 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery and Extract: Refining Event Extraction as Type-oriented Binary Decoding
Oct 14, 2021
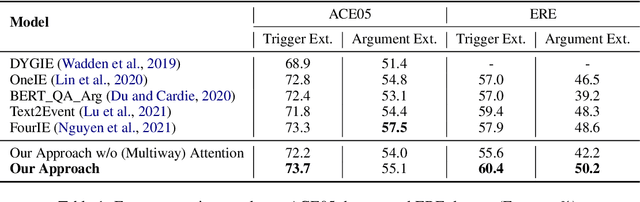
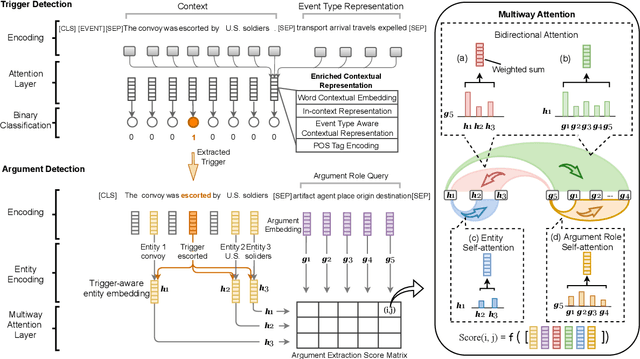
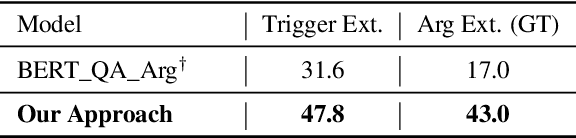
Event extraction is typically modeled as a multi-class classification problem where both event types and argument roles are treated as atomic symbols. These approaches are usually limited to a set of pre-defined types. We propose a novel event extraction framework that takes event types and argument roles as natural language queries to extract candidate triggers and arguments from the input text. With the rich semantics in the queries, our framework benefits from the attention mechanisms to better capture the semantic correlation between the event types or argument roles and the input text. Furthermore, the query-and-extract formulation allows our approach to leverage all available event annotations from various ontologies as a unified model. Experiments on two public benchmarks, ACE and ERE, demonstrate that our approach achieves state-of-the-art performance on each dataset and significantly outperforms existing methods on zero-shot event extraction. We will make all the programs publicly available once the paper is accepted.
On the Interplay Between Sparsity, Naturalness, Intelligibility, and Prosody in Speech Synthesis
Oct 04, 2021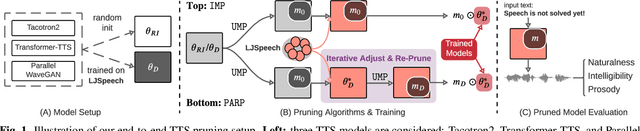
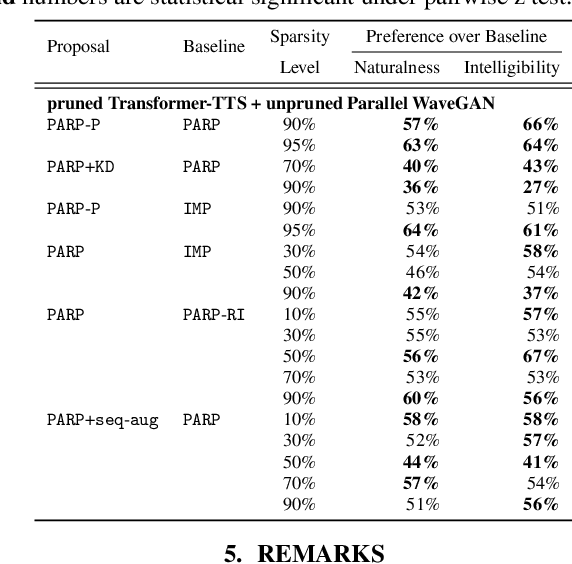
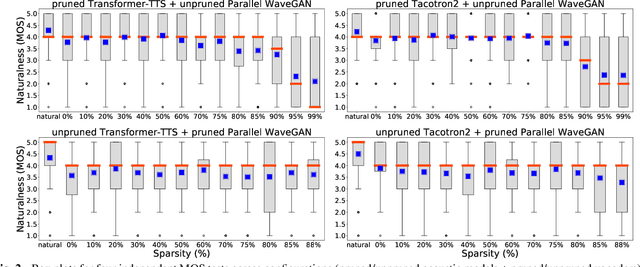
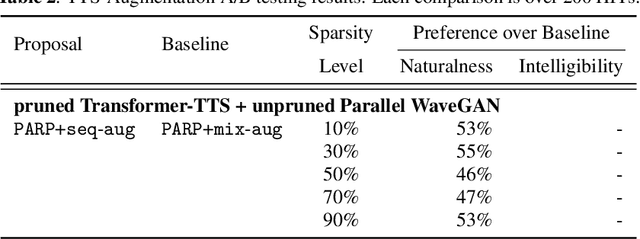
Are end-to-end text-to-speech (TTS) models over-parametrized? To what extent can these models be pruned, and what happens to their synthesis capabilities? This work serves as a starting point to explore pruning both spectrogram prediction networks and vocoders. We thoroughly investigate the tradeoffs between sparstiy and its subsequent effects on synthetic speech. Additionally, we explored several aspects of TTS pruning: amount of finetuning data versus sparsity, TTS-Augmentation to utilize unspoken text, and combining knowledge distillation and pruning. Our findings suggest that not only are end-to-end TTS models highly prunable, but also, perhaps surprisingly, pruned TTS models can produce synthetic speech with equal or higher naturalness and intelligibility, with similar prosody. All of our experiments are conducted on publicly available models, and findings in this work are backed by large-scale subjective tests and objective measures. Code and 200 pruned models are made available to facilitate future research on efficiency in TTS.
Global Rhythm Style Transfer Without Text Transcriptions
Jun 16, 2021
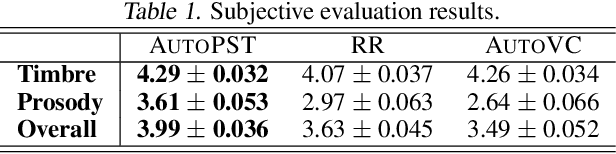
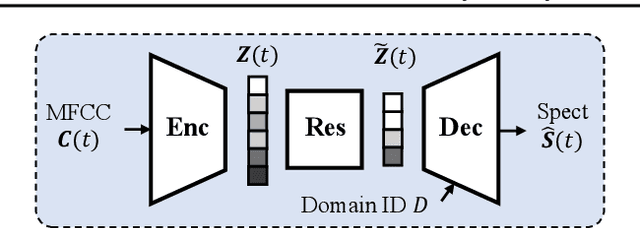

Prosody plays an important role in characterizing the style of a speaker or an emotion, but most non-parallel voice or emotion style transfer algorithms do not convert any prosody information. Two major components of prosody are pitch and rhythm. Disentangling the prosody information, particularly the rhythm component, from the speech is challenging because it involves breaking the synchrony between the input speech and the disentangled speech representation. As a result, most existing prosody style transfer algorithms would need to rely on some form of text transcriptions to identify the content information, which confines their application to high-resource languages only. Recently, SpeechSplit has made sizeable progress towards unsupervised prosody style transfer, but it is unable to extract high-level global prosody style in an unsupervised manner. In this paper, we propose AutoPST, which can disentangle global prosody style from speech without relying on any text transcriptions. AutoPST is an Autoencoder-based Prosody Style Transfer framework with a thorough rhythm removal module guided by the self-expressive representation learning. Experiments on different style transfer tasks show that AutoPST can effectively convert prosody that correctly reflects the styles of the target domains.
Learning Stable Classifiers by Transferring Unstable Features
Jun 15, 2021

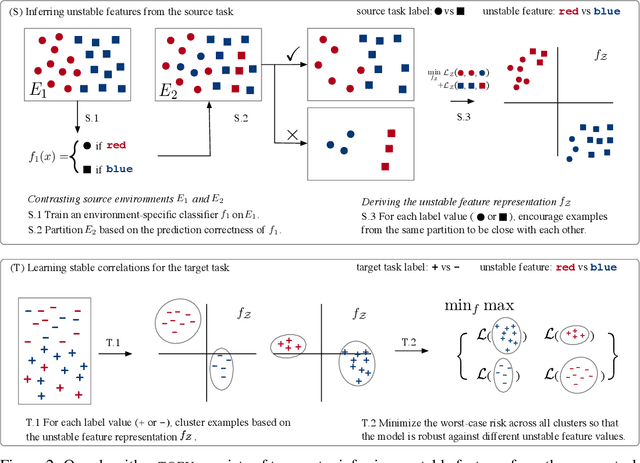
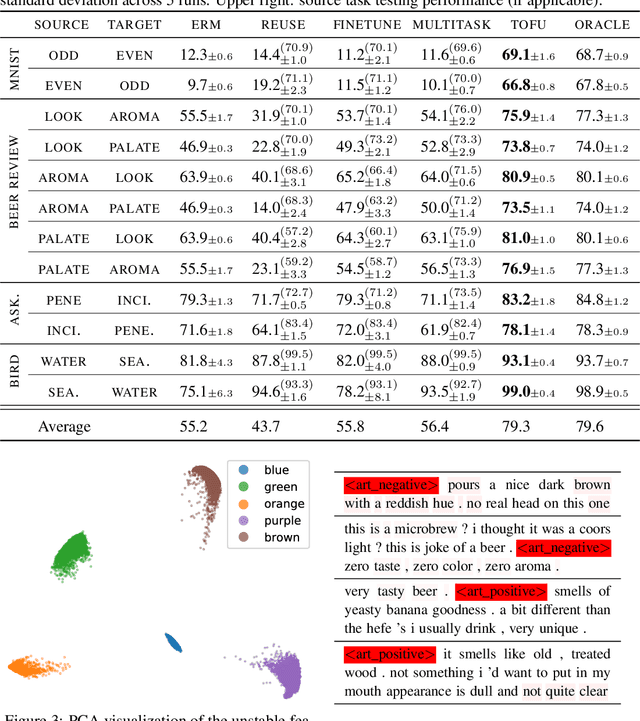
We study transfer learning in the presence of spurious correlations. We experimentally demonstrate that directly transferring the stable feature extractor learned on the source task may not eliminate these biases for the target task. However, we hypothesize that the unstable features in the source task and those in the target task are directly related. By explicitly informing the target classifier of the source task's unstable features, we can regularize the biases in the target task. Specifically, we derive a representation that encodes the unstable features by contrasting different data environments in the source task. On the target task, we cluster data from this representation, and achieve robustness by minimizing the worst-case risk across all clusters. We evaluate our method on both text and image classifications. Empirical results demonstrate that our algorithm is able to maintain robustness on the target task, outperforming the best baseline by 22.9% in absolute accuracy across 12 transfer settings. Our code is available at https://github.com/YujiaBao/Tofu.
PARP: Prune, Adjust and Re-Prune for Self-Supervised Speech Recognition
Jun 10, 2021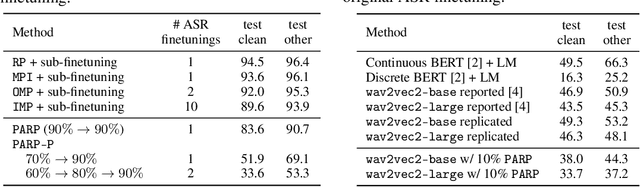
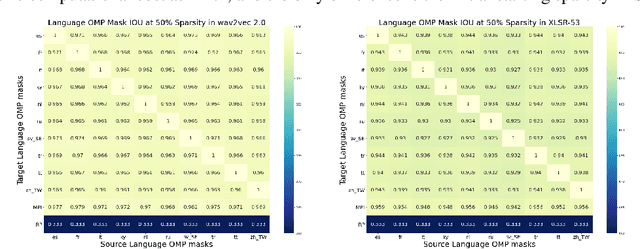
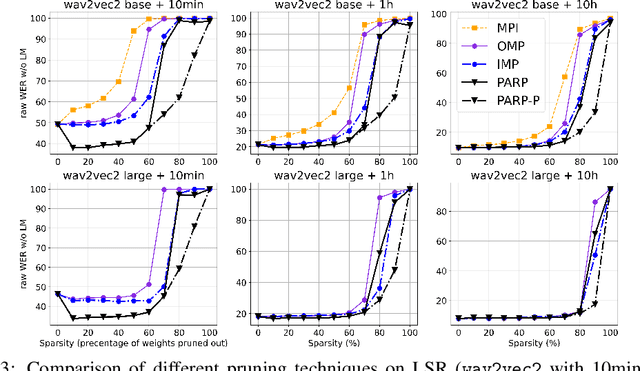
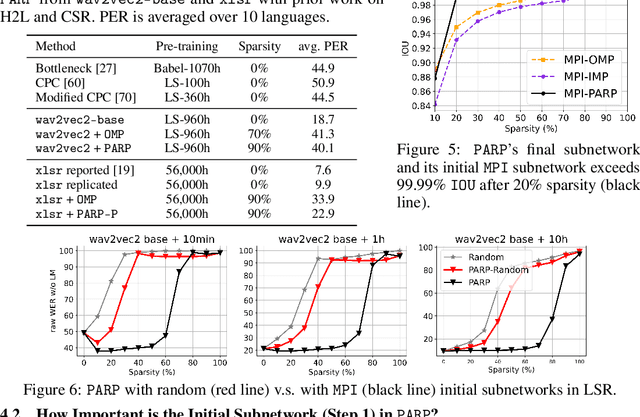
Recent work on speech self-supervised learning (speech SSL) demonstrated the benefits of scale in learning rich and transferable representations for Automatic Speech Recognition (ASR) with limited parallel data. It is then natural to investigate the existence of sparse and transferrable subnetworks in pre-trained speech SSL models that can achieve even better low-resource ASR performance. However, directly applying widely adopted pruning methods such as the Lottery Ticket Hypothesis (LTH) is suboptimal in the computational cost needed. Moreover, contrary to what LTH predicts, the discovered subnetworks yield minimal performance gain compared to the original dense network. In this work, we propose Prune-Adjust- Re-Prune (PARP), which discovers and finetunes subnetworks for much better ASR performance, while only requiring a single downstream finetuning run. PARP is inspired by our surprising observation that subnetworks pruned for pre-training tasks only needed to be slightly adjusted to achieve a sizeable performance boost in downstream ASR tasks. Extensive experiments on low-resource English and multi-lingual ASR show (1) sparse subnetworks exist in pre-trained speech SSL, and (2) the computational advantage and performance gain of PARP over baseline pruning methods. On the 10min Librispeech split without LM decoding, PARP discovers subnetworks from wav2vec 2.0 with an absolute 10.9%/12.6% WER decrease compared to the full model. We demonstrate PARP mitigates performance degradation in cross-lingual mask transfer, and investigate the possibility of discovering a single subnetwork for 10 spoken languages in one run.
Predict then Interpolate: A Simple Algorithm to Learn Stable Classifiers
May 26, 2021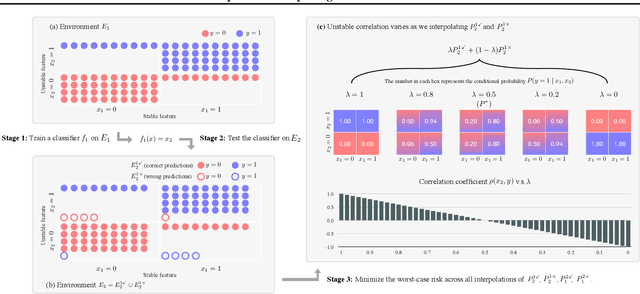
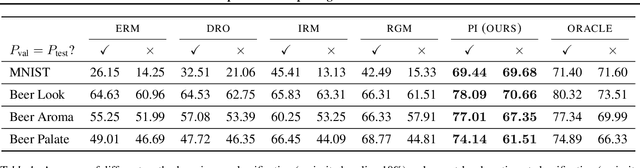
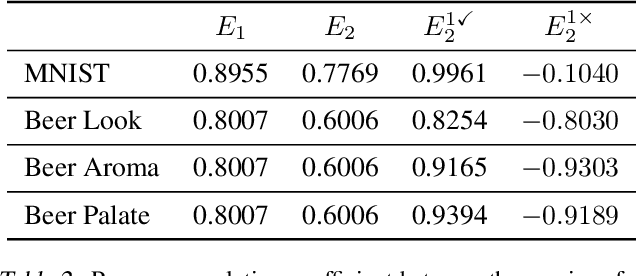
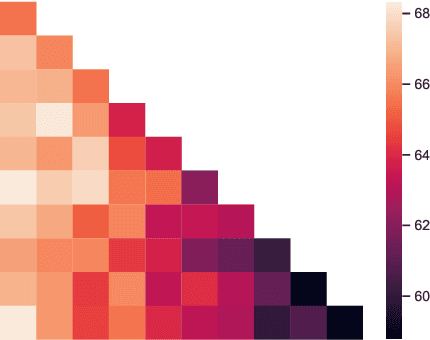
We propose Predict then Interpolate (PI), a simple algorithm for learning correlations that are stable across environments. The algorithm follows from the intuition that when using a classifier trained on one environment to make predictions on examples from another environment, its mistakes are informative as to which correlations are unstable. In this work, we prove that by interpolating the distributions of the correct predictions and the wrong predictions, we can uncover an oracle distribution where the unstable correlation vanishes. Since the oracle interpolation coefficients are not accessible, we use group distributionally robust optimization to minimize the worst-case risk across all such interpolations. We evaluate our method on both text classification and image classification. Empirical results demonstrate that our algorithm is able to learn robust classifiers (outperforms IRM by 23.85% on synthetic environments and 12.41% on natural environments). Our code and data are available at https://github.com/YujiaBao/Predict-then-Interpolate.
Complementary Evidence Identification in Open-Domain Question Answering
Apr 05, 2021
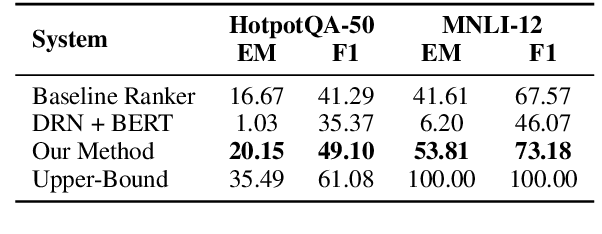

This paper proposes a new problem of complementary evidence identification for open-domain question answering (QA). The problem aims to efficiently find a small set of passages that covers full evidence from multiple aspects as to answer a complex question. To this end, we proposes a method that learns vector representations of passages and models the sufficiency and diversity within the selected set, in addition to the relevance between the question and passages. Our experiments demonstrate that our method considers the dependence within the supporting evidence and significantly improves the accuracy of complementary evidence selection in QA domain.
Generating Adversarial Computer Programs using Optimized Obfuscations
Mar 18, 2021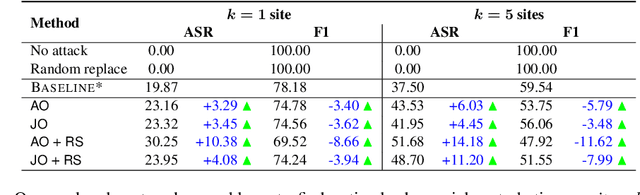

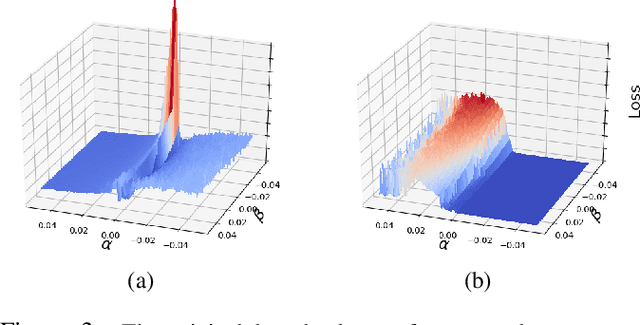
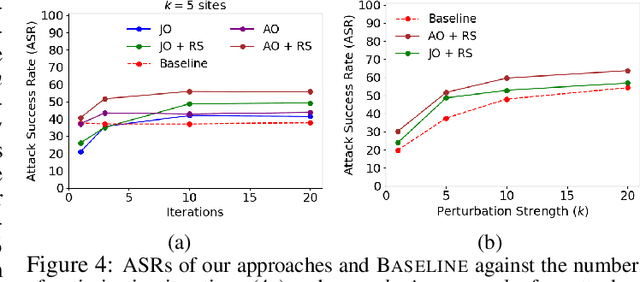
Machine learning (ML) models that learn and predict properties of computer programs are increasingly being adopted and deployed. These models have demonstrated success in applications such as auto-completing code, summarizing large programs, and detecting bugs and malware in programs. In this work, we investigate principled ways to adversarially perturb a computer program to fool such learned models, and thus determine their adversarial robustness. We use program obfuscations, which have conventionally been used to avoid attempts at reverse engineering programs, as adversarial perturbations. These perturbations modify programs in ways that do not alter their functionality but can be crafted to deceive an ML model when making a decision. We provide a general formulation for an adversarial program that allows applying multiple obfuscation transformations to a program in any language. We develop first-order optimization algorithms to efficiently determine two key aspects -- which parts of the program to transform, and what transformations to use. We show that it is important to optimize both these aspects to generate the best adversarially perturbed program. Due to the discrete nature of this problem, we also propose using randomized smoothing to improve the attack loss landscape to ease optimization. We evaluate our work on Python and Java programs on the problem of program summarization. We show that our best attack proposal achieves a $52\%$ improvement over a state-of-the-art attack generation approach for programs trained on a seq2seq model. We further show that our formulation is better at training models that are robust to adversarial attacks.
TransGAN: Two Transformers Can Make One Strong GAN
Feb 16, 2021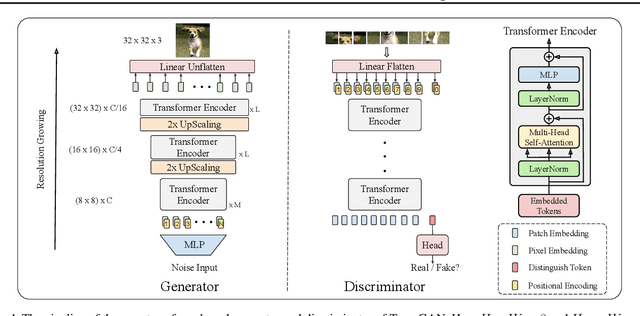
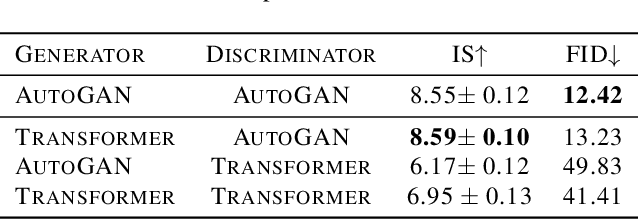
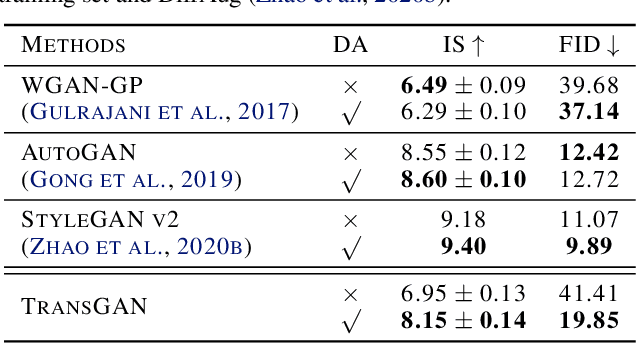
The recent explosive interest on transformers has suggested their potential to become powerful "universal" models for computer vision tasks, such as classification, detection, and segmentation. However, how further transformers can go - are they ready to take some more notoriously difficult vision tasks, e.g., generative adversarial networks (GANs)? Driven by that curiosity, we conduct the first pilot study in building a GAN \textbf{completely free of convolutions}, using only pure transformer-based architectures. Our vanilla GAN architecture, dubbed \textbf{TransGAN}, consists of a memory-friendly transformer-based generator that progressively increases feature resolution while decreasing embedding dimension, and a patch-level discriminator that is also transformer-based. We then demonstrate TransGAN to notably benefit from data augmentations (more than standard GANs), a multi-task co-training strategy for the generator, and a locally initialized self-attention that emphasizes the neighborhood smoothness of natural images. Equipped with those findings, TransGAN can effectively scale up with bigger models and high-resolution image datasets. Specifically, our best architecture achieves highly competitive performance compared to current state-of-the-art GANs based on convolutional backbones. Specifically, TransGAN sets \textbf{new state-of-the-art} IS score of 10.10 and FID score of 25.32 on STL-10. It also reaches competitive 8.64 IS score and 11.89 FID score on Cifar-10, and 12.23 FID score on CelebA $64\times64$, respectively. We also conclude with a discussion of the current limitations and future potential of TransGAN. The code is available at \url{https://github.com/VITA-Group/TransGAN}.
Self-Progressing Robust Training
Dec 22, 2020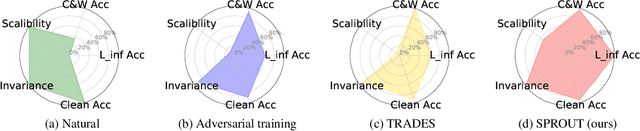


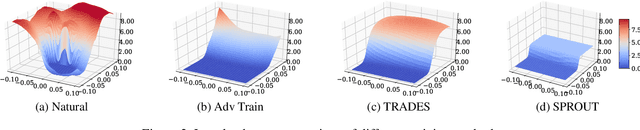
Enhancing model robustness under new and even adversarial environments is a crucial milestone toward building trustworthy machine learning systems. Current robust training methods such as adversarial training explicitly uses an "attack" (e.g., $\ell_{\infty}$-norm bounded perturbation) to generate adversarial examples during model training for improving adversarial robustness. In this paper, we take a different perspective and propose a new framework called SPROUT, self-progressing robust training. During model training, SPROUT progressively adjusts training label distribution via our proposed parametrized label smoothing technique, making training free of attack generation and more scalable. We also motivate SPROUT using a general formulation based on vicinity risk minimization, which includes many robust training methods as special cases. Compared with state-of-the-art adversarial training methods (PGD-l_inf and TRADES) under l_inf-norm bounded attacks and various invariance tests, SPROUT consistently attains superior performance and is more scalable to large neural networks. Our results shed new light on scalable, effective and attack-independent robust training methods.