 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPUS: Towards Efficient and Principled Data Selection in Large Language Model Pre-training in Every Iteration
Feb 05, 2026As high-quality public text approaches exhaustion, a phenomenon known as the Data Wall, pre-training is shifting from more tokens to better tokens. However, existing methods either rely on heuristic static filters that ignore training dynamics, or use dynamic yet optimizer-agnostic criteria based on raw gradients. We propose OPUS (Optimizer-induced Projected Utility Selection), a dynamic data selection framework that defines utility in the optimizer-induced update space. OPUS scores candidates by projecting their effective updates, shaped by modern optimizers, onto a target direction derived from a stable, in-distribution proxy. To ensure scalability, we employ Ghost technique with CountSketch for computational efficiency, and Boltzmann sampling for data diversity, incurring only 4.7\% additional compute overhead. OPUS achieves remarkable results across diverse corpora, quality tiers, optimizers, and model scales. In pre-training of GPT-2 Large/XL on FineWeb and FineWeb-Edu with 30B tokens, OPUS outperforms industrial-level baselines and even full 200B-token training. Moreover, when combined with industrial-level static filters, OPUS further improves pre-training efficiency, even with lower-quality data. Furthermore, in continued pre-training of Qwen3-8B-Base on SciencePedia, OPUS achieves superior performance using only 0.5B tokens compared to full training with 3B tokens, demonstrating significant data efficiency gains in specialized domains.
Socratic-Geo: Synthetic Data Generation and Geometric Reasoning via Multi-Agent Interaction
Feb 03, 2026Multimodal Large Language Models (MLLMs) have significantly advanced vision-language understanding. However, even state-of-the-art models struggle with geometric reasoning, revealing a critical bottleneck: the extreme scarcity of high-quality image-text pairs. Human annotation is prohibitively expensive, while automated methods fail to ensure fidelity and training effectiveness. Existing approaches either passively adapt to available images or employ inefficient random exploration with filtering, decoupling generation from learning needs. We propose Socratic-Geo, a fully autonomous framework that dynamically couples data synthesis with model learning through multi-agent interaction. The Teacher agent generates parameterized Python scripts with reflective feedback (Reflect for solvability, RePI for visual validity), ensuring image-text pair purity. The Solver agent optimizes reasoning through preference learning, with failure paths guiding Teacher's targeted augmentation. Independently, the Generator learns image generation capabilities on accumulated "image-code-instruction" triplets, distilling programmatic drawing intelligence into visual generation. Starting from only 108 seed problems, Socratic-Solver achieves 49.11 on six benchmarks using one-quarter of baseline data, surpassing strong baselines by 2.43 points. Socratic-Generator achieves 42.4% on GenExam, establishing new state-of-the-art for open-source models, surpassing Seedream-4.0 (39.8%) and approaching Gemini-2.5-Flash-Image (43.1%).
Agentic Proposing: Enhancing Large Language Model Reasoning via Compositional Skill Synthesis
Feb 03, 2026Advancing complex reasoning in large language models relies on high-quality, verifiable datasets, yet human annotation remains cost-prohibitive and difficult to scale. Current synthesis paradigms often face a recurring trade-off: maintaining structural validity typically restricts problem complexity, while relaxing constraints to increase difficulty frequently leads to inconsistent or unsolvable instances. To address this, we propose Agentic Proposing, a framework that models problem synthesis as a goal-driven sequential decision process where a specialized agent dynamically selects and composes modular reasoning skills. Through an iterative workflow of internal reflection and tool-use, we develop the Agentic-Proposer-4B using Multi-Granularity Policy Optimization (MGPO) to generate high-precision, verifiable training trajectories across mathematics, coding, and science. Empirical results demonstrate that downstream solvers trained on agent-synthesized data significantly outperform leading baselines and exhibit robust cross-domain generalization. Notably, a 30B solver trained on only 11,000 synthesized trajectories achieves a state-of-the-art 91.6% accuracy on AIME25, rivaling frontier-scale proprietary models such as GPT-5 and proving that a small volume of high-quality synthetic signals can effectively substitute for massive human-curated datasets.
Grounding and Enhancing Informativeness and Utility in Dataset Distillation
Jan 29, 2026Dataset Distillation (DD) seeks to create a compact dataset from a large, real-world dataset. While recent methods often rely on heuristic approaches to balance efficiency and quality, the fundamental relationship between original and synthetic data remains underexplored. This paper revisits knowledge distillation-based dataset distillation within a solid theoretical framework. We introduce the concepts of Informativeness and Utility, capturing crucial information within a sample and essential samples in the training set, respectively. Building on these principles, we define optimal dataset distillation mathematically. We then present InfoUtil, a framework that balances informativeness and utility in synthesizing the distilled dataset. InfoUtil incorporates two key components: (1) game-theoretic informativeness maximization using Shapley Value attribution to extract key information from samples, and (2) principled utility maximization by selecting globally influential samples based on Gradient Norm. These components ensure that the distilled dataset is both informative and utility-optimized. Experiments demonstrate that our method achieves a 6.1\% performance improvement over the previous state-of-the-art approach on ImageNet-1K dataset using ResNet-18.
UNSEEN: Enhancing Dataset Pruning from a Generalization Perspective
Nov 18, 2025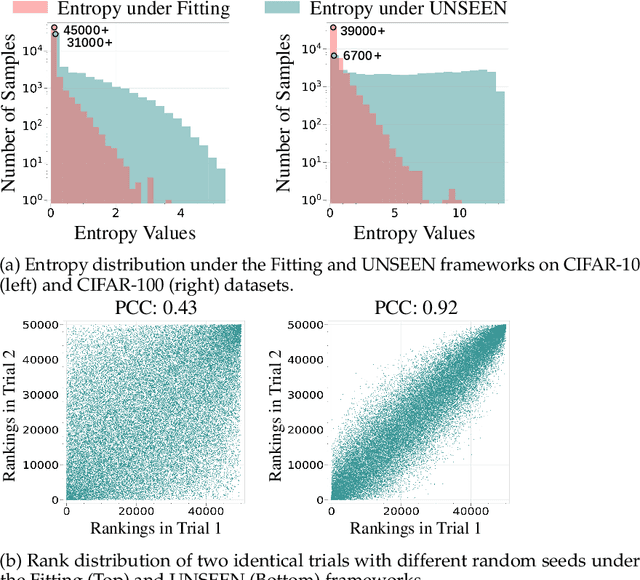

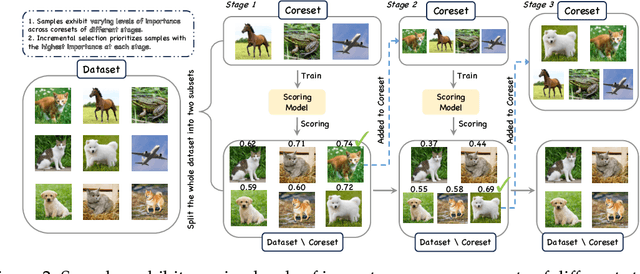

The growing scale of datasets in deep learning has introduced significant computational challenges. Dataset pruning addresses this challenge by constructing a compact but informative coreset from the full dataset with comparable performance. Previous approaches typically establish scoring metrics based on specific criteria to identify representative samples. However, these methods predominantly rely on sample scores obtained from the model's performance during the training (i.e., fitting) phase. As scoring models achieve near-optimal performance on training data, such fitting-centric approaches induce a dense distribution of sample scores within a narrow numerical range. This concentration reduces the distinction between samples and hinders effective selection. To address this challenge, we conduct dataset pruning from the perspective of generalization, i.e., scoring samples based on models not exposed to them during training. We propose a plug-and-play framework, UNSEEN, which can be integrated into existing dataset pruning methods. Additionally, conventional score-based methods are single-step and rely on models trained solely on the complete dataset, providing limited perspective on the importance of samples. To address this limitation, we scale UNSEEN to multi-step scenarios and propose an incremental selection technique through scoring models trained on varying coresets, and optimize the quality of the coreset dynamically. Extensive experiments demonstrate that our method significantly outperforms existing state-of-the-art (SOTA) methods on CIFAR-10, CIFAR-100, and ImageNet-1K. Notably, on ImageNet-1K, UNSEEN achieves lossless performance while reducing training data by 30\%.
ImagebindDC: Compressing Multi-modal Data with Imagebind-based Condensation
Nov 11, 2025

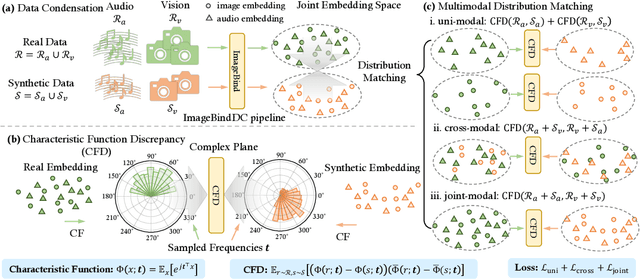

Data condensation techniques aim to synthesize a compact dataset from a larger one to enable efficient model training, yet while successful in unimodal settings, they often fail in multimodal scenarios where preserving intricate inter-modal dependencies is crucial. To address this, we introduce ImageBindDC, a novel data condensation framework operating within the unified feature space of ImageBind. Our approach moves beyond conventional distribution-matching by employing a powerful Characteristic Function (CF) loss, which operates in the Fourier domain to facilitate a more precise statistical alignment via exact infinite moment matching. We design our objective to enforce three critical levels of distributional consistency: (i) uni-modal alignment, which matches the statistical properties of synthetic and real data within each modality; (ii) cross-modal alignment, which preserves pairwise semantics by matching the distributions of hybrid real-synthetic data pairs; and (iii) joint-modal alignment, which captures the complete multivariate data structure by aligning the joint distribution of real data pairs with their synthetic counterparts. Extensive experiments highlight the effectiveness of ImageBindDC: on the NYU-v2 dataset, a model trained on just 5 condensed datapoints per class achieves lossless performance comparable to one trained on the full dataset, achieving a new state-of-the-art with an 8.2\% absolute improvement over the previous best method and more than 4$\times$ less condensation time.
Shifting AI Efficiency From Model-Centric to Data-Centric Compression
May 25, 2025The rapid advancement of large language models (LLMs) and multi-modal LLMs (MLLMs) has historically relied on model-centric scaling through increasing parameter counts from millions to hundreds of billions to drive performance gains. However, as we approach hardware limits on model size, the dominant computational bottleneck has fundamentally shifted to the quadratic cost of self-attention over long token sequences, now driven by ultra-long text contexts, high-resolution images, and extended videos. In this position paper, \textbf{we argue that the focus of research for efficient AI is shifting from model-centric compression to data-centric compression}. We position token compression as the new frontier, which improves AI efficiency via reducing the number of tokens during model training or inference. Through comprehensive analysis, we first examine recent developments in long-context AI across various domains and establish a unified mathematical framework for existing model efficiency strategies, demonstrating why token compression represents a crucial paradigm shift in addressing long-context overhead. Subsequently, we systematically review the research landscape of token compression, analyzing its fundamental benefits and identifying its compelling advantages across diverse scenarios. Furthermore, we provide an in-depth analysis of current challenges in token compression research and outline promising future directions. Ultimately, our work aims to offer a fresh perspective on AI efficiency, synthesize existing research, and catalyze innovative developments to address the challenges that increasing context lengths pose to the AI community's advancement.
KO: Kinetics-inspired Neural Optimizer with PDE Simulation Approaches
May 20, 2025The design of optimization algorithms for neural networks remains a critical challenge, with most existing methods relying on heuristic adaptations of gradient-based approaches. This paper introduces KO (Kinetics-inspired Optimizer), a novel neural optimizer inspired by kinetic theory and partial differential equation (PDE) simulations. We reimagine the training dynamics of network parameters as the evolution of a particle system governed by kinetic principles, where parameter updates are simulated via a numerical scheme for the Boltzmann transport equation (BTE) that models stochastic particle collisions. This physics-driven approach inherently promotes parameter diversity during optimization, mitigating the phenomenon of parameter condensation, i.e. collapse of network parameters into low-dimensional subspaces, through mechanisms analogous to thermal diffusion in physical systems. We analyze this property, establishing both a mathematical proof and a physical interpretation. Extensive experiments on image classification (CIFAR-10/100, ImageNet) and text classification (IMDB, Snips) tasks demonstrate that KO consistently outperforms baseline optimizers (e.g., Adam, SGD), achieving accuracy improvements while computation cost remains comparable.
DD-Ranking: Rethinking the Evaluation of Dataset Distillation
May 19, 2025



In recent years, dataset distillation has provided a reliable solution for data compression, where models trained on the resulting smaller synthetic datasets achieve performance comparable to those trained on the original datasets. To further improve the performance of synthetic datasets, various training pipelines and optimization objectives have been proposed, greatly advancing the field of dataset distillation. Recent decoupled dataset distillation methods introduce soft labels and stronger data augmentation during the post-evaluation phase and scale dataset distillation up to larger datasets (e.g., ImageNet-1K). However, this raises a question: Is accuracy still a reliable metric to fairly evaluate dataset distillation methods? Our empirical findings suggest that the performance improvements of these methods often stem from additional techniques rather than the inherent quality of the images themselves, with even randomly sampled images achieving superior results. Such misaligned evaluation settings severely hinder the development of DD. Therefore, we propose DD-Ranking, a unified evaluation framework, along with new general evaluation metrics to uncover the true performance improvements achieved by different methods. By refocusing on the actual information enhancement of distilled datasets, DD-Ranking provides a more comprehensive and fair evaluation standard for future research advancements.
Data Whisperer: Efficient Data Selection for Task-Specific LLM Fine-Tuning via Few-Shot In-Context Learning
May 18, 2025Fine-tuning large language models (LLMs) on task-specific data is essential for their effective deployment. As dataset sizes grow, efficiently selecting optimal subsets for training becomes crucial to balancing performance and computational costs. Traditional data selection methods often require fine-tuning a scoring model on the target dataset, which is time-consuming and resource-intensive, or rely on heuristics that fail to fully leverage the model's predictive capabilities. To address these challenges, we propose Data Whisperer, an efficient, training-free, attention-based method that leverages few-shot in-context learning with the model to be fine-tuned. Comprehensive evaluations were conducted on both raw and synthetic datasets across diverse tasks and models. Notably, Data Whisperer achieves superior performance compared to the full GSM8K dataset on the Llama-3-8B-Instruct model, using just 10% of the data, and outperforms existing methods with a 3.1-point improvement and a 7.4$\times$ speedup.