this paper, we aim to relieve the contradiction between computation cost and model performance by improving the network efficiency to a higher degree. We propose a flexible convolutional module, namely generalized OctConv (gOctConv), to efficiently utilize both in-stage and cross-stages multi-scale features, while reducing the representation redundancy by a novel dynamic weight decay scheme. The effective dynamic weight decay scheme stably boosts the sparsity of parameters during training, supports learnable number of channels for each scale in gOctConv, allowing 80% of parameters reduce with negligible performance drop. Utilizing gOctConv, we build an extremely light-weighted model, namely CSNet, which achieves comparable performance with about 0.2% parameters (100k) of large models on popular salient object detection benchmarks.
Fast Dense Residual Network: Enhancing Global Dense Feature Flow for Text Recognition
Jan 23, 2020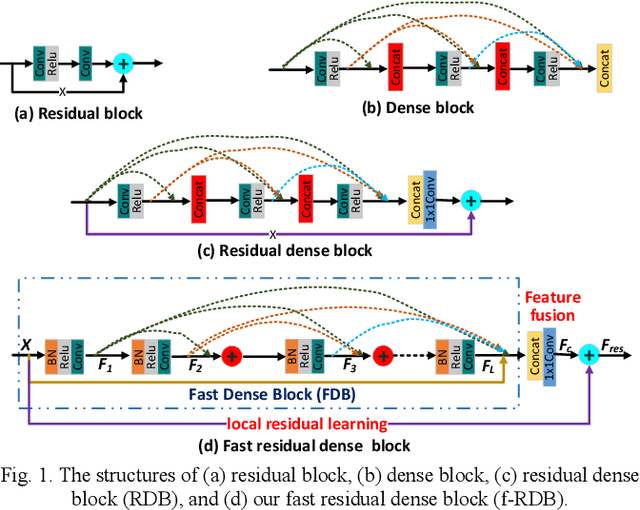
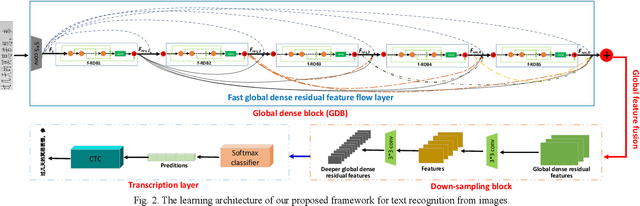
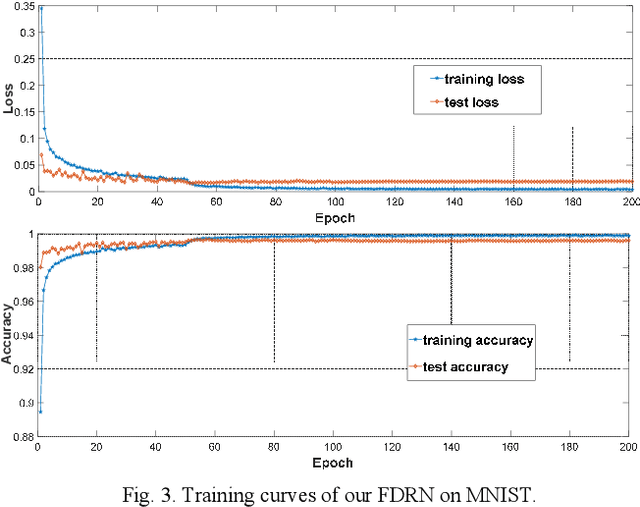
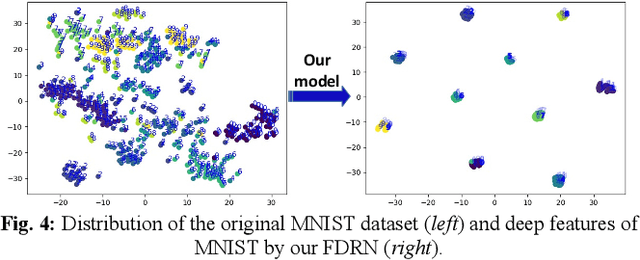
Deep Convolutional Neural Networks (CNNs), such as Dense Convolutional Networks (DenseNet), have achieved great success for image representation by discovering deep hierarchical information. However, most existing networks simply stacks the convolutional layers and hence failing to fully discover local and global feature information among layers. In this paper, we mainly explore how to enhance the local and global dense feature flow by exploiting hierarchical features fully from all the convolution layers. Technically, we propose an efficient and effective CNN framework, i.e., Fast Dense Residual Network (FDRN), for text recognition. To construct FDRN, we propose a new fast residual dense block (f-RDB) to retain the ability of local feature fusion and local residual learning of original RDB, which can reduce the computing efforts at the same time. After fully learning local residual dense features, we utilize the sum operation and several f-RDBs to define a new block termed global dense block (GDB) by imitating the construction of dense blocks to learn global dense residual features adaptively in a holistic way. Finally, we use two convolution layers to construct a down-sampling block to reduce the global feature size and extract deeper features. Extensive simulations show that FDRN obtains the enhanced recognition results, compared with other related models.
DerainCycleGAN: An Attention-guided Unsupervised Benchmark for Single Image Deraining and Rainmaking
Jan 15, 2020
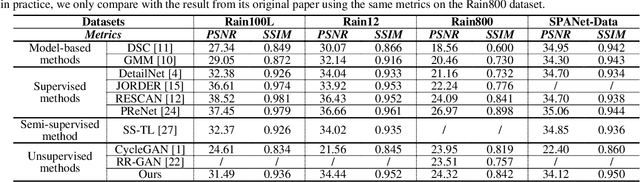


Single image deraining (SID) is an important and challenging topic in emerging vision applications, and most of emerged deraining methods are supervised relying on the ground truth (i.e., paired images) in recent years. However, in practice it is rather common to have no un-paired images in real deraining task, in such cases how to remove the rain streaks in an unsupervised way will be a very challenging task due to lack of constraints between images and hence suffering from low-quality recovery results. In this paper, we explore the unsupervised SID task using unpaired data and propose a novel net called Attention-guided Deraining by Constrained CycleGAN (or shortly, DerainCycleGAN), which can fully utilize the constrained transfer learning abilitiy and circulatory structure of CycleGAN. Specifically, we design an unsu-pervised attention guided rain streak extractor (U-ARSE) that utilizes a memory to extract the rain streak masks with two constrained cycle-consistency branches jointly by paying attention to both the rainy and rain-free image domains. As a by-product, we also contribute a new paired rain image dataset called Rain200A, which is constructed by our network automatically. Compared with existing synthesis datasets, the rainy streaks in Rain200A contains more obvious and diverse shapes and directions. As a result, existing supervised methods trained on Rain200A can perform much better for processing real rainy images. Extensive experiments on synthesis and real datasets show that our net is superior to existing unsupervised deraining networks, and is also very competitive to other related supervised networks.
Multilayer Collaborative Low-Rank Coding Network for Robust Deep Subspace Discovery
Jan 15, 2020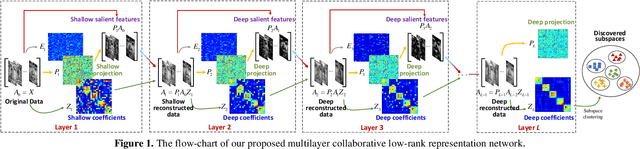
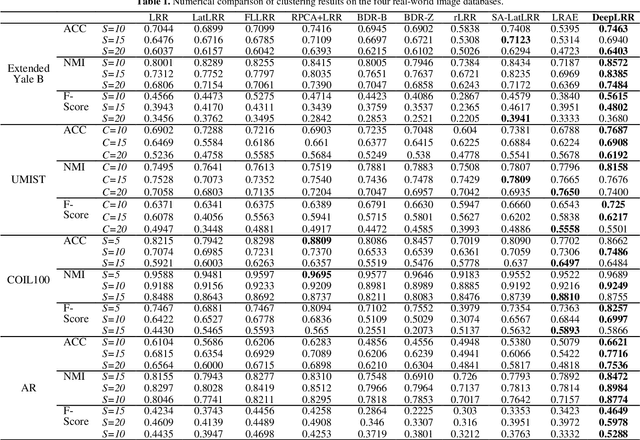


For subspace recovery, most existing low-rank representation (LRR) models performs in the original space in single-layer mode. As such, the deep hierarchical information cannot be learned, which may result in inaccurate recoveries for complex real data. In this paper, we explore the deep multi-subspace recovery problem by designing a multilayer architecture for latent LRR. Technically, we propose a new Multilayer Collabora-tive Low-Rank Representation Network model termed DeepLRR to discover deep features and deep subspaces. In each layer (>2), DeepLRR bilinearly reconstructs the data matrix by the collabo-rative representation with low-rank coefficients and projection matrices in the previous layer. The bilinear low-rank reconstruc-tion of previous layer is directly fed into the next layer as the input and low-rank dictionary for representation learning, and is further decomposed into a deep principal feature part, a deep salient feature part and a deep sparse error. As such, the coher-ence issue can be also resolved due to the low-rank dictionary, and the robustness against noise can also be enhanced in the feature subspace. To recover the sparse errors in layers accurately, a dynamic growing strategy is used, as the noise level will be-come smaller for the increase of layers. Besides, a neighborhood reconstruction error is also included to encode the locality of deep salient features by deep coefficients adaptively in each layer. Extensive results on public databases show that our DeepLRR outperforms other related models for subspace discovery and clustering.
Convolutional Dictionary Pair Learning Network for Image Representation Learning
Jan 15, 2020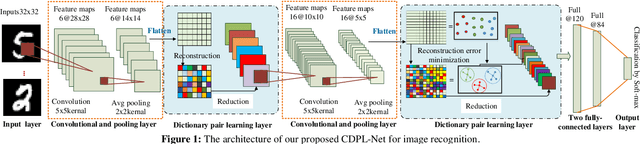
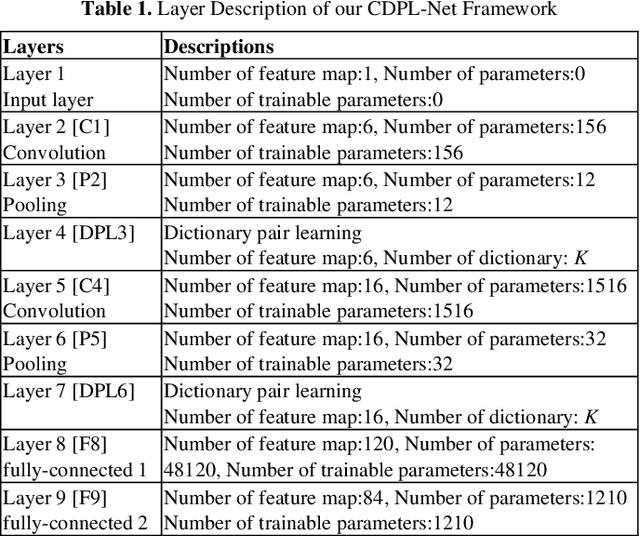
Both the Dictionary Learning (DL) and Convolutional Neural Networks (CNN) are powerful image representation learning systems based on different mechanisms and principles, however whether we can seamlessly integrate them to improve the per-formance is noteworthy exploring. To address this issue, we propose a novel generalized end-to-end representation learning architecture, dubbed Convolutional Dictionary Pair Learning Network (CDPL-Net) in this paper, which integrates the learning schemes of the CNN and dictionary pair learning into a unified framework. Generally, the architecture of CDPL-Net includes two convolutional/pooling layers and two dictionary pair learn-ing (DPL) layers in the representation learning module. Besides, it uses two fully-connected layers as the multi-layer perception layer in the nonlinear classification module. In particular, the DPL layer can jointly formulate the discriminative synthesis and analysis representations driven by minimizing the batch based reconstruction error over the flatted feature maps from the convolution/pooling layer. Moreover, DPL layer uses l1-norm on the analysis dictionary so that sparse representation can be delivered, and the embedding process will also be robust to noise. To speed up the training process of DPL layer, the efficient stochastic gradient descent is used. Extensive simulations on real databases show that our CDPL-Net can deliver enhanced performance over other state-of-the-art methods.
RC-DARTS: Resource Constrained Differentiable Architecture Search
Dec 30, 2019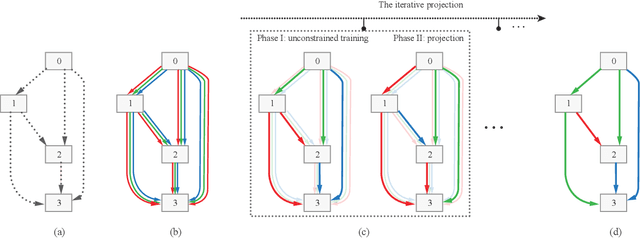
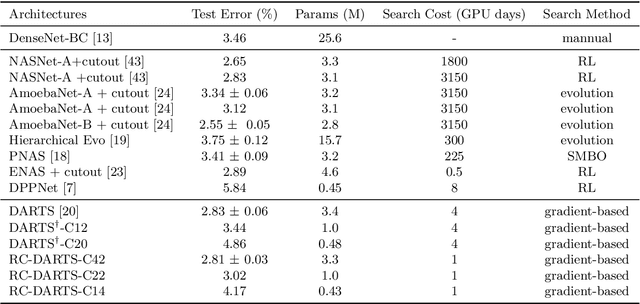
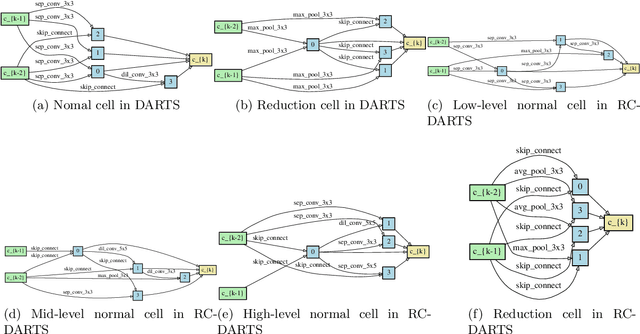
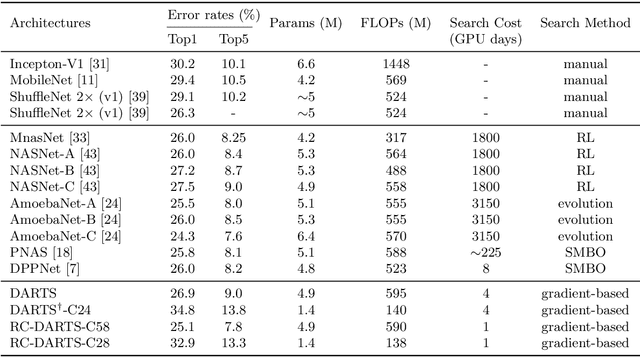
Recent advances show that Neural Architectural Search (NAS) method is able to find state-of-the-art image classification deep architectures. In this paper, we consider the one-shot NAS problem for resource constrained applications. This problem is of great interest because it is critical to choose different architectures according to task complexity when the resource is constrained. Previous techniques are either too slow for one-shot learning or does not take the resource constraint into consideration. In this paper, we propose the resource constrained differentiable architecture search (RC-DARTS) method to learn architectures that are significantly smaller and faster while achieving comparable accuracy. Specifically, we propose to formulate the RC-DARTS task as a constrained optimization problem by adding the resource constraint. An iterative projection method is proposed to solve the given constrained optimization problem. We also propose a multi-level search strategy to enable layers at different depths to adaptively learn different types of neural architectures. Through extensive experiments on the Cifar10 and ImageNet datasets, we show that the RC-DARTS method learns lightweight neural architectures which have smaller model size and lower computational complexity while achieving comparable or better performances than the state-of-the-art methods.
Very Long Natural Scenery Image Prediction by Outpainting
Dec 29, 2019
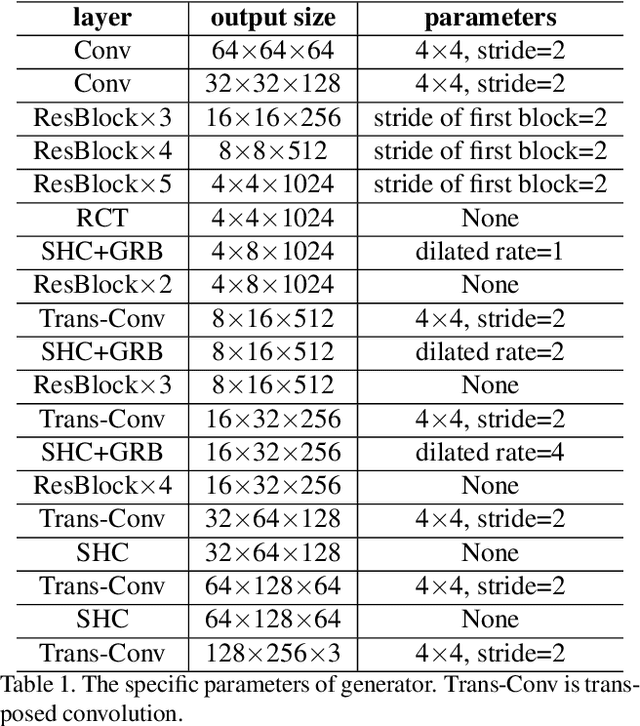

Comparing to image inpainting, image outpainting receives less attention due to two challenges in it. The first challenge is how to keep the spatial and content consistency between generated images and original input. The second challenge is how to maintain high quality in generated results, especially for multi-step generations in which generated regions are spatially far away from the initial input. To solve the two problems, we devise some innovative modules, named Skip Horizontal Connection and Recurrent Content Transfer, and integrate them into our designed encoder-decoder structure. By this design, our network can generate highly realistic outpainting prediction effectively and efficiently. Other than that, our method can generate new images with very long sizes while keeping the same style and semantic content as the given input. To test the effectiveness of the proposed architecture, we collect a new scenery dataset with diverse, complicated natural scenes. The experimental results on this dataset have demonstrated the efficacy of our proposed network. The code and dataset are available from https://github.com/z-x-yang/NS-Outpainting.
Learning Hybrid Representation by Robust Dictionary Learning in Factorized Compressed Space
Dec 26, 2019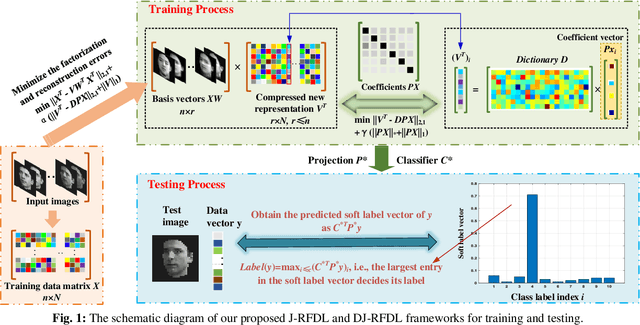

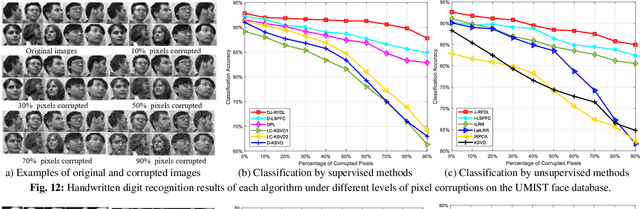
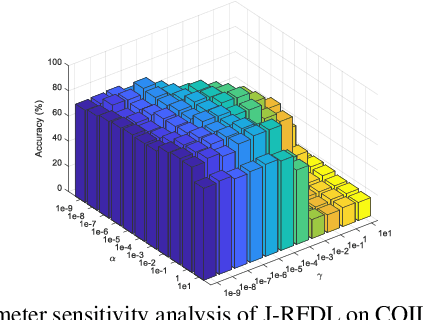
In this paper, we investigate the robust dictionary learning (DL) to discover the hybrid salient low-rank and sparse representation in a factorized compressed space. A Joint Robust Factorization and Projective Dictionary Learning (J-RFDL) model is presented. The setting of J-RFDL aims at improving the data representations by enhancing the robustness to outliers and noise in data, encoding the reconstruction error more accurately and obtaining hybrid salient coefficients with accurate reconstruction ability. Specifically, J-RFDL performs the robust representation by DL in a factorized compressed space to eliminate the negative effects of noise and outliers on the results, which can also make the DL process efficient. To make the encoding process robust to noise in data, J-RFDL clearly uses sparse L2, 1-norm that can potentially minimize the factorization and reconstruction errors jointly by forcing rows of the reconstruction errors to be zeros. To deliver salient coefficients with good structures to reconstruct given data well, J-RFDL imposes the joint low-rank and sparse constraints on the embedded coefficients with a synthesis dictionary. Based on the hybrid salient coefficients, we also extend J-RFDL for the joint classification and propose a discriminative J-RFDL model, which can improve the discriminating abilities of learnt coeffi-cients by minimizing the classification error jointly. Extensive experiments on public datasets demonstrate that our formulations can deliver superior performance over other state-of-the-art methods.
Asymmetric GAN for Unpaired Image-to-image Translation
Dec 25, 2019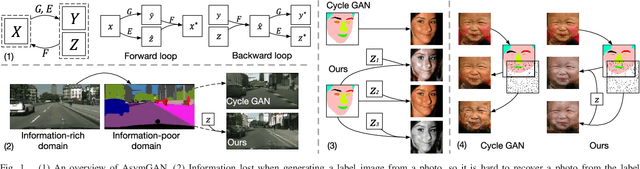
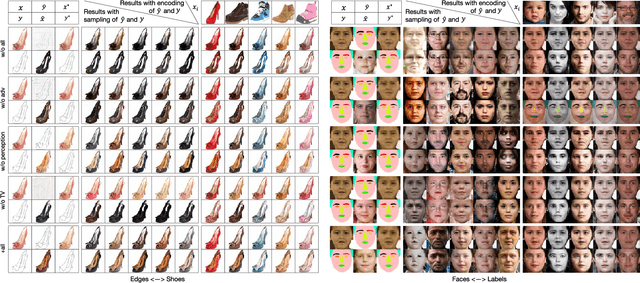


Unpaired image-to-image translation problem aims to model the mapping from one domain to another with unpaired training data. Current works like the well-acknowledged Cycle GAN provide a general solution for any two domains through modeling injective mappings with a symmetric structure. While in situations where two domains are asymmetric in complexity, i.e., the amount of information between two domains is different, these approaches pose problems of poor generation quality, mapping ambiguity, and model sensitivity. To address these issues, we propose Asymmetric GAN (AsymGAN) to adapt the asymmetric domains by introducing an auxiliary variable (aux) to learn the extra information for transferring from the information-poor domain to the information-rich domain, which improves the performance of state-of-the-art approaches in the following ways. First, aux better balances the information between two domains which benefits the quality of generation. Second, the imbalance of information commonly leads to mapping ambiguity, where we are able to model one-to-many mappings by tuning aux, and furthermore, our aux is controllable. Third, the training of Cycle GAN can easily make the generator pair sensitive to small disturbances and variations while our model decouples the ill-conditioned relevance of generators by injecting aux during training. We verify the effectiveness of our proposed method both qualitatively and quantitatively on asymmetric situation, label-photo task, on Cityscapes and Helen datasets, and show many applications of asymmetric image translations. In conclusion, our AsymGAN provides a better solution for unpaired image-to-image translation in asymmetric domains.
* Accepted by IEEE Transactions on Image Processing (TIP) 2019