 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
OneRec Technical Report
Jun 16, 2025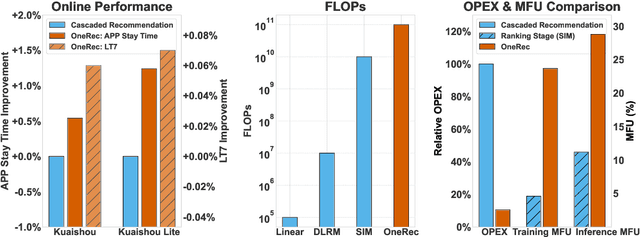

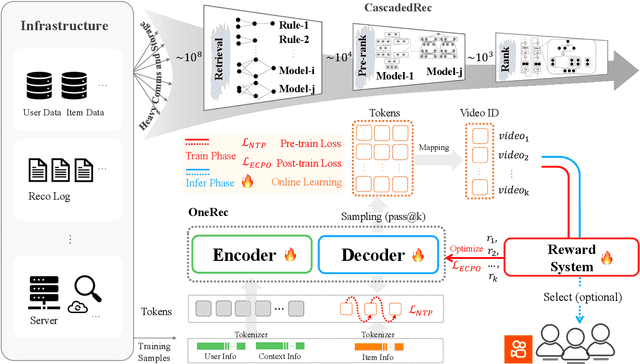
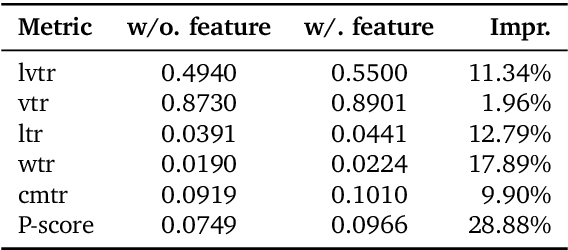
Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.
Learning Speaker-Invariant Visual Features for Lipreading
Jun 09, 2025Lipreading is a challenging cross-modal task that aims to convert visual lip movements into spoken text. Existing lipreading methods often extract visual features that include speaker-specific lip attributes (e.g., shape, color, texture), which introduce spurious correlations between vision and text. These correlations lead to suboptimal lipreading accuracy and restrict model generalization. To address this challenge, we introduce SIFLip, a speaker-invariant visual feature learning framework that disentangles speaker-specific attributes using two complementary disentanglement modules (Implicit Disentanglement and Explicit Disentanglement) to improve generalization. Specifically, since different speakers exhibit semantic consistency between lip movements and phonetic text when pronouncing the same words, our implicit disentanglement module leverages stable text embeddings as supervisory signals to learn common visual representations across speakers, implicitly decoupling speaker-specific features. Additionally, we design a speaker recognition sub-task within the main lipreading pipeline to filter speaker-specific features, then further explicitly disentangle these personalized visual features from the backbone network via gradient reversal. Experimental results demonstrate that SIFLip significantly enhances generalization performance across multiple public datasets. Experimental results demonstrate that SIFLip significantly improves generalization performance across multiple public datasets, outperforming state-of-the-art methods.
LLM-Alignment Live-Streaming Recommendation
Apr 07, 2025



In recent years, integrated short-video and live-streaming platforms have gained massive global adoption, offering dynamic content creation and consumption. Unlike pre-recorded short videos, live-streaming enables real-time interaction between authors and users, fostering deeper engagement. However, this dynamic nature introduces a critical challenge for recommendation systems (RecSys): the same live-streaming vastly different experiences depending on when a user watching. To optimize recommendations, a RecSys must accurately interpret the real-time semantics of live content and align them with user preferences.
Enhancing Embedding Representation Stability in Recommendation Systems with Semantic ID
Apr 02, 2025The exponential growth of online content has posed significant challenges to ID-based models in industrial recommendation systems, ranging from extremely high cardinality and dynamically growing ID space, to highly skewed engagement distributions, to prediction instability as a result of natural id life cycles (e.g, the birth of new IDs and retirement of old IDs). To address these issues, many systems rely on random hashing to handle the id space and control the corresponding model parameters (i.e embedding table). However, this approach introduces data pollution from multiple ids sharing the same embedding, leading to degraded model performance and embedding representation instability. This paper examines these challenges and introduces Semantic ID prefix ngram, a novel token parameterization technique that significantly improves the performance of the original Semantic ID. Semantic ID prefix ngram creates semantically meaningful collisions by hierarchically clustering items based on their content embeddings, as opposed to random assignments. Through extensive experimentation, we demonstrate that Semantic ID prefix ngram not only addresses embedding instability but also significantly improves tail id modeling, reduces overfitting, and mitigates representation shifts. We further highlight the advantages of Semantic ID prefix ngram in attention-based models that contextualize user histories, showing substantial performance improvements. We also report our experience of integrating Semantic ID into Meta production Ads Ranking system, leading to notable performance gains and enhanced prediction stability in live deployments.
AutoRedTeamer: Autonomous Red Teaming with Lifelong Attack Integration
Mar 20, 2025



As large language models (LLMs) become increasingly capable, security and safety evaluation are crucial. While current red teaming approaches have made strides in assessing LLM vulnerabilities, they often rely heavily on human input and lack comprehensive coverage of emerging attack vectors. This paper introduces AutoRedTeamer, a novel framework for fully automated, end-to-end red teaming against LLMs. AutoRedTeamer combines a multi-agent architecture with a memory-guided attack selection mechanism to enable continuous discovery and integration of new attack vectors. The dual-agent framework consists of a red teaming agent that can operate from high-level risk categories alone to generate and execute test cases and a strategy proposer agent that autonomously discovers and implements new attacks by analyzing recent research. This modular design allows AutoRedTeamer to adapt to emerging threats while maintaining strong performance on existing attack vectors. We demonstrate AutoRedTeamer's effectiveness across diverse evaluation settings, achieving 20% higher attack success rates on HarmBench against Llama-3.1-70B while reducing computational costs by 46% compared to existing approaches. AutoRedTeamer also matches the diversity of human-curated benchmarks in generating test cases, providing a comprehensive, scalable, and continuously evolving framework for evaluating the security of AI systems.
Unified Semantic and ID Representation Learning for Deep Recommenders
Feb 23, 2025



Effective recommendation is crucial for large-scale online platforms. Traditional recommendation systems primarily rely on ID tokens to uniquely identify items, which can effectively capture specific item relationships but suffer from issues such as redundancy and poor performance in cold-start scenarios. Recent approaches have explored using semantic tokens as an alternative, yet they face challenges, including item duplication and inconsistent performance gains, leaving the potential advantages of semantic tokens inadequately examined. To address these limitations, we propose a Unified Semantic and ID Representation Learning framework that leverages the complementary strengths of both token types. In our framework, ID tokens capture unique item attributes, while semantic tokens represent shared, transferable characteristics. Additionally, we analyze the role of cosine similarity and Euclidean distance in embedding search, revealing that cosine similarity is more effective in decoupling accumulated embeddings, while Euclidean distance excels in distinguishing unique items. Our framework integrates cosine similarity in earlier layers and Euclidean distance in the final layer to optimize representation learning. Experiments on three benchmark datasets show that our method significantly outperforms state-of-the-art baselines, with improvements ranging from 6\% to 17\% and a reduction in token size by over 80%. These results demonstrate the effectiveness of combining ID and semantic tokenization to enhance the generalization ability of recommender systems.
FARM: Frequency-Aware Model for Cross-Domain Live-Streaming Recommendation
Feb 13, 2025



Live-streaming services have attracted widespread popularity due to their real-time interactivity and entertainment value. Users can engage with live-streaming authors by participating in live chats, posting likes, or sending virtual gifts to convey their preferences and support. However, the live-streaming services faces serious data-sparsity problem, which can be attributed to the following two points: (1) User's valuable behaviors are usually sparse, e.g., like, comment and gift, which are easily overlooked by the model, making it difficult to describe user's personalized preference. (2) The main exposure content on our platform is short-video, which is 9 times higher than the exposed live-streaming, leading to the inability of live-streaming content to fully model user preference. To this end, we propose a Frequency-Aware Model for Cross-Domain Live-Streaming Recommendation, termed as FARM. Specifically, we first present the intra-domain frequency aware module to enable our model to perceive user's sparse yet valuable behaviors, i.e., high-frequency information, supported by the Discrete Fourier Transform (DFT). To transfer user preference across the short-video and live-streaming domains, we propose a novel preference align before fuse strategy, which consists of two parts: the cross-domain preference align module to align user preference in both domains with contrastive learning, and the cross-domain preference fuse module to further fuse user preference in both domains using a serious of tailor-designed attention mechanisms. Extensive offline experiments and online A/B testing on Kuaishou live-streaming services demonstrate the effectiveness and superiority of FARM. Our FARM has been deployed in online live-streaming services and currently serves hundreds of millions of users on Kuaishou.
Session-Level Dynamic Ad Load Optimization using Offline Robust Reinforcement Learning
Jan 09, 2025



Session-level dynamic ad load optimization aims to personalize the density and types of delivered advertisements in real time during a user's online session by dynamically balancing user experience quality and ad monetization. Traditional causal learning-based approaches struggle with key technical challenges, especially in handling confounding bias and distribution shifts. In this paper, we develop an offline deep Q-network (DQN)-based framework that effectively mitigates confounding bias in dynamic systems and demonstrates more than 80% offline gains compared to the best causal learning-based production baseline. Moreover, to improve the framework's robustness against unanticipated distribution shifts, we further enhance our framework with a novel offline robust dueling DQN approach. This approach achieves more stable rewards on multiple OpenAI-Gym datasets as perturbations increase, and provides an additional 5% offline gains on real-world ad delivery data. Deployed across multiple production systems, our approach has achieved outsized topline gains. Post-launch online A/B tests have shown double-digit improvements in the engagement-ad score trade-off efficiency, significantly enhancing our platform's capability to serve both consumers and advertisers.
A Unified Framework for Cross-Domain Recommendation
Sep 06, 2024



In addressing the persistent challenges of data-sparsity and cold-start issues in domain-expert recommender systems, Cross-Domain Recommendation (CDR) emerges as a promising methodology. CDR aims at enhancing prediction performance in the target domain by leveraging interaction knowledge from related source domains, particularly through users or items that span across multiple domains (e.g., Short-Video and Living-Room). For academic research purposes, there are a number of distinct aspects to guide CDR method designing, including the auxiliary domain number, domain-overlapped element, user-item interaction types, and downstream tasks. With so many different CDR combination scenario settings, the proposed scenario-expert approaches are tailored to address a specific vertical CDR scenario, and often lack the capacity to adapt to multiple horizontal scenarios. In an effect to coherently adapt to various scenarios, and drawing inspiration from the concept of domain-invariant transfer learning, we extend the former SOTA model UniCDR in five different aspects, named as UniCDR+. Our work was successfully deployed on the Kuaishou Living-Room RecSys.