 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Promoted Supervision for Few-Shot Transformer
Mar 14, 2022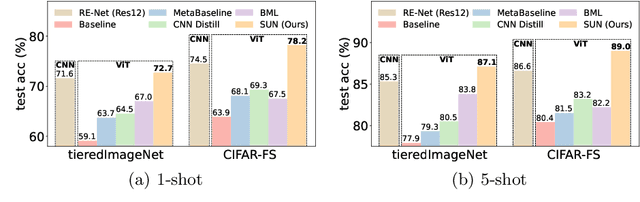
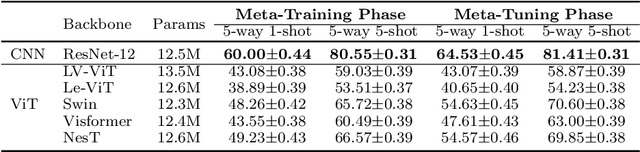
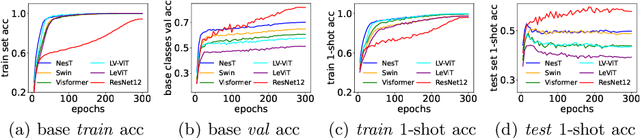
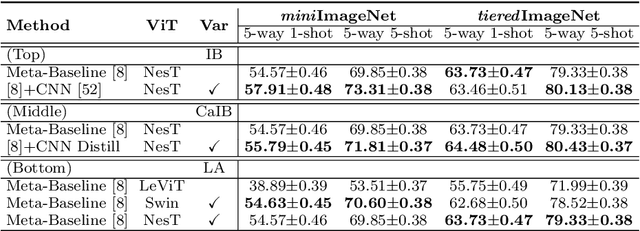
The few-shot learning ability of vision transformers (ViTs) is rarely investigated though heavily desired. In this work, we empirically find that with the same few-shot learning frameworks, e.g., Meta-Baseline, replacing the widely used CNN feature extractor with a ViT model often severely impairs few-shot classification performance. Moreover, our empirical study shows that in the absence of inductive bias, ViTs often learn the dependencies among input tokens slowly under few-shot learning regime where only a few labeled training data are available, which largely contributes to the above performance degradation. To alleviate this issue, for the first time, we propose a simple yet effective few-shot training framework for ViTs, namely Self-promoted sUpervisioN (SUN). Specifically, besides the conventional global supervision for global semantic learning, SUN further pretrains the ViT on the few-shot learning dataset and then uses it to generate individual location-specific supervision for guiding each patch token. This location-specific supervision tells the ViT which patch tokens are similar or dissimilar and thus accelerates token dependency learning. Moreover, it models the local semantics in each patch token to improve the object grounding and recognition capability which helps learn generalizable patterns. To improve the quality of location-specific supervision, we further propose two techniques:~1) background patch filtration to filtrate background patches out and assign them into an extra background class; and 2) spatial-consistent augmentation to introduce sufficient diversity for data augmentation while keeping the accuracy of the generated local supervisions. Experimental results show that SUN using ViTs significantly surpasses other few-shot learning frameworks with ViTs and is the first one that achieves higher performance than those CNN state-of-the-arts.
Modern Augmented Reality: Applications, Trends, and Future Directions
Feb 24, 2022



Augmented reality (AR) is one of the relatively old, yet trending areas in the intersection of computer vision and computer graphics with numerous applications in several areas, from gaming and entertainment, to education and healthcare. Although it has been around for nearly fifty years, it has seen a lot of interest by the research community in the recent years, mainly because of the huge success of deep learning models for various computer vision and AR applications, which made creating new generations of AR technologies possible. This work tries to provide an overview of modern augmented reality, from both application-level and technical perspective. We first give an overview of main AR applications, grouped into more than ten categories. We then give an overview of around 100 recent promising machine learning based works developed for AR systems, such as deep learning works for AR shopping (clothing, makeup), AR based image filters (such as Snapchat's lenses), AR animations, and more. In the end we discuss about some of the current challenges in AR domain, and the future directions in this area.
Robustness and Accuracy Could Be Reconcilable by (Proper) Definition
Feb 21, 2022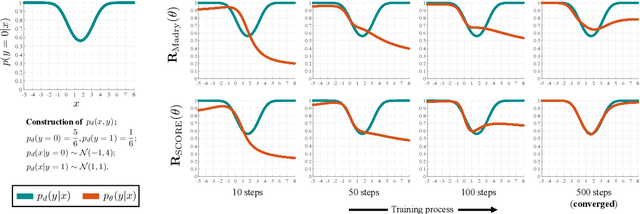
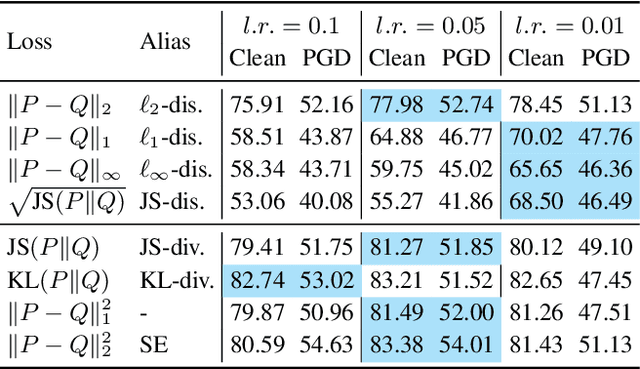
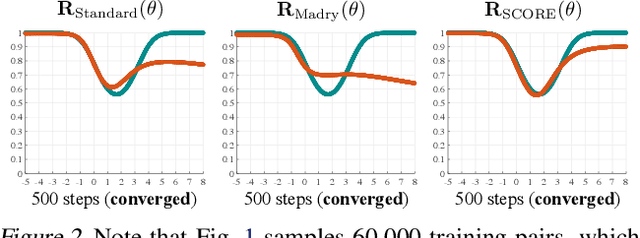
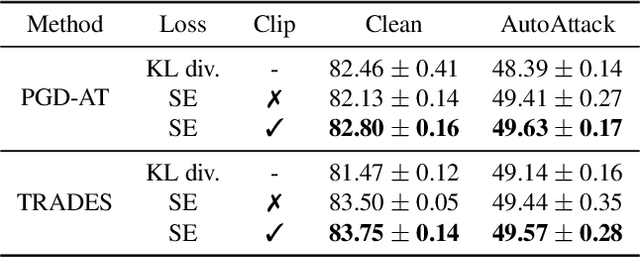
The trade-off between robustness and accuracy has been widely studied in the adversarial literature. Although still controversial, the prevailing view is that this trade-off is inherent, either empirically or theoretically. Thus, we dig for the origin of this trade-off in adversarial training and find that it may stem from the improperly defined robust error, which imposes an inductive bias of local invariance -- an overcorrection towards smoothness. Given this, we advocate employing local equivariance to describe the ideal behavior of a robust model, leading to a self-consistent robust error named SCORE. By definition, SCORE facilitates the reconciliation between robustness and accuracy, while still handling the worst-case uncertainty via robust optimization. By simply substituting KL divergence with variants of distance metrics, SCORE can be efficiently minimized. Empirically, our models achieve top-rank performance on RobustBench under AutoAttack. Besides, SCORE provides instructive insights for explaining the overfitting phenomenon and semantic input gradients observed on robust models.
How Should Pre-Trained Language Models Be Fine-Tuned Towards Adversarial Robustness?
Dec 22, 2021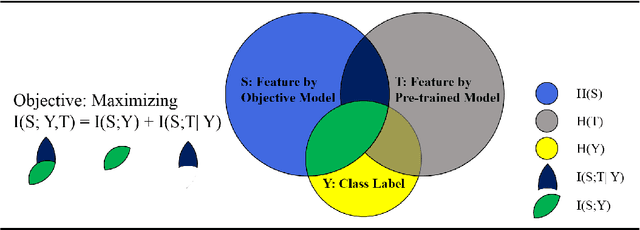

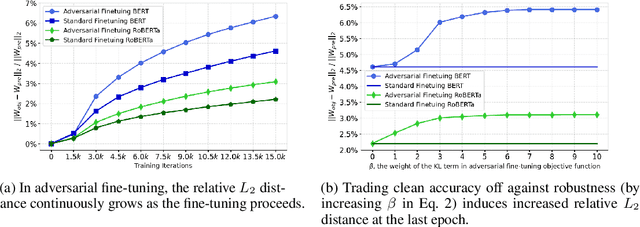

The fine-tuning of pre-trained language models has a great success in many NLP fields. Yet, it is strikingly vulnerable to adversarial examples, e.g., word substitution attacks using only synonyms can easily fool a BERT-based sentiment analysis model. In this paper, we demonstrate that adversarial training, the prevalent defense technique, does not directly fit a conventional fine-tuning scenario, because it suffers severely from catastrophic forgetting: failing to retain the generic and robust linguistic features that have already been captured by the pre-trained model. In this light, we propose Robust Informative Fine-Tuning (RIFT), a novel adversarial fine-tuning method from an information-theoretical perspective. In particular, RIFT encourages an objective model to retain the features learned from the pre-trained model throughout the entire fine-tuning process, whereas a conventional one only uses the pre-trained weights for initialization. Experimental results show that RIFT consistently outperforms the state-of-the-arts on two popular NLP tasks: sentiment analysis and natural language inference, under different attacks across various pre-trained language models.
TransZero++: Cross Attribute-Guided Transformer for Zero-Shot Learning
Dec 21, 2021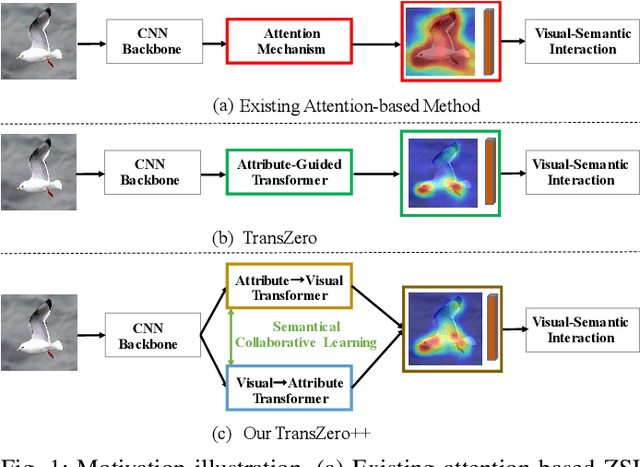
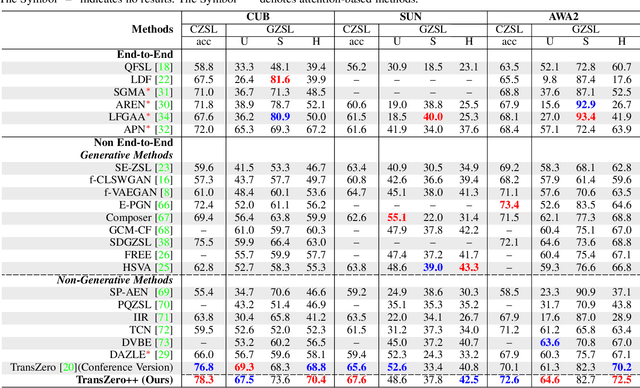
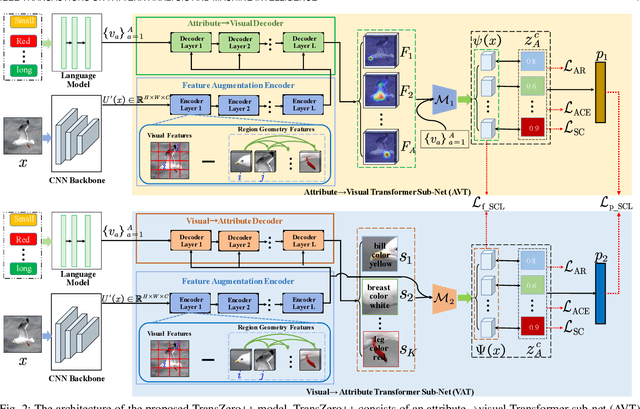
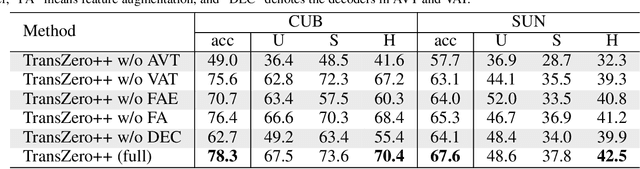
Zero-shot learning (ZSL) tackles the novel class recognition problem by transferring semantic knowledge from seen classes to unseen ones. Existing attention-based models have struggled to learn inferior region features in a single image by solely using unidirectional attention, which ignore the transferability and discriminative attribute localization of visual features. In this paper, we propose a cross attribute-guided Transformer network, termed TransZero++, to refine visual features and learn accurate attribute localization for semantic-augmented visual embedding representations in ZSL. TransZero++ consists of an attribute$\rightarrow$visual Transformer sub-net (AVT) and a visual$\rightarrow$attribute Transformer sub-net (VAT). Specifically, AVT first takes a feature augmentation encoder to alleviate the cross-dataset problem, and improves the transferability of visual features by reducing the entangled relative geometry relationships among region features. Then, an attribute$\rightarrow$visual decoder is employed to localize the image regions most relevant to each attribute in a given image for attribute-based visual feature representations. Analogously, VAT uses the similar feature augmentation encoder to refine the visual features, which are further applied in visual$\rightarrow$attribute decoder to learn visual-based attribute features. By further introducing semantical collaborative losses, the two attribute-guided transformers teach each other to learn semantic-augmented visual embeddings via semantical collaborative learning. Extensive experiments show that TransZero++ achieves the new state-of-the-art results on three challenging ZSL benchmarks. The codes are available at: \url{https://github.com/shiming-chen/TransZero_pp}.
DualFormer: Local-Global Stratified Transformer for Efficient Video Recognition
Dec 09, 2021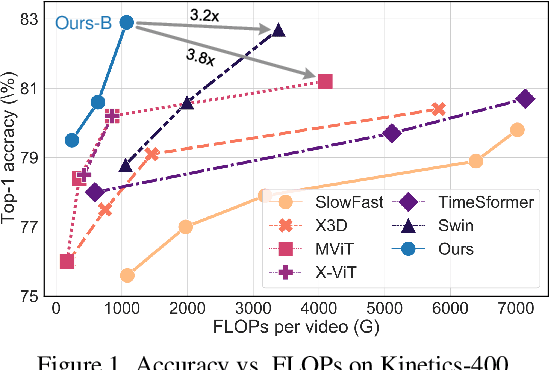
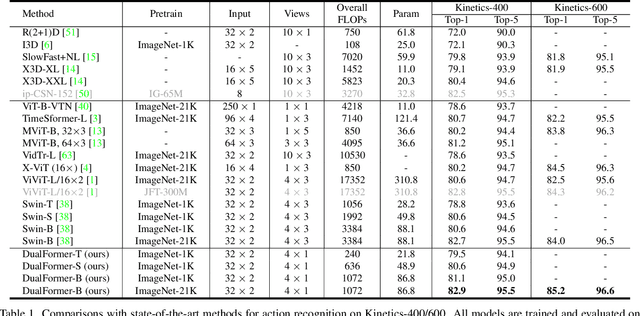
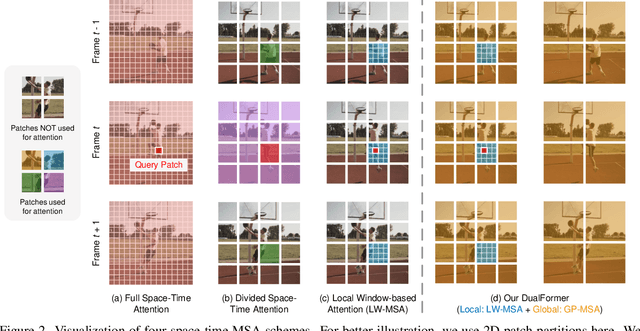
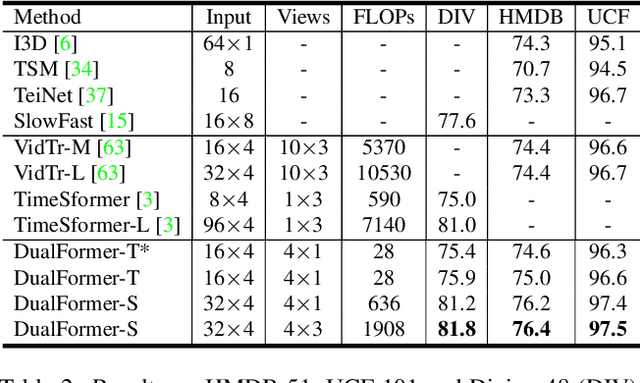
While transformers have shown great potential on video recognition tasks with their strong capability of capturing long-range dependencies, they often suffer high computational costs induced by self-attention operation on the huge number of 3D tokens in a video. In this paper, we propose a new transformer architecture, termed DualFormer, which can effectively and efficiently perform space-time attention for video recognition. Specifically, our DualFormer stratifies the full space-time attention into dual cascaded levels, i.e., to first learn fine-grained local space-time interactions among nearby 3D tokens, followed by the capture of coarse-grained global dependencies between the query token and the coarse-grained global pyramid contexts. Different from existing methods that apply space-time factorization or restrict attention computations within local windows for improving efficiency, our local-global stratified strategy can well capture both short- and long-range spatiotemporal dependencies, and meanwhile greatly reduces the number of keys and values in attention computation to boost efficiency. Experimental results show the superiority of DualFormer on five video benchmarks against existing methods. In particular, DualFormer sets new state-of-the-art 82.9%/85.2% top-1 accuracy on Kinetics-400/600 with around 1000G inference FLOPs which is at least 3.2 times fewer than existing methods with similar performances.
Geometry-Guided Progressive NeRF for Generalizable and Efficient Neural Human Rendering
Dec 08, 2021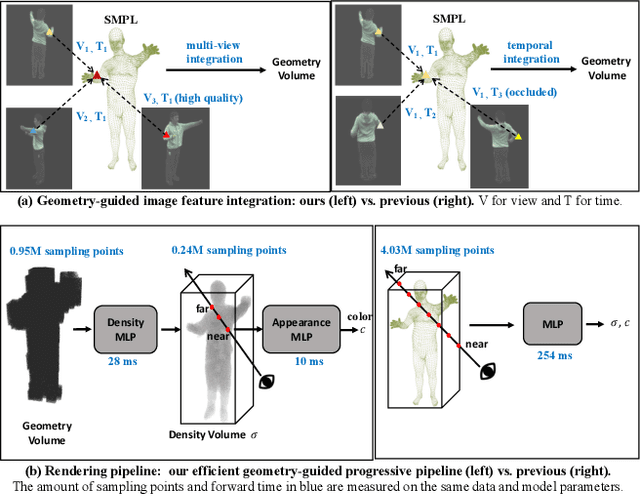
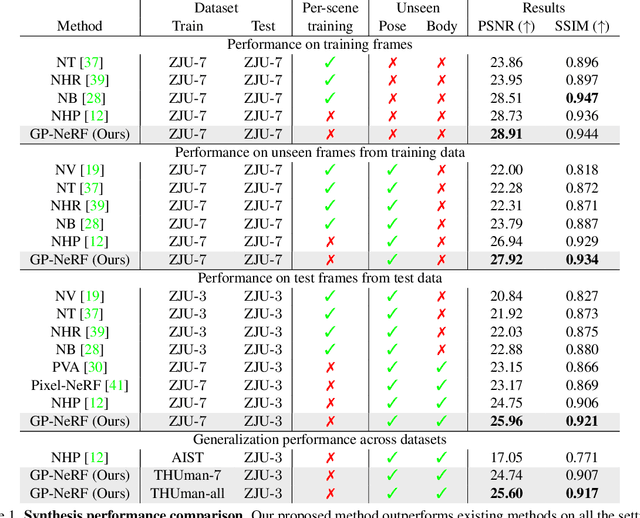
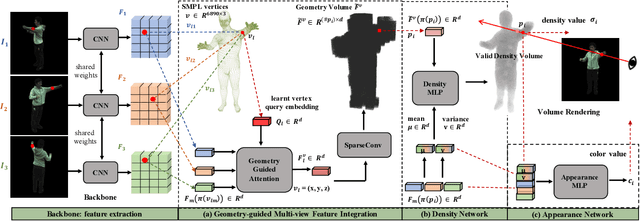
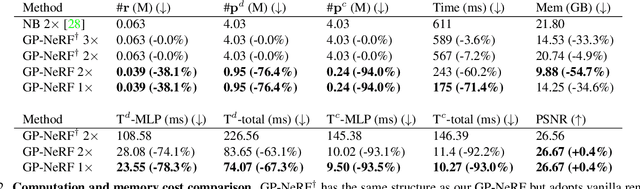
In this work we develop a generalizable and efficient Neural Radiance Field (NeRF) pipeline for high-fidelity free-viewpoint human body synthesis under settings with sparse camera views. Though existing NeRF-based methods can synthesize rather realistic details for human body, they tend to produce poor results when the input has self-occlusion, especially for unseen humans under sparse views. Moreover, these methods often require a large number of sampling points for rendering, which leads to low efficiency and limits their real-world applicability. To address these challenges, we propose a Geometry-guided Progressive NeRF~(GP-NeRF). In particular, to better tackle self-occlusion, we devise a geometry-guided multi-view feature integration approach that utilizes the estimated geometry prior to integrate the incomplete information from input views and construct a complete geometry volume for the target human body. Meanwhile, for achieving higher rendering efficiency, we introduce a geometry-guided progressive rendering pipeline, which leverages the geometric feature volume and the predicted density values to progressively reduce the number of sampling points and speed up the rendering process. Experiments on the ZJU-MoCap and THUman datasets show that our method outperforms the state-of-the-arts significantly across multiple generalization settings, while the time cost is reduced >70% via applying our efficient progressive rendering pipeline.
MetaFormer is Actually What You Need for Vision
Nov 29, 2021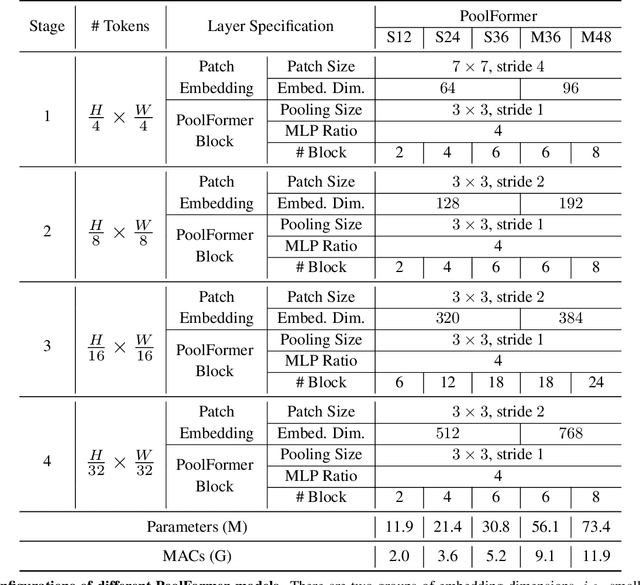
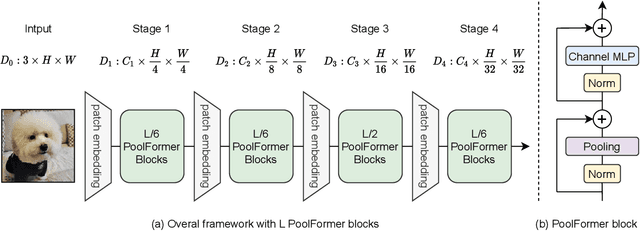
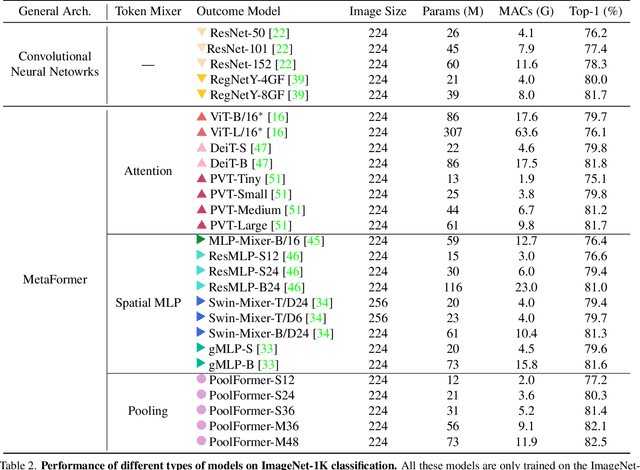
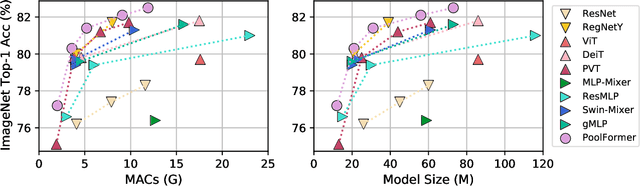
Transformers have shown great potential in computer vision tasks. A common belief is their attention-based token mixer module contributes most to their competence. However, recent works show the attention-based module in transformers can be replaced by spatial MLPs and the resulted models still perform quite well. Based on this observation, we hypothesize that the general architecture of the transformers, instead of the specific token mixer module, is more essential to the model's performance. To verify this, we deliberately replace the attention module in transformers with an embarrassingly simple spatial pooling operator to conduct only the most basic token mixing. Surprisingly, we observe that the derived model, termed as PoolFormer, achieves competitive performance on multiple computer vision tasks. For example, on ImageNet-1K, PoolFormer achieves 82.1% top-1 accuracy, surpassing well-tuned vision transformer/MLP-like baselines DeiT-B/ResMLP-B24 by 0.3%/1.1% accuracy with 35%/52% fewer parameters and 48%/60% fewer MACs. The effectiveness of PoolFormer verifies our hypothesis and urges us to initiate the concept of "MetaFormer", a general architecture abstracted from transformers without specifying the token mixer. Based on the extensive experiments, we argue that MetaFormer is the key player in achieving superior results for recent transformer and MLP-like models on vision tasks. This work calls for more future research dedicated to improving MetaFormer instead of focusing on the token mixer modules. Additionally, our proposed PoolFormer could serve as a starting baseline for future MetaFormer architecture design. Code is available at https://github.com/sail-sg/poolformer
Direct Multi-view Multi-person 3D Pose Estimation
Nov 27, 2021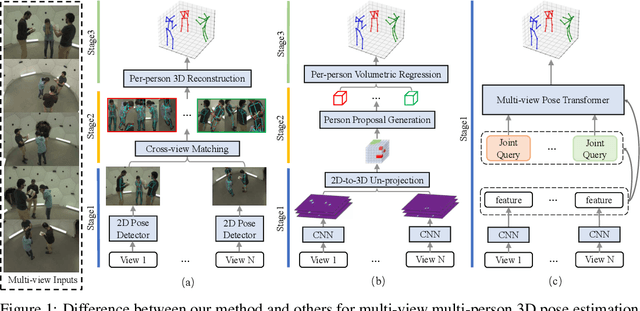

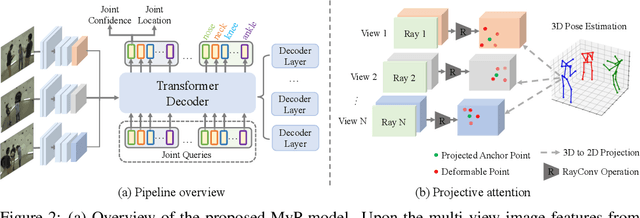
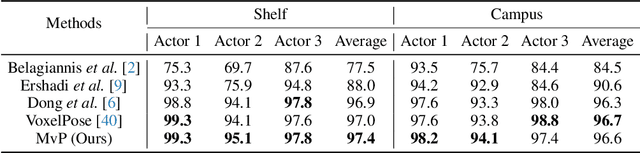
We present Multi-view Pose transformer (MvP) for estimating multi-person 3D poses from multi-view images. Instead of estimating 3D joint locations from costly volumetric representation or reconstructing the per-person 3D pose from multiple detected 2D poses as in previous methods, MvP directly regresses the multi-person 3D poses in a clean and efficient way, without relying on intermediate tasks. Specifically, MvP represents skeleton joints as learnable query embeddings and let them progressively attend to and reason over the multi-view information from the input images to directly regress the actual 3D joint locations. To improve the accuracy of such a simple pipeline, MvP presents a hierarchical scheme to concisely represent query embeddings of multi-person skeleton joints and introduces an input-dependent query adaptation approach. Further, MvP designs a novel geometrically guided attention mechanism, called projective attention, to more precisely fuse the cross-view information for each joint. MvP also introduces a RayConv operation to integrate the view-dependent camera geometry into the feature representations for augmenting the projective attention. We show experimentally that our MvP model outperforms the state-of-the-art methods on several benchmarks while being much more efficient. Notably, it achieves 92.3% AP25 on the challenging Panoptic dataset, improving upon the previous best approach [36] by 9.8%. MvP is general and also extendable to recovering human mesh represented by the SMPL model, thus useful for modeling multi-person body shapes. Code and models are available at https://github.com/sail-sg/mvp.
Arbitrary Virtual Try-On Network: Characteristics Preservation and Trade-off between Body and Clothing
Nov 24, 2021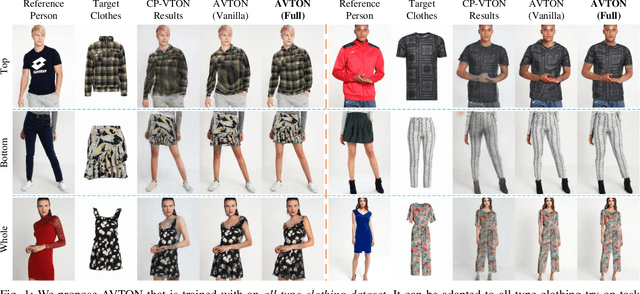
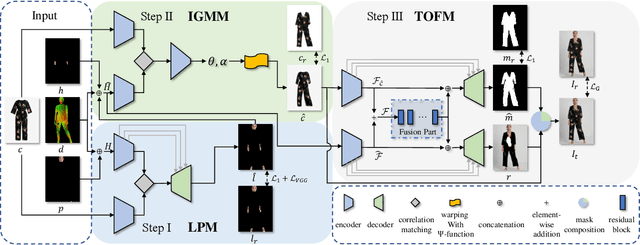


Deep learning based virtual try-on system has achieved some encouraging progress recently, but there still remain several big challenges that need to be solved, such as trying on arbitrary clothes of all types, trying on the clothes from one category to another and generating image-realistic results with few artifacts. To handle this issue, we in this paper first collect a new dataset with all types of clothes, \ie tops, bottoms, and whole clothes, each one has multiple categories with rich information of clothing characteristics such as patterns, logos, and other details. Based on this dataset, we then propose the Arbitrary Virtual Try-On Network (AVTON) that is utilized for all-type clothes, which can synthesize realistic try-on images by preserving and trading off characteristics of the target clothes and the reference person. Our approach includes three modules: 1) Limbs Prediction Module, which is utilized for predicting the human body parts by preserving the characteristics of the reference person. This is especially good for handling cross-category try-on task (\eg long sleeves \(\leftrightarrow\) short sleeves or long pants \(\leftrightarrow\) skirts, \etc), where the exposed arms or legs with the skin colors and details can be reasonably predicted; 2) Improved Geometric Matching Module, which is designed to warp clothes according to the geometry of the target person. We improve the TPS based warping method with a compactly supported radial function (Wendland's \(\Psi\)-function); 3) Trade-Off Fusion Module, which is to trade off the characteristics of the warped clothes and the reference person. This module is to make the generated try-on images look more natural and realistic based on a fine-tune symmetry of the network structure. Extensive simulations are conducted and our approach can achieve better performance compared with the state-of-the-art virtual try-on methods.