 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-efficient Learning of Morphology and Controller for a Microrobot
May 03, 2019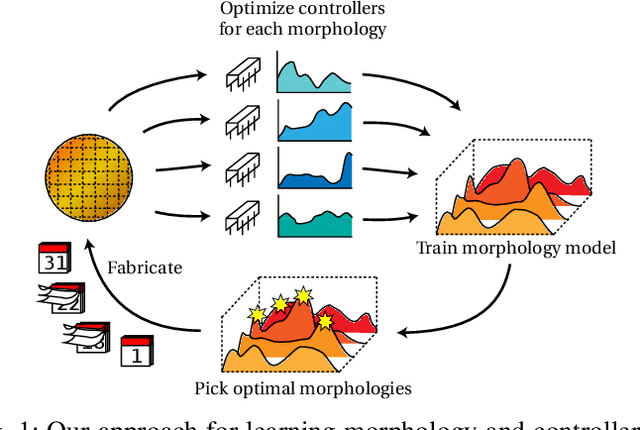
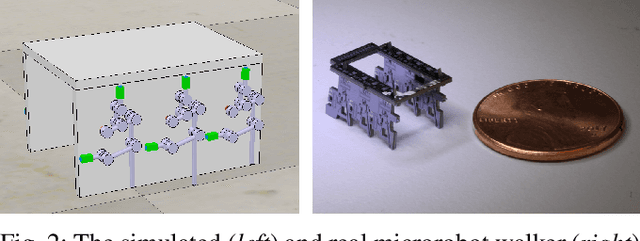
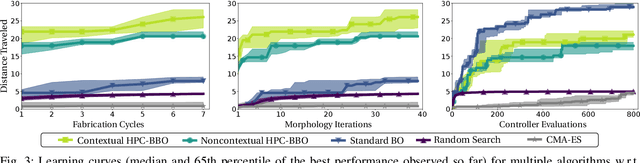
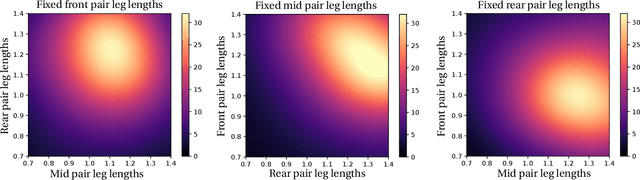
Robot design is often a slow and difficult process requiring the iterative construction and testing of prototypes, with the goal of sequentially optimizing the design. For most robots, this process is further complicated by the need, when validating the capabilities of the hardware to solve the desired task, to already have an appropriate controller, which is in turn designed and tuned for the specific hardware. In this paper, we propose a novel approach, HPC-BBO, to efficiently and automatically design hardware configurations, and evaluate them by also automatically tuning the corresponding controller. HPC-BBO is based on a hierarchical Bayesian optimization process which iteratively optimizes morphology configurations (based on the performance of the previous designs during the controller learning process) and subsequently learns the corresponding controllers (exploiting the knowledge collected from optimizing for previous morphologies). Moreover, HPC-BBO can select a "batch" of multiple morphology designs at once, thus parallelizing hardware validation and reducing the number of time-consuming production cycles. We validate HPC-BBO on the design of the morphology and controller for a simulated 6-legged microrobot. Experimental results show that HPC-BBO outperforms multiple competitive baselines, and yields a $360\%$ reduction in production cycles over standard Bayesian optimization, thus reducing the hypothetical manufacturing time of our microrobot from 21 to 4 months.
Improvisation through Physical Understanding: Using Novel Objects as Tools with Visual Foresight
Apr 11, 2019
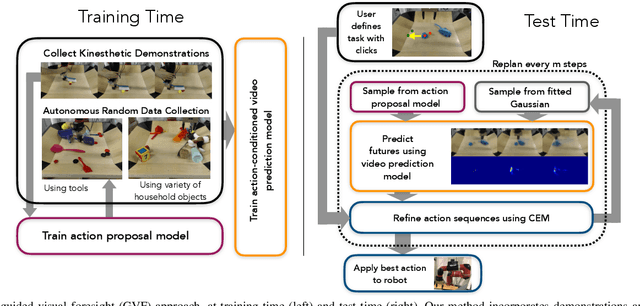


Machine learning techniques have enabled robots to learn narrow, yet complex tasks and also perform broad, yet simple skills with a wide variety of objects. However, learning a model that can both perform complex tasks and generalize to previously unseen objects and goals remains a significant challenge. We study this challenge in the context of "improvisational" tool use: a robot is presented with novel objects and a user-specified goal (e.g., sweep some clutter into the dustpan), and must figure out, using only raw image observations, how to accomplish the goal using the available objects as tools. We approach this problem by training a model with both a visual and physical understanding of multi-object interactions, and develop a sampling-based optimizer that can leverage these interactions to accomplish tasks. We do so by combining diverse demonstration data with self-supervised interaction data, aiming to leverage the interaction data to build generalizable models and the demonstration data to guide the model-based RL planner to solve complex tasks. Our experiments show that our approach can solve a variety of complex tool use tasks from raw pixel inputs, outperforming both imitation learning and self-supervised learning individually. Furthermore, we show that the robot can perceive and use novel objects as tools, including objects that are not conventional tools, while also choosing dynamically to use or not use tools depending on whether or not they are required.
InfoBot: Transfer and Exploration via the Information Bottleneck
Apr 04, 2019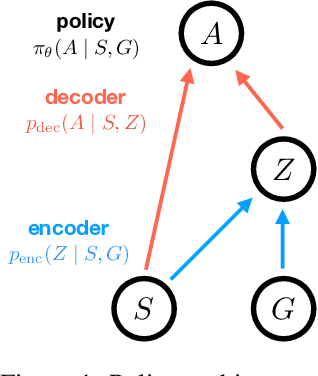



A central challenge in reinforcement learning is discovering effective policies for tasks where rewards are sparsely distributed. We postulate that in the absence of useful reward signals, an effective exploration strategy should seek out {\it decision states}. These states lie at critical junctions in the state space from where the agent can transition to new, potentially unexplored regions. We propose to learn about decision states from prior experience. By training a goal-conditioned policy with an information bottleneck, we can identify decision states by examining where the model actually leverages the goal state. We find that this simple mechanism effectively identifies decision states, even in partially observed settings. In effect, the model learns the sensory cues that correlate with potential subgoals. In new environments, this model can then identify novel subgoals for further exploration, guiding the agent through a sequence of potential decision states and through new regions of the state space.
Guided Meta-Policy Search
Apr 01, 2019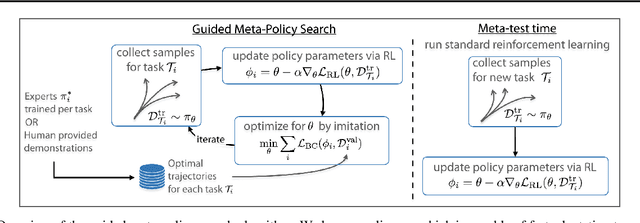
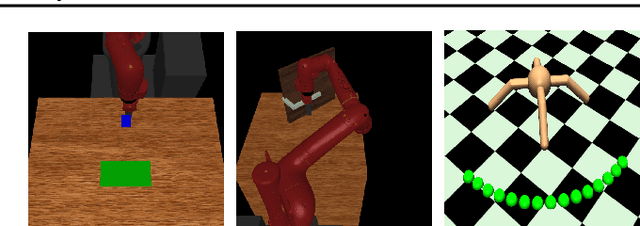
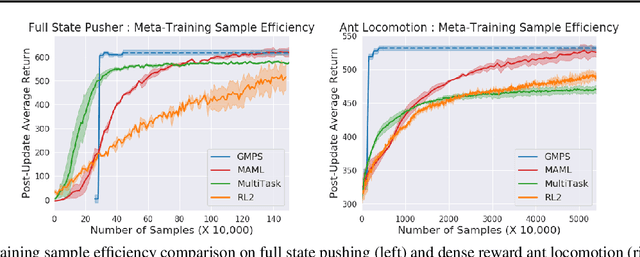
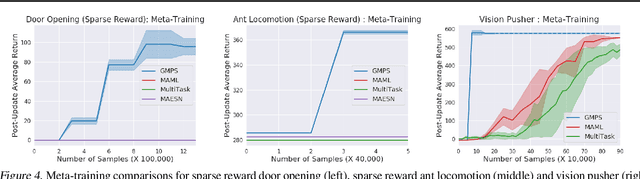
Reinforcement learning (RL) algorithms have demonstrated promising results on complex tasks, yet often require impractical numbers of samples because they learn from scratch. Meta-RL aims to address this challenge by leveraging experience from previous tasks in order to more quickly solve new tasks. However, in practice, these algorithms generally also require large amounts of on-policy experience during the meta-training process, making them impractical for use in many problems. To this end, we propose to learn a reinforcement learning procedure through imitation of expert policies that solve previously-seen tasks. This involves a nested optimization, with RL in the inner loop and supervised imitation learning in the outer loop. Because the outer loop imitation learning can be done with off-policy data, we can achieve significant gains in meta-learning sample efficiency. In this paper, we show how this general idea can be used both for meta-reinforcement learning and for learning fast RL procedures from multi-task demonstration data. The former results in an approach that can leverage policies learned for previous tasks without significant amounts of on-policy data during meta-training, whereas the latter is particularly useful in cases where demonstrations are easy for a person to provide. Across a number of continuous control meta-RL problems, we demonstrate significant improvements in meta-RL sample efficiency in comparison to prior work as well as the ability to scale to domains with visual observations.
Wasserstein Dependency Measure for Representation Learning
Mar 28, 2019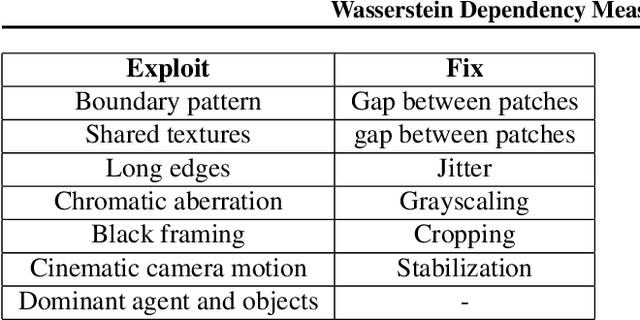

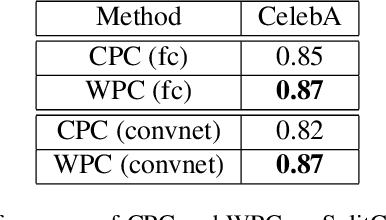
Mutual information maximization has emerged as a powerful learning objective for unsupervised representation learning obtaining state-of-the-art performance in applications such as object recognition, speech recognition, and reinforcement learning. However, such approaches are fundamentally limited since a tight lower bound of mutual information requires sample size exponential in the mutual information. This limits the applicability of these approaches for prediction tasks with high mutual information, such as in video understanding or reinforcement learning. In these settings, such techniques are prone to overfit, both in theory and in practice, and capture only a few of the relevant factors of variation. This leads to incomplete representations that are not optimal for downstream tasks. In this work, we empirically demonstrate that mutual information-based representation learning approaches do fail to learn complete representations on a number of designed and real-world tasks. To mitigate these problems we introduce the Wasserstein dependency measure, which learns more complete representations by using the Wasserstein distance instead of the KL divergence in the mutual information estimator. We show that a practical approximation to this theoretically motivated solution, constructed using Lipschitz constraint techniques from the GAN literature, achieves substantially improved results on tasks where incomplete representations are a major challenge.
Sim-to-Real via Sim-to-Sim: Data-efficient Robotic Grasping via Randomized-to-Canonical Adaptation Networks
Mar 25, 2019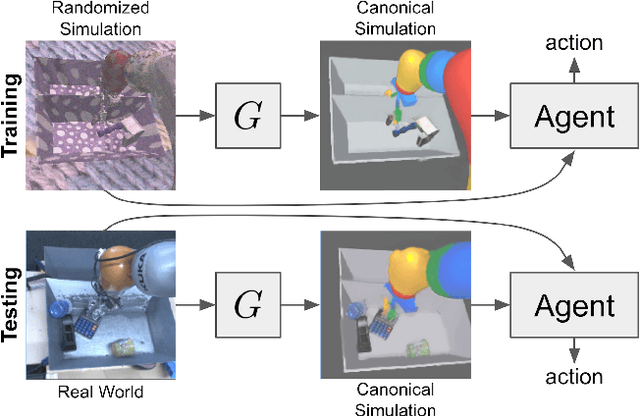
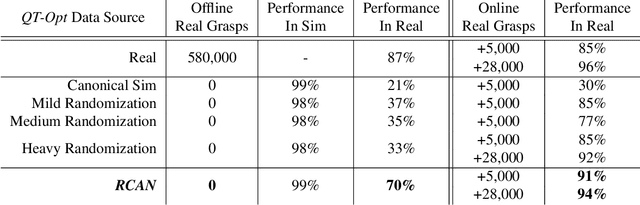


Real world data, especially in the domain of robotics, is notoriously costly to collect. One way to circumvent this can be to leverage the power of simulation to produce large amounts of labelled data. However, training models on simulated images does not readily transfer to real-world ones. Using domain adaptation methods to cross this "reality gap" requires a large amount of unlabelled real-world data, whilst domain randomization alone can waste modeling power. In this paper, we present Randomized-to-Canonical Adaptation Networks (RCANs), a novel approach to crossing the visual reality gap that uses no real-world data. Our method learns to translate randomized rendered images into their equivalent non-randomized, canonical versions. This in turn allows for real images to also be translated into canonical sim images. We demonstrate the effectiveness of this sim-to-real approach by training a vision-based closed-loop grasping reinforcement learning agent in simulation, and then transferring it to the real world to attain 70% zero-shot grasp success on unseen objects, a result that almost doubles the success of learning the same task directly on domain randomization alone. Additionally, by joint finetuning in the real-world with only 5,000 real-world grasps, our method achieves 91%, attaining comparable performance to a state-of-the-art system trained with 580,000 real-world grasps, resulting in a reduction of real-world data by more than 99%.
Learning to Walk via Deep Reinforcement Learning
Mar 25, 2019
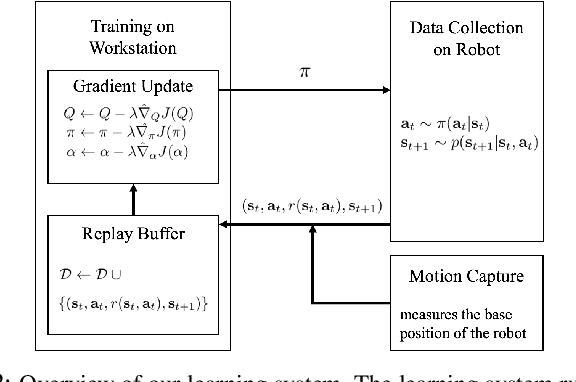
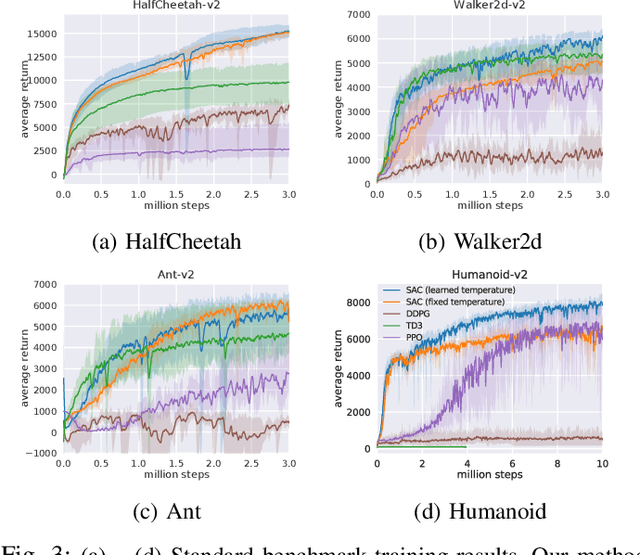
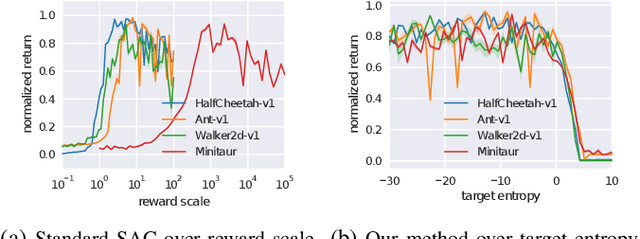
Deep reinforcement learning offers the promise of automatic acquisition of robotic control policies that directly map sensory inputs to low-level actions. In the domain of robotic locomotion, it could make it possible for locomotion skills to be learned with minimal engineering and without even needing to construct a model of the robot. However, applying deep reinforcement learning methods on real-world robots is exceptionally difficult, due both to the sample complexity and, just as importantly, the sensitivity of such methods to hyperparameters. While hyperparameter tuning can be performed in parallel in simulated domains, it is usually impractical to tune hyperparameters directly on real-world robotic platforms, especially legged platforms like quadrupedal robots that can be damaged through extensive trial-and-error learning. We develop a stable deep RL algorithm that extends soft actor-critic, requires minimal hyperparameter tuning, and requires only a modest number of trials to learn multilayer neural network policies. We then apply this method to learn walking gaits on a real-world Minitaur robot. Our method can learn to walk from scratch directly in the real world in two hours of training, without any model or simulation, and the resulting policy is robust to moderate variations in the environment. We further show that our algorithm achieves state-of-the-art performance on four standard simulated benchmarks.
Efficient Off-Policy Meta-Reinforcement Learning via Probabilistic Context Variables
Mar 19, 2019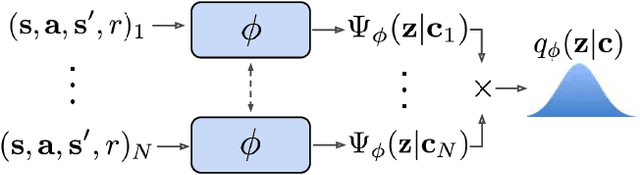
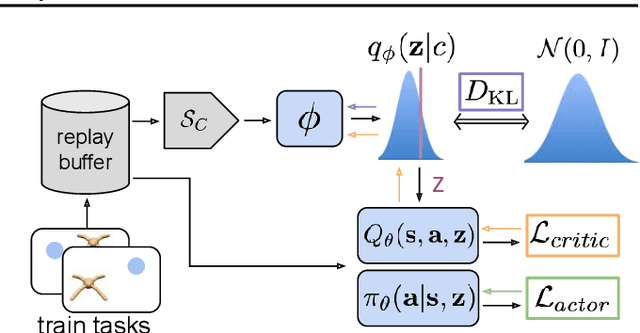
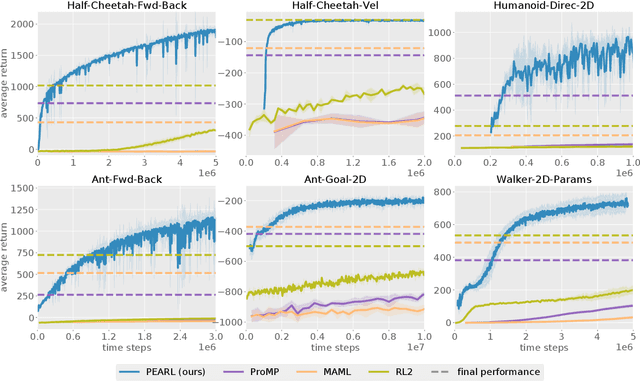
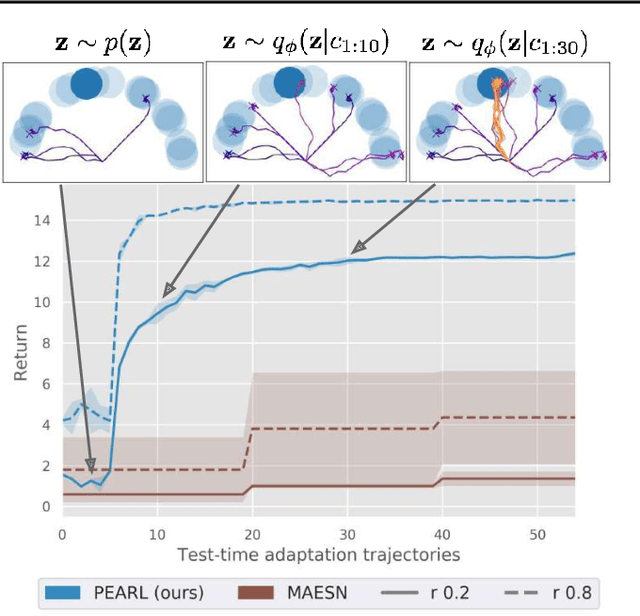
Deep reinforcement learning algorithms require large amounts of experience to learn an individual task. While in principle meta-reinforcement learning (meta-RL) algorithms enable agents to learn new skills from small amounts of experience, several major challenges preclude their practicality. Current methods rely heavily on on-policy experience, limiting their sample efficiency. The also lack mechanisms to reason about task uncertainty when adapting to new tasks, limiting their effectiveness in sparse reward problems. In this paper, we address these challenges by developing an off-policy meta-RL algorithm that disentangles task inference and control. In our approach, we perform online probabilistic filtering of latent task variables to infer how to solve a new task from small amounts of experience. This probabilistic interpretation enables posterior sampling for structured and efficient exploration. We demonstrate how to integrate these task variables with off-policy RL algorithms to achieve both meta-training and adaptation efficiency. Our method outperforms prior algorithms in sample efficiency by 20-100X as well as in asymptotic performance on several meta-RL benchmarks.
Manipulation by Feel: Touch-Based Control with Deep Predictive Models
Mar 11, 2019

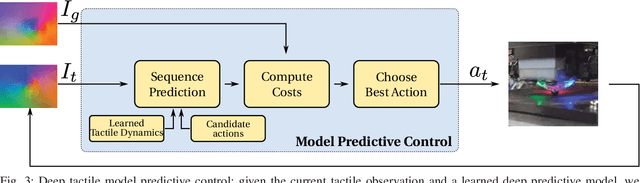
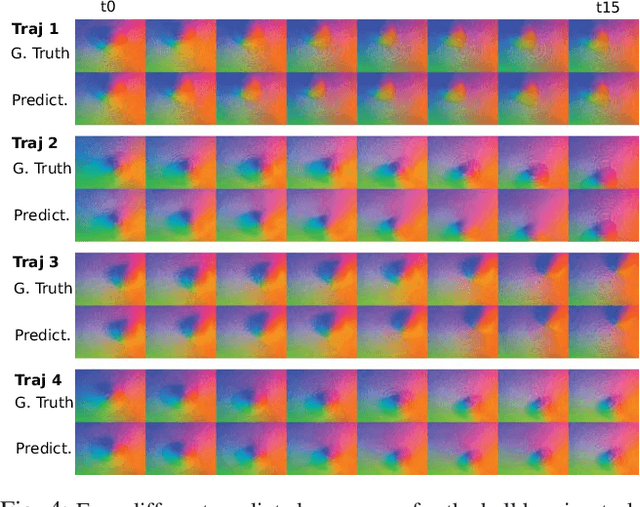
Touch sensing is widely acknowledged to be important for dexterous robotic manipulation, but exploiting tactile sensing for continuous, non-prehensile manipulation is challenging. General purpose control techniques that are able to effectively leverage tactile sensing as well as accurate physics models of contacts and forces remain largely elusive, and it is unclear how to even specify a desired behavior in terms of tactile percepts. In this paper, we take a step towards addressing these issues by combining high-resolution tactile sensing with data-driven modeling using deep neural network dynamics models. We propose deep tactile MPC, a framework for learning to perform tactile servoing from raw tactile sensor inputs, without manual supervision. We show that this method enables a robot equipped with a GelSight-style tactile sensor to manipulate a ball, analog stick, and 20-sided die, learning from unsupervised autonomous interaction and then using the learned tactile predictive model to reposition each object to user-specified configurations, indicated by a goal tactile reading. Videos, visualizations and the code are available here: https://sites.google.com/view/deeptactilempc
Skew-Fit: State-Covering Self-Supervised Reinforcement Learning
Mar 08, 2019
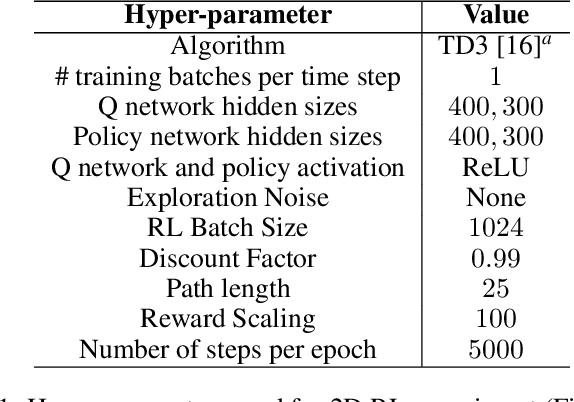
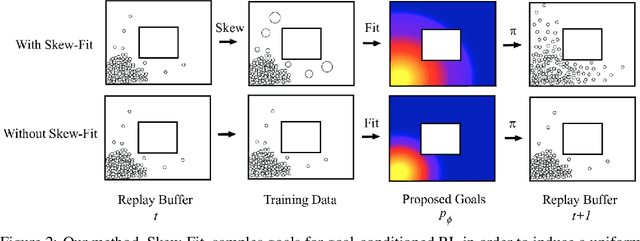
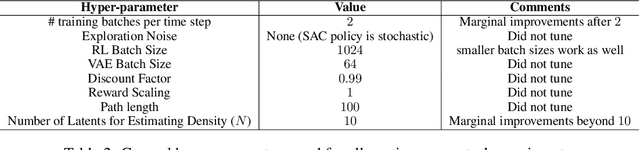
In standard reinforcement learning, each new skill requires a manually-designed reward function, which takes considerable manual effort and engineering. Self-supervised goal setting has the potential to automate this process, enabling an agent to propose its own goals and acquire skills that achieve these goals. However, such methods typically rely on manually-designed goal distributions, or heuristics to force the agent to explore a wide range of states. We propose a formal exploration objective for goal-reaching policies that maximizes state coverage. We show that this objective is equivalent to maximizing the entropy of the goal distribution together with goal reaching performance, where goals correspond to entire states. We present an algorithm called Skew-Fit for learning such a maximum-entropy goal distribution, and show that under certain regularity conditions, our method converges to a uniform distribution over the set of possible states, even when we do not know this set beforehand. Skew-Fit enables self-supervised agents to autonomously choose and practice diverse goals. Our experiments show that it can learn a variety of manipulation tasks from images, including opening a door with a real robot, entirely from scratch and without any manually-designed reward function.