 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoment&Cross: Next-Generation Real-Time Cross-Domain CTR Prediction for Live-Streaming Recommendation at Kuaishou
Aug 11, 2024



Kuaishou, is one of the largest short-video and live-streaming platform, compared with short-video recommendations, live-streaming recommendation is more complex because of: (1) temporarily-alive to distribution, (2) user may watch for a long time with feedback delay, (3) content is unpredictable and changes over time. Actually, even if a user is interested in the live-streaming author, it still may be an negative watching (e.g., short-view < 3s) since the real-time content is not attractive enough. Therefore, for live-streaming recommendation, there exists a challenging task: how do we recommend the live-streaming at right moment for users? Additionally, our platform's major exposure content is short short-video, and the amount of exposed short-video is 9x more than exposed live-streaming. Thus users will leave more behaviors on short-videos, which leads to a serious data imbalance problem making the live-streaming data could not fully reflect user interests. In such case, there raises another challenging task: how do we utilize users' short-video behaviors to make live-streaming recommendation better?
An LLM-Assisted Easy-to-Trigger Backdoor Attack on Code Completion Models: Injecting Disguised Vulnerabilities against Strong Detection
Jun 10, 2024Large Language Models (LLMs) have transformed code completion tasks, providing context-based suggestions to boost developer productivity in software engineering. As users often fine-tune these models for specific applications, poisoning and backdoor attacks can covertly alter the model outputs. To address this critical security challenge, we introduce CodeBreaker, a pioneering LLM-assisted backdoor attack framework on code completion models. Unlike recent attacks that embed malicious payloads in detectable or irrelevant sections of the code (e.g., comments), CodeBreaker leverages LLMs (e.g., GPT-4) for sophisticated payload transformation (without affecting functionalities), ensuring that both the poisoned data for fine-tuning and generated code can evade strong vulnerability detection. CodeBreaker stands out with its comprehensive coverage of vulnerabilities, making it the first to provide such an extensive set for evaluation. Our extensive experimental evaluations and user studies underline the strong attack performance of CodeBreaker across various settings, validating its superiority over existing approaches. By integrating malicious payloads directly into the source code with minimal transformation, CodeBreaker challenges current security measures, underscoring the critical need for more robust defenses for code completion.
Large Language Models for Education: A Survey and Outlook
Apr 01, 2024

The advent of Large Language Models (LLMs) has brought in a new era of possibilities in the realm of education. This survey paper summarizes the various technologies of LLMs in educational settings from multifaceted perspectives, encompassing student and teacher assistance, adaptive learning, and commercial tools. We systematically review the technological advancements in each perspective, organize related datasets and benchmarks, and identify the risks and challenges associated with deploying LLMs in education. Furthermore, we outline future research opportunities, highlighting the potential promising directions. Our survey aims to provide a comprehensive technological picture for educators, researchers, and policymakers to harness the power of LLMs to revolutionize educational practices and foster a more effective personalized learning environment.
NameGuess: Column Name Expansion for Tabular Data
Oct 19, 2023Recent advances in large language models have revolutionized many sectors, including the database industry. One common challenge when dealing with large volumes of tabular data is the pervasive use of abbreviated column names, which can negatively impact performance on various data search, access, and understanding tasks. To address this issue, we introduce a new task, called NameGuess, to expand column names (used in database schema) as a natural language generation problem. We create a training dataset of 384K abbreviated-expanded column pairs using a new data fabrication method and a human-annotated evaluation benchmark that includes 9.2K examples from real-world tables. To tackle the complexities associated with polysemy and ambiguity in NameGuess, we enhance auto-regressive language models by conditioning on table content and column header names -- yielding a fine-tuned model (with 2.7B parameters) that matches human performance. Furthermore, we conduct a comprehensive analysis (on multiple LLMs) to validate the effectiveness of table content in NameGuess and identify promising future opportunities. Code has been made available at https://github.com/amazon-science/nameguess.
MIML: Multiplex Image Machine Learning for High Precision Cell Classification via Mechanical Traits within Microfluidic Systems
Sep 15, 2023Label-free cell classification is advantageous for supplying pristine cells for further use or examination, yet existing techniques frequently fall short in terms of specificity and speed. In this study, we address these limitations through the development of a novel machine learning framework, Multiplex Image Machine Learning (MIML). This architecture uniquely combines label-free cell images with biomechanical property data, harnessing the vast, often underutilized morphological information intrinsic to each cell. By integrating both types of data, our model offers a more holistic understanding of the cellular properties, utilizing morphological information typically discarded in traditional machine learning models. This approach has led to a remarkable 98.3\% accuracy in cell classification, a substantial improvement over models that only consider a single data type. MIML has been proven effective in classifying white blood cells and tumor cells, with potential for broader application due to its inherent flexibility and transfer learning capability. It's particularly effective for cells with similar morphology but distinct biomechanical properties. This innovative approach has significant implications across various fields, from advancing disease diagnostics to understanding cellular behavior.
AVARS -- Alleviating Unexpected Urban Road Traffic Congestion using UAVs
Sep 10, 2023



Reducing unexpected urban traffic congestion caused by en-route events (e.g., road closures, car crashes, etc.) often requires fast and accurate reactions to choose the best-fit traffic signals. Traditional traffic light control systems, such as SCATS and SCOOT, are not efficient as their traffic data provided by induction loops has a low update frequency (i.e., longer than 1 minute). Moreover, the traffic light signal plans used by these systems are selected from a limited set of candidate plans pre-programmed prior to unexpected events' occurrence. Recent research demonstrates that camera-based traffic light systems controlled by deep reinforcement learning (DRL) algorithms are more effective in reducing traffic congestion, in which the cameras can provide high-frequency high-resolution traffic data. However, these systems are costly to deploy in big cities due to the excessive potential upgrades required to road infrastructure. In this paper, we argue that Unmanned Aerial Vehicles (UAVs) can play a crucial role in dealing with unexpected traffic congestion because UAVs with onboard cameras can be economically deployed when and where unexpected congestion occurs. Then, we propose a system called "AVARS" that explores the potential of using UAVs to reduce unexpected urban traffic congestion using DRL-based traffic light signal control. This approach is validated on a widely used open-source traffic simulator with practical UAV settings, including its traffic monitoring ranges and battery lifetime. Our simulation results show that AVARS can effectively recover the unexpected traffic congestion in Dublin, Ireland, back to its original un-congested level within the typical battery life duration of a UAV.
Train Your Own GNN Teacher: Graph-Aware Distillation on Textual Graphs
Apr 20, 2023



How can we learn effective node representations on textual graphs? Graph Neural Networks (GNNs) that use Language Models (LMs) to encode textual information of graphs achieve state-of-the-art performance in many node classification tasks. Yet, combining GNNs with LMs has not been widely explored for practical deployments due to its scalability issues. In this work, we tackle this challenge by developing a Graph-Aware Distillation framework (GRAD) to encode graph structures into an LM for graph-free, fast inference. Different from conventional knowledge distillation, GRAD jointly optimizes a GNN teacher and a graph-free student over the graph's nodes via a shared LM. This encourages the graph-free student to exploit graph information encoded by the GNN teacher while at the same time, enables the GNN teacher to better leverage textual information from unlabeled nodes. As a result, the teacher and the student models learn from each other to improve their overall performance. Experiments in eight node classification benchmarks in both transductive and inductive settings showcase GRAD's superiority over existing distillation approaches for textual graphs.
STREET: A Multi-Task Structured Reasoning and Explanation Benchmark
Feb 13, 2023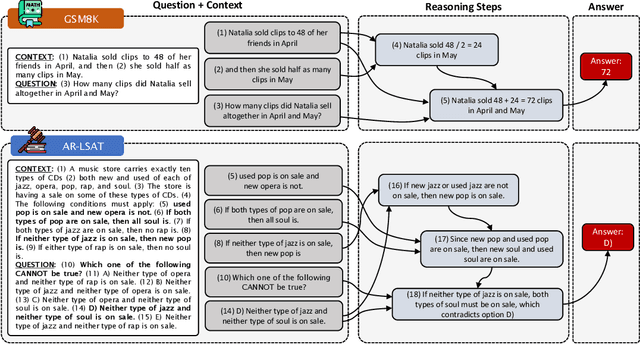
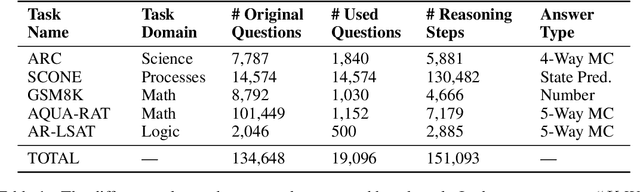
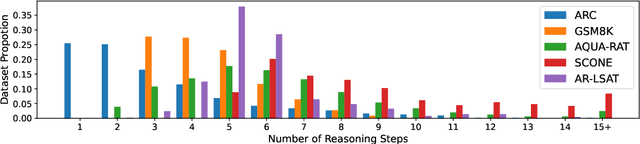
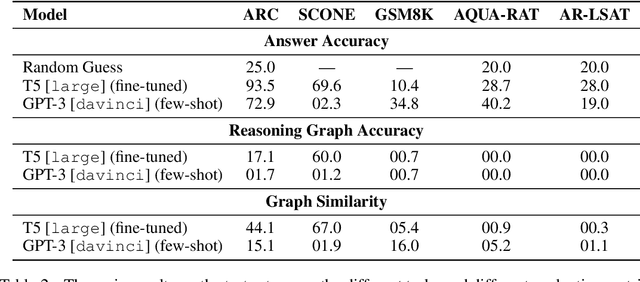
We introduce STREET, a unified multi-task and multi-domain natural language reasoning and explanation benchmark. Unlike most existing question-answering (QA) datasets, we expect models to not only answer questions, but also produce step-by-step structured explanations describing how premises in the question are used to produce intermediate conclusions that can prove the correctness of a certain answer. We perform extensive evaluation with popular language models such as few-shot prompting GPT-3 and fine-tuned T5. We find that these models still lag behind human performance when producing such structured reasoning steps. We believe this work will provide a way for the community to better train and test systems on multi-step reasoning and explanations in natural language.
OrthoReg: Improving Graph-regularized MLPs via Orthogonality Regularization
Jan 31, 2023



Graph Neural Networks (GNNs) are currently dominating in modeling graph-structure data, while their high reliance on graph structure for inference significantly impedes them from widespread applications. By contrast, Graph-regularized MLPs (GR-MLPs) implicitly inject the graph structure information into model weights, while their performance can hardly match that of GNNs in most tasks. This motivates us to study the causes of the limited performance of GR-MLPs. In this paper, we first demonstrate that node embeddings learned from conventional GR-MLPs suffer from dimensional collapse, a phenomenon in which the largest a few eigenvalues dominate the embedding space, through empirical observations and theoretical analysis. As a result, the expressive power of the learned node representations is constrained. We further propose OrthoReg, a novel GR-MLP model to mitigate the dimensional collapse issue. Through a soft regularization loss on the correlation matrix of node embeddings, OrthoReg explicitly encourages orthogonal node representations and thus can naturally avoid dimensionally collapsed representations. Experiments on traditional transductive semi-supervised classification tasks and inductive node classification for cold-start scenarios demonstrate its effectiveness and superiority.
MetaKRec: Collaborative Meta-Knowledge Enhanced Recommender System
Nov 14, 2022Knowledge graph (KG) enhanced recommendation has demonstrated improved performance in the recommendation system (RecSys) and attracted considerable research interest. Recently the literature has adopted neural graph networks (GNNs) on the collaborative knowledge graph and built an end-to-end KG-enhanced RecSys. However, the majority of these approaches have three limitations: (1) treat the collaborative knowledge graph as a homogeneous graph and overlook the highly heterogeneous relationships among items, (2) lack of design to explicitly leverage the rich side information, and (3) overlook the rich knowledge in user preference. To fill this gap, in this paper, we explore the rich, heterogeneous relationship among items and propose a new KG-enhanced recommendation model called Collaborative Meta-Knowledge Enhanced Recommender System (MetaKRec). In particular, we focus on modeling the rich, heterogeneous semantic relationships among items and construct several collaborative Meta-KGs to explicitly depict the relatedness of the items under the guidance of meta-knowledge. In addition to the knowledge obtained from KG, we leverage user knowledge that extracts from user preference to construct the Meta-KGs. The constructed Meta-KGs can capture the knowledge from both the knowledge graph and user preference. Furthermore. we utilize a light convolution encoder to recursively integrate the item relationship in each collaborative Meta-KGs. This scheme allows us to explicitly gather the heterogeneous semantic relationships among items and encode them into the representations of items. In addition, we propose channel attention to fuse the item and user representations from different Meta-KGs. Extensive experiments are conducted on four real-world benchmark datasets, demonstrating significant gains over the state-of-the-art baselines on both regular and cold-start recommendation settings.