 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Gap in Cultural Alignment: Task-Aware Culture Management for Large Language Models
Feb 25, 2026Large language models (LLMs) are increasingly deployed in culturally sensitive real-world tasks. However, existing cultural alignment approaches fail to align LLMs' broad cultural values with the specific goals of downstream tasks and suffer from cross-culture interference. We propose CultureManager, a novel pipeline for task-specific cultural alignment. CultureManager synthesizes task-aware cultural data in line with target task formats, grounded in culturally relevant web search results. To prevent conflicts between cultural norms, it manages multi-culture knowledge learned in separate adapters with a culture router that selects the appropriate one to apply. Experiments across ten national cultures and culture-sensitive tasks show consistent improvements over prompt-based and fine-tuning baselines. Our results demonstrate the necessity of task adaptation and modular culture management for effective cultural alignment.
City Editing: Hierarchical Agentic Execution for Dependency-Aware Urban Geospatial Modification
Feb 22, 2026As cities evolve over time, challenges such as traffic congestion and functional imbalance increasingly necessitate urban renewal through efficient modification of existing plans, rather than complete re-planning. In practice, even minor urban changes require substantial manual effort to redraw geospatial layouts, slowing the iterative planning and decision-making procedure. Motivated by recent advances in agentic systems and multimodal reasoning, we formulate urban renewal as a machine-executable task that iteratively modifies existing urban plans represented in structured geospatial formats. More specifically, we represent urban layouts using GeoJSON and decompose natural-language editing instructions into hierarchical geometric intents spanning polygon-, line-, and point-level operations. To coordinate interdependent edits across spatial elements and abstraction levels, we propose a hierarchical agentic framework that jointly performs multi-level planning and execution with explicit propagation of intermediate spatial constraints. We further introduce an iterative execution-validation mechanism that mitigates error accumulation and enforces global spatial consistency during multi-step editing. Extensive experiments across diverse urban editing scenarios demonstrate significant improvements in efficiency, robustness, correctness, and spatial validity over existing baselines.
Multi-Agent Procedural Graph Extraction with Structural and Logical Refinement
Jan 27, 2026Automatically extracting workflows as procedural graphs from natural language is promising yet underexplored, demanding both structural validity and logical alignment. While recent large language models (LLMs) show potential for procedural graph extraction, they often produce ill-formed structures or misinterpret logical flows. We present \model{}, a multi-agent framework that formulates procedural graph extraction as a multi-round reasoning process with dedicated structural and logical refinement. The framework iterates through three stages: (1) a graph extraction phase with the graph builder agent, (2) a structural feedback phase in which a simulation agent diagnoses and explains structural defects, and (3) a logical feedback phase in which a semantic agent aligns semantics between flow logic and linguistic cues in the source text. Important feedback is prioritized and expressed in natural language, which is injected into subsequent prompts, enabling interpretable and controllable refinement. This modular design allows agents to target distinct error types without supervision or parameter updates. Experiments demonstrate that \model{} achieves substantial improvements in both structural correctness and logical consistency over strong baselines.
Iterative Feature Space Optimization through Incremental Adaptive Evaluation
Jan 24, 2025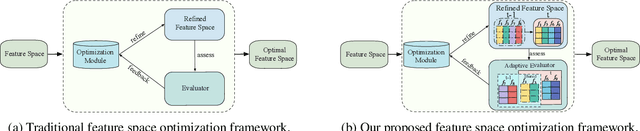
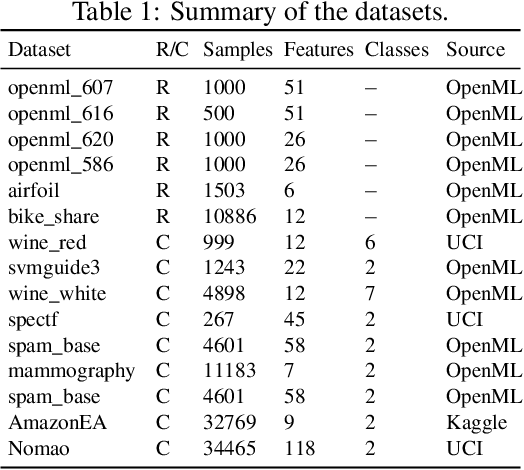
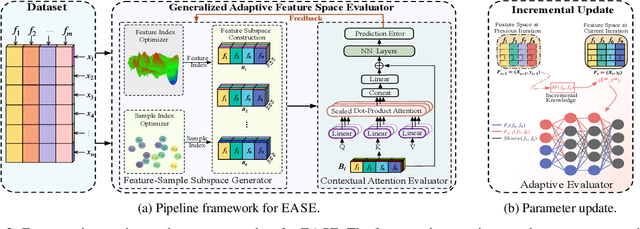
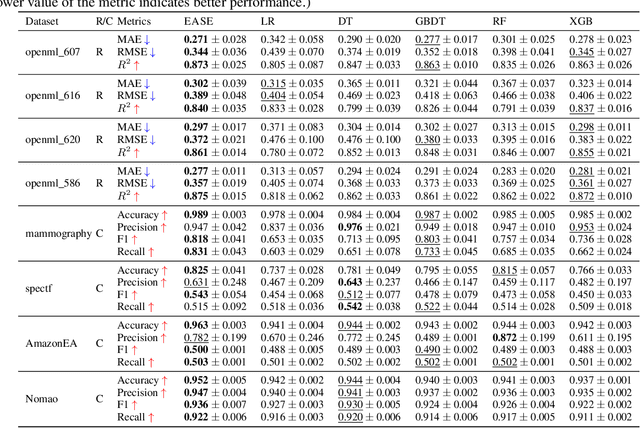
Iterative feature space optimization involves systematically evaluating and adjusting the feature space to improve downstream task performance. However, existing works suffer from three key limitations:1) overlooking differences among data samples leads to evaluation bias; 2) tailoring feature spaces to specific machine learning models results in overfitting and poor generalization; 3) requiring the evaluator to be retrained from scratch during each optimization iteration significantly reduces the overall efficiency of the optimization process. To bridge these gaps, we propose a gEneralized Adaptive feature Space Evaluator (EASE) to efficiently produce optimal and generalized feature spaces. This framework consists of two key components: Feature-Sample Subspace Generator and Contextual Attention Evaluator. The first component aims to decouple the information distribution within the feature space to mitigate evaluation bias. To achieve this, we first identify features most relevant to prediction tasks and samples most challenging for evaluation based on feedback from the subsequent evaluator. This decoupling strategy makes the evaluator consistently target the most challenging aspects of the feature space. The second component intends to incrementally capture evolving patterns of the feature space for efficient evaluation. We propose a weighted-sharing multi-head attention mechanism to encode key characteristics of the feature space into an embedding vector for evaluation. Moreover, the evaluator is updated incrementally, retaining prior evaluation knowledge while incorporating new insights, as consecutive feature spaces during the optimization process share partial information. Extensive experiments on fourteen real-world datasets demonstrate the effectiveness of the proposed framework. Our code and data are publicly available.
Exploring Multi-Modal Integration with Tool-Augmented LLM Agents for Precise Causal Discovery
Dec 18, 2024Causal inference is an imperative foundation for decision-making across domains, such as smart health, AI for drug discovery and AIOps. Traditional statistical causal discovery methods, while well-established, predominantly rely on observational data and often overlook the semantic cues inherent in cause-and-effect relationships. The advent of Large Language Models (LLMs) has ushered in an affordable way of leveraging the semantic cues for knowledge-driven causal discovery, but the development of LLMs for causal discovery lags behind other areas, particularly in the exploration of multi-modality data. To bridge the gap, we introduce MATMCD, a multi-agent system powered by tool-augmented LLMs. MATMCD has two key agents: a Data Augmentation agent that retrieves and processes modality-augmented data, and a Causal Constraint agent that integrates multi-modal data for knowledge-driven inference. Delicate design of the inner-workings ensures successful cooperation of the agents. Our empirical study across seven datasets suggests the significant potential of multi-modality enhanced causal discovery.
Decoding Time Series with LLMs: A Multi-Agent Framework for Cross-Domain Annotation
Oct 22, 2024



Time series data is ubiquitous across various domains, including manufacturing, finance, and healthcare. High-quality annotations are essential for effectively understanding time series and facilitating downstream tasks; however, obtaining such annotations is challenging, particularly in mission-critical domains. In this paper, we propose TESSA, a multi-agent system designed to automatically generate both general and domain-specific annotations for time series data. TESSA introduces two agents: a general annotation agent and a domain-specific annotation agent. The general agent captures common patterns and knowledge across multiple source domains, leveraging both time-series-wise and text-wise features to generate general annotations. Meanwhile, the domain-specific agent utilizes limited annotations from the target domain to learn domain-specific terminology and generate targeted annotations. Extensive experiments on multiple synthetic and real-world datasets demonstrate that TESSA effectively generates high-quality annotations, outperforming existing methods.
Online Multi-modal Root Cause Analysis
Oct 13, 2024Root Cause Analysis (RCA) is essential for pinpointing the root causes of failures in microservice systems. Traditional data-driven RCA methods are typically limited to offline applications due to high computational demands, and existing online RCA methods handle only single-modal data, overlooking complex interactions in multi-modal systems. In this paper, we introduce OCEAN, a novel online multi-modal causal structure learning method for root cause localization. OCEAN employs a dilated convolutional neural network to capture long-term temporal dependencies and graph neural networks to learn causal relationships among system entities and key performance indicators. We further design a multi-factor attention mechanism to analyze and reassess the relationships among different metrics and log indicators/attributes for enhanced online causal graph learning. Additionally, a contrastive mutual information maximization-based graph fusion module is developed to effectively model the relationships across various modalities. Extensive experiments on three real-world datasets demonstrate the effectiveness and efficiency of our proposed method.
RIO-CPD: A Riemannian Geometric Method for Correlation-aware Online Change Point Detection
Jul 12, 2024



The objective of change point detection is to identify abrupt changes at potentially multiple points within a data sequence. This task is particularly challenging in the online setting where various types of changes can occur, including shifts in both the marginal and joint distributions of the data. This paper tackles these challenges by sequentially tracking correlation matrices on the Riemannian geometry, where the geodesic distances accurately capture the development of correlations. We propose Rio-CPD, a non-parametric correlation-aware online change point detection framework that combines the Riemannian geometry of the manifold of symmetric positive definite matrices and the cumulative sum statistic (CUSUM) for detecting change points. Rio-CPD enhances CUSUM by computing the geodesic distance from present observations to the Fr\'echet mean of previous observations. With careful choice of metrics equipped to the Riemannian geometry, Rio-CPD is simple and computationally efficient. Experimental results on both synthetic and real-world datasets demonstrate that Rio-CPD outperforms existing methods in detection accuracy and efficiency.
LEMMA-RCA: A Large Multi-modal Multi-domain Dataset for Root Cause Analysis
Jun 08, 2024



Root cause analysis (RCA) is crucial for enhancing the reliability and performance of complex systems. However, progress in this field has been hindered by the lack of large-scale, open-source datasets tailored for RCA. To bridge this gap, we introduce LEMMA-RCA, a large dataset designed for diverse RCA tasks across multiple domains and modalities. LEMMA-RCA features various real-world fault scenarios from IT and OT operation systems, encompassing microservices, water distribution, and water treatment systems, with hundreds of system entities involved. We evaluate the quality of LEMMA-RCA by testing the performance of eight baseline methods on this dataset under various settings, including offline and online modes as well as single and multiple modalities. Our experimental results demonstrate the high quality of LEMMA-RCA. The dataset is publicly available at https://lemma-rca.github.io/.
Multi-modal Causal Structure Learning and Root Cause Analysis
Feb 04, 2024



Effective root cause analysis (RCA) is vital for swiftly restoring services, minimizing losses, and ensuring the smooth operation and management of complex systems. Previous data-driven RCA methods, particularly those employing causal discovery techniques, have primarily focused on constructing dependency or causal graphs for backtracking the root causes. However, these methods often fall short as they rely solely on data from a single modality, thereby resulting in suboptimal solutions. In this work, we propose Mulan, a unified multi-modal causal structure learning method for root cause localization. We leverage a log-tailored language model to facilitate log representation learning, converting log sequences into time-series data. To explore intricate relationships across different modalities, we propose a contrastive learning-based approach to extract modality-invariant and modality-specific representations within a shared latent space. Additionally, we introduce a novel key performance indicator-aware attention mechanism for assessing modality reliability and co-learning a final causal graph. Finally, we employ random walk with restart to simulate system fault propagation and identify potential root causes. Extensive experiments on three real-world datasets validate the effectiveness of our proposed framework.