 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Dense Residual Network: Enhancing Global Dense Feature Flow for Text Recognition
Jan 23, 2020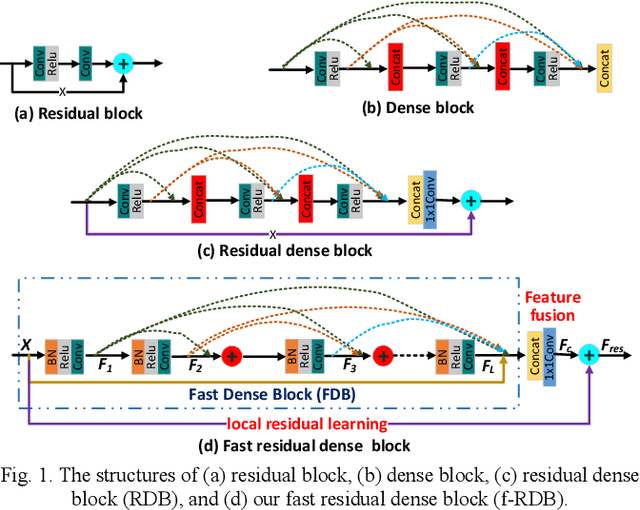
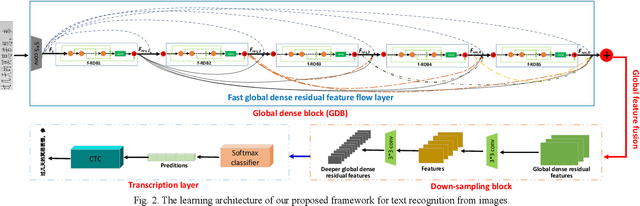
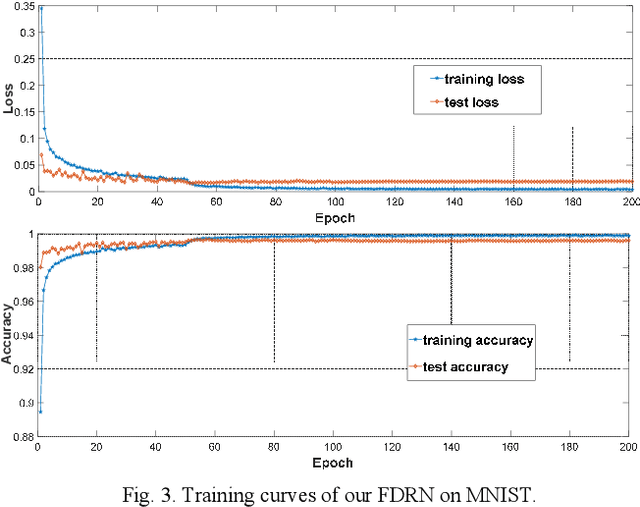
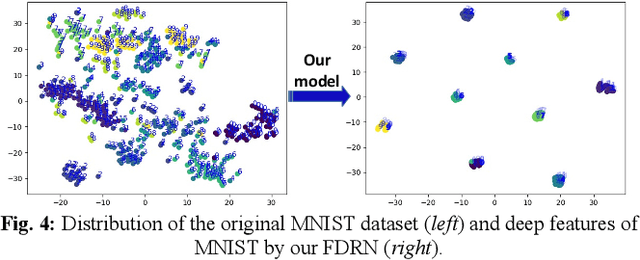
Deep Convolutional Neural Networks (CNNs), such as Dense Convolutional Networks (DenseNet), have achieved great success for image representation by discovering deep hierarchical information. However, most existing networks simply stacks the convolutional layers and hence failing to fully discover local and global feature information among layers. In this paper, we mainly explore how to enhance the local and global dense feature flow by exploiting hierarchical features fully from all the convolution layers. Technically, we propose an efficient and effective CNN framework, i.e., Fast Dense Residual Network (FDRN), for text recognition. To construct FDRN, we propose a new fast residual dense block (f-RDB) to retain the ability of local feature fusion and local residual learning of original RDB, which can reduce the computing efforts at the same time. After fully learning local residual dense features, we utilize the sum operation and several f-RDBs to define a new block termed global dense block (GDB) by imitating the construction of dense blocks to learn global dense residual features adaptively in a holistic way. Finally, we use two convolution layers to construct a down-sampling block to reduce the global feature size and extract deeper features. Extensive simulations show that FDRN obtains the enhanced recognition results, compared with other related models.
Fully-Convolutional Intensive Feature Flow Neural Network for Text Recognition
Jan 15, 2020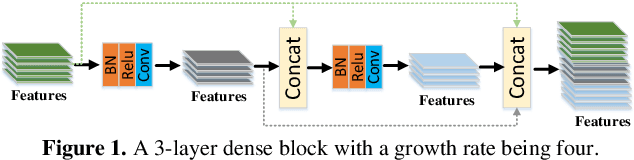
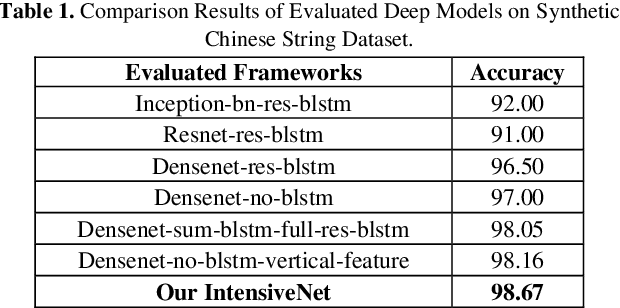
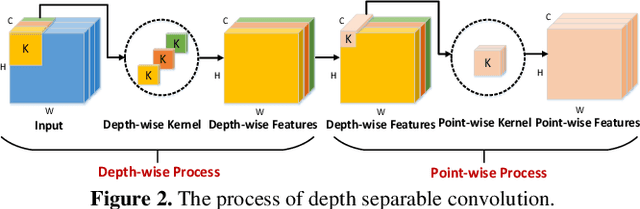
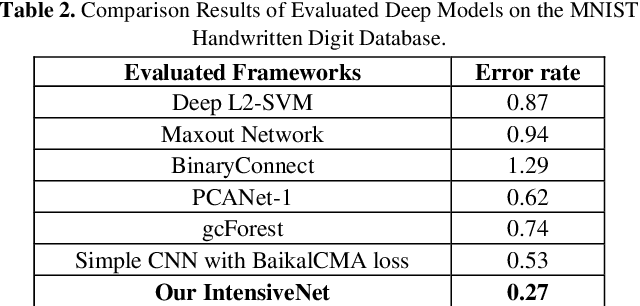
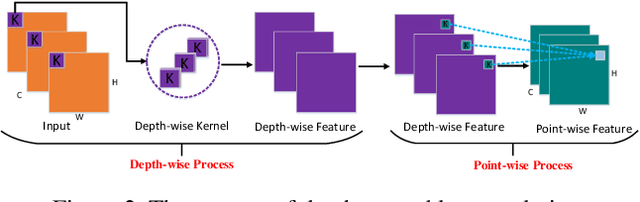
The Deep Convolutional Neural Networks (CNNs) have obtained a great success for pattern recognition, such as recognizing the texts in images. But existing CNNs based frameworks still have several drawbacks: 1) the traditaional pooling operation may lose important feature information and is unlearnable; 2) the tradi-tional convolution operation optimizes slowly and the hierar-chical features from different layers are not fully utilized. In this work, we address these problems by developing a novel deep network model called Fully-Convolutional Intensive Feature Flow Neural Network (IntensiveNet). Specifically, we design a further dense block called intensive block to extract the feature information, where the original inputs and two dense blocks are connected tightly. To encode data appropriately, we present the concepts of dense fusion block and further dense fusion opera-tions for our new intensive block. By adding short connections to different layers, the feature flow and coupling between layers are enhanced. We also replace the traditional convolution by depthwise separable convolution to make the operation efficient. To prevent important feature information being lost to a certain extent, we use a convolution operation with stride 2 to replace the original pooling operation in the customary transition layers. The recognition results on large-scale Chinese string and MNIST datasets show that our IntensiveNet can deliver enhanced recog-nition results, compared with other related deep models.
Fast DenseNet: Towards Efficient and Accurate Text Recognition with Fast Dense Networks
Dec 15, 2019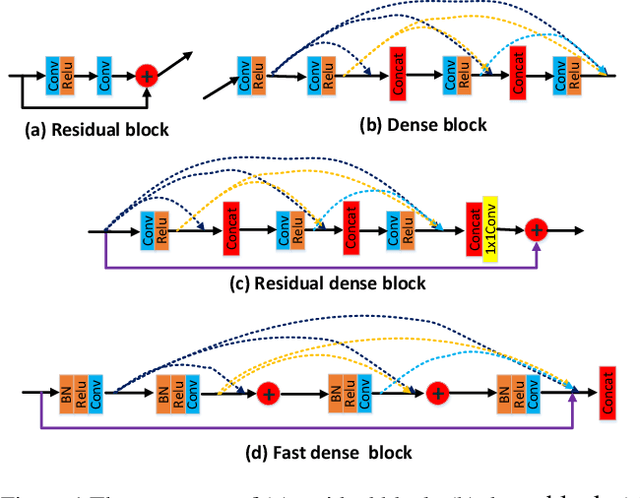

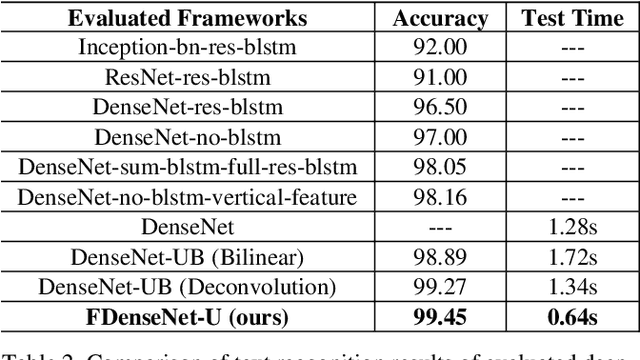
Convolutional Recurrent Neural Network (CRNN) is a popular network for recognizing texts in images. Advances like the variants of CRNN, such as Dense Convolutional Network with Connectionist Temporal Classification, has reduced the running time of the networks, but exposing the inner computation cost of the convolutional networks as a bottleneck. Specifically, DenseNet based frameworks use the dense blocks as the core module, but the inner features are combined in the form of concatenation in dense blocks. As a result, the number of channels of combined features delivered as the input of the layers close to the output and the relevant computational cost grows rapidly with the dense blocks getting deeper. This will severely bring heavy computational cost and restrict the depth of dense blocks. In this paper, we propose an efficient convolutional block called Fast Dense Block (FDB). To reduce the computing cost, we redefine and design the way of combining internal features of dense blocks. FDB is a convolutional block similarly as the dense block, but it applies both sum and concatenating operations to connect the inner features in blocks, which can reduce the computation cost to (1/L, 2/L), compared with the original dense block, where L is the number of layers in the dense block. Importantly, since the parameters of standard dense block and our new FDB keep consistent except the way of combining features, and their inputs and outputs have the same size and same number of channels, so FDB can be easily used to replace the original dense block in any DenseNet based framework. Based on the designed FDBs, we further propose a fast network of DenseNet to improve the text recognition performance in images.