 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinaryDemoire: Moiré-Aware Binarization for Image Demoiréing
Feb 03, 2026Image demoiréing aims to remove structured moiré artifacts in recaptured imagery, where degradations are highly frequency-dependent and vary across scales and directions. While recent deep networks achieve high-quality restoration, their full-precision designs remain costly for deployment. Binarization offers an extreme compression regime by quantizing both activations and weights to 1-bit. Yet, it has been rarely studied for demoiréing and performs poorly when naively applied. In this work, we propose BinaryDemoire, a binarized demoiréing framework that explicitly accommodates the frequency structure of moiré degradations. First, we introduce a moiré-aware binary gate (MABG) that extracts lightweight frequency descriptors together with activation statistics. It predicts channel-wise gating coefficients to condition the aggregation of binary convolution responses. Second, we design a shuffle-grouped residual adapter (SGRA) that performs structured sparse shortcut alignment. It further integrates interleaved mixing to promote information exchange across different channel partitions. Extensive experiments on four benchmarks demonstrate that the proposed BinaryDemoire surpasses current binarization methods. Code: https://github.com/zhengchen1999/BinaryDemoire.
Combined Flicker-banding and Moire Removal for Screen-Captured Images
Feb 02, 2026Capturing display screens with mobile devices has become increasingly common, yet the resulting images often suffer from severe degradations caused by the coexistence of moiré patterns and flicker-banding, leading to significant visual quality degradation. Due to the strong coupling of these two artifacts in real imaging processes, existing methods designed for single degradations fail to generalize to such compound scenarios. In this paper, we present the first systematic study on joint removal of moiré patterns and flicker-banding in screen-captured images, and propose a unified restoration framework, named CLEAR. To support this task, we construct a large-scale dataset containing both moiré patterns and flicker-banding, and introduce an ISP-based flicker simulation pipeline to stabilize model training and expand the degradation distribution. Furthermore, we design a frequency-domain decomposition and re-composition module together with a trajectory alignment loss to enhance the modeling of compound artifacts. Extensive experiments demonstrate that the proposed method consistently. outperforms existing image restoration approaches across multiple evaluation metrics, validating its effectiveness in complex real-world scenarios.
KITINet: Kinetics Theory Inspired Network Architectures with PDE Simulation Approaches
May 23, 2025Despite the widely recognized success of residual connections in modern neural networks, their design principles remain largely heuristic. This paper introduces KITINet (Kinetics Theory Inspired Network), a novel architecture that reinterprets feature propagation through the lens of non-equilibrium particle dynamics and partial differential equation (PDE) simulation. At its core, we propose a residual module that models feature updates as the stochastic evolution of a particle system, numerically simulated via a discretized solver for the Boltzmann transport equation (BTE). This formulation mimics particle collisions and energy exchange, enabling adaptive feature refinement via physics-informed interactions. Additionally, we reveal that this mechanism induces network parameter condensation during training, where parameters progressively concentrate into a sparse subset of dominant channels. Experiments on scientific computation (PDE operator), image classification (CIFAR-10/100), and text classification (IMDb/SNLI) show consistent improvements over classic network baselines, with negligible increase of FLOPs.
KO: Kinetics-inspired Neural Optimizer with PDE Simulation Approaches
May 20, 2025The design of optimization algorithms for neural networks remains a critical challenge, with most existing methods relying on heuristic adaptations of gradient-based approaches. This paper introduces KO (Kinetics-inspired Optimizer), a novel neural optimizer inspired by kinetic theory and partial differential equation (PDE) simulations. We reimagine the training dynamics of network parameters as the evolution of a particle system governed by kinetic principles, where parameter updates are simulated via a numerical scheme for the Boltzmann transport equation (BTE) that models stochastic particle collisions. This physics-driven approach inherently promotes parameter diversity during optimization, mitigating the phenomenon of parameter condensation, i.e. collapse of network parameters into low-dimensional subspaces, through mechanisms analogous to thermal diffusion in physical systems. We analyze this property, establishing both a mathematical proof and a physical interpretation. Extensive experiments on image classification (CIFAR-10/100, ImageNet) and text classification (IMDB, Snips) tasks demonstrate that KO consistently outperforms baseline optimizers (e.g., Adam, SGD), achieving accuracy improvements while computation cost remains comparable.
Low Rank Representation on Riemannian Manifold of Square Root Densities
Aug 18, 2015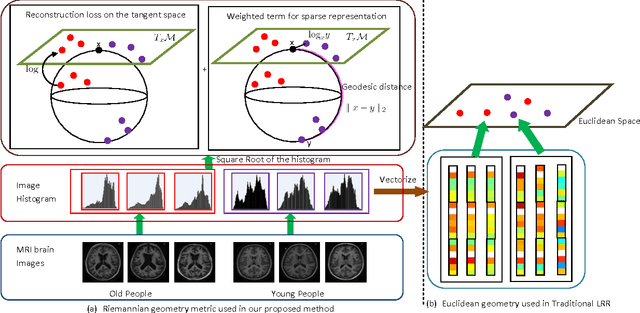
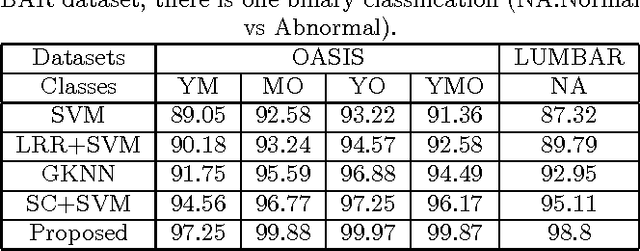

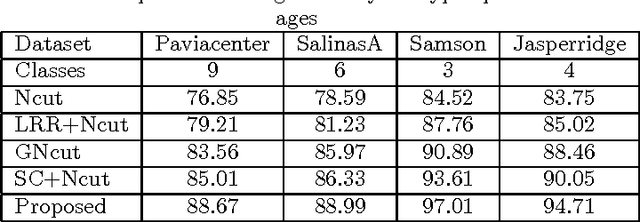
In this paper, we present a novel low rank representation (LRR) algorithm for data lying on the manifold of square root densities. Unlike traditional LRR methods which rely on the assumption that the data points are vectors in the Euclidean space, our new algorithm is designed to incorporate the intrinsic geometric structure and geodesic distance of the manifold. Experiments on several computer vision datasets showcase its noise robustness and superior performance on classification and subspace clustering compared to other state-of-the-art approaches.