 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaCF: Mitigating Shortcut Learning in Reward Models via Dynamic Counterfactual Sensitivity
Jun 08, 2026Reward models trained from pairwise preferences often exploit superficial shortcut cues rather than learning true response quality. We propose DynaCF, a dynamic reweighting framework for mitigating shortcut learning in reward model training. Unlike static shortcut heuristics, DynaCF measures shortcut sensitivity online during optimization by applying semantics-preserving counterfactual perturbations and tracking the resulting margin shifts and preference flips under the current model. Samples with higher shortcut sensitivity are dynamically downweighted in the Bradley-Terry objective, encouraging the model to rely less on superficial patterns and more on task-relevant preference signals. Extensive experiments show that DynaCF consistently improves robustness in preference modeling.
RASFT: Rollout-Adaptive Supervised Fine-Tuning for Reasoning
Jun 05, 2026Supervised fine-tuning (SFT) is a prevailing method for adapting large language models to reasoning tasks by imitating offline expert demonstrations, often treating a single expert trajectory as the target behavior. However, reasoning is not simple path imitation: rigidly following one demonstrated solution may overfit to surface forms and suppress the model's own reasoning distribution. We propose Rollout-Adaptive Supervised Fine-Tuning (RASFT), a policy-aware SFT framework that calibrates expert supervision according to problem-level solvability estimated from verified on-policy rollouts. For each problem, RASFT strengthens expert guidance when the current policy struggles, while relaxing rigid imitation and incorporating correct self-generated trajectories when the model already exhibits reliable reasoning behavior. To preserve useful reasoning priors, RASFT further introduces a clipped inverse ratio between the frozen reference model and the current policy to constrain excessive policy drift. Experiments across multiple models on six mathematical reasoning benchmarks and two code reasoning benchmarks show that RASFT achieves better overall performance than SFT, SFT variants, and representative RL methods. The code is available at https://github.com/zjd1sq/RASFT.
AdaJudge: Adaptive Multi-Perspective Judging for Reward Modeling
Jan 13, 2026Reward modeling is essential for aligning large language models with human preferences, yet predominant architectures rely on a static pooling strategy to condense sequences into scalar scores. This paradigm, however, suffers from two key limitations: a static inductive bias that misaligns with task-dependent preference signals, and a representational mismatch, as the backbone is optimized for generation rather than fine-grained discrimination. To address this, we propose AdaJudge, a unified framework that jointly adapts representation and aggregation. AdaJudge first refines backbone representations into a discrimination-oriented space via gated refinement blocks. It then replaces the static readout with an adaptive multi-view pooling module that dynamically routes and combines evidence. Extensive experiments on RM-Bench and JudgeBench show that AdaJudge outperforms strong off-the-shelf reward models and traditional pooling baselines.
NeuronScope: A Multi-Agent Framework for Explaining Polysemantic Neurons in Language Models
Jan 07, 2026Neuron-level interpretation in large language models (LLMs) is fundamentally challenged by widespread polysemanticity, where individual neurons respond to multiple distinct semantic concepts. Existing single-pass interpretation methods struggle to faithfully capture such multi-concept behavior. In this work, we propose NeuronScope, a multi-agent framework that reformulates neuron interpretation as an iterative, activation-guided process. NeuronScope explicitly deconstructs neuron activations into atomic semantic components, clusters them into distinct semantic modes, and iteratively refines each explanation using neuron activation feedback. Experiments demonstrate that NeuronScope uncovers hidden polysemanticity and produces explanations with significantly higher activation correlation compared to single-pass baselines.
ImagebindDC: Compressing Multi-modal Data with Imagebind-based Condensation
Nov 11, 2025

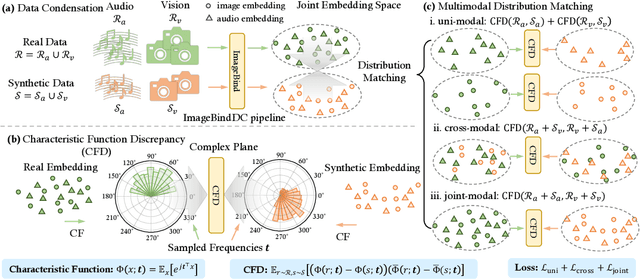

Data condensation techniques aim to synthesize a compact dataset from a larger one to enable efficient model training, yet while successful in unimodal settings, they often fail in multimodal scenarios where preserving intricate inter-modal dependencies is crucial. To address this, we introduce ImageBindDC, a novel data condensation framework operating within the unified feature space of ImageBind. Our approach moves beyond conventional distribution-matching by employing a powerful Characteristic Function (CF) loss, which operates in the Fourier domain to facilitate a more precise statistical alignment via exact infinite moment matching. We design our objective to enforce three critical levels of distributional consistency: (i) uni-modal alignment, which matches the statistical properties of synthetic and real data within each modality; (ii) cross-modal alignment, which preserves pairwise semantics by matching the distributions of hybrid real-synthetic data pairs; and (iii) joint-modal alignment, which captures the complete multivariate data structure by aligning the joint distribution of real data pairs with their synthetic counterparts. Extensive experiments highlight the effectiveness of ImageBindDC: on the NYU-v2 dataset, a model trained on just 5 condensed datapoints per class achieves lossless performance comparable to one trained on the full dataset, achieving a new state-of-the-art with an 8.2\% absolute improvement over the previous best method and more than 4$\times$ less condensation time.